企业智能体的未来,不在云端
距离为一个医疗客户上线只有三周时,他们的合规团队问了一个问题:"当这个RAG智能体运行时,我们的患者数据到底去了哪里?"

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
距离为一个医疗客户上线只有三周时,他们的合规团队问了一个问题:"当这个RAG智能体运行时,我们的患者数据到底去了哪里?"
诚实的答案是:OpenAI的服务器。可接受的答案是:不会离开他们的VPC。
这是一次技术栈替换的开始,我们已经在7个企业级RAG部署中重复了这个过程。每一次都始于同样的认识:生产级RAG不是一个LLM问题。它是一个基础设施、数据主权和编排问题,而典型的OpenAI优先教程并没有为此做好准备。
以下是我们替换了什么、过程中什么坏了,以及为什么我们的生产RAG智能体现在在Llama 3 + pgvector + LangGraph上部署得比在OpenAI上更快。
1、技术栈替换,逐层进行
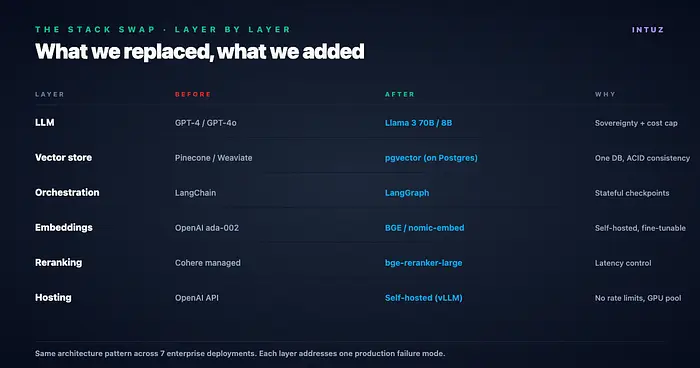
本文逐步介绍每次替换、为什么在生产环境中重要,以及大多数RAG教程搞错的5件事(这些错误让我们损失了数周时间才发现)。
2、为什么我们做出替换(3个致命问题)
2.1 数据主权不再是可选项
OpenAI的数据处理策略对原型来说没问题。对医疗记录、金融交易、法律合同或任何包含"数据不离开你的环境"这一措辞的合同来说,就不行了。
当我们的7个企业RAG客户中有4个在一个季度内问了同样的VPC问题时,我们不再把它当作边缘情况。受监管行业的生产RAG意味着模型、嵌入和向量存储都在客户边界内运行。
2.2 成本可预测性是虚构的
OpenAI的按token定价在原型规模看起来合理。在每天10万+查询的生产规模下,三件事会叠加:
- Token蔓延:生产智能体每次用户请求查询LLM 3-5次(重写、检索、评分、生成、验证),而不是一次
- 上下文膨胀:随着知识库增长,平均上下文长度增长
- 突发峰值:一个病毒式产品时刻会把4千美元/月的账单变成4万美元/月的账单,而且没有上限
自托管的Llama 3在预留实例GPU上将相同工作负载的成本限制在约2,800美元/月。节省是真实的,但可预测性是更大的收获。CFO们签字认可的是有上限的基础设施,而不是可变的token账单。
2.3 延迟控制在第95百分位很重要
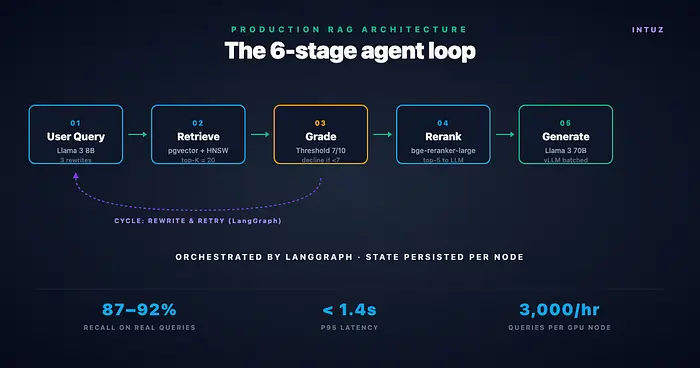
OpenAI的API平均很快。尾部(p95、p99)是RAG生产崩溃的地方。一个每次查询命中OpenAI 5次的检索增强聊天会在其中一个调用命中慢区域时随机花费8秒。使用vLLM批处理的自托管Llama 3给我们可预测的p95低于1.4秒,因为没有任何东西离开我们的基础设施。
这三个致命问题并不适用于每个团队。如果你在公共文档上发布面向公众的聊天机器人,OpenAI仍然是正确的选择。我们会在下面讨论何时不应该替换。但如果这三个致命问题中有任何一个对你来说是真实的,本文的其余部分就是操作手册。
3、我们替换了什么(新技术栈,逐层介绍)
3.1 LLM:GPT-4 → Llama 3
我们使用Llama 3 70B进行生产级推理(在我们的用例中相当于GPT-4的质量),使用Llama 3 8B进行查询重写、意图分类和重排序器推理(速度比深度更重要)。
70B模型在2块A100(80GB)GPU上运行,使用vLLM批处理。我们获得约85 tokens/秒的单流吞吐量,这大约可以维持每节点3,000个生产查询/小时。增加第二个节点用于高可用性,你就覆盖了任何中型企业负载。
对于大多数团队来说,8B模型就足够了。我们只在用例需要8B无法提供的细腻度时才默认使用70B。
3.2 向量存储:Pinecone → pgvector
这次替换让我们惊讶。Pinecone工作得很好。为什么要迁移?
两个原因:运维简洁性和事务一致性。
运维方面:我们的大多数企业客户已经在运行Postgres进行事务工作负载。在现有Postgres实例上添加pgvector意味着少一个供应商、少一个网络跳转、少一组凭据、少一个监控仪表板。已经写入Postgres的ETL管道不需要向向量供应商进行第二次同步。
一致性方面:当记录在事实来源数据库中更新时,嵌入在同一事务中更新。没有过期向量。没有向量存储与关系数据状态不同的竞态条件。
权衡是:在非常大的规模(1000万+向量且要求低于50ms延迟)下,pgvector比Pinecone慢。我们发现对于500万以下的向量,pgvector使用HNSW索引可以达到生产性能。超过这个规模,Pinecone或Weaviate仍然胜出。
3.3 编排:LangChain → LangGraph
LangChain适用于一次性RAG管道。在任何有状态的东西上,它在生产环境中就会崩溃。
我们在对顶级AI智能体框架的深度分析中详细讨论了这一点,简短版本是:LangGraph将每个节点视为检查点,使循环成为一等公民,为多智能体协调提供了监督者模式,并为每个节点强制执行显式终止条件。我们在替换后将RAG智能体调试时间从4小时减少到20分钟。在第一季度的4个客户智能体中,我们实现了零协调故障。
对于RAG来说,LangGraph的价值在于检索→评分→重写→检索循环变成了一个具有显式状态的图。当重写步骤出现故障时,你可以从那里重放。用LangChain是不行的。
3.4 嵌入:OpenAI ada → BGE / nomic
OpenAI的text-embedding-ada-002是好的。BGE-large-en和nomic-embed-text-v1在自托管于CPU节点时具有竞争力且零每次调用成本。对于大多数企业内容(技术文档、政策手册、客户支持数据),检索质量差异在误差范围内。自托管嵌入模型还意味着你可以在特定领域语料库上微调——这是OpenAI的API不允许的。
3.5 重排序:Cohere → bge-reranker-large
在top-K检索之后,你进行重排序,将最相关的块拉到顶部,然后再发送给LLM。Cohere的托管重排序器很优秀,但有与OpenAI相同的数据外流问题。bge-reranker-large在小型GPU节点上运行,在我们的用例中达到Cohere 90%+的质量。
4、大多数RAG教程搞错的5件事
这是我们在正确完成替换之前浪费最多时间的地方。如果你在搭建生产RAG,这些是我们在7次部署中累积的五条教训。
4.1 查询重写是不可协商的
用户不会输入干净的查询。他们输入:
"上个季度我们向物流客户收了多少钱"
这不会匹配你向量存储中的任何内容,因为没有哪个块字面上写着"物流客户"。一个生产RAG智能体在检索前将查询重写为3个语义变体:
- "Q3 [LogiCorp / FleetX / 等] 的发票金额"
- "物流行业客户账单历史"
- "运输账户季度收费"
然后对所有三个进行检索并合并结果。没有重写,你的检索召回率在实际查询中低于60%。有了重写,我们在相同评估集上达到87-92%的召回率。
4.2 Top-K检索不够——你需要相关性评分器
余弦相似度找到最近的块。它不会找到正确的块。如果你的用户问"退款政策",而你的top-5块都是关于"退货政策"的,因为嵌入在同一个邻域,你的LLM会臆造退款相关内容。
修复方案:相关性评分器。检索后,通过一个小的Llama 3 8B提示运行每个块,问:"这个块是否真正回答了用户的问题?评分0-10。"
设置一个阈值(我们用7)。如果没有通过的,智能体拒绝而不是臆造:"我在知识库中没有关于这个的信息。以下是我有的相关主题信息。"
仅这一项改动将我们的臆造率从12%降至2.4%。
4.3 嵌入不匹配会无声地杀死系统
当你更换嵌入模型(OpenAI ada → BGE → nomic)时,你现有的向量存储就无效了。向量在不同的几何空间中。用BGE编码的查询无法正确检索用ada编码的向量。
这听起来很明显。但这也是我们在第一次替换时花了2天才诊断出来的静默故障模式。系统技术上在工作——向量被返回了——但召回率下降了约40%。
修复方案:更换嵌入模型时重新嵌入整个语料库。为此做好计划。为此做预算。不要假设旧向量与新嵌入兼容。
4.4 集成悬崖:开发能工作,生产失败
经典的失败模式:你的RAG在开发环境中针对精选数据集完美运行。然后在生产中,真实数据到来,23%的源文档静默地破坏了管道。
包含扫描图像页面的PDF。包含合并单元格的CSV。包含嵌入对象的Word文档。包含宏渲染表格的Confluence页面。
修复方案:在每个摄取步骤进行优雅降级。如果解析器失败,记录带有足够调试上下文的失败,然后继续。不要让整个管道崩溃。我们添加了结构化摄取日志,生产数据完整性在3个客户部署中从67%提升到100%。
4.5 可观测性黑盒:当智能体静默失败时,调试需要4小时
LangChain将智能体状态隐藏在链中。当一个12步智能体的第7步失败时,我们无法重现它。我们能看到失败的输出,但看不到导致它的中间检索、评分、重写和决策。
LangGraph的逐节点检查点修复了这个问题。每个节点记录其输入、输出和状态。我们可以从任何节点重放任何故障。调试时间从4小时下降到20分钟。
如果你继续使用LangChain,你需要添加自定义追踪(LangSmith有帮助)。如果你替换到LangGraph,可观测性是内置的。
5、何时不应该做这个替换

这个技术栈并非普遍正确。我们在三种场景下建议反对替换:
场景:为什么OpenAI优先仍然胜出。面向公众的公共文档问答。没有主权问题,查询量低,快速上线更重要。每天少于50个生产查询。自托管开销超过OpenAI成本;不值得运维投入。没有ML/DevOps能力的团队。Llama 3 + vLLM + GPU管理需要真正的工程所有权
如果你在发布一个营销聊天机器人或公共文档问答,继续使用OpenAI。经济学和运维简洁性都偏向它。
6、生产RAG检查清单
在我们团队的任何RAG智能体上线之前,它必须通过这个12点检查清单:
- 查询重写层启用(最少3个变体)
- Top-K检索使用HNSW索引(典型k=20)
- 相关性评分器带阈值(默认7/10)
- 当没有块通过时使用拒绝而非臆造的回退策略
- 检索后LLM前的重排序器
- LangGraph编排带逐节点检查点
- 所有源文档的结构化摄取日志
- 嵌入模型版本控制(替换时重新嵌入)
- p95延迟预算已定义并在负载下测试
- 成本上限已定义(每查询和每月)
- 数据主权断言已验证(每个数据去了哪里?)
- 臆造率针对保留评估集测量,目标低于3%
这是我们每个客户参与运行的检查清单,与技术栈无关。Llama 3 + pgvector + LangGraph替换是我们用来持续满足检查清单的方案。

7、结束语
我们停止使用OpenAI不是因为OpenAI不好。我们停止是因为生产RAG需要主权、可预测性和可观测性,而这些不是OpenAI的工作来交付。
如果你现在正在搭建RAG智能体,问题不是"OpenAI还是Llama 3"。而是"你的技术栈通过了12点生产检查清单吗?"对照你当前的设置运行检查清单。未通过最多检查的项就是最快回报的替换。
我们的大多数客户在OpenAI上前6项检查通过,后6项失败。从OpenAI → Llama 3 + pgvector + LangGraph的替换修复了后半部分。
原文链接: Why We Stopped Using OpenAI for Our RAG Agents: A 2026 Production Stack Swap
汇智网翻译整理,转载请标明出处
