智能体的7个Harness组件
在本文中,我将向你解释可以使用哪 7 个 Harness 来构建可靠的 AI Agent。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
你的 Agent 刚刚在一个查询中对用户收费 38 美元。
不是因为它做了什么复杂的事情。而是因为它把同一份文档总结了 47 次,发现已经做过工作了,然后又做了一遍。没有崩溃。没有警报。只一个旋转的循环和一张不断增长的发票。
你检查模型日志。模型正在按训练的方式工作。
问题是包裹它的一切都没有对它已经做过的事情的记忆,没有状态文件,没有停止条件。系统没有办法说
"我们来过一次。"
这就是演示和生产 Agent 之间的差距。
在本文中,我将向你解释可以使用哪 7 个 Harness 来构建可靠的 AI Agent。
1、没有人警告你的差距
构建一个能工作一次的 Agent 确实很容易。调用 LLM,给它工具,让它循环。二十行 Python。你录制一个演示。看起来很干净。
然后你发布它。真实用户发送意外输入。
工具调用返回空。四十分钟后上下文满了。两个子 Agent 互相矛盾。模型决定无限重试某些东西。
演示中 invisible 的东西在生产中都变成失败。
差距不是模型质量。是 Harness 质量。
"没有 harness 的模型就像没有神经系统的 brain。思考在发生。其他的都不在。"
2、Agent = 模型 + Harness
这个框架改变了你构建的方式。
Agent = 模型 + Harness
模型 → 推理、语言、决策
Harness → 模型需要可靠地执行的一切
如果不是你,就是 Harness。
Harness 是包裹模型的每一行代码、每一个配置、每一个执行钩子,将文本生成器变成真正能工作东西。
模型决定做什么。Harness 确保它能安全地、重复地、大规模地做。
大多数工程师花 90% 的时间在模型上:更好的提示词、更新的模型、更多的例子。生产失败几乎总是出在他们跳过的 10% 上。
3、实际上重要的 7 个组件
3.1 控制循环
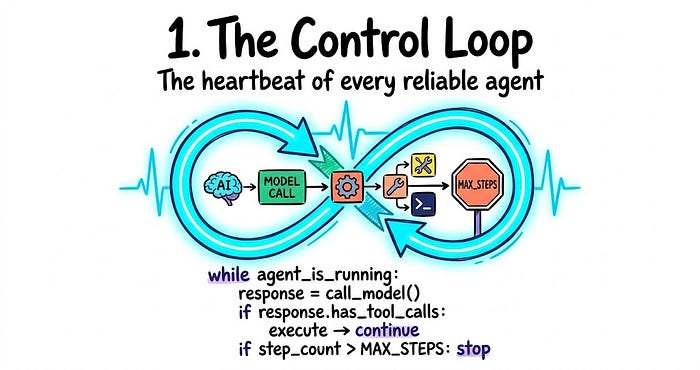
循环是 Agent 的心跳。没有它,你得到一个模型调用和一个响���。那不是 Agent,是聊天机器人。
循环运行模型,读取它返回的内容,执行任何工具调用,将结果附加回去,然后重复,直到模型停止调用工具或达到步骤上限。
while agent_is_running:
response = call_model(context)
if response.has_tool_calls:
results = execute_tools(response.tool_calls)
append_to_context(results)
continue
if response.is_final_answer:
return response.content
if step_count > MAX_STEPS:
return "Task incomplete. Max steps reached."
MAX_STEPS 行不是可选的。这是行为良好的 Agent 和 38 美元事件之间的区别。在写任何工具之前就构建它。
一个糟糕的循环比没有循环更糟糕。没有停止条件,没有状态跟踪,没有重复工具调用检测意味着模型可以在已经完成的任务上无限期地工作。
3.2 状态管理

模型默认是无状态的。每次 API 调用都是新的。没有 Harness 明确跟踪发生了什么,Agent 对它已经做过什么、什么成功了、或在哪里停止都没有记忆。
你需要两种状态:
会话状态 涵盖这次对话中发生的事情:对话历史、工具结果、当前步骤号。
持久状态 是会话结束后仍然存在的。长时间任务的进度。已经处理完的文件。
最简单的生产状态存储是一个 JSON 文件。跟踪任务进度、已处理的项目和当前状态。它可读、可调试、能承受进程重启,不需要基础设施。
{
"task_id": "refactor-auth-module",
"completed_files": ["auth.py", "middleware.py"],
"pending_files": ["routes.py", "tests/test_auth.py"],
"current_step": 3
}
对于跨大型代码库工作的编码 Agent,这个文件是将取得进展的 Agent 和每次循环都重新编辑同一文件的 Agent 分开的东西。Git 在上面添加版本控制:Agent 可以跟踪工作、回滚错误和分支实验。
3.3 记忆
状态跟踪 Agent 本会话做了什么。记忆是它在跨会话知道什么。
短期记忆是对话历史:每条消息、工具调用和结果都被附加到传递给模型的列表中。
这实现起来便宜疏于管理会很贵。 随着列表增长,token 成本攀升,性能在你达到硬限制之前就下降了。
长期记忆更难。一个帮你写代码的 Agent 应该记住你更喜欢显式错误处理而不是异常。一个处理客户支持的 Agent 应该知道某个特定客户上周有计费问题。这通常存储在语义检索的向量数据库中,或者当事实是特定的时候存储在结构化文件中。
一个好的生产模式:
会话开始:
1. 加载 AGENTS.md 或项目记忆文件 → 注入系统提示
2. 根据当前任务检索相关记忆 → 添加为上下文
会话期间:
3. 维护滚动对话历史
会话结束:
4. 总结关键学习 → 写入记忆存储
Harness 处理步骤 1、2 和 4。模型不管理自己的记忆。它不能。
没有长期记忆的 Agent 每次运行时都要重新学习上下文。用户会注意到。他们开始觉得 Agent 在忘记他们,尽管模型完全有能力。这种信任的侵蚀是 Harness 问题,不是模型问题。
3.4 工具和 bash 逃生舱

工具是将语言转化为行动的东西。没有它们,模型产生关于做事的文本。有了它们,它就做。
工具设计比工具数量更重要。你添加的每个工具都消耗上下文(它的描述在提示中)并增加模型选错工具的机会。三个描述优秀的工具会胜过十个描述模糊的工具。
一个好的工具描述回答三个问题:
- 这个工具实际上做什么?
- 什么时候应该使用它(不仅仅是什么时候可以)?
- 输出是什么样子以便我知道它工作了?
bash 逃生舱 是改变 Agent 能做什么的建筑move。相反pre-design每个可能的工具,你给 Agent 访问 bash 的权限,它自己即时编写工具。这就是 Claude Code 处理开放任务的方式。模型不局限于固定工具集。它设计它需要的。
权衡是安全, 这就是为什么一旦 bash 介入,沙箱隔离就变得不可或缺。
在本地运行 Agent 生成的代码是有风险的,单个环境不能扩展到并发工作。沙箱给 Agent saf,e 隔离的执行:运行代码、安装包、检查文件,所有这些都不接触你的主机系统。它们按需启动,并行任务展开,当工作完成时拆除。
配置良好的沙箱也带有正确的默认值: 语言运行时、git CLI、测试运行器、浏览器。这就是让 Agent 自我验证的原因:编写代码、运行测试、检查日志、修复失败。Harness 构建环境。模型使用它。
3.5 上下文管理
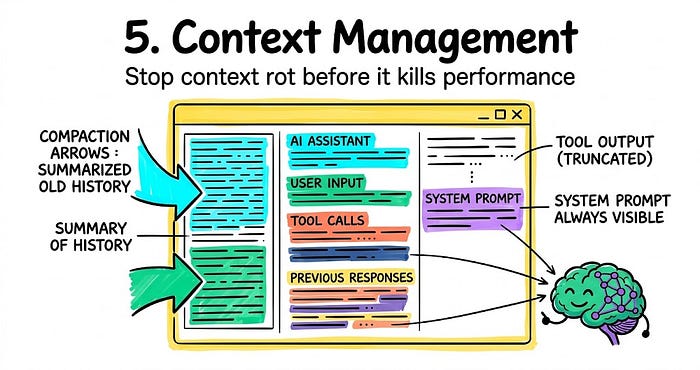
上下文腐坏是生产失败中最隐蔽的一种。
Agent 好好地运行了四十分钟。现在它忽略了自己的系统提示。没有崩溃。没有触发错误。上下文窗口满了,重要的指令被埋在中间,模型逐渐停止关注它们。
Harness 控制模型看到什么。模型不。
三种在生产中实际有效的模式:
压缩 通过总结旧的对话历史来处理填充的上下文窗口,而不是直接丢弃它。关键约束:永远不要压缩原始任务定义或系统提示。其他一切都可以商量。
工具输出截断 防止大型工具结果淹没上下文。从 fetch 调用返回的 50 页文档会吃掉你的整个预算并挤掉所有有用的东西。Harness 保留第一个和最后一个 N token,将完整输出存储到文件系统,如果模型需要更多,给它一个指针。
技能通过渐进式披露 解决启动问题。在会话开始时加载每个工具描述会使上下文膨胀在 Agent 做任何事情之前。技能按需加载它们的前言,当模型决定它需要那个能力时。具有 50 个延迟加载技能的 Agent 通常优于具有 10 个预先加载工具的 Agent,因为当真正开始工作时上下文负担更低。
生产规则:你的系统提示和任务定义始终可见。在你接触那些之前压缩历史。
3.6 规划
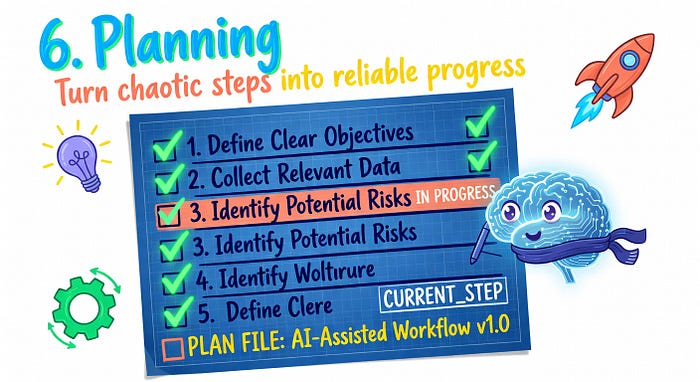
没有规划的模型会采取最明显的下一步,不管它是否是通向目标的连贯路径的一部分。
对于简单任务这可以。对于复杂的多步工作,它会产生不连贯:步骤乱序、步骤重复、步骤被跳过因为它们不明显。Agent 可以非常有能力但仍然失败任务,因为没有人给它一个执行的结构。
计划文件模式是最简单的修复,在生产中实际有效:
task: Migrate database schema from v1 to v2
steps:
- Backup current schema [ ]
- Generate migration script [ ]
- Run migration on staging [x]
- Verify data integrity [ ]
- Run migration on production [ ]
- Update documentation [ ]
current_step: 4
Harness 在每个循环开始时将这个注入上下文。Agent 在完成它们时勾选步骤。如果会话结束,计划仍然存在。当 Agent 恢复时,它确切知道它在哪里。
自我验证关闭循环。在完成每个步骤后,Agent 在继续之前验证结果。Harness 可以通过运行测试套件并反馈失败来强制这一点。编写迁移脚本并立即针对 staging 环境验证的 Agent 比编写后假设的 Agent 可靠得多。
Ralph Loop 值得知道名字。当 Agent 在长时间任务中完成其上下文窗口而没有达到目标时,Ralph Loop 通过钩子拦截那个出口,将原始目标注入新的上下文窗口,并强制继续。文件系统使这成为可能:每个新鲜上下文从上一次迭代读取状态。这就是真正的长视野自主性如何跨越多个上下文窗口工作。
3.7 错误处理
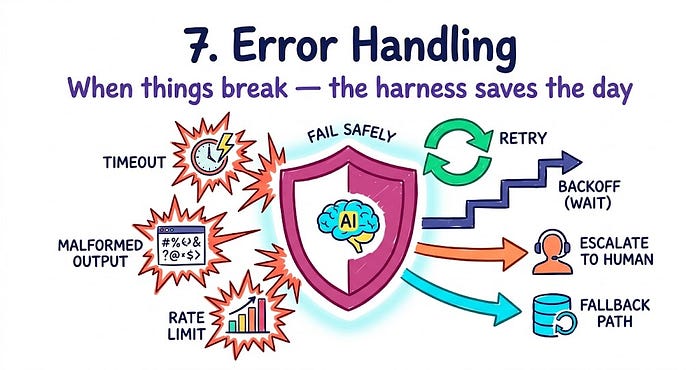
现实世界不配合。工具失败。API 速率受限。文件丢失。模型偶尔返回无法解析的输出。
没有显式错误处理,遇到这些情况的 Agent 有两个糟糕的选择:崩溃,或者 silently hallucinate around the error 就像没有发生一样。两者都是生产失败。
工具失败:
→ 可重试?(超时、速率限制)→ 指数退避
→ 数据错误?→ 尝试替代方法
→ 权限错误?→ 升级给人
模型输出格式错误:
→ 用明确格式提醒重试
→ 三次失败 → 退回到结构化输出强制
Agent 循环:
→ 步骤计数器触发 → 强制停止
→ 检测到重复的相同工具调用 → 中断并重定向
置信度低:
→ 标记等待异步人工审查
→ 不要在等待时阻止用户
升级路径是最重要的事情大多数 Harness 没有。知道何时停止并寻求帮助的 Agent 在生产中比总是试图完成的更有用。在发布之前构建明确的置信度阈值。
每个工具调用都应该有明确定义的失败行为。不是"优雅地处理错误。"具体:如果这返回空,做 X。如果错误,做 Y。如果超时,做 Z。
4、一个真实的追踪:生产 Agent 内部发生了什么
用户输入:"总结上个月关于欧盟 AI 监管的新闻报道的主要论点。"
步骤 1:计划创建
- 搜索欧盟监管新闻(最近 30 天)
- 阅读前 5 个结果
- 提取论点聚类
- 合成结构化摘要
步骤 2:状态检查
没有现有进度。步骤计数器初始化为 0。
步骤 3:搜索工具调用
返回 8 篇文章。Harness 将每个截断到 500 token → 添加到上下文。
步骤 4:fetch_url() 对前 5 个结果调用
完整文本存储到文件系统。Agent 获得摘要 + 文件指针。
步骤 5:上下文检查
60% 容量。尚不需要压缩。
步骤 6:综合
Agent 找到 3 个主要论点聚类 → 写入上下文。
步骤 7:验证
Agent 检查文章日期。两个是 45 天前的。标记它们。
用更严格的日期过滤器重新搜索。添加 2 篇新文章。
步骤 8:最终输出
带引用的结构化摘要。步骤计数器:9。MAX_STEPS:20。
步骤 9:状态更新
计划文件:所有步骤完成。
关键发现写入记忆存储供将来会话使用。
模型写了摘要。Harness 跟踪状态、管理上下文、强制验证、应用步骤限制、写入记忆。九步,没有人工干预,正确的输出。
这就是 Harness 实际做的。它不华丽。它是一个工具只工作一次和一个可靠地工作的区别。
5、会抓住你的边缘情况
尽管有工具还是会幻觉。 Agent 有搜索工具但使用它的训练数据而不是。当工具描述没有明确说明何时需要它,而不只是何时可用时,就会发生这种情况。修复:明确说明哪些问题需要在回答之前调用工具。
无限循环。 模型在得到空结果后用微小变化重试相同的工具。它把空解释为"再试一次"而不是"这种方法不对。"修复:检测重复的相同工具调用并用重定向提示中断。
上下文溢出。 Agent 前 30 分钟很棒。现在它忽略自己的指令。上下文慢慢填满,系统提示被埋,性能 invisible 地下降。修复:压缩策略和硬规则,任务定义始终出现在上下文开始和结束。
工具误用。 先写后读。删除而不是存档。当工具描述对先决条件模糊时,就会发生这些。修复:每个描述应该说什么时候不要使用工具,而是什么时候使用。
延迟爆炸。 一串合理的工具调用产生 45 秒响应。修复:独立的工具调用并发运行,而不是顺序运行。在接触模型之前测量哪些 Harness 选择增加延迟。
6、关于模型-Harness 耦合的事情
大多数工程师没有意识到这一点。
像 Claude Code 这样的现代编码 Agent 是在模型和 Harness 一起运行的情况下post-trained的。模型学习文件系统操作、bash 执行和规划,部分是因为它在奖励这些行为的 Harness 内部运行时被训练过。
这创造了一个有趣的副作用。
改变工具逻辑通常会降低模型性能,即使新逻辑是等价的。在特定 patch 格式上训练的模型如果交换格式会表现更差,即使两种格式在逻辑上是相同的。与 Harness 在环中训练创造了对那种 Harness 设计的某种过拟合。
实际后果: 开箱即用的 Harness 并不总是你的任务的最优选择。在 Terminal Bench 2.0 排行榜上,Opus 4.6 在 Claude Code 内的得分明显低于在自定义调优的 Harness 内的 Opus 4.6。相同的模型,不同的 Harness,可测量地不同的排名。
大多数团队根本没有触及 Harness 优化。那是真正的性能等待的地方。
7、什么时候不使用 Agent
Agent 是人们想承认的更经常错误的工具。
当相同的输入总是通过相同的步骤产生相同的输出时,使用确定性管道。硬编码它。更快、更便宜、比任何 Agent 都会做的更可靠。
当错误意味着删除生产数据或给错误的人发邮件时,使用明确的人为 gates。将 Agent 的建议与执行分开。Agent 会犯错误。确保那个错误不可逆。
当输入是结构化的且处理是基于规则的时候,完全跳过 Agent。给表单提交流工作流增加复杂性は过度工程,不是改进。
"Agent 并不是工作流的升级。这是不同类问题的不同工具。知道你拥有的是哪一个。"
最清楚的过度工程信号:你的工作流中的每一步都有一个正确的动作,路径是完全定义的,你想要 Agent 的主要原因是 Agent 看起来令人印象深刻。它们确实。它们也是确定性管道的过度杀伤。
8、如果你从零开始构建,从哪里开始
按这个顺序添加。每一层解决那个阶段最常见的失败。
- 带步骤限制的控制循环。 在任何工具之前。
MAX_STEPS = 10防止隔夜计费事件发生。 - 状态文件。 跟踪发生了什么和接下来会发生什么的 JSON。在每个循环开始时读取它。
- 工具集。 三到五个,描述良好的。只有当你发现特定差距时才添加更多。
- 错误处理。 在发布之前为每个工具定义失败行为。
- 上下文压缩。 当你在长会话中看到性能下降时添加这个,而不是之前。
- 记忆。 当用户注意到 Agent 忘记它应该知道的事情时添加这个。
- 规划。 当任务跨越多个会话或超过单个上下文窗口时添加这个。
这个顺序不是任意的。没有步骤 2 就跳到步骤 6,你会调试错误的东西。
9、最后的想法
关于构建良好的 Agent 的最好的事情不是它在一切顺利时做什么。
而是它在某些东西坏了时做什么。
随着模型改进,今天住在 Harness 中的一些东西将被原生吸收。模型将在不需要那么多提示支持的情况下变得更擅长规划 和自我验证。一些 Harness 复杂性确实会变得不必要。
但是围绕模型智能的工程、正确的工具、持久的状态、上下文管理、验证循环,这些使任何模型更有效,不管能力如何。这不是修补缺陷。这是系统设计。
模型每几个月变得更好。Harness 是你的去构建的。
"模型不是你的 Agent。Harness 是。相应地投资。"
原文链接:7 Agent Harness Components Every AI Developer Needs to Build Reliable AI Agent Systems
汇智网翻译整理,转载请标明出处
