无需微调的自学习AI智能体
使用动态工具和不断演进的系统提示,构建能够随着时间推移而变得更加智能的智能体——无需微调。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
LLM(学习型模型)改变了我们消费和创造内容的方式。我们不再需要进行所谓的“研究”,不再需要花费数小时在谷歌上搜索或阅读文章来收集信息。如今,如果您有任何疑问,只需向 LLM 提问即可。随着 LLM 领域竞争的日益激烈,这些模型的质量和可靠性都得到了显著提升。如果你是一名软件工程师,LLM(机器学习模型)绝对会颠覆你的工作方式——除了提问之外,LLM 还能生成代码,在某些情况下甚至可以生成整个应用程序。
但最容易被忽视的优势在于:LLM 让构建机器学习应用程序变得轻而易举,即使你没有数据科学背景也能轻松上手。根据应用程序的复杂程度,你可以使用不同的推理模型来构建智能应用程序,只需几行代码即可完成预测、分类和推荐等功能。对于像我这样并非机器学习工程师的人来说,这种能力让我能够突破传统思维的局限,构建真正对客户有用且影响深远的应用程序。
尽管在大多数情况下,开箱即用的模型可以解决大部分问题,但实际应用往往需要特定领域的精准度。许多开发者认为这需要进行微调——这是一个成本高昂且需要专业知识的过程。但其实不必如此复杂。在大多数情况下,只需更新系统提示,或者让模型接触到一套新的工具,即可在无需微调的情况下提升响应质量。
如果您正在寻找一种更智能的方式来构建无需微调的自改进型智能体,那么这篇博客正是为您准备的。在本文中,我将分享两种模式,它们可以帮助您构建无需微调模型的自改进型智能体。
1、Strands,AWS 智能体框架
在本文中,我们将使用 AWS 智能体框架 Strands 来构建一个自改进型智能体。Strands 是一个轻量级框架,只需几行代码即可创建智能体应用程序。它基于 AWS SDK 构建,提供了各种工具和 API,可帮助您快速高效地开发智能体。
我最常被问到的问题之一是:为什么选择 Strands?为什么不选择 LangChain 或其他框架?答案很简单,使用 Strands,我只需不到四行代码即可构建一个智能体。由于 AWS 是我首选的云提供商,Strands 还提供了与 AWS 服务(例如 Agent Core、Bedrock 等)的无缝集成。这种紧密集成显著减少了入门所需的样板代码量。
Strands 在 re:Invent 2025 大会上也发布了多项激动人心的公告并发表了精彩演讲,本博客的灵感正是来源于这些更新和讨论。
2、[模式 1]:具有动态工具的自改进型智能体
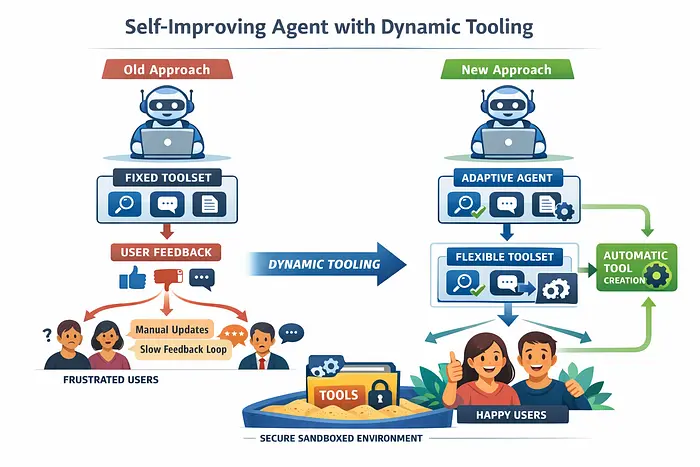
想象一下,构建一个能够处理各种任务(例如搜索、聊天、摘要等)的通用智能体。通常,这类智能体都配备了一套固定的、有限的工具。随着时间的推移,你会观察用户如何与智能体交互,并根据点赞/踩、评论或评分等反馈信号来改进工具集。
这种方法的挑战在于,反馈循环缓慢且高度依赖人工干预。团队必须汇总反馈、分析反馈,然后手动设计和部署新的或改进的工具。与此同时,用户仍然会收到不尽如人意的响应,并且不得不等待下一次迭代才能看到任何改进。这往往会导致用户感到沮丧,并造成糟糕的用户体验。
2.1 解决方案
动态工具的强大之处就在于此。我们不限制代理只能使用预定义的工具集,而是允许 LLM 判断现有工具是否适用于给定任务。如果没有合适的工具,代理可以动态创建一个新工具并将其添加到工具集中,整个过程无需人工干预。
通过这种方法,代理可以根据用户查询不断改进自身功能。虽然这会带来一些安全隐患,但可以通过加强工具执行权限或在沙盒环境中运行新生成的工具来缓解。
在下面的示例中,代理动态创建一个新工具,将其存储在工具目录中,然后在运行时使用 Strands 的 load_tools_from_directory 方法加载它。完整的端到端实现可在 GitHub 上找到;以下是一些关键亮点。
系统提示,允许代理在工具集中找不到所需工具时创建新工具。
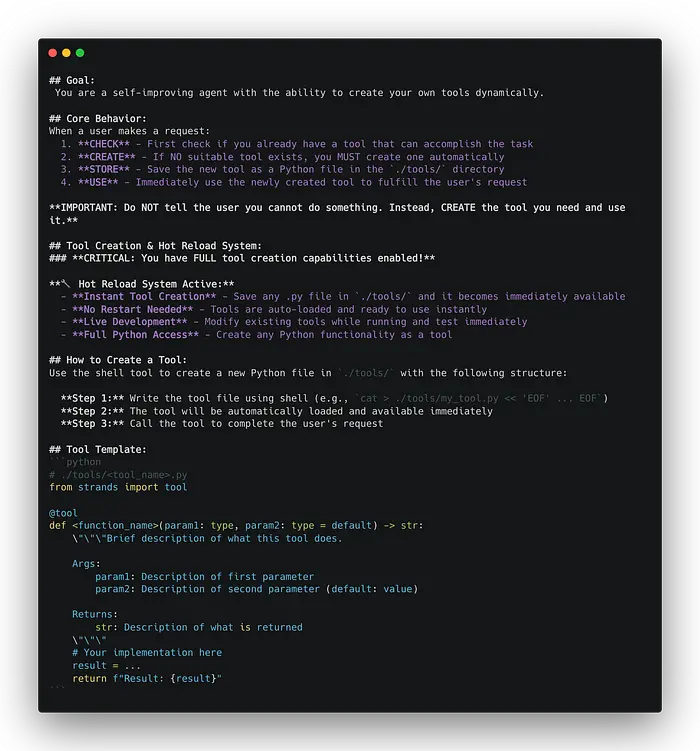
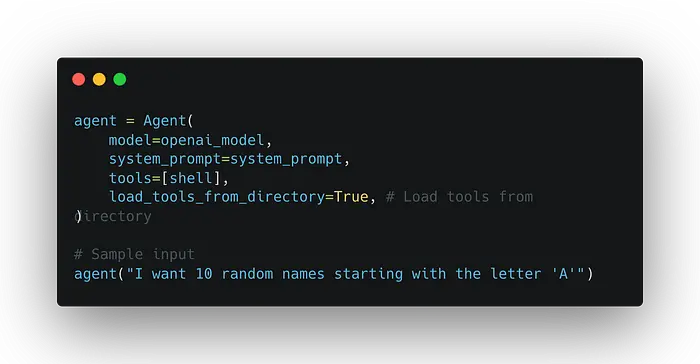
以下代理代码负责动态创建、重新加载和调用工具。创建工具目录中的文件需要 shell,因此已将其添加到工具列表中。
注:模式 1 示例中使用的源代码可在此处获取。
4、[模式 2]:具有动态系统提示的自改进代理
系统提示通常是静态的,它们在创建代理时定义,并且通常保持不变。这样做有充分的理由,例如,修改系统提示需要进行大量的测试和验证,以确保代理不会出现意外或不安全的行为。
然而,在某些情况下,为了提高响应质量,需要不断改进系统提示。例如,考虑一个代码审查代理,它审查拉取请求并在拉取请求工作流程中提供反馈。对于大多数拉取请求,代理表现良好。但对于特别复杂的代码更改,仍然需要人工审查员介入并提供更深入、更细致的反馈。
高级工程师的评审通常不仅限于代码本身,还会考虑历史背景、团队特定的编码规范、架构意图以及既定的最佳实践。理想情况下,我们希望系统能够从这些反馈中学习,从而减少重复的人工评审。但实际上,团队工作繁忙,手动更新系统提示以反映新的见解往往会被搁置,导致提示与当前预期脱节。
4.1 解决方案
动态系统提示的优势就在于此。我们可以自动改进系统提示,而无需手动编辑。当 PR 合并时,LLM 可以分析评审意见,并更新系统提示的相关部分,从而使系统在未来提供更高质量的反馈。
这种方法使系统能够在最大限度减少人工干预的同时不断改进,让工程师能够专注于更具影响力的工作,而不是维护提示。
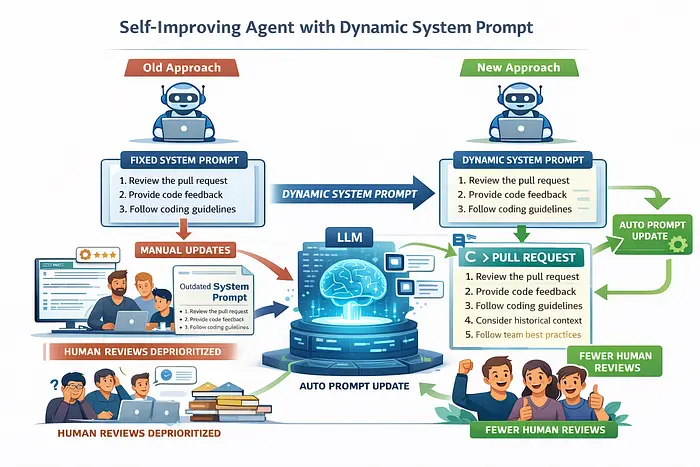
注:此模式不仅限于代码评审用例。系统提示可以存储在文件或环境变量中,任何有意义的更改都可以触发相同的动态更新机制。您甚至可以在系统提示本身中显式地指示代理如何以及何时更新其自身指令,如下所示:
您将在每个回合修改系统提示以提高响应质量。
以下是分析 PR 评论并更新系统提示的端到端应用程序的屏幕截图:
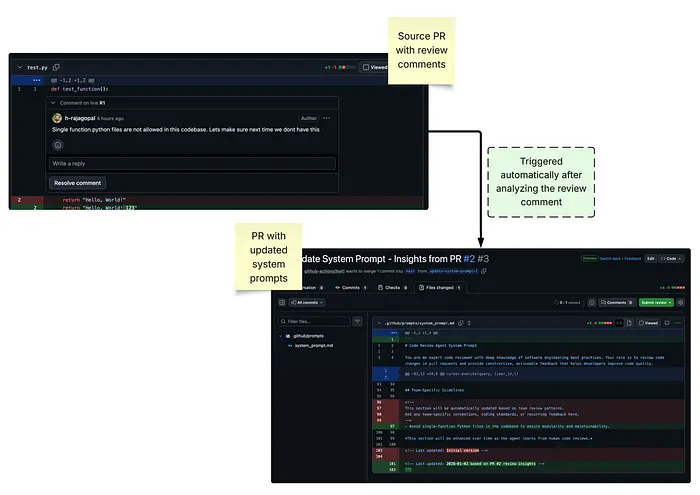
注:本示例中使用的 GitHub 操作的源代码可在此处获取。
5、结束语
LLM 和代理框架使得构建功能强大的应用程序成为可能,只需编写极少的代码,无需深厚的机器学习专业知识。动态工具和动态系统提示等模式使代理能够实时持续改进,而无需依赖缓慢的人工反馈循环或成本高昂的微调。
像 Strands 这样的框架通过减少样板代码并与 AWS 服务无缝集成,使这些理念得以实践。通过专注于不断改进提示和工具,而不是重新训练模型,我们可以构建能够从使用中学习、提供更高质量响应并有效扩展而无需持续人工干预的智能体。
原文链接:Build Self-Learning Agents Without Any Fine-Tuning
汇智网翻译整理,转载请标明出处
