大语言模型维基模式
如果你一直对 RAG 感到沮丧,如果你觉得你的人工智能工具在对话结束的那一刻就忘记了一切,如果你因为维护太繁重而放弃了 Notion 数据库和 Obsidian 保险库;Karpathy 刚刚给了你让大语言模型做维护的蓝图。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
Andrej Karpathy,那个通过他的斯坦福课程教会世界神经网络如何工作的人,OpenAI 的联合创始人,特斯拉 Autopilot 视觉栈的构建者,离开 OpenAI(再次)后一直安静地发布开源黄金的人;他发布了一个 GitHub Gist。不是一个仓库。不是一个框架。不是一个有 47 个依赖项和 YAML 配置的库,让你质疑自己的职业选择。
一个 Gist。
一个 Markdown 文件。
而人工智能社区集体疯狂了。48 小时内获得 5000+ 星标。1,294 个分支。对于一个包含零代码的文档。
事情是这样的:该文档描述了一种叫做"大语言模型维基"的东西,这是一种构建个人知识库的模式,其中大语言模型不仅仅是检索信息;它编译、维护、交叉引用并持续丰富一个结构化的 Markdown 维基。每添加一个源,知识就会复合。没有什么会消失在聊天记录中。
人们称它为 RAG 杀手。
让我们深入探讨。
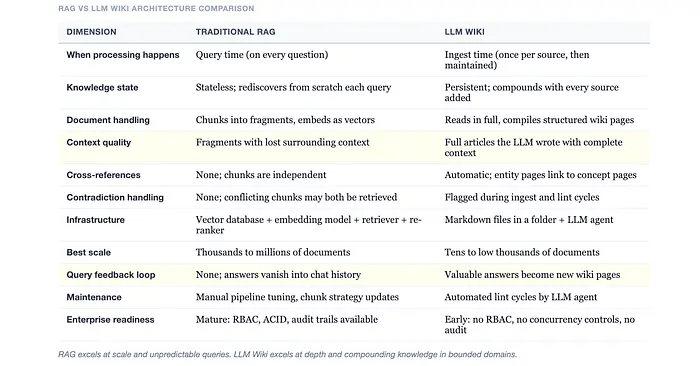
1、RAG 实际上做了什么(以及为什么人们感到厌倦)
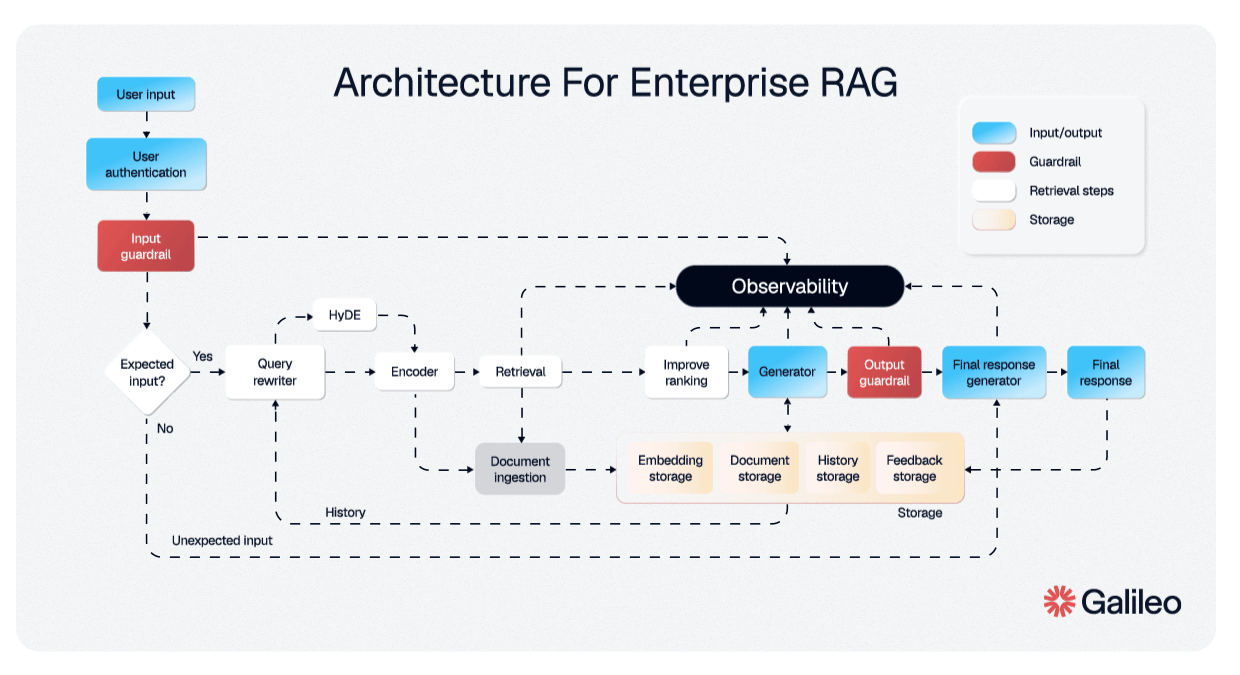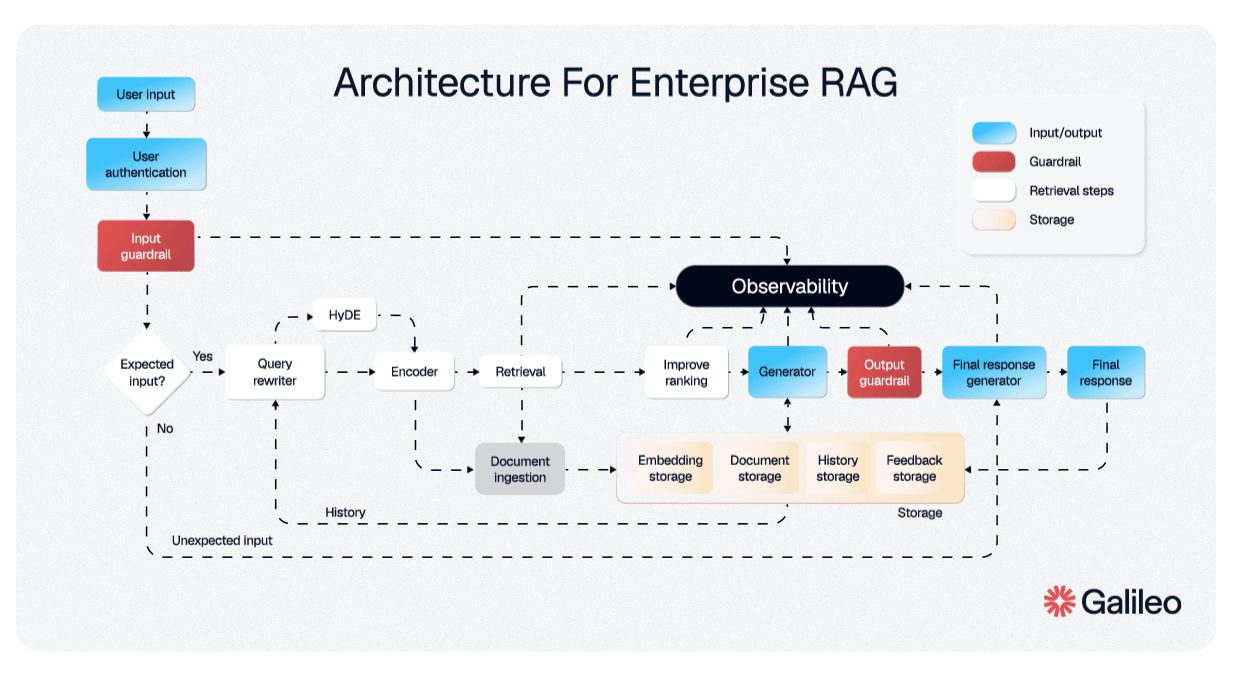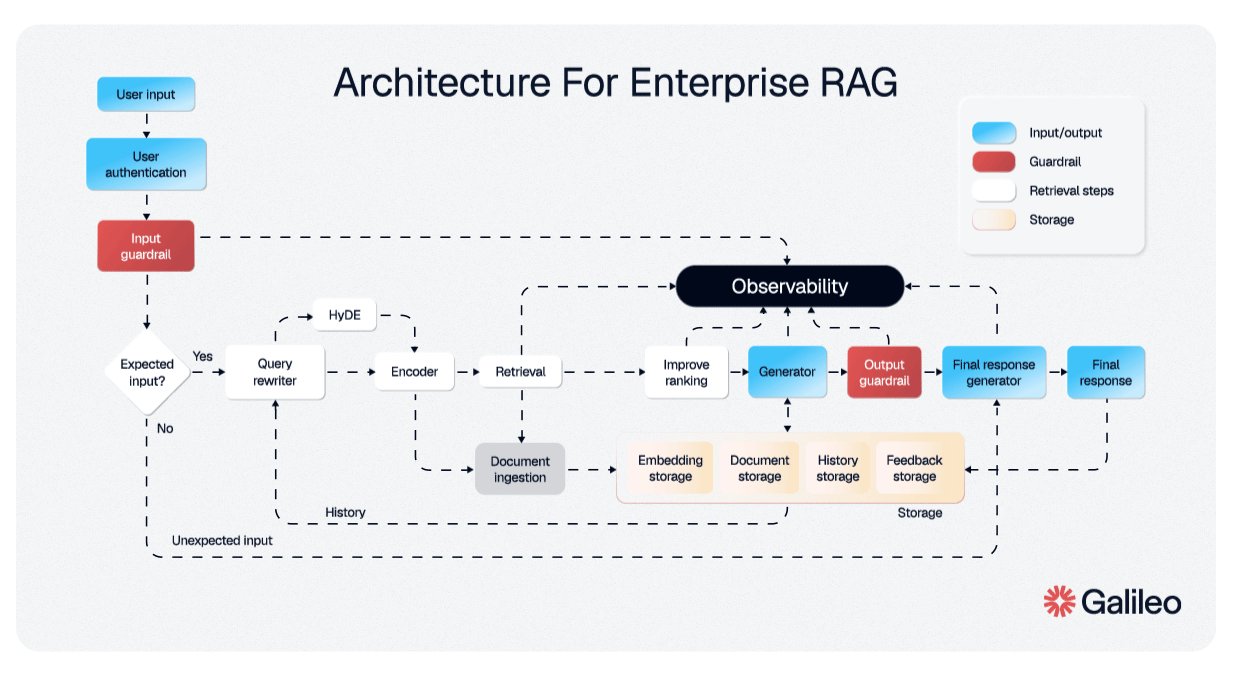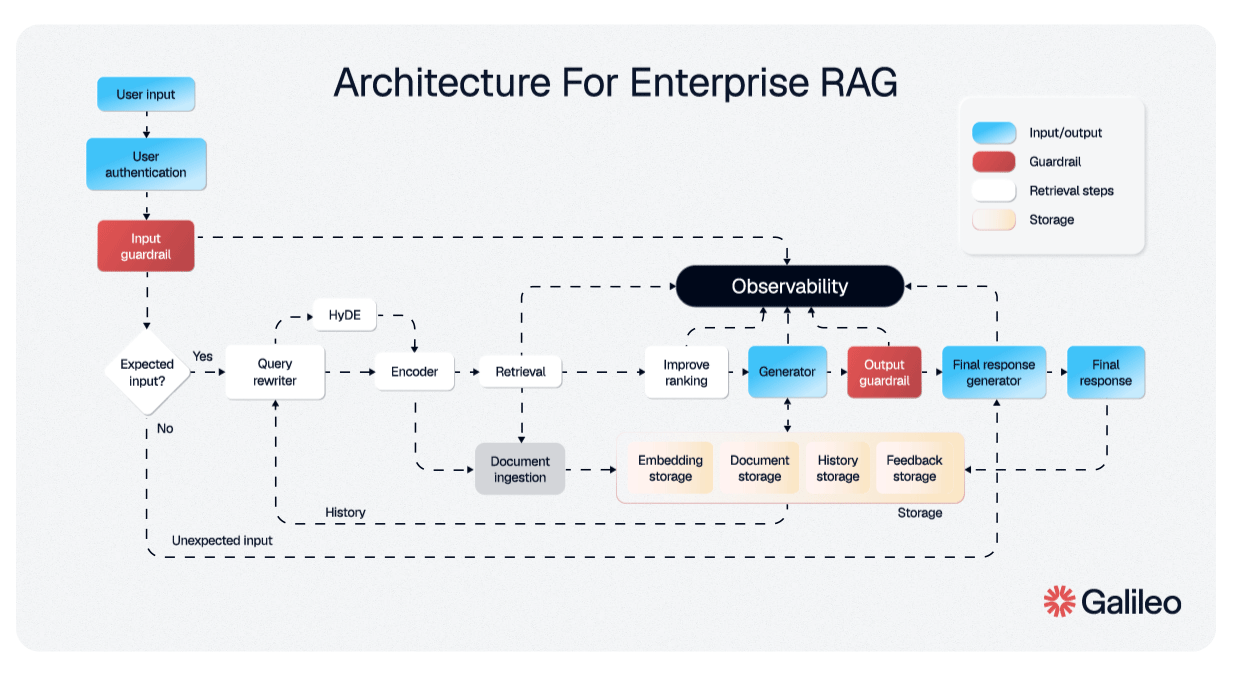
说实话,大多数人对 RAG 的体验是……令人失望的。以下是每个人都知道的流程:你上传文档。系统将它们分割成片段,有时是智能的,通常不是。这些片段被嵌入成向量并存储在数据库中。当你提出问题时,系统检索"最相似"的片段,将它们塞进上下文,然后大语言模型生成答案。
它有效。勉强有效。
问题很微妙但破坏性很大。每次查询都是重新开始。大语言模型每次都从头重新发现知识。没有积累。没有综合。没有记住它上次弄清楚的东西。明天问同样的问题,系统会进行相同的检索舞蹈,找到相同的片段(如果你幸运的话)或不同的片段(如果你不幸运的话)。
但是等等。
分块问题甚至比无状态性更糟糕。
当你将一篇 40 页的研究论文分割成 512 个 token 的片段时,你正在破坏上下文。一个关于 Transformer 注意力机制的段落与被定义符号的段落分离。一个结论引用了第 3 部分的发现,但第 3 部分在一个完全不同的片段中。嵌入可能会说"这是相关的",但大语言模型正在阅读一个没有开头也没有结尾的句子。
社区已经为此呐喊了一年多。复杂的分块策略、重叠窗口、分层检索、重新排序管道;RAG 生态系统已经变成了一个鲁布·戈德堡机器,为基本架构问题提供变通方案。
信息具有结构。分块破坏了这种结构。然后我们花费巨大的工程努力试图重建我们已经拥有的东西。
2、大语言模型维基登场
Karpathy 的洞见简单得优雅:如果大语言模型不在查询时检索原始文档会怎样?如果相反,它已经阅读了所有内容,提取了关键信息,将其组织成一个带有交叉引用和实体页面的结构化维基,并保持整个内容持续更新会怎样?
他使用的比喻很完美:Obsidian 是 IDE。大语言模型是程序员。维基是代码库。
你从不自己编写维基。
你提供源文件。你探索。你提问。大语言模型做所有繁重的工作。
该架构有三层,它们的简单性使这种模式强大:
第 1 层:原始源文件
这是你原始材料的不可变集合。文章、论文、转录稿、笔记、图片。它们进入 raw/ 目录并保持不变。将它们视为你的真相来源。
第 2 层:维基
这就是魔法发生的地方。大语言模型阅读原始源文件并生成结构化的 Markdown 文件:每个源文件的摘要、关键概念和实体的百科式文章、相关想法之间的交叉引用,以及编录所有内容的主索引。一个源文件可以同时触及 10 到 15 个维基页面。源文件之间的矛盾会被标记。综合反映了系统曾经消费过的所有内容。
第 3 层:模式
一个配置文档(Karpathy 使用 CLAUDE.md),告诉大语言模型智能体如何行为:维基的结构应该是什么样子、如何格式化页面、在摄取期间做什么、如何处理冲突。这是智能体运行的宪法。
这不是通常的 RAG 管道。差得远呢。
3、使其运作的三个操作
该系统运行在三个核心操作上,它们形成一个自我强化的循环,随着时间的推移变得更智能:
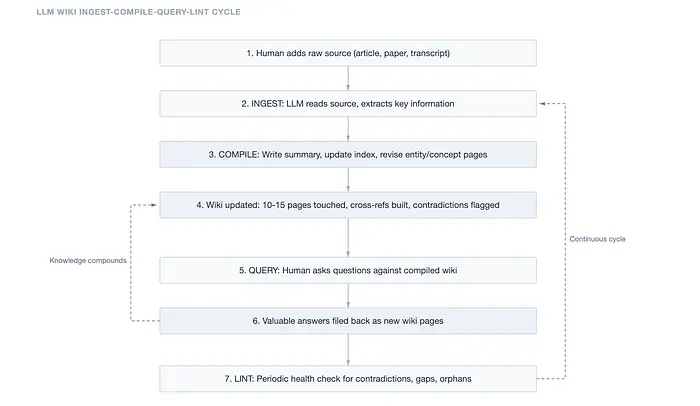
摄取是源文件进入系统的地方。
你将新文章、论文或转录稿放入原始集合中。大语言模型阅读它,讨论关键要点,编写摘要页面,更新主索引,然后——这是关键部分——修订整个维基中每个相关的实体和概念页面。一篇关于 Transformer 效率的单一论文可能会更新注意力机制、模型压缩、推理优化页面和三个不同的研究者实体页面。全部自动完成。全部交叉链接。
查询是你查询维基的方式。
你提出一个问题。大语言模型搜索维基索引,调出相关页面,并从结构化、预编译的知识中综合答案。不是片段。不是块。完整的、连贯的文章,它自己编写的。这就是真正有趣的地方:如果答案有价值,它就会成为一个新的维基页面。你的探索在知识库中复合。
再读一遍。
你的问题使维基更智能。
清理是维护周期。
定期地,大语言模型扫描整个维基以查找矛盾、过时的声明、孤立页面、缺失的概念和数据缺口。这是对你知识库的健康检查。维基会自我修复。
这是他离开 OpenAI 后的第一个研究模式,感觉真正具有范式转变意义。不是因为技术是新的;Markdown 文件和大语言模型智能体已经存在一段时间了。而是因为这种框架重新定义了我们如何思考人工智能的知识管理。
4、没有人谈论的 Vannevar Bush 联系

Karpathy 明确引用了 Vannevar Bush 1945 年的 Memex。对于那些不知道的人来说,Bush 是二战期间美国科学研究与发展办公室主任,他写了一篇预言性的文章"As We May Think",本质上描述了现代互联网、个人知识管理和超链接信息系统;比网络存在早 50 年。
Bush 的 Memex 是一个假设的设备,研究人员可以在其中存储他们所有的书籍、记录和通信,用"关联线索"链接跨文档的相关想法。愿景是一个个人的、策划的知识存储,随着你使用它而变得更有价值。
Bush 无法解决的问题是维护。
谁保持所有这些交叉引用更新?谁阅读每篇新论文并将其链接到每个相关的现有文档?谁在新发现与旧发现矛盾时进行标记?
人类。而人类会放弃维基。每一次都会。
但大语言模型不会感到无聊。它们不会忘记更新索引。它们不会因为周五下午而跳过交叉引用。在实践中杀死每个个人知识库的繁琐记账——这正是大语言模型独特擅长的事情。
Karpathy 不仅仅是构建了一个更好的 RAG。
他解决了 Bush 80 年前的维护问题。
如果生活如此简单,那么我们几十年前就已经实现了。但事实并非如此。我们需要大语言模型。
5、社区反应
围绕这个 gist 的讨论是……迷人的。该线程在几小时内就被剖析、辩论、分叉并在互联网上被 meme 化。反应分为不同的阵营。
5.1 爱好者认为这是知识工作的未来。
人们指出,维基的持久性、复合性解决了他们在传统 RAG 中遇到的准确问题:问同样的问题,得到不一致的答案,从不基于以前的见解进行构建。一些人已经在构建自己的实现。
一位开发者开源了 llmwiki.app,通过 MCP 直接连接到 Claude。另一位分享了一个他们一直在独立构建的"知识综合引擎"。有人 literally 将这个 gist 喂给 Hermes,让它当场开始为他们构建一个维基。
5.2 怀疑者称其为缓存层的重新发明。
他们有合理的观点。最尖锐的批评?Karpathy 并没有杀死 RAG;他只是重命名了缓存层。任何将大语言模型维基作为新正统推出的人将在六个月后艰难地重新发现去重和失效问题。
他们还指出,Claude Code 已经使用了其智能体搜索:模型现在擅长文件搜索,让它们用更多上下文搜索文件在许多用例中胜过分块文本搜索嵌入。
5.3 缺失的部分是复合记忆。
实用主义者可能有最有用的观点:RAG 对于它所做的事情来说很好。缺失的部分是复合记忆。策划的笔记加上引用加上定期刷新胜过每轮重新检索。RAG 和大语言模型维基不一定是敌人;它们是不同规模和用例的不同工具。
然后有一位怀疑者称其为"肤浅的炒作",认为每次启动 Claude Code 时,模型只有其训练知识,首先阅读技能和配置并不能让它变得更聪明一点。
嗯 :( 不。
这完全错过了重点。维基并没有让模型变得更聪明。它使知识变得可访问和结构化,以便模型可以有效地推理它。将 50 个随机文档块塞进上下文和给模型一个它自己编译的、组织良好的百科全书之间有着深刻的区别。
6、规模问题:100 篇文章不是企业级
这里我们需要诚实。
Karpathy 报告在大约 100 篇文章和大约 400,000 个词的规模上使用这种模式。在这个规模上,模型通过摘要和索引页面导航的能力绰绰有余。大语言模型可以阅读索引,识别相关页面,并将它们拉入上下文,因为现代上下文窗口足够大,可以同时容纳一个索引和几篇完整的文章。
在 10⁴、10⁵、10⁶ 文件时会发生什么
……一个具有合规要求、基于角色的访问控制和 50 个智能体同时写入的 PB 级企业知识库?
企业可扩展性差距是真实且有据可查的。
- 基于文件的 Markdown 系统没有 RBAC 机制;你无法限制智能体访问敏感数据类别。
- 没有 ACID 事务保证;多个同时写入同一维基页面的智能体会产生竞态条件。
- 对于受监管的行业,没有防篡改的审计跟踪。
- 扁平文件系统根本无法处理大规模数据的性能需求。
这不是对 Karpathy 工作的批评。他明确声明该文档有意抽象,描述的是一种模式而不是规定一种实现。
目录结构、模式约定和工具取决于你的领域。他知道这是一种个人知识武器,而不是企业平台。
但科技世界因兴奋而嗡嗡作响,而兴奋有一种将个人工具变成过度承诺的企业产品的方式。我们以前看过这部电影。
7、为什么"只是更好的 RAG"是错误的框架
社区中的一些人正在将其视为"仍然是 RAG,只是更好地排序"。
不完全是。
这种区别很重要,而且不仅仅是语义上的。传统 RAG 是在查询时进行检索操作。你搜索,你找到块,你生成。系统是无状态的。每次查询都是第一天。
大语言模型维基是在摄取时进行编译操作。当新源文件进入系统时,大语言模型不仅仅是索引它;它阅读它,理解它,将其整合到现有知识中,更新交叉引用,标记矛盾,并加强综合。知识在你提问之前就以结构化、预编译的形式存在。
这是搜索引擎和百科全书之间的区别。
Google(搜索)帮助你找到可能包含你答案的页面。维基百科(编译的知识)给你一篇结构化的文章,综合了来自数百个源文件的信息,带有交叉引用、引用和编辑监督。
RAG 是搜索引擎。
大语言模型维基是百科全书。
两者都有用。根本不同的架构解决根本不同的问题。
8、真正有意义的使用案例
Karpathy 概述了几个使用案例,有些比其他更有说服力:
个人知识管理是杀手级应用。
跟踪目标、健康指标、心理学笔记。将日记条目与研究报告一起归档。随着时间的推移构建你自己的结构化图景。这有效是因为规模本质上是个人化的(数百,而不是数百万文档),而且当只有一个用户,系统可以在几个月内学习其上下文时,复合知识的价值最高。
研究综合是这种模式真正胜过 RAG 的地方。
阅读论文数月,构建一个带有演变论文的综合维基,观察新发现如何修改或矛盾早期的发现;这是任何研究者的梦想工作流程。维基成为你外部化的理解,由一个永远不会忘记更新交叉引用的智能体维护。
阅读一本书出奇地强大。
在阅读时构建一个粉丝维基。人物、主题、情节线索,全部交叉引用,随着新章节揭示新信息而全部更新。对于密集的小说或复杂的非小说,这真的很有用。
业务运营经理
这就是它变得有趣的地方,也是可扩展性问题咬人的地方——但仍然可能非常有用。将 Slack 线程、会议转录稿和客户电话输入维基听起来令人难以置信。维基保持最新,因为人工智能做没人想做的维护工作。但这也是你需要 RBAC、审计跟踪和并发控制的地方。"酷模式"和"生产系统"之间的差距是企业工程的护城河。
9、Obsidian 赌注和工具生态系统
不是大小,而是生态系统。
Karpathy 选择 Obsidian 作为人机界面是深思熟虑且明智的。当某物已经存在时为什么要重新发明。(虽然我对 Obsidian 的闭源模式有异议……这个改天再说)。
Obsidian 的图谱视图揭示了维基中的结构模式:哪些概念是中心(高度连接),哪些是孤立(断开连接),维基在哪里有密集的知识集群以及在哪里有缺口。Dataview 插件支持对页面 frontmatter 进行动态查询。Marp 从维基内容生成幻灯片。而且因为维基只是文件夹中的 Markdown 文件,它自动成为一个具有完整版本历史的 git 仓库。
社区已经在以有趣的方向扩展这个。多个实现在几天内弹出:llmwiki.app、obsidian-wiki 集成,以及企业团队将该模式调整为半导体知识管理和服务交付文档。有人通过 MCP 服务器直接将其连接到 Claude,意味着你可以从你的人工智能智能体内部与你的维基对话。
工具融合是真实的。像 qmd 这样的本地混合搜索工具提供 BM25/向量搜索与大语言模型重新排序。Obsidian Web Clipper 一键将任何网络文章转换为 Markdown。从"我发现了一篇有趣的文章"到"我的维基已更新新知"的整个管道正在接近零摩擦。
但如果你正要基于 Obsidian 保险库中的 Markdown 文件构建你整个公司的知识基础设施……也许先深呼吸一下。
10、没有人讨论的微调终局
这就是事情变得非常疯狂的地方。
Karpathy 模式中最被低估的方面之一是他暗示的未来方向:从维基生成合成训练数据以微调模型。想想这意味着什么。你花费数月构建一个关于你领域的全面的、交叉引用的、标记矛盾的维基。然后你使用该维基生成训练示例。然后你在这些示例上微调一个模型。
知识从上下文窗口移动到模型权重。
你的个人维基成为个人模型。
逻辑的下一步是让模型用新知识重建其权重。维基是中间表示。编译的知识库是一个等待成为模型的数据集。
11、这对 RAG 行业意味着什么
让我们清楚一点。RAG 没有死。差得远呢。RAG 解决了大语言模型维基无法运作的规模上的真实问题:数百万文档、不可预测的查询、实时数据、具有严格安全要求的多租户企业部署。
但批评是有效的
对于个人知识库、研究项目、小团队维基以及数百到数千个文档规模的领域特定知识管理?大语言模型维基模式明显优于传统 RAG。
预编译的、结构化的知识完全消除了分块问题。
复合循环意味着系统随着使用而变得更好。维护自动化解决了杀死每个个人维基的放弃问题。
建立在向量数据库和检索管道上的 RAG 供应商应该关注。不是因为大语言模型维基今天取代了他们的企业产品。而是因为该模式暴露了该行业一直在回避的一个真相:
大多数 RAG 实现对于用户实际需要的来说过度工程化,对于用户实际想要的来说工程化不足。
用户不想要检索。他们想要知识。有区别。
创新从不让人失望。但有时它来自 GitHub 上的单个 Markdown 文件,而不是来自拥有 5000 万美元 B 轮融资的初创公司。
12、模式就是产品
这是我不断回到的。Karpathy 没有发布软件。他发布了一种模式。一个想法文件。一个你应该递给你大语言模型智能体并说"和我一起构建这个"的文档。实现细节被有意留得模糊,因为具体细节取决于你的领域、你的工具、你的规模、你的偏好。
有些人觉得这令人沮丧。他们想要一个可以克隆的仓库、一个可以运行的 docker-compose、一个可以注册的 SaaS。而那些正在到来;社区已经在构建它们。
但发布模式而不是产品的力量在于它邀请适应而不是采用。每个实现都会不同,因为每个知识领域都不同。半导体工程师的维基看起来不会像小说读者的维基,也不会看起来像初创公司创始人的维基。这就是重点。
这是我的观点。你应该做你感到舒服的事情。
但如果你一直对 RAG 感到沮丧,如果你觉得你的人工智能工具在对话结束的那一刻就忘记了一切,如果你因为维护太繁重而放弃了 Notion 数据库和 Obsidian 保险库;Karpathy 刚刚给了你让大语言模型做维护的蓝图。
人类策划源文件、指导分析、提出好问题、思考意义。
大语言模型处理其他一切。
Vannevar Bush 会感到骄傲。
原文链接:Andrej Karpathy Killed RAG. Or Did He? The LLM Wiki Pattern
汇智网翻译整理,转载请标明出处
