Token经济学决定你AI成本的80%
别再浪费 token 了。以下是你的 AI 为什么越来越贵的数学原理。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我最近分享了我尝试用区区 5 美元预算对一个大型项目进行 vibe 编码的经历。
不出所料,它失败了。但我相信我可以在预算内开发出一个 MVP,而且我差一点就成功了。
以下是我的项目发生了什么。我使用的是 Claude Code 配合 Anthropic API。我以为我可以非常高效地使用 token,不需要 20 美元的专业订阅。我让 Claude 在一个提示中完成所有需求。Claude 工作了大约 20 分钟后停了下来。我检查了 Anthropic 控制台,发现我只花了 1.33 美元。对于这种规模的项目来说,这很棒,我这样想。而且我仍然远低于预算。如果我自己开发这个项目,可能需要几个月的时间。
当我尝试运行开发服务器时,终端报错了。这在任何项目中都是正常的。我对自己说,出了问题就要修复。我让 Claude 修复了几次错误。
然后 Claude 说,我的预算已经用完了。
为什么我在不到一小时内就烧完了 5 美元的预算?首先,我当时并不了解 Claude 的代码是如何工作的。我之前的那篇文章就是关于这个的。但另一方面,我也没有充分认识到"token 经济学"。这就是本文要讨论的内容。
1、不要把 GenAI 项目当作传统软件项目来对待
因为它们消耗资源的方式完全不同。
在传统计算中,你为机器属于你的时间付费。拥有时间可以以毫秒或小时为单位来衡量。但它是可预测的。
但对于生成式 AI 来说,这种可预测的使用量计量器已经失效了。你不再仅仅通过拥有计算资源的时间来衡量成本。相反,在这里 token 才是主导者。
Token 是 LLM 中最基本的组成部分。一个 token 可以是很多东西。它可以是一个单词、一个空格、一个字母,甚至可以是句子和段落。它们是 LLM 中基本的度量单位。
如果你通过 API 提供商(例如 OpenAI 或 OpenRouter)使用 LLM,你将为提示中的 token 以及作为 AI 响应返回的 token 付费。
但是,输入 token 的成本和输出 token 的成本之间存在巨大差异。例如,GPT 5.4 的价格是 $2.75 / 100 万输入 token。这些是你在提示中使用的 token。但要让模型与你对话,你大约需要花费 8 倍的成本。同一模型的定价为 $15 / 100 万输出 token。
为什么模型回复要收取溢价?
原因是 LLM 的输出是自回归的。这意味着,每个输出 token 都依赖于它之前的 token。因此,它们无法被并行处理。LLM 要处理 GB 级的数据,仅仅是为了预测下一个 token。
除了输入和输出 token 之外,一些模型还会消耗 token 用于推理。思考 token 是 LLM 的内部草稿本。值得注意的是,思考模型将 LLM 的实用性提升到了一个新的水平。然而,你可能需要消耗 3000 个思考 token 才能得到 500 个 token 的输出。
Token 是有成本的。大多数人为了避免意外的 AI 账单而采取的最自然的解决方案就是自行托管。
2、自行托管模型是否有助于降低推理成本?
自行托管模型可以给你更多控制权。但它们能否给你带来你梦寐以求的好处?——这取决于具体情况。
这就像为什么人们比害怕公路旅行更害怕乘飞机旅行。在飞机上,你无法与飞行员交谈或观看飞行员驾驶飞机。但在汽车里,你有方向盘。或者你可以轻松地与司机交谈。然而事实是,飞机事故远少于公路事故。
同样地,第三方推理提供商的不可控性比可控的自行托管解决方案更让我们害怕。然而,自行托管时的失败方式比你为 API 付费时更多。
如果你想为固定基础设施而不是 API 付费,这里有一个经验法则。
转折点:如果你每天调用 LLM 超过 5 万次,就自行托管。
如果你超过大约每天 5 万次调用,自行托管对你来说就有意义了。因为如果你使用 Claude Sonnet 4.6 并且每次调用平均消耗 4000 个 token(每天 200 万 token),你仅输出 token 就要花费近 600 美元。你可以预期每月的账单约为 750 美元。
你可以用这个成本租用一块 L40 GPU(*推荐链接),全天候运行一整月。
3、除了自行托管,你还能做什么?
自行托管有其优势。但当关注点是成本节约时,自行托管不是唯一也不是正确的选择。以下是你可以在继续使用第三方推理提供商的同时大幅节省成本的方法。
3.1 结构化输出
在我看来,最快速、最大的节省始终是结构化输出。
如果你清楚你向 AI 请求的是什么,你几乎总是可以推断出输出会是什么样子。既然你知道了,为什么要浪费 token 让 AI 生成你已经知道的输出部分呢?
当我设计 AI 系统时,我总是致力于限制输出结构。结构化输出不仅让我拥有控制权,还能大幅降低推理成本。
即使在期望文本响应时,我仍然让 AI 将输出结构化,以填充我提示中的空白。
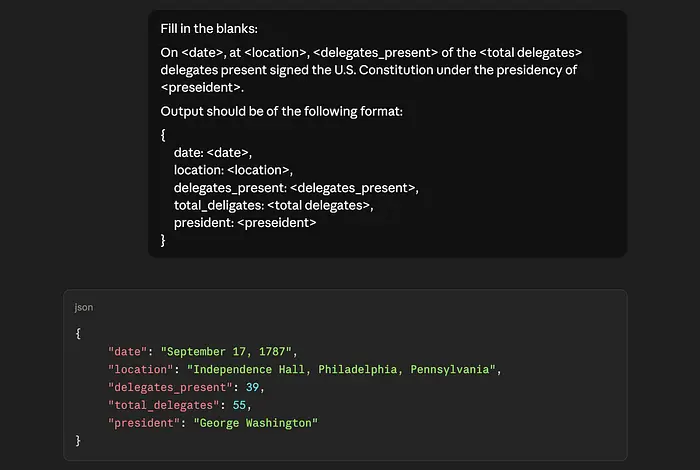
向 LLM 请求结构化输出的截图
3.2 有意缩小输出
也许这是结构化输出的另一种形式。如果结构化输出将响应压缩到绝对的最低限度,这种方式则给了更多呼吸的空间。
AI 的回复通常包含额外的解释。这对聊天机器人很有帮助。当你设计系统时,可以避免这些。如果无法使用结构化输出,你可以明确要求模型限制输出长度。
你可以通过多种方式限制响应长度。
最有效的解决方案是使用 max_token 参数(如果模型支持的话)。如果不支持,你可以在提示本身中要求模型保持一致的响应。例如,要求模型在 3 句话内回答或限制在 50 个词以内。
3.3 尽可能使用量化模型
量化是一种非常有效的解决方案,不仅可以降低你的费用,还可以减少延迟。一举两得。
量化将模型权重存储在低精度数据类型中。因此,模型运行所需的内存大大减少。输出准确性的损失是一种权衡。但在大多数情况下,这是可以忽略不计的。
你有一张图片并将其压缩到原来大小的一半。当然,现在图片的像素变少了。但你很少注意到图像质量的差异,不是吗?这就是量化的等效概念。
量化模型可以缩小约 75%,速度快 2-3 倍,仅有微不足道的 5% 的细节损失。
如果你使用的是专有模型,可能无法这样做。但大多数开放模型和推理提供商都支持量化模型。
3.4 压缩较长的提示(输入)
我们已经讨论了很多关于节省输出 token 的方法。但输入 token 不应该被忽视。即使它们的定价较低,输入提示本身也可能很大。
例如,如果你上传了几份公司年度报告并要求 AI 对公司盈利能力的年度趋势发表评论,即使不做任何优化,你的输出也不大。然而,输入量是巨大的。
因此,解决这个问题的最佳方法是使用另一个专门的模型来压缩输入。
除了节省成本之外,压缩输入还有助于提高响应质量。这是因为大多数 LLM 都存在一种叫做"迷失在中间"的现象。
3.5 提示缓存(输入)
这是另一种输入 token 优化技术。提示缓存可以将输入 token 成本降低高达 98%。
AI 来回处理 token 以生成每个新 token。但大多数情况下,LLM 读取的内容与之前相同。有一种方法可以提高效率——提示缓存。
当我们设计 AI 系统时,我们在每个提示中都包含一个系统提示。这包含所有重复的指令和安全协议。系统提示很少改变。
为了利用这一点,推理提供商提供提示缓存。在 Anthropic 中,我们可以通过指定 cache-control 头来实现。OpenAI 表示它会缓存前大约 256 个 token。这个限制可以增加。
4、结束语
如果你认真对待 AI,在开始做任何事情之前,你需要了解 token 在 LLM 中是如何工作的。Token 驱动成本,token 影响延迟,它们决定了你的 AI 能做的一切。
在这篇文章中,我分享了一些经过验证的优化 AI 项目中 token 使用的技术。即使你已经用 AI 开发了产品,在将其投入生产之前,也值得按照这份清单检查一遍。
原文链接: Understand Token Economics Before You Do Anything With AI
汇智网翻译整理,转载请标明出处
