Supermemory ASMR
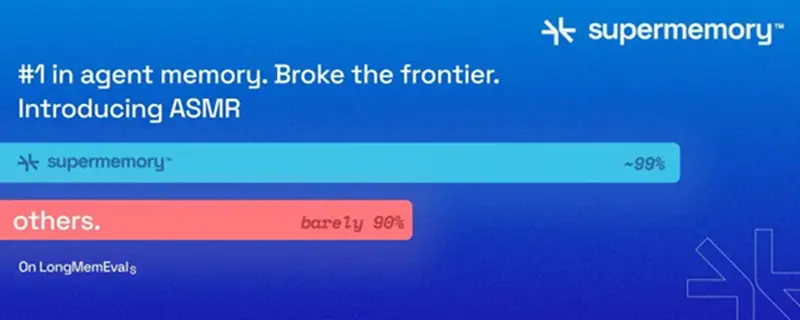
Supermemory再LongMemEval_s测试中取得了约99%的成绩,智能体记忆问题或许已经彻底解决。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
智能体记忆问题或许已经彻底解决。
几年后,数十亿个智能体将高度个性化,并根据每个用户的具体需求进行定制——它们会不断学习,并根据我们的一举一动进行进化。这就是我们多年来一直致力于人工智能记忆研究的原因。当我们最终完善这项技术时,会发生什么呢?
几个月前,我们发布了第一份研究报告,展示了 Supermemory 在 LongMemEval_s 测试中取得了约 85% 的成绩,这使我们领先于当时所有公开测试的记忆系统。今天,我们发布了新的成果:在 LongMemEval_s 测试中取得了约 99% 的成绩。
首先要明确的是:这尚未应用到我们主要的生产级 Supermemory 引擎中。本博客将介绍我们构建的一个全新的、高度实验性的智能体流程,旨在探索在不受核心生产环境限制的情况下,记忆检索和推理的极限究竟在哪里。经过几个月的研究,我们终于取得了成果。
以下是我们的成果。隆重推出我们的新技术:ASMR(智能体搜索和记忆检索)。
这项技术具有以下特点:
- 极易实现
- 无需向量数据库或嵌入,完全可在内存中运行
- 这意味着它可以嵌入到其他系统中,甚至包括机器人等设备。
1、简介
LongMemEval 是目前公开可用的最严格的长期记忆基准测试之一。与测试短上下文中简单检索的基准测试不同,LongMemEval 旨在模拟真实生产环境的复杂性:超过 11.5 万个词元的对话历史记录、相互矛盾的信息、跨越多个会话的事件,以及需要时间推理的问题。
大多数记忆系统得分低的原因通常是检索能力不足,而非推理能力。即使回忆率很高,如果检索过程中存在大量噪声,LLM 也可能难以有效利用这些信息。问题在于如何首先将正确的信息放入上下文窗口,而更难的是:如何判断检索到的信息何时过时,何时被更新的版本所取代。
为了解决这个问题,我们摒弃了传统的 RAG(随机数生成器),构建了一个多智能体协调的流程。
2、设置与实验架构
标准的向量搜索通常效果不错。然而,在处理密集的多会话时间数据时,它却显得力不从心。语义相似性匹配无法可靠地区分旧信息和新的更正。为了应对 LongMemEval 的复杂性,我们不得不从根本上重新设计数据摄取和检索流程,用主动智能体推理取代向量数学。
就像 ASMR 一样,这项技术简单而令人满意。
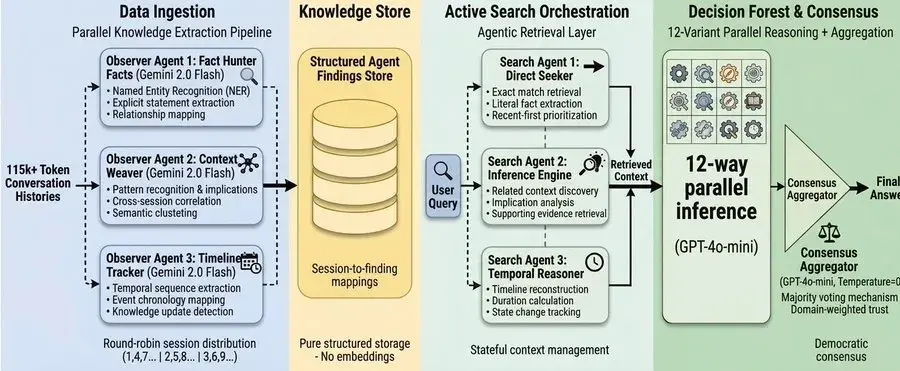
1) 并行编排与数据摄取(观察者代理)
我们没有采用分块和嵌入用户会话的方式,而是部署了一个代理编排器,该编排器利用了 3 个并行读取(观察)代理(由 Gemini 2.0 Flash 提供支持)。这些代理并发读取原始会话(例如,代理 1 读取会话 1、3 和 5;代理 2 读取会话 2、4 和 6)。
它们的目标是从六个维度提取目标知识:个人信息、偏好、事件、时间数据、更新和助手信息。这些结构化的结果会被原生存储,并映射到其对应的源会话。
2) 主动代理检索(搜索代理)
当收到问题时,我们不会查询向量数据库。而是部署 3 个并行搜索代理。这些代理会主动读取并分析已存储的结果,每个代理都有其特定的关注点:
- 代理 1:搜索直接事实和明确陈述。
- 代理 2:寻找相关上下文、社交线索和暗示。
- 代理 3:重建时间线和关系图。
协调器汇总所有三个搜索代理的发现,提取会话原文摘录以进行细节验证。这使得基于实际认知理解而非仅仅基于关键词或数学相似性的智能检索成为可能。
3) 代理协调的答题集成
一旦上下文构建完成,单个提示就无法处理 LongMemEval 中种类繁多的问题类型。有些问题需要您推断细节,而另一些问题则需要您精准定位。我们尝试了两种不同的代理答题流程:
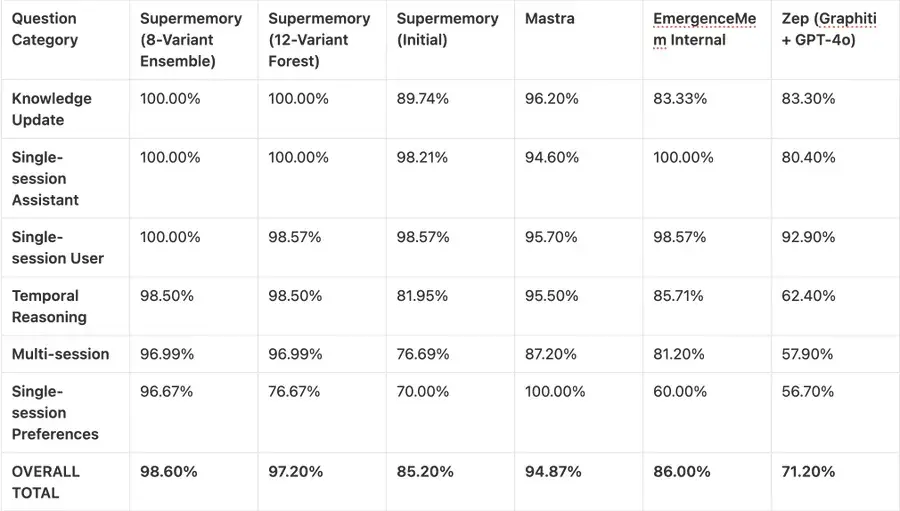
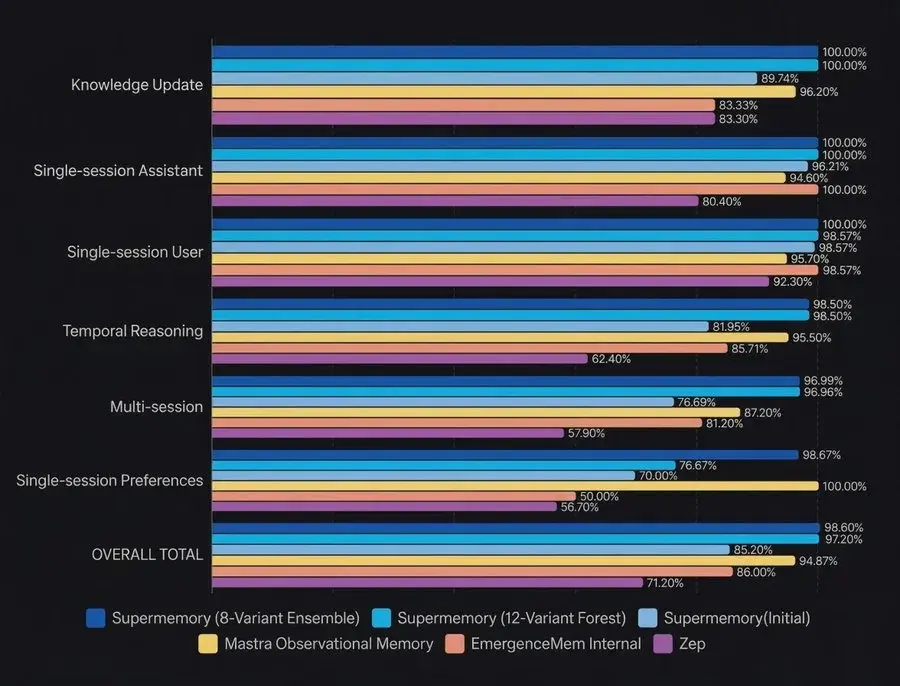
运行 1:8 种变体集成(准确率 98.60%)。在我们的第一种方法中,我们将检索到的上下文路由到 8 个高度专业化的提示变体,这些变体并行运行(例如,精确计数、时间专家、上下文深度挖掘)。每个变体独立评估上下文并生成答案。如果 8 条不同的推理路径中的任何一条成功得出正确答案,则该问题被判定为正确。这种并行多评判方法使我们达到了惊人的 98.60% 的总体准确率,完美地弥补了我们的盲点。
运行 2:12 变体决策森林(准确率 97.20%)为了测试一个能够生成答案的系统,我们进行了以下测试。为了获得单一且权威的答案,而非依赖多次独立尝试,我们将架构扩展为一个包含 12 个变体的决策森林。
在这个模型中,12 个高度专业化的智能体(由 GPT-4o-mini 驱动)独立地回答了提示问题。然后,我们引入了一个聚合器 LLM 作为最终评判者。聚合器使用多数投票、领域信任和冲突解决机制综合了这 12 个答案。这个单一的共识模型也实现了高达 97.20% 的准确率。
3、结果
这种实验性架构的性能从根本上改变了人工智能长期记忆的可能性。为了更好地理解这一成就的意义,以下是我们的实验性智能体流程与我们原始生产引擎以及整个行业整体的对比:
此外,该系统对智能体延迟的影响也比您预期的要小——不过,这正是我们一直在努力改进的地方。
4、我们的收获与展望
构建一个在生产级基准测试中准确率达到约 99% 的系统,让我们获得了一些关键的工程洞见:
智能体检索优于向量搜索:放弃向量嵌入而采用主动搜索智能体是最大的突破。主动搜索上下文的智能体消除了语义相似性陷阱,而语义相似性陷阱正是导致传统 RAG 在时间变化和更新时失效的原因。
并行处理至关重要:将信息摄取和检索工作负载分配到多个专用智能体(3 个读取智能体,3 个搜索智能体)上,显著提高了事实提取的速度和粒度。此外,由于每个智能体在提取时都可以专注于特定领域,因此也有助于避免冲突。
专业化优于泛化:通过专用专业智能体(例如计数器或细节提取器)路由上下文,其性能远超任何单一主控智能体。
由于这只是一个实验性的沙箱,而非我们核心的 Supermemory 引擎,我们希望 AI 社区能够从中学习并在此架构的基础上进行构建。
我们将很快开源这个实验性智能体流程的完整代码。记忆是一个不断演变的挑战,虽然这项研究突破了现有技术的极限,但我们已经在考虑如何将这些纯智能体检索技术应用到我们的核心生产环境中。
11 天后(4 月初),我们将发布并开源关于这个全新智能体记忆系统的所有信息。它将在公开平台上构建,供大家观看。我们乐在其中。
请访问我们的 GitHub 仓库,并密切关注发布信息 👀
智能体记忆现在(可能)已经是一个已解决的问题了吗?
原文链接:We broke the frontier in agent memory: Introducing ~99% SOTA memory system.
汇智网翻译整理,转载请标明出处
