RMSNorm 背后的数学
RMSNorm本质上是在做一个赌注:激活向量的方向已经承载了所有有用信息,你只需要归一化幅度来保持训练稳定。
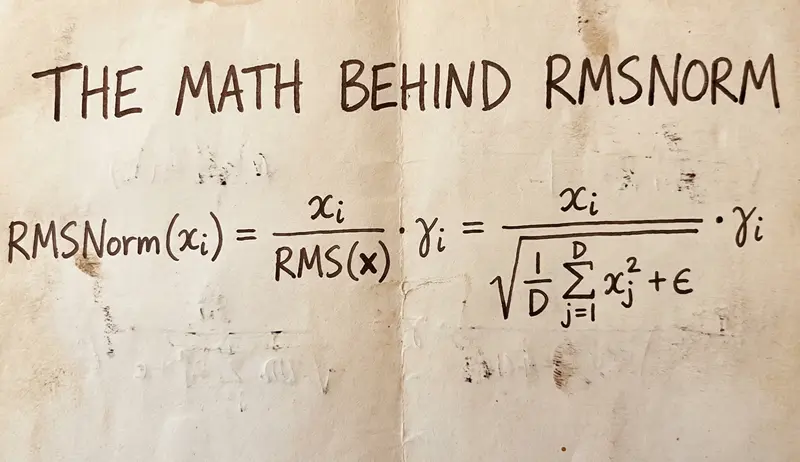
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
训练深度神经网络,本质上是一场与不稳定性的斗争。随着梯度通过反向传播在数百万或数十亿层中向后流动,它们可能消失殆尽(梯度消失问题)或爆炸成混乱(梯度爆炸问题)。每一层的激活以不可预测的方式移动和缩放,使优化器很难找到稳定的学习信号。这个问题由深度学习中一项最基本的技术来解决,即归一化,它有助于稳定梯度并使模型在训练期间显著更快地收敛。
当今神经网络中使用的三种最流行的归一化方法是批归一化(BN)、层归一化(LN)和RMS归一化(RMSNorm)。
在语言模型的训练中,层归一化被证明非常有效,因为与批归一化不同,它不依赖于一批样本来计算其统计量。但LayerNorm并不完美。2019年,Biao Zhang和Rico Sennrich发现了它的一些基本缺陷,最终催生了RMSNorm——当今几乎所有主要语言模型中使用的归一化方法,包括LLaMA、Mistral和Gemma。
在这篇文章中,我将逐步讲解层归一化的工作原理、它的缺陷是什么,以及RMSNorm如何用一个绝妙简单的想法来修复它们。但在深入之前,让我们先了解为什么我们需要归一化。
1、为什么需要归一化
在讨论使用哪种归一化之前,先了解为什么我们需要归一化会有所帮助。
随着神经网络的训练,每一层的激活分布在持续流入的新数据的作用下不断变化。第L层的权重更新,这改变了对第L+1层的输入,这意味着第L+1层现在必须不断适应一个移动的目标,它下游的每一层也是如此。这种现象被称为内部协变量偏移,它是2015年批归一化问世的主要推动问题之一。
除了协变量偏移,还有规模的根本问题。如果某一层的激活变得非常大,反向传播期间的梯度可能会爆炸。如果它们缩小到太小,梯度就会消失。无论哪种情况,训练都会变得极其缓慢或完全崩溃。
归一化通过强制激活在每一层保持在受控范围内来解决这两个问题,为优化器提供一个稳定、可预测的工作面。
2、为什么LayerNorm成为默认选择
层归一化由Ba等人在2016年提出,它通过改变归一化的维度来修改批归一化的核心思想。LayerNorm不是在批次上进行归一化(批归一化),而是在特征维度上进行归一化,这意味着每个单独的训练样本使用自己的统计量独立归一化。
这使得LayerNorm完全独立于批次大小,因此非常适合Transformer,且在训练和推理之间保持一致。
2.1 LayerNorm背后的数学
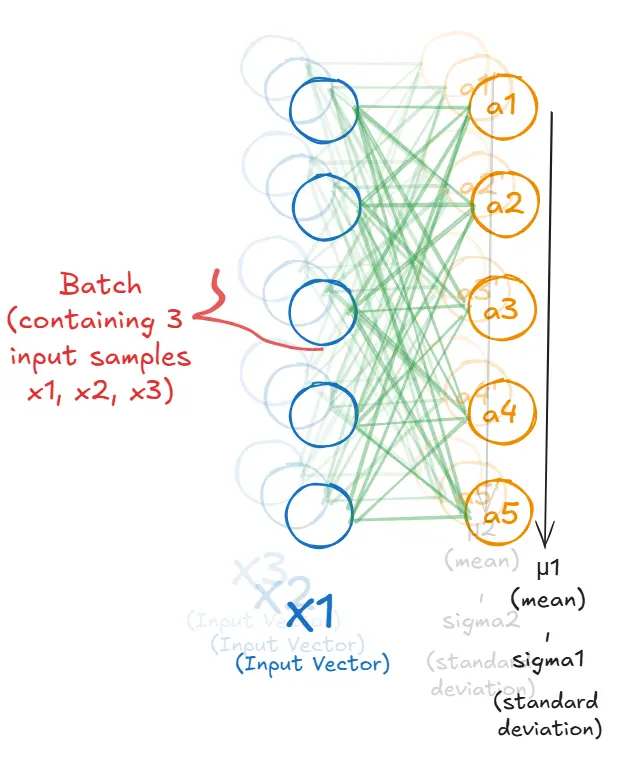
给定一个维度为d的输入向量x(某个层中单个token的隐藏表示),我们以d = 5为例。所以我们的输入向量有5个特征:a1, a2, a3, a4, a5。LayerNorm计算以下统计量:
步骤1:计算均值
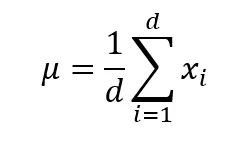
如图所示,均值是针对批次中的每个样本分别计算的。所以对于样本x1,均值为:
μ1 = (a1 + a2 + a3 + a4 + a5) / 5
类似地,μ2和μ3分别为样本x2和x3独立计算。这是与批归一化的关键区别:每个样本获得自己的统计量,从自己的特征中计算。
步骤2:计算方差
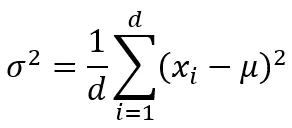
同样,方差为每个样本独立计算。对于样本x1,公式中的每个xᵢ被aᵢ替换(其中i从1到5),μ为μ1。对x2和x3用各自的均值重复相同的过程。
步骤3:归一化
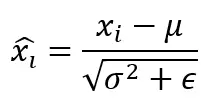
这里ε是一个非常小的常数(通常约为10⁻⁸),纯粹为了数值稳定性而添加,这样在方差极小的情况下我们永远不会意外地除以零。
步骤4:缩放和偏移
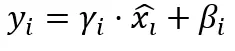
γ和β是可学习参数,两者都与输入向量x维度相同。γ被称为增益(或缩放),β被称为偏置(或偏移)。它们存在的原因很重要;归一化后,我们所有的激活被迫进入标准分布。但如果网络需要不同的缩放或均值来表示有意义的内容呢?γ和β给了网络撤销归一化的自由,如果任务需要的话。它们像任何其他权重一样在训练期间学习。
将所有内容组合起来,完整的LayerNorm操作可以简洁地写成:
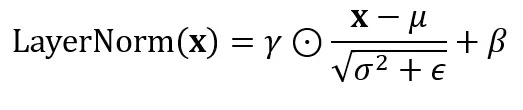
其中⊙表示逐元素乘法。看起来很密集,但它只是上面我们逐步讲解的四个步骤,压缩成了一个表达式。
2.2 LayerNorm实际上在做什么?
如果你剥离数学,LayerNorm对你的激活向量执行的是恰好两个不同的操作:
- 重新居中 — 它减去均值μ,移动整个分布使其以零为中心。
- 重新缩放 — 它除以标准差σ,压缩或拉伸分布使其具有单位方差。
然后,γ和β让网络在需要时偏离那个标准化分布。
这两个操作在每次前向传递中都会发生,对于每个token,在每一层。LayerNorm曾是标准,并且运行良好。但这个两步过程——重新居中和重新缩放——正是Biao Zhang在2019年审视并提出一个非常不舒服的问题的原因:我们真的需要这两个操作吗,还是其中一个做了所有真正的工作?
这个问题将我们引向了RMSNorm。
3、RMSNorm:没有均值的归一化
均方根归一化(RMSNorm)将LayerNorm精简到其本质要素:重新缩放。基本上,Biao Zhang观察到LayerNorm成功的主要原因在于其重新缩放特性,而非重新居中。他在论文中说得非常清楚:
"对LayerNorm成功的一个广为人知的解释是其重新居中和重新缩放不变性特性。前者使模型对输入和权重上的移位噪声不敏感,后者在输入和权重被随机缩放时保持输出表示完整。在本文中,我们假设重新缩放不变性是LayerNorm成功的原因,而非重新居中不变性。"
换句话说,重新居中所做的工作远比我们认为的要少。那为什么要为它付出计算成本呢?
3.1 RMSNorm背后的数学
给定一个维度为d的输入向量x,RMSNorm计算以下内容:
步骤1:计算RMS
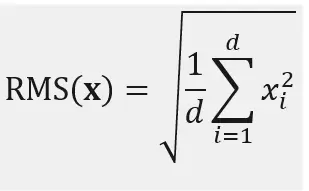
注意缺少了什么:没有任何均值减法。我们只是直接计算平方值的平均值,而不是均值居中的平方值的平均值。这是均方根,不是标准差。这一个差异就是整个想法。
步骤2:归一化
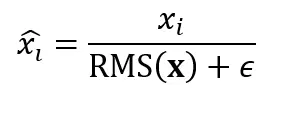
步骤3:缩放
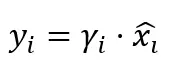
注意这里没有β项。由于我们不重新居中分布,所以不需要可学习的偏移参数。唯一的可学习参数是增益向量γ,与LayerNorm相比参数数量恰好减少了一半。
将所有内容组合起来,完整的RMSNorm操作为:
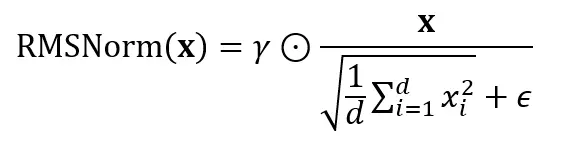
3.2 几何直觉
这里有一种清晰的方式来思考这两种归一化方法真正在做什么。
想象你的激活向量x是d维空间中的一个箭头。它有一个方向——哪些特征相对于其他特征是活跃的,以及一个幅度——表示整体激活有多大。
- LayerNorm既重新定位箭头(减去均值,将其质心移动到原点)又重新缩放它(除以标准差,归一化其分布)。
- RMSNorm只重新缩放箭头(除以RMS,归一化其整体幅度)。它完全不做相对位置调整。
RMSNorm本质上是在做一个赌注:激活向量的方向已经承载了所有有用信息,你只需要归一化幅度来保持训练稳定。箭头居中在哪里不重要,只有它有多长才重要。
正如原始论文中的实验所表明的,这个赌注是成功的。
4、RMSNorm在Transformer中到底存在于哪里?
在原始的Attention Is All You Need Transformer中,LayerNorm被应用于注意力或前馈子层之后(Post-LN)。现代Transformer绝大多数使用Pre-LN(或Pre-RMSNorm),在输入进入子层之前对其进行归一化,并有残差连接绕过归一化。
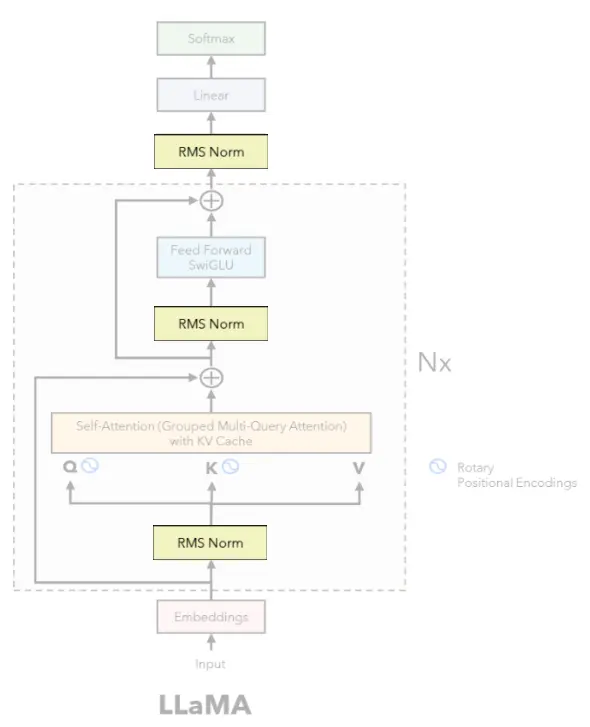
这种Pre-Norm安排,加上RMSNorm,正是你在LLaMA 2、LLaMA 3、Mistral、Gemma和大多数其他现代开源语言模型中看到的。
5、RMSNorm实现(PyTorch)
现在让我们看看这如何干净地转化为代码。以下是RMSNorm在PyTorch中的实现,我在我的LLM构建中使用:
class RMSNorm(nn.Module):
def __init__(self,dim:int, eps: float = 1e-6):
super().__init__()
self.eps = eps
## The gamma parameter
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x: torch.Tensor):
# (B,seq_len,dim) * (B,seq_len,1) -> (b,seq_len,dim)
# rsqrt: 1/sqrt(x)
return x * torch.rsqrt(x.pow(2).mean(-1,keepdim=True) + self.eps)
def forward(self, x: torch.Tensor):
# (dim) * (b,seq_len,dim) => (b,seq_len,dim)
return self.weight * self._norm(x.float()).type_as(x) #
__init__方法只初始化两样东西,eps(公式中的ε,用于数值稳定性)和self.weight(我们的可学习γ,初始化为1)。注意没有偏置参数,正如我们讨论的,RMSNorm没有β。
真正的工作在_norm中完成。让我们从左到右分解:
x.pow(2)→ 对x的每个元素求平方,得到x².mean(-1, keepdim=True)→ 在最后一个维度(特征维度d)上取均值,得到x²的均值。keepdim=True保持形状兼容以便广播。+ self.eps→ 添加ε用于数值稳定性torch.rsqrt(...)→ 计算1/√(mean(x²) + ε),即恰好1/RMS(x)x * torch.rsqrt(...)→ 将x乘以1/RMS(x),即归一化步骤
在forward方法中,self.weight * self._norm(x)只是最终的缩放步骤,将归一化后的输出与我们的可学习γ进行逐元素乘法。末尾的.type_as(x)确保输出dtype与输入匹配,因为我们在_norm内部转换为float以提高数值精度。
整个RMSNorm操作,我们花了好几段从数学上理解的,最终归结为几行有意义的代码。没有均值计算,没有偏移参数,没有额外开销。这种简洁性正是关键所在。
原文链接: From LayerNorm to RMSNorm: The Math behind Smarter Normalization
汇智网翻译整理,转载请标明出处
