文本扩散模型快速指南
文本扩散模型是大型语言模型(LLM),它使用扩散来"去噪"一组生成的token,而不是像自回归(AR)LLM那样一次预测一个下一个token

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
文本扩散模型是大型语言模型(LLM),它使用扩散来"去噪"一组生成的token,而不是像自回归(AR)LLM那样一次预测一个下一个token。扩散技术现在在图像生成模型(如Midjourney)中很常见,但迄今为止在语言模型中不太成功,主要是由于图像像素和文本之间数据类型的差异。
随着一些论文(如LLaDA和SEDD论文)展示了不同类型的文本扩散方法在某些情况下具有更快、更准确和更灵活的潜力,文本扩散模型最近受到更多关注。本文解释了文本扩散模型的架构差异、优势和潜在用例。
关键要点:
- 迄今为止最成功的文本扩散模型使用token掩码,而不是高斯噪声来并行迭代预测输出token。
- 文本扩散模型在大多数情况下不如自回归LLM有效,但在填空任务和需要大输出且吞吐量更快的任务中显示出一些前景。
- LLaDA和SEDD是两个最受欢迎的演示,LLaDA可在Hugging Face上下载。
1、扩散模型在架构上有何不同
文本扩散模型有三个主要类别。第一种在token级别嵌入上使用连续扩散(Diffusion-LM、Genie)。第二种将文本编码为压缩语义潜变量,这是抽象的、高层意义的表示。然后在该潜在空间中应用扩散,之后将潜变量解码回文本。第三种通过直接掩码token使用离散扩散(LLaDA、D3PM、SEDD)。这第三种范式目前在报告结果中表现最好,因此是这里的重点。
这种文本扩散方法与图像扩散模型不同,因为它使用token掩码作为噪声而不是高斯噪声。它仍然是实际的扩散,只是适应了离散数据(文本)。模型目前显示掩码对离散数据(如语言)更有效,因为它将文本视为分类数据,允许模型填空,而高斯噪声更适合连续数据(如图像像素)。
文本扩散模型的预训练步骤与自回归模型有一些相似之处。文本扩散模型在预训练期间也不需要标记数据。它们只需要大量原始文本数据。决定最大长度(即4096个token),并掩码一定百分比的token。在LLaDA预训练的情况下,它从[0,1]均匀采样t,然后以概率t独立掩码每个token。被选为掩码的token将被<MASK>token替换。对于一定百分比的训练传递,长度在1到4096之间随机采样并填充,以便模型暴露于所有大小的序列。对于LLaDA,它在序列长度4096进行训练,1%的预训练数据采样为从[1,4096]均匀分布的随机长度,以实现可变长度鲁棒性。
然后整个序列被输入基于transformer的模型,将所有输入嵌入向量转换为新的嵌入。然后对每个掩码token应用分类头来预测原始token,损失在掩码位置上平均交叉熵。在LLaDA中,预测器使用非因果注意力,因此它可以关注完整序列以进行掩码token预测。这种双向设置改变了相对于因果AR解码的计算行为,LLaDA还报告在其设置中使用普通多头注意力时与key-value(KV)缓存不兼容。作为参考,LLaDA 8B预训练计算报告约为0.13百万H800 GPU小时。
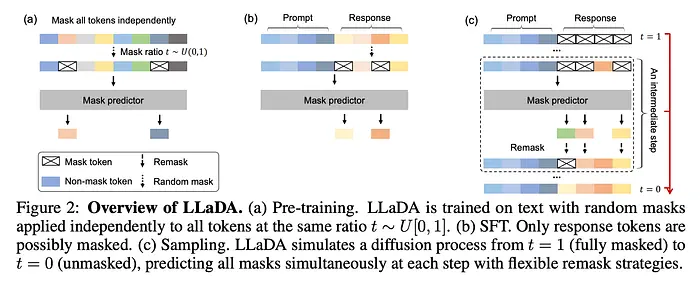
监督微调(SFT)模仿预训练。提示保持不变,仅在响应中随机掩码token,模型预测这些缺失的响应token,条件为提示和掩码响应。对于LLaDA 8B,监督微调报告在3个epoch的450万个提示-响应对上进行。
此时,模型可以预测掩码文本,但推理必须从仅有提示生成完整响应。为此,用提示初始化<MASK>token序列,并并行预测掩码token。LLaDA将总逆向采样步骤和初始响应长度都视为显式推理超参数,创建质量与速度的权衡。默认情况下它使用均匀分布的时间步;当从时间t步进到s时,它重新掩码预测token的预期分数s/t,在实践中它使用低置信度重新掩码而不是纯随机重新掩码。生成后,丢弃序列结束(EOS)token之后的token。
以前未掩码的token如果置信度低可以再次被掩码,允许更新以前生成的token。这是文本扩散模型相对于自回归模型的主要优势之一。
2、为什么要使用文本扩散?
文本扩散模型在三个方面显示出前景。
首先,与自回归模型相比,在某些设置中它们有可能为更长的文本提供更快的推理,因为它们不必一次预测单个token。它们通过多轮并行预测所有token。其次,在某些设置中它们也可能有更好的输出,因为token可以在字符串的任何位置替换。而如果自回归模型生成了错误的token,它无法回去更改。
最后,提示有更高层次的灵活性。提示不必只是前缀,就像自回归模型中那样。提示可以是整个文档,在文档中间缺失文本。这使其能够支持填空任务,如完成PDF表单和重写中间段落或代码块。
文本扩散模型不太可能完全取代自回归模型,因为它们通常需要更高的计算量,而且它们还没有被证明在更广泛的情况下优于自回归模型。扩散解码通常需要多次去噪迭代,这可能会根据步骤数和实现增加延迟。
在下面,你可以看到LLaDA 2.0 Flash在基准测试上与Qwen3-30B和Ling-flash-2.0得分相当,即使LLaDA 2.0-Flash比其他两个模型快得多,token每秒吞吐量超过380 TPS,而Ling-flash和Qwen3-30B分别为256和237,根据LLaDA论文。

3、结束语
文本扩散模型是自回归解码模型在特定工作流中的有意义的替代方案,特别是在填空和迭代细化有价值的地方。虽然它们尚未成为通用LLM任务的默认选择,但像LLaDA和SEDD这样的最新基于掩码的方法表明,当适应离散token时,扩散对于语言是实用的。
原文链接: What Are Text Diffusion Models? An Overview
汇智网翻译整理,转载请标明出处
