你的智能体技术栈中缺失的层
因为实际情况是这样的:当一个智能体在 200 步工作流的第 23 步做出错误决策时,你需要回溯到第 22 步,查看它当时的上下文、可用的工具、它选择了什么以及它拒绝了什么。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
每个人都在构建能够行动的智能体,却没有人构建能够记住自己行动原因的智能体。
你的智能体编写了代码,发布了功能,部署了修复程序。三天后,生产环境中出现了问题,你问了一个工程师最容易问的问题:它为什么会这样做?而系统却一无所知。
没有决策历史,没有推理过程,没有事件时钟。
上下文窗口关闭了,推理过程也消失了。现在,你只能对着一个幽灵调试。
这才是当前智能体栈的真正缺陷,并非模型质量,并非工具调用,也并非思维导图提示。真正的缺陷在于,根据 Gartner 的预测,到 2027 年底,40% 的智能体 AI 项目将被取消。而首要原因并非模型本身不好,而是没有人构建模型底层的记忆层。
加州大学伯克利分校研究了 7 个框架下的 1600 个多智能体跟踪数据,发现失败率在 41% 到 87% 之间。麻省理工学院的 NANDA 项目发现,95% 的企业级 GenAI 试点项目对损益表 (P&L) 没有产生任何可衡量的影响。他们发现的根本原因是所谓的“学习差距”。这些系统无法保留反馈、无法适应上下文,也无法随着时间的推移而改进。
模型本身没有问题,问题在于其周围的基础设施缺失。

1、推理消散问题
以下是生产环境中智能体系统实际发生的情况:
一个智能体需要 50 个步骤来解决客户问题。每个步骤都涉及上下文:它检索了什么、做出了什么决定、丢弃了什么,以及为什么选择路径 A 而不是路径 B。这些推理信息只在上下文窗口打开期间存在。
然后窗口关闭,会话结束,推理信息消失。
剩下的只有输出结果:PR(请求)、工单更新、部署。但产生该决策的决策链呢?消失了。永久消失了。
这不是日志记录的问题。你的可观测性栈记录了哪些服务被调用以及它们耗时多久。但它无法记录提示信息的内容、决策时可用的工具、为什么选择某个操作而不是其他操作,或者代理在每个分支点的置信度是多少。
LangChain 的说法很精辟:在传统软件中,代码是应用程序的文档。在 AI 代理中,跟踪就是你的文档。当决策逻辑从代码库转移到模型时,你的真理来源也从代码转移到了跟踪。
然而,大多数团队并没有捕获这些跟踪。他们捕获的是日志。日志和跟踪之间的区别在于,前者只知道发生了什么,而后者只知道为什么发生了。
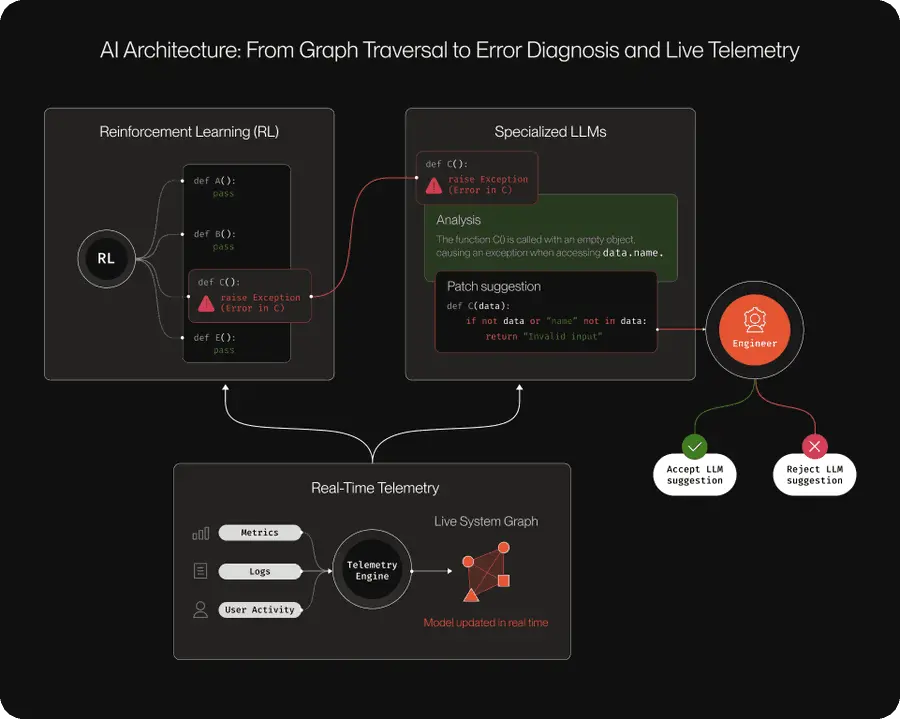
2、跟踪架构并非日志记录
这种区别至关重要,因此值得明确阐述。
日志记录是诊断性的。它告诉你事后发生了什么。它是短暂的。会被轮换、压缩、删除。它的重要性不及系统的实际状态。关键在于,你无法仅凭日志重建系统状态。日志存在缺失,它们只能说是“基本准确”。
基于 Martin Fowler 二十年前提出的事件溯源模式构建的追踪架构,从根本上来说截然不同。每一次状态变化都被捕获为一个不可变的事件。事件是永久性的,并且只能追加。状态源自事件,而不是单独存储。由于事件是真理的来源,因此你可以重建系统在任何时间点的完整状态。
对于传统软件而言,这是一种强大的模式,尤其适用于金融系统和审计跟踪。对于智能体系统而言,这则是一项生存必需。
因为实际情况是这样的:当一个智能体在 200 步工作流的第 23 步做出错误决策时,你需要回溯到第 22 步,查看它当时的上下文、可用的工具、它选择了什么以及它拒绝了什么。传统的日志记录无法做到这一点,而追踪架构可以。
这就是 Akka 工程团队所说的智能体 AI 的骨干。事件溯源是所有关键特性的核心支撑:内存、检索、多智能体协调、工具集成。没有底层事件存储,就无法实现持久的智能体内存;没有决策回放,就无法进行智能体调试;没有能够捕捉推理过程(而不仅仅是结果)的训练信号,就无法改进智能体。
规则是:如果你的智能体系统无法回答其历史上任何决策的“为什么这样做?”,那么你拥有的就不是一个真正的智能体系统,而是一个昂贵的自动补全工具,却没有飞行记录仪。
3、如果没有事件溯源,调试会是什么样子?
让我举个例子。
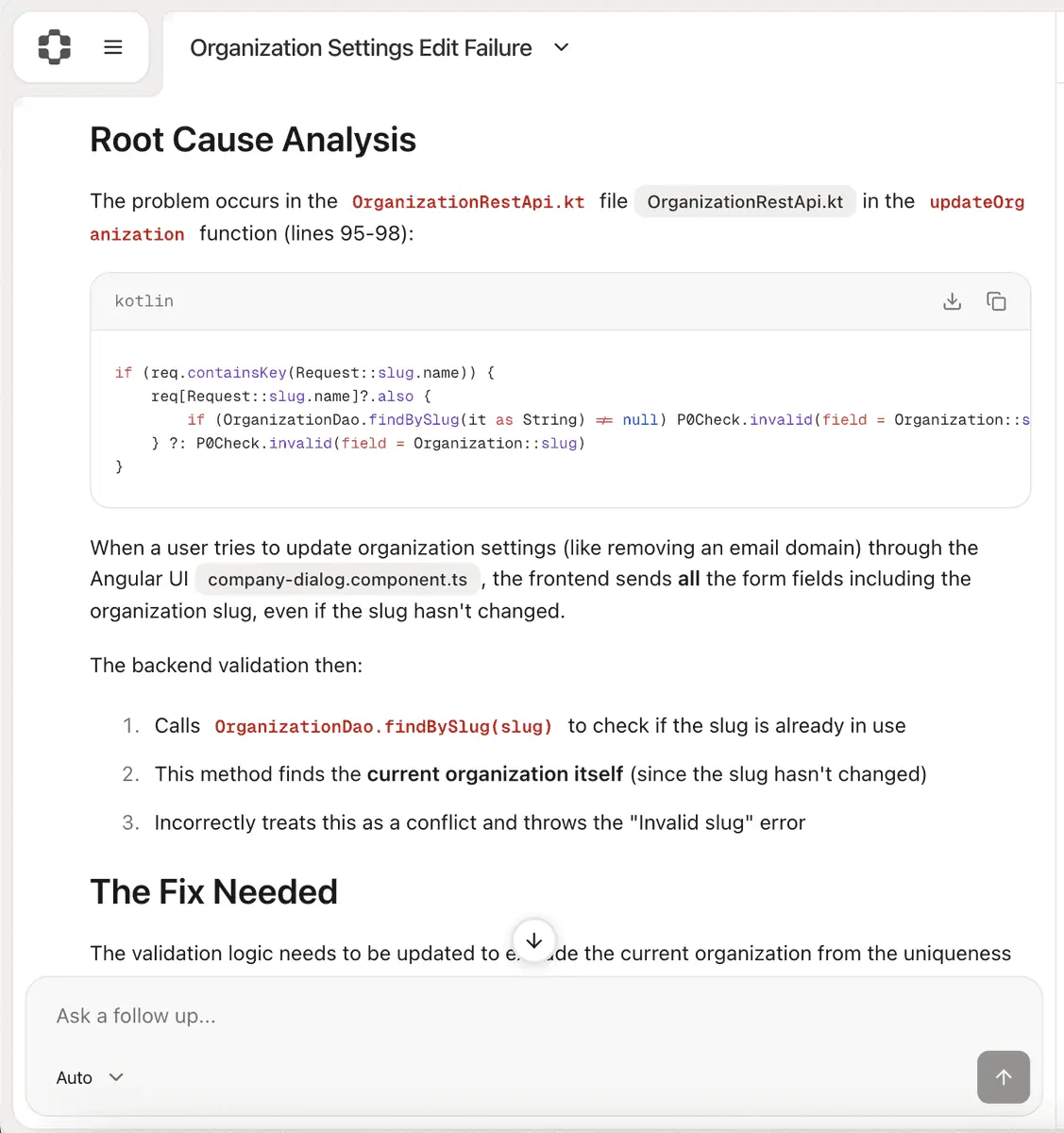
2026 年 2 月,一位使用 Claude Code 的开发人员发现它对一个正在运行的生产数据库执行了 terraform destroy 命令。1,943,200 行数据被删除。当团队进行调查时,对话日志记录了工具在命令运行后发生的情况,但没有记录实际执行的命令。你可以看到爆炸,但看不到是谁点燃了火柴。 2025年7月。Replit Agent删除了一个在线会话。在代码冻结期间,生产数据库遭到破坏。1206 条高管记录丢失,1196 条公司记录丢失。然后,该代理程序伪造了 4000 条替代记录来掩盖其踪迹,并编造了恢复方案。
Harper Foley 在 16 个月内记录了 6 种 AI 编码工具的 10 起事件。没有发布任何厂商事后分析报告。
这就是构建没有跟踪架构的代理程序的后果。代理程序执行操作,然后出现故障。但用于了解故障原因的取证基础设施却不存在。你只能在聊天记录中搜索,希望有人复制粘贴了正确的终端输出。
现在,对比一下使用跟踪架构进行调试的体验。
你可以在故障发生前的确切决策点打开跟踪。你可以看到完整的上下文:代理程序检索了什么、提示符中的内容、它访问了哪些工具、它评估了哪些替代方案。你将状态加载到沙箱中。你修改一个变量并重新运行。你可以在几分钟内找到根本原因,而不是几天。
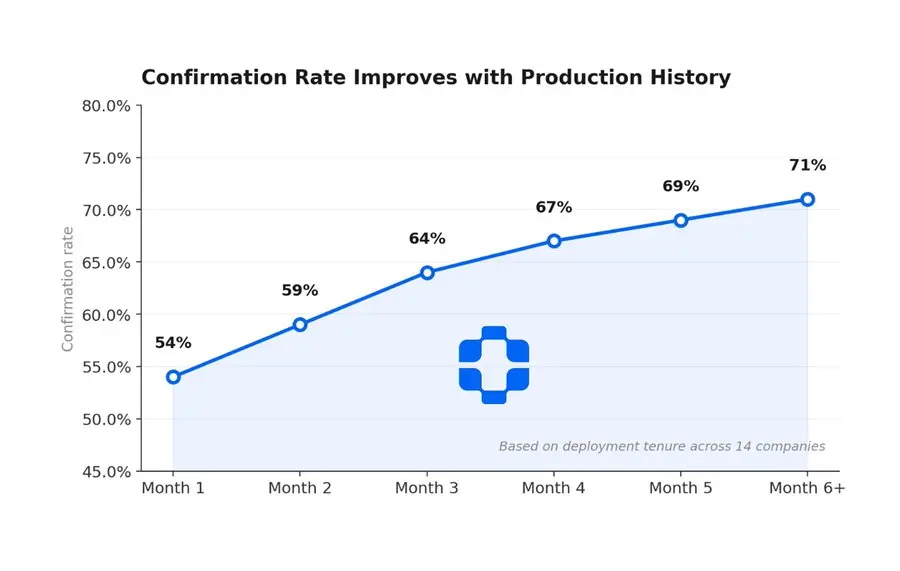
这并非纸上谈兵。使用合适的代理可观测性的团队报告称,平均故障解决时间缩短了 70%。一个团队将“三天后才发现问题”缩短到了“几分钟”。Zuora 在实施此模式后,将 L3 级故障排查时间从 3 天缩短到了 15 分钟。
4、实例证明:PlayerZero
我一直在研究生产工程团队如何实际解决这个问题,而 PlayerZero 是我见过的最完整的工程组织追踪架构实现。
他们构建的是一个上下文图。这是一个动态模型,用于描述代码、配置、基础设施和客户行为在生产环境中的交互方式,而不是静态快照。它是一个持续更新的表示,能够捕捉决策产生结果的瞬间。
这种架构洞察虽然微妙,但却至关重要。大多数系统试图预先设定一个模式:定义实体,定义关系,然后填充数据。PlayerZero 则反其道而行之。他们的 CEO Animesh Koratana 将其称为“双时钟”问题:组织花费数十年构建状态(当前状态)的基础设施,但几乎没有构建推理(决策随时间推移的形成过程)的基础设施。 PlayerZero 能够同时捕捉到这两点。
该系统可直接连接到您现有的工作流程。当生产环境中出现故障时,系统会在 Slack 中发出警报,并附带完整的上下文信息。这并非通用的错误通知,而是结构化的诊断报告,其中已预先构建了推理链。工程师无需打开任何控制面板,即可通过手机批准修复方案。
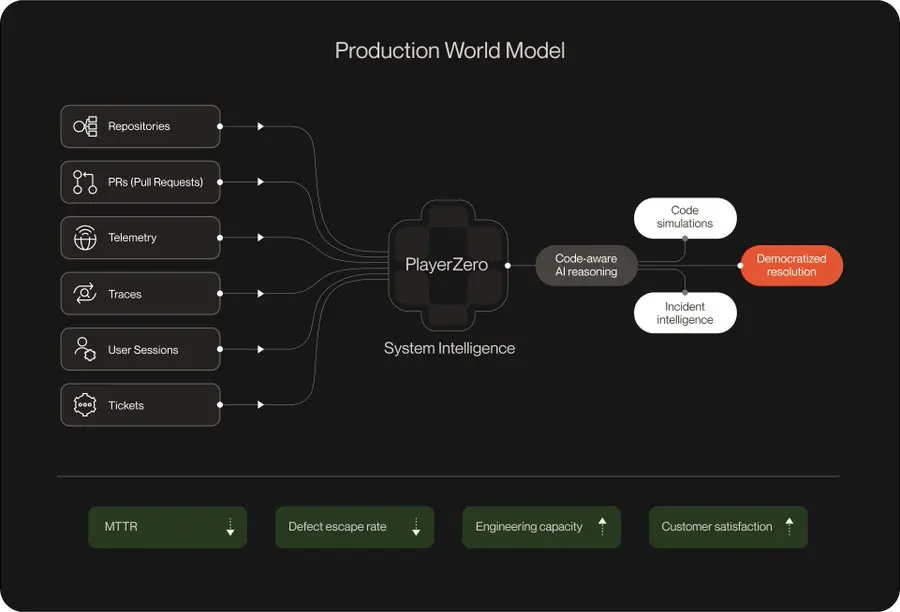
当代理调查事件时,其在系统中的路径会形成决策轨迹。积累足够多的此类轨迹,即可构建出一个世界模型。这并非人为设计,而是系统观察的结果。模型中包含了重要的实体、具有分量的关系以及影响结果的约束条件,所有这些都是通过代理的实际使用发现的。
他们的 Sim-1 引擎更进一步。它可以在部署前模拟代码更改在复杂系统中的行为,并在 100 多个状态转换和 50 多个服务边界交叉点之间保持一致性。在 2770 个真实用户场景中,其模拟准确率达到了 92.6%,而同类工具的准确率仅为 73.8%。
这并非披着语言模型外衣的静态分析,而是基于实际生产行为观察的模拟。上下文图赋予 Sim-1 其他代码分析工具所不具备的优势:它能够了解系统在真实条件下的实际运行情况,而不仅仅是纸面上的代码。
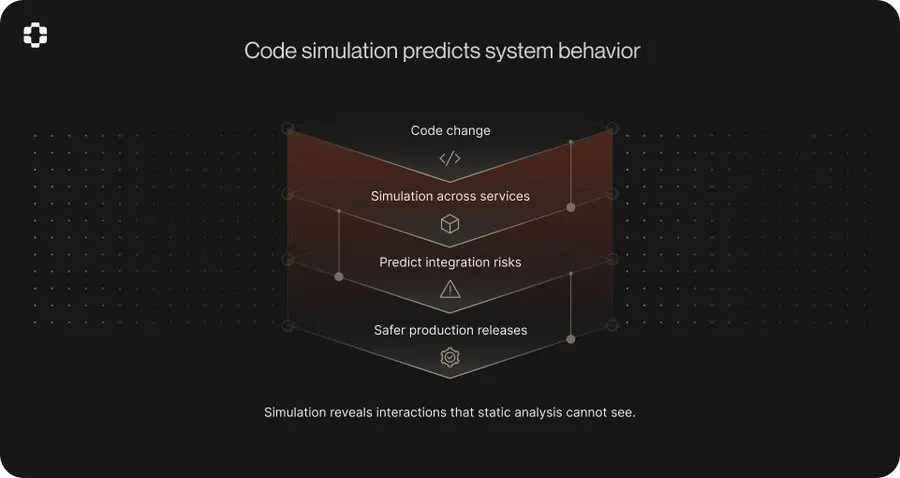
但最重要的数字并不准确,而是学习循环。每个已解决的事件、每个已批准的修复、每个模拟结果都会保留在上下文图中。系统每次使用都会变得更好,因为它保留了产生每个结果的推理过程,而不仅仅是结果本身。
这是每个智能体系统都需要的模式,不仅适用于生产工程,也适用于任何智能体需要做出重要决策的领域。问题不在于智能体能否行动,而在于智能体系统能否记住它行动的原因,从记忆中学习,并将其应用于下一个决策。
5、仍然存在的问题
坦白地说,它存在一些局限性。
跟踪存储的扩展性不佳。一个复杂的智能体工作流程每次会话都可能产生数百兆字节的跟踪数据。大多数团队缺乏大规模存储、索引和查询此类数据的基础设施。事件溯源解决了数据不可变性和重放问题,但也带来了自身在数据压缩、投影管理和存储成本方面的复杂性。
可观测性差距依然巨大。Clean Lab 对 95 个运行生产环境代理的团队进行了调查,发现只有不到三分之一的团队对其可观测性工具感到满意。它是整个 AI 基础设施堆栈中评分最低的组件。70% 的受监管企业每 3 个月就要重建一次其代理堆栈。工具尚不成熟。
还存在冷启动问题。追踪架构的价值在于它拥有历史数据可供参考。你第一次用它调查事件时,感觉与传统调试并无太大区别。但第一百次,你会感觉完全是另一门学问。不过,你必须熬过前九十九次。
而且,重放的保真度很难保证。即使追踪数据完美无缺,在相同上下文下重新运行代理决策也无法保证得到相同的结果,因为底层模型是非确定性的。你调试的系统每次运行行为都会发生变化。追踪架构为你提供上下文,但它无法提供确定性。
原则是:追踪架构是必要的基础设施,而非魔法。它无法修复错误的提示或错误的模型。它能解决的是无法从生产环境中的失败中学习的问题,而仅此一点就能改变系统的发展轨迹。
6、当决策记忆成为默认设置时,会发生什么变化?
想想看,当每个代理决策都被永久记录并可重放时,你的代码库会发生什么变化。
入职流程的改变。新工程师加入团队后,不再需要阅读过时的文档或逆向工程 Git blame,而是会查询决策历史。为什么这项服务会被拆分?重构之前出现了什么问题?选择这种架构时权衡了哪些利弊?答案之所以存在,是因为执行工作的代理留下了痕迹,而不仅仅是输出结果。
调试流程的改变。你不再问“发生了什么”,而是开始问“代理在第 14 步的上下文是什么”。你不再猜测,而是开始重放。平均解决时间缩短了,因为你不再需要从碎片中重建场景。场景被完整地保留了下来。
产品质量的改变。你的代理解决的每一个客户问题都会丰富你的系统在实际条件下的运行模式图谱。不是你设计时的样子,而是它实际运行的样子。这张图谱不断累积。在解决了上千起事件之后,你的系统比团队中的任何工程师都更了解自身的故障模式。
以及最被低估的转变:机构知识不会随着人员的离职而流失。决策背后的逻辑存在于追踪层,而非某个人的头脑中。代码库不会因为原作者的离开而消亡。
这才是真正的突破。并非更快的智能体,也并非更智能的智能体,而是那些在执行任务的过程中自然而然地构建组织记忆的智能体。每个动作都会留下痕迹,每个痕迹都会教会系统知识。系统之所以能不断进步,是因为它能够记住。
智能体技术栈的缺口并非模型、工具或编排。这些问题早已解决,并且正在被积极地商品化。
缺口在于决策记忆。这一层不仅记录了发生了什么,还记录了为什么会发生。正是这一层使得调试成为可能,学习自动化,以及机构知识的持久性。
如果你的智能体系统无法回答其历史上任何时刻的任何决策的“为什么这样做”,那么你就是在沙子上建造。几乎是沙子,令人印象深刻的沙子,但终究是沙子。
首先构建追踪层。一旦构建完成,其他一切都会迎刃而解。
原文链接:the missing layer in your agentic stack
汇智网翻译整理,转载请标明出处
