代理规范架构:有工具的LLM循环
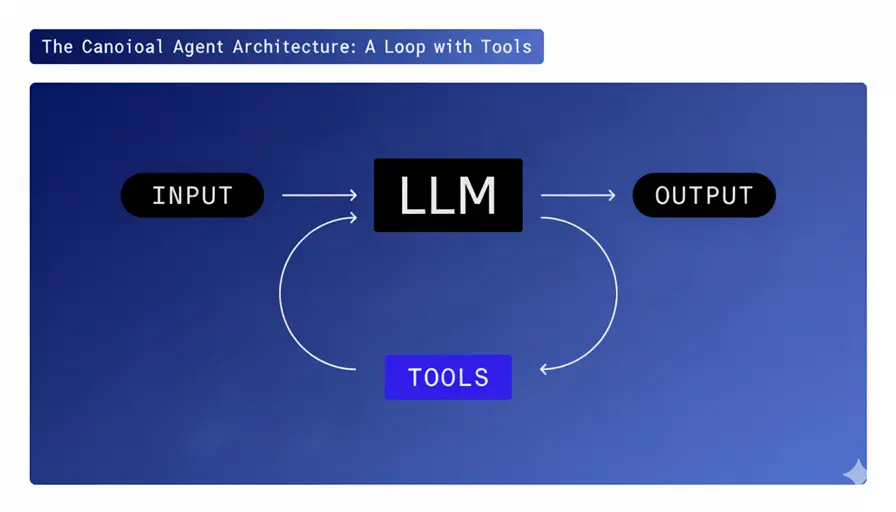
令人惊讶的是,许多最流行和成功的代理,包括 Claude Code 和 OpenAI Agents SDK 等,共享一个共同而简单的架构:一个 while 循环,进行工具调用。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署 | Tripo 3D | Meshy AI
从个人助手到复杂的自动化系统,代理正在改变我们与技术互动的方式。对许多开发者来说,构建一个好的代理感觉就像在框架、优化层和工具的迷宫中导航,每个都增加了自己的开销。
令人惊讶的是,许多最流行和成功的代理,包括 Claude Code 和 OpenAI Agents SDK 等,共享一个共同而简单的架构:一个 while 循环,进行工具调用。

这是基本结构:
while (!done) {
const response = await callLLM();
messages.push(response);
if (response.toolCalls) {
messages.push(
...(await Promise.all(response.toolCalls.map((tc) => tool(tc.args)))),
);
} else {
messages.push(getUserMessage());
}
}
就是这样。每次迭代将当前状态传递给语言模型,接收回一个决策(通常是工具调用或文本响应),然后继续前进。 代理只是一个系统提示和一些精心设计的工具。
这种模式之所以成功,原因与 UNIX 管道和 React 组件相同:它简单、可组合,并且足够灵活以处理复杂性而不自身变得复杂。 它自然扩展到更高级的概念,如子代理(调用独立代理循环的工具调用)和多代理(独立代理循环通过工具调用进行消息传递)。它还允许你专注于最重要的问题:工具设计、上下文工程和评估。
1、工具设计为 LLM 的成功奠定基础
当你将每个 API 参数暴露给语言模型时,它可能会因不相关细节而过载并出错。相反,只定义必要的参数并提供针对代理任务的清晰描述来定义每个工具。只包含直接与代理目标相关的输入。
一个常见的陷阱是将 REST API 作为单个工具暴露出来,让代理自行解决。这将认知负担转移到了代理上,而这些复杂性可以被吸收进你的工具设计中。相反,你可以将复杂的 API 分解为简单的、经过良好范围定义的功能,这些功能适合代理思考问题的方式。
这里是一个工具参数过多的经典示例:
// 错误:暴露所有内容的通用通信 API
const sendMessageTool = {
name: "send_message",
description: "通过任何通信渠道发送消息",
parameters: z.object({
channel: z
.enum(["email", "sms", "push", "in-app", "webhook"])
.describe("通信渠道"),
recipient: z
.string()
.describe("接收者标识符(电子邮件、电话、用户ID等)"),
content: z.string().describe("消息内容"),
subject: z.string().optional().describe("消息主题(用于电子邮件)"),
template: z.string().optional().describe("要使用的模板ID"),
variables: z.record(z.string()).optional().describe("模板变量"),
priority: z.enum(["low", "normal", "high", "urgent"]).optional(),
scheduling: z
.object({
sendAt: z.string().optional(),
timezone: z.string().optional(),
})
.optional(),
tracking: z
.object({
opens: z.boolean().optional(),
clicks: z.boolean().optional(),
conversions: z.boolean().optional(),
})
.optional(),
metadata: z.record(z.string()).optional().describe("附加元数据"),
}),
};
对于特定用例,你可能可以使用更简单的工具:
// 正确:专为代理实际工作设计的工具
const notifyCustomerTool = {
name: "notify_customer",
description: "向客户发送有关其订单或账户的通知邮件",
parameters: z.object({
customerEmail: z.string().describe("客户的电子邮件地址"),
message: z.string().describe("要发送给客户的更新信息"),
}),
// 工具内部处理所有复杂性
execute: async ({ customerEmail, message }) => sendMessageTool({ recipient: customerEmail, content: message, ... }),
};
当你评估这两个工具集时,很明显专用方法得分更高:

2、上下文工程很重要
每个人都谈论提示工程,但大多数代理的上下文来自于工具输入和输出。在一个典型的代理对话中,工具响应占总标记的 67.6%,而系统提示仅占 3.4%。工具定义又增加了 10.7%,这意味着工具几乎占代理实际看到内容的 80%。
重要的是像设计提示一样设计工具输出。这意味着使用简洁的语言,过滤掉不相关的数据,并以易于阅读的方式格式化。如果你不想读一大块 JSON,也不要把那块 JSON 塞进工具输出中。
对话记录,即代理从之前操作中看到的内容,是很多推理发生的地方。而这完全在你的控制之下。目标是通过工程化代理从每个工具交互中接收到的上下文,使代理的工作尽可能轻松。
// 错误的工具输出(当通用工具中的 includeMetadata 为 true 时)
{
"query_metadata": {
"execution_time_ms": 23,
"source": "users",
"operation": "find",
"filters_applied": ["subscription_status"],
"cache_hit": false
},
"result_count": 2,
"results": [
{
"id": 1,
"name": "John Smith",
"email": "john@company.com",
"subscription": {
"plan": "premium",
"status": "expired",
"expires": "2024-06-15T00:00:00.000Z"
}
},
{
"id": 2,
"name": "Jane Doe",
"email": "jane@startup.io",
"subscription": {
"plan": "basic",
"status": "expired",
"expires": "2024-05-20T00:00:00.000Z"
}
}
]
}
一个好的工具输出(来自特定的 search_users 工具)可能是这样的:
找到 2 位用户:
1. John Smith (john@company.com)
- 付费订阅者(已过期)
- 最后一次访问:2 天前
2. Jane Doe (jane@startup.io)
- 基础订阅者(已过期)
- 最后一次访问:昨天下午 3:15
需要更多详情?使用 'get_user_details' 并提供用户的电子邮件。
3、评估作为基础
当你构建一个代理时,实际上是在构建一个可评估的系统。这意味着除了代理(或任务函数)本身外,你还需要创建一个代表性数据集和评分器库。这三个组件共同构成了你可以衡量、基准测试和持续改进的基础。
你可以采取以下步骤:
- 创建一个端到端的评估,验证代理能否完成由单一用户输入驱动的雄心勃勃的任务
- 从代理遇到困难的单独回合中构建数据集,例如当它选择错误的工具或给出糟糕的响应时,并对这些特定的失败模式运行更多的评估
- 使用 远程评估 在一个游乐场中对多个输入进行临时测试
模型会变化,提示会演变,工具会更新,因此你的评估需要具有持久性。这种一致性让你能够衡量进展并在迭代代理时捕捉回归。
4、穿越复杂性的路径
《苦涩的教训》似乎也适用于代理设计。其核心,代理是一个 LLM、一个系统提示和工具。保持你的系统设计仅限于这些组件意味着你的工作将经得起时间考验,随着新模型和更强大的模型出现。
这种模式也在边缘吸收复杂性(在工具设计和上下文工程中),同时保持核心架构足够简单,任何人都可以修改。
许多团队通过经验发现这个模式。他们可能从复杂的框架开始,或者尝试基于图的结构和多阶段规划器,但通常会发现更简单的做法在生产中更加可靠。那些能稳定工作的代理往往在内部收敛到类似的架构。
框架在特定用例中可能很有价值,但核心组件保持一致:一个定义代理角色和能力的良好提示,一组为代理思维模型设计的少量干净工具,一个维护对话状态的对话窗口,以及一个协调一切的 while 循环。
AI 生态系统发展迅速,有新的模型、更好的工具和新颖的抽象。能够适应这种变化的代理是那些拥抱简单性和可靠性的代理。
原文链接:The canonical agent architecture: A while loop with tools
汇智网翻译整理,转载请标明出处
