第二大脑:我的Obsidian重构实践
继"是LLM Wiki / 否LLM Wiki"的争论之后,我想分享过去五年在Obsidian中构建第二大脑的经验。将它连接到Claude Code让我看到了我一直在忽视的东西。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我在2021年打开了我的第一个Obsidian库。那是一团糟——从Evernote、Notion和三台电脑上散落的十年文本文件的迁移堆。五年后,那个库拥有超过5000条笔记,涵盖我的咨询工作、个人研究、投资论文,以及日常生活的纹理——会议笔记、读书高亮、半成品的想法,以及那种只有在你确定没人在看时才会做的思考。
Obsidian对我来说成为了承重基础设施。不是在生产力网红的意义上。而是在当客户要求我综合六个月的项目历史时,我打开的是我的库而不是邮箱的意义上。当我在评估一家公司时,我调出我的投资框架笔记和多年来积累的行业研究。当我需要写点什么时,初稿已经作为碎片散布在一百条笔记中了。
但我做不到的事情是:我无法向这个库提问。我无法说"我的分布式系统笔记和组织设计笔记之间有什么联系?"并得到一个真正的答案。知识都在那里——链接了、标记了、结构化了——但唯一能遍历它的只有我自己,手动地,一次一条笔记。
当我把Claude Code连接到我的库时,一切都改变了。而且改变的程度超出了我的预期。
1、大多数Obsidian-AI指南弄错了什么
大多数集成指南从工具开始。安装这个插件。配置那个服务器。给你一个JSON配置。它们错过了一个让整个事情运转的根本洞察。
Claude Code不是为笔记构建的。它是为导航代码库构建的——读取文件、理解结构、跟踪引用、进行定向编辑和执行多步骤计划。一个Obsidian库几乎完美地映射到这个模型上。代码库有源文件、导入语句、目录结构和配置。你的库包含Markdown笔记、wikilinks、文件夹层次结构和YAML frontmatter。Claude Code能以类似的流畅度导航它们。
最简单的集成是最被低估的:
cd ~/my-vault
claude
就是这样。Claude Code现在可以读取每条笔记、创建新文件、编辑内容、用正则搜索和对你的库运行shell命令。不需要插件、服务器或配置。
但"能访问文件"只是基本要求。我花五年时间构建库结构——约定、文件夹架构、链接模式——这些才是让集成真正有用的东西。而教Claude这些约定才是真正的工作开始的地方。
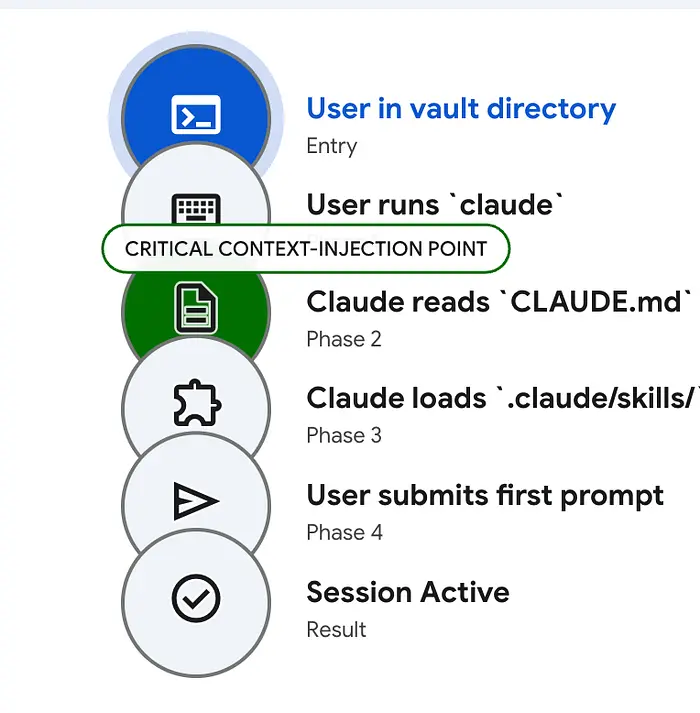
2、CLAUDE.md:改变一切的文件
当你在目录中运行claude时,它会自动读取根目录下一个名为CLAUDE.md的文件。把它想象为一个极其能干但会在会话之间忘记一切的新员工的入职文档。
我第一次运行/init,它通过扫描我的库结构生成了一个起点。然后我大量重写了它。生成的版本捕捉了显而易见的东西——文件夹名称、文件类型。但它不知道我的约定、我的活跃项目,或者我需要Claude永远不要碰的东西。
以下是五年库管理经验教会我放在CLAUDE.md中的内容:
# Vault Context
这是我的个人+专业知识库。五年的笔记
涵盖咨询、投资、分布式系统研究和个人发展。
笔记使用Obsidian风格的Markdown,包含[[wikilinks]]、
标注和YAML frontmatter。
## Structure
- Projects/ - 活跃的客户和个人工作
- Areas/ - 持续关注的领域(健康、财务、ML研究)
- Resources/ - 参考资料、读书笔记、论文
- Archive/ - 已完成的工作(仍可搜索,不活跃)
- _attachments/ - 图片和PDF(永不修改)
- _templates/ - Obsidian模板(永不修改)
- _ai-drafts/ - AI生成内容的暂存区
## Conventions
- 内部链接:始终使用[[wikilinks]],不使用裸URL
- 标签:层级#domain/topic格式
- MOC:以"MOC - "为前缀(内容地图)
- 每日笔记:Journal/YYYY/YYYY-MM/YYYY-MM-DD.md
- 来源笔记:必须在frontmatter中包含`source:`
## Rules
- 永不修改 _attachments/、_templates/ 或 .obsidian/
- 永不未经我明确确认删除笔记
- 始终包含YAML frontmatter:date、tags、aliases
- 综合时,仅使用我笔记中的内容
- 输出草稿到 _ai-drafts/ - 永不直接写入库中
## Active Context(我每次会话前更新此部分)
- 正在处理:Q2客户架构评审
- 未解决的问题:遗留系统的容器化策略
- 近期关注:Areas/distributed-systems/、Projects/client-acme/
我学到的三个非显而易见的实践比模板本身更重要:
保持活跃上下文的新鲜。我在每次会话前更新这个部分。过时的上下文比没有上下文更糟——它会让Claude冲向昨天的优先事项。更好的做法:每次会话结束时,我让Claude追加一个简短的会话日志。这创造了我没想到会如此重视的连续性。
引用,不要内联。我的兴趣、活跃项目和专业背景都在单独的笔记中。CLAUDE.md引用它们。这保持根文件聚焦,避免在与每次会话无关的上下文上浪费token。
包含负面指令。"永不修改_templates/"比希望Claude自己弄明白更有效。我在一个早期会话中得到了这个教训——它"改进"了我的一个Templater脚本。
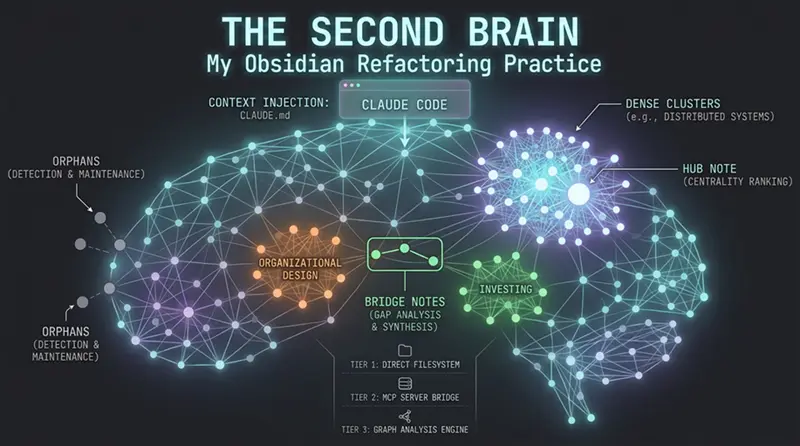
3、你已经拥有的知识图谱
这是我经过多年链接笔记后才意识到的:我的库不仅仅是Markdown文件的文件夹。它是一个图数据库。
每个Obsidian库都包含一个隐式图。笔记是节点。Wikilinks创建边——当你在Raft笔记中写[[Distributed Consensus]]时,你创建了一条从一个概念到另一个概念的边。单独的wikilinks是有向的(笔记A链接到笔记B),但Obsidian的反向链接功能创建了双向导航层,所以你可以在任一方向遍历连接。标签作为标签将节点分组成子图。Frontmatter属性成为图感知工具可以查询和过滤的节点属性。
Obsidian的图视图向你展示了这种结构。它很漂亮。但它是被动的——它不能在图上推理,不能告诉你哪些笔记是枢纽,不能识别应该连接但没有的集群。
经过5000条笔记和五年的链接,我的图有了值得分析的真实结构。而这就是Claude Code——特别是通过具有图功能的MCP服务器——填补了Obsidian本身没有的空白。
4、真正重要的图指标
一旦你通过支持图操作的MCP服务器将Claude Code连接到你的库,你就解锁了我以前只能肉眼做(做得不好)或根本不做的分析:
中心性排名识别你真正的枢纽笔记——连接到最多其他概念的概念。我发现我的实际枢纽并不总是与我的"官方"MOC(内容地图)匹配。我关于"反馈循环"的笔记有38个来自四个领域的传入链接。我的系统思维MOC只有7个。这种不匹配是我需要重构的信号。
以下是使用TurboVault进行中心性查询的实践示例:
> get_centrality_ranking(limit=5)
1. Feedback Loops - 38个连接 (Areas/systems-thinking,
Projects/client-acme, Resources/books)
2. MOC - Distributed Systems - 34个连接
3. Bayesian Reasoning - 29个连接 (桥接3个集群)
4. Second-Order Effects - 26个连接
5. Margin of Safety - 24个连接 (Areas/investing,
Projects/portfolio)
孤立检测找到零传入或传出链接的笔记。在我的库中,我有340个孤立笔记——我捕获但从未连接的想法。有些值得整合。大多数是归档候选。不管怎样,直到我问了才知道它们存在。
集群分析揭示自然分组,更重要的是,哪些集群是断开的。我的投资笔记和系统思维笔记是两个独立的岛屿,尽管有明显的概念重叠。那是一个我错过了几年的整合机会。
桥接笔记识别找到连接原本孤立集群的稀有笔记。这些通常是你最有原创性的洞察——你在其他人保持分离的领域之间建立了联系的地方。
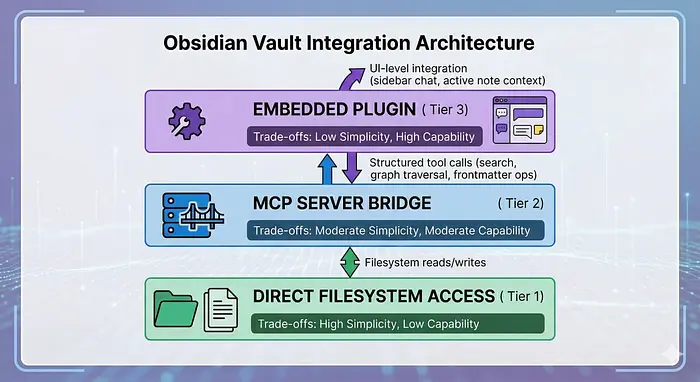
5、工具:什么真正有效
我测试了所有主要的集成路径。以下是我的推荐,按复杂度递增排列。
第一层:直接文件系统(从这里开始)
只需从库根目录运行claude。添加CLAUDE.md。安装官方的kepano/obsidian-skills——来自Obsidian CEO Steph Ango的五个技能文件,教Claude Code完整的Obsidian格式:wikilinks、标注、Bases、Canvas和CLI。没有它们,Claude会将[[wikilinks]]视为损坏的Markdown,将> [!warning]视为引用块。
npx skills add git@github.com:kepano/obsidian-skills.git
这个组合——CLI + CLAUDE.md + 技能——处理了我80%的需求。我在前两个月只使用了这个。
第二层:MCP服务器(当你需要结构化搜索时)
当我的库超过2000条笔记时,对于搜索密集型工作流,原始文件访问开始感觉慢了。MCP服务器将你的库暴露为Claude Code可以程序化调用的结构化工具:搜索、frontmatter操作、标签管理、图遍历。
我对大多数人的推荐——MCPVault:零Obsidian插件依赖,14个方法,BM25排名搜索,以及响应压缩带来的40-60%更小的token使用量。在你的Claude配置中设置:
~/.claude.json:
{
"mcpServers": {
"obsidian": {
"command": "npx",
"args": ["@bitbonsai/mcpvault@latest", "/path/to/your/vault"]
}
}
}
对于更深入的Obsidian集成,obsidian-claude-code-mcp在Obsidian本身内部运行一个带有WebSocket自动发现的MCP服务器——运行claude,输入/ide,然后从列表中选择你的库。对于语义(基于含义的)搜索,obsidian-mcp-tools与Smart Connections插件集成,可以找到概念相关的笔记,即使它们没有共享术语。
第三层:图分析(适用于大型、重度链接的库)
TurboVault是强力工具——一个Rust引擎,拥有47个专用工具,在10万条笔记上实现亚500毫秒的BM25搜索,对frontmatter进行SQL查询,以及我上面描述的图分析功能(中心性、集群、桥接)。如果你的库有10000+条笔记或者你关心图级洞察,这个值得设置。
obsidian-mcp-plugin采用不同方法——它将你的库暴露为一个连接的知识图谱,具有多跳遍历、反向链接分析和概念发现功能。AI导航图结构本身,而不是将笔记视为孤立文件。
第四层:嵌入式插件(适用于侧边栏忠实用户)
像Claudian和Cortex这样的插件将Claude直接嵌入Obsidian的侧边栏,具有持久会话和活跃笔记感知。用户体验是无缝的,但你依赖于插件维护。我更喜欢CLI的灵活性——但如果你整天生活在Obsidian中,侧边栏体验很吸引人。
6、物有所值的工作流
不是每个AI工作流都能持续。这些是我经过几个月迭代后仍在每周使用的。
6.1 自动反向链接(入门级)
阅读我今天的日记条目,并为所有提到的
人物、地点和书籍添加[[wikilinks]]。
在库中搜索每个实体的现有笔记。
如果没有现有笔记,在Resources/People/或
Resources/Places/中创建一个带有基本
frontmatter的存根笔记。
这是我的第一个Claude Code工作流,仍然是投资回报率最高的。过去需要我10-15分钟手动链接的工作现在在我等待时就能完成。经过三个月的持续使用,我的每日日记条目从死胡同笔记变成了图中丰富连接的节点。复合效应是真实的——每个链接条目都为下一个条目提供了更好的上下文。
6.2 跨领域综合
这是让我重新思考库用途的工作流:
阅读Areas/distributed-systems/和
Areas/organizational-design/中的笔记。
识别在两个领域中出现或具有结构相似性的
概念。在_ai-drafts/cross-domain-synthesis.md
中写一篇综合笔记,映射这些相似之处。
仅使用我笔记中的内容——不要添加外部声明。
包含指向所有源笔记的[[wikilinks]]。
Claude发现了我不曾明确建立的连接:我关于共识协议的笔记和关于扁平组织中决策的笔记从不同角度描述了相同的协调问题。那篇综合笔记成为了一次会议演讲的种子。我不会手动写出它——不是因为我不能,而是因为阅读两个文件夹中的40条笔记并将它们全部保持在记忆中的激活能量太高了。
6.3 库健康审计(每月维护)
找到所有孤立笔记(无传入或传出链接)、
缺少YAML frontmatter的笔记和损坏的wikilinks。
在_ai-drafts/vault-health-report.md输出报告。
我每月运行这个。这相当于PKM中的运行测试套件。在我开始之前,我的库有9%的孤立率和极不一致的frontmatter。六个月的月度审计将孤立率降至2%以下,frontmatter合规性提高到95%以上。
6.4 差距分析
检查Areas/investing/并列出严肃的从业者
期望找到但没有任何现有笔记覆盖的主题。
Claude发现我的投资笔记广泛涵盖了估值和护城河,但在仓位大小、风险管理或投资组合构建方面几乎没有内容。这个差距对我三年来都是不可见的,因为我确实有的笔记让人感觉已经很全面了。
6.5 快速CLI管道
claude -p "用200字总结Resources/RFID/" \
> Resources/RFID-summary.md
-p(或--print)标志以非交互方式运行Claude并输出到stdout。我将此用于批量操作——为整个文件夹生成摘要、从研究笔记中提取关键声明或从主题列表创建存根笔记。
7、为什么是Obsidian + Claude?
而不是Notion AI或Logseq + GPT?
我试过替代方案。以下是我不断回来的原因:
本地文件,不是云锁定。我的库是我文件系统上的Markdown文件文件夹。我拥有它们。我可以grep它们、git它们、备份它们或明天切换工具。Notion AI很强大,但你的数据以专有格式存储在Notion的服务器上。当我给Claude Code访问我的库时,它读取的是我在Obsidian中编辑的相同文件——没有同步层、没有API翻译、没有数据离开我的机器。
代理式,不是自动补全。PKM工具中的大多数AI集成是增强版的自动补全——你输入,它们建议。Claude Code是一个代理。它可以读取40条笔记、确定哪些相关、创建新文件、添加wikilinks并报告它做了什么。"AI辅助写作"和"AI辅助知识管理"之间的区别是一个更好的键盘和研究助理之间的区别。
可组合,不是单体。我可以更换MCP服务器、更改CLAUDE.md、添加技能、通过shell脚本管道输出或明天使用完全不同的AI模型。架构是纯文本层和开放协议。没有任何东西被锁定。
Claude Code需要Max订阅或API使用量,这会产生费用,这值得承认。对于我的使用模式——每周几次会话,每次涉及20-50条笔记——与它节省的咨询时间相比,费用微不足道。你的计算会有所不同,但第一个月值得跟踪。
8、你会希望你先设置的安全实践
我通过犯错学到了这些。在你的第一次会话之前设置它们。
为你的库使用git。这是最重要的安全网。Claude的每一个更改都成为可审查的diff。每一个错误都是可逆的。
cd ~/vault
git init
echo ".obsidian/workspace.json" >> .gitignore
echo "_attachments/" >> .gitignore
在第一次提交之前检查暂存文件——确保你不会意外跟踪敏感数据。
将所有AI输出通过_ai-drafts/。Claude的工作是草稿,直到你审查过它。永远不要让它直接写入你的主库结构。审查后手动提升笔记。这保留了你的库作为你思考的仓库。
始终约束综合提示。"仅使用我笔记中的内容"不是可选的。没有它,Claude会将你的知识与它的训练数据混合,结果看起来权威但包含你从未做出的声明。我将此约束添加到每个综合和摘要请求中——这是PKM中的输入消毒等价物。
将请求限定在特定文件夹。"总结Resources/quantum-computing/"是安全和快速的。"总结我整个库"是一个产生肤浅结果的token炸弹。
9、复合效应
真正的回报不是任何单一工作流。而是经过数月一致的AI辅助维护后发生的事情。
经过三个月的自动反向链接,我的每日笔记从死胡同条目变成了连接节点。经过六个月的库健康审计,我的孤立率从9%降至2%以下。在每个知识领域运行差距分析后,我开始写填补结构漏洞的笔记,而不是堆叠到已经密集的集群上。
图变得更密集、更连接、更可导航——对我和对AI都是如此。更好的链接笔记给Claude更好的上下文,产生更好的建议,创建更好的链接。每一个改进都在复合。
这是Zettelkasten方法承诺的轨迹,但很少有人手动实现。组织工作——反向链接、标记、格式化、一致性——正是AI擅长的。你带来思考。Claude带来簿记。
10、本周开始
如果你读到这里但还没开始,这是30分钟的设置:
- 安装Claude Code —
npm install -g @anthropic-ai/claude-code - 初始化 —
cd ~/vault && claude然后/init - 重写CLAUDE.md — 使用上面的模板,针对你的库结构和约定定制
- 安装obsidian-skills —
npx skills add git@github.com:kepano/obsidian-skills.git - 运行你的第一次审计 — "找到所有孤立笔记和缺少YAML frontmatter的笔记。输出报告到_ai-drafts/vault-audit.md。"
这里是第一周的挑战,让你超越教程阶段:对7条每日笔记自动化反向链接。运行你的第一次库健康审计。让Claude找到你两个最分离的知识领域之间的连接。到周五,你将有一个可衡量的感觉,这是否改变了你的工作流还是只是另一个闪亮工具。
我押注前者。五年构建我的库使它有价值。将它连接到一个能真正用它思考的代理,以我没想到过的方式使那种价值变得可访问。
图一直都在。现在有东西可以遍历它了。
原文链接: Your Obsidian Vault Is a Knowledge Graph. Here’s How to Make It Think (quickly).
汇智网翻译整理,转载请标明出处
