5种最常用的数据摄入方法
数据实际上是如何进入你的管道的——全量加载、增量加载、CDC、流式处理和基于API的方式,附Python代码。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在你编写任何转换之前,在你构建预测模型之前,或者在你运行Spark管道之前,你必须做的就是获取数据。
第一步——从数据所在的任何地方拉取数据并将其存放到你可以工作的地方——就是数据摄入。
听起来很简单。但并不总是如此。
我见过管道崩溃,不是因为转换有问题,而是因为摄入方法不合适。有人在该用增量加载时使用了全量加载。有人在对需要近实时处理的数据构建批处理作业。
管道技术上是工作的——它只是没有做业务需要的事情。
在本文中,我们将介绍五种摄入方法:全量加载、增量加载、CDC(变更数据捕获)、流式处理和基于API的摄入。
对于每种方法,我们将介绍摄入是什么、何时使用以及如何在Python中实现。我们还将使用类比来解释概念。我知道这篇文章有点长,但我相信你读完后会学到一些东西。
我们将从最常见和最直接的到更高级的逐一介绍。让我们开始吧!
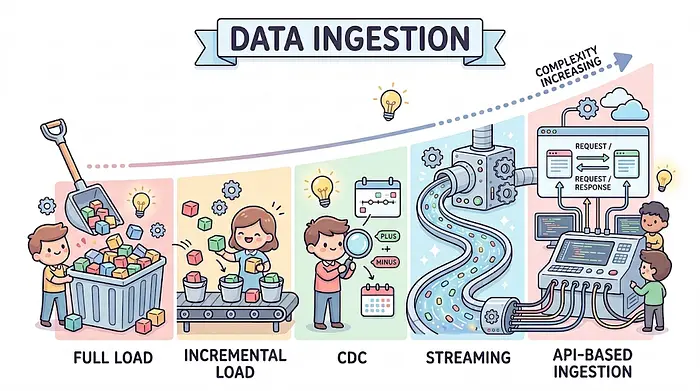
数据摄入
1、全量加载
全量加载正如其名:每次触发管道时,它从源拉取整个数据集并替换目标中的所有内容。
没有历史跟踪,没有比较——只是完全覆盖。
在技术上,全量加载会截断目标表并重新插入源中的每一行。这意味着你的管道不需要知道自上次运行以来发生了什么变化——它将每次运行视为全新的运行。
权衡在于它实现简单但在大规模时成本高昂:如果你的源表有5000万行,你每次都要移动5000万行。
把它想象成一个每天早上被擦掉并重新绘制的白板。
如果白板上有5个条目,那很快——擦掉、重画、完成。但如果它有10,000个条目,即使只有3个东西在一夜之间改变了,你也要重画所有内容。全量加载也是同样的方式:每次运行都是完全重画,无论是一行改变还是一百万行改变。
1.1 可以使用全量加载的实际场景
- 一个小型参考表,例如不经常变化且足够小可以廉价重新加载的国家代码列表
- 一个始终需要反映配置表完整当前状态的夜间报告
- 一个少于10,000行的查找表,在这种情况下增量跟踪会增加复杂性而没有实际收益
1.2 常用工具
Airbyte、Fivetran、AWS Glue、pandas、SQLAlchemy
当我构建一个需要从源数据库同步完整国家列表的项目时,我选择了全量加载——表很小,几乎不变,而且设置水印跟踪的代码会比数据本身还多。
以下是示例代码:
import pandas as pd
from sqlalchemy import create_engine
# Source: read the entire table from the source database
source_engine = create_engine("postgresql://user:pass@source-host/source_db")
df = pd.read_sql("SELECT * FROM country_codes", source_engine) # full extract — no filter
# Destination: truncate and reload
dest_engine = create_engine("postgresql://user:pass@dest-host/dest_db")
df.to_sql(
"country_codes",
dest_engine,
if_exists="replace", # drops and recreates the table on every run — this is full load
index=False
)
print(f"Full load complete: {len(df)} rows loaded")

全量加载结果
如果没有添加新国家,每次运行都会产生相同的行数——目标始终完全镜像源。
2、增量加载
增量加载不是每次都拉取所有内容,而是只拉取自上次运行以来新增或更新的记录。它通过跟踪一个"水印"来实现——通常是一个时间戳或自增ID——并且只提取该值大于上次记录值的行。
水印方法在源数据有可靠的时间戳或ID时效果很好。但是,如果记录可以在不更改updated_at列的情况下更新,或者行可以被删除,增量加载会静默地遗漏这些变更。
这是我在这种方法中看到的最常见的错误——假设增量加载覆盖了删除。它没有。

想象你正在统计一个你朋友不断添加的邮票收藏。你每次访问后记下总数,下次你只计算你离开后新增的数量。
这完美运作——直到你的朋友扔掉了一些,或者换了一个而不告诉你。如果数量没有减少,也没有任何东西被标记,你永远不会知道有什么变化。
2.1 增量加载适合的实际场景
- 一个每天增加数千行新记录的订单表——你不想每晚移动3年的历史数据
- 一个带有
updated_at列的客户表——只拉取过去24小时内被触及的行 - 一个记录只追加不删除的销售交易系统
2.2 常用工具
Airbyte(带游标字段)、Apache Spark、Pandas、SQLAlchemy(可用于全量加载和增量加载)
当我构建一个拉取每日订单记录的管道时——每天约2,000行新记录,而总表有400万行——增量加载是显而易见的选择。
每晚移动整个表既慢又没有意义。以下是模式:
import pandas as pd
from sqlalchemy import create_engine
from datetime import datetime, timedelta
last_run = datetime.now() - timedelta(hours=24) # watermark: last successful run timestamp
source_engine = create_engine("postgresql://user:pass@source-host/source_db")
# Only extract rows updated since the last run
query = f"""
SELECT *
FROM orders
WHERE updated_at > '{last_run.strftime('%Y-%m-%d %H:%M:%S')}'
"""
df = pd.read_sql(query, source_engine)
dest_engine = create_engine("postgresql://user:pass@dest-host/dest_db")
df.to_sql(
"orders",
dest_engine,
if_exists="append", # add new rows — don't overwrite the whole table
index=False
)
print(f"Incremental load complete: {len(df)} rows loaded since {last_run}")

使用增量加载,400万行的表中只有1,842行需要移动。与全量加载相比,这效率高得多。
3、变更数据捕获(CDC)
CDC比增量加载更深一层。
CDC不是查询源表并按时间戳过滤,而是读取数据库的事务日志——数据库为每个插入、更新和删除保留的内部记录。
这意味着你捕获所有内容:新行、更改的行和删除的行。
在幕后,像Debezium这样的CDC工具连接到数据库的二进制日志——MySQL中的binlog、PostgreSQL中的WAL——并在每个数据事件发生时将其发出。
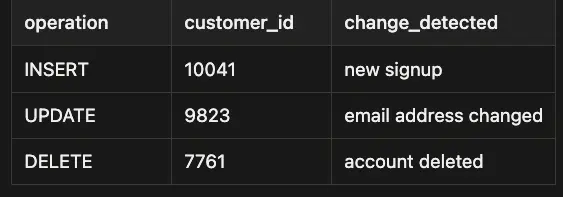
每个事件捕获操作类型(INSERT、UPDATE、DELETE)、行的前状态和后状态以及时间戳。你的管道消费这些事件并将它们应用到目标。
3.1 CDC适合的实际场景
- 一个用户可以删除其账户的客户表——你需要将这些删除传播到你的数据仓库,而不仅仅是跟踪新注册
- 一个每行修改都需要被审计和历史跟踪的金融系统——完整的前/后状态很重要
- 一个没有可靠
updated_at时间戳的源数据库——CDC基于事务日志工作,因此它不依赖于应用程序正确写入时间戳
3.2 常用工具
Debezium、AWS DMS、Fivetran(CDC模式)、Airbyte(CDC模式)、Kafka Connect
如果你的源数据会被删除,而你的下游分析依赖于对存在内容的准确计数——而不仅仅是曾经插入的内容——那么增量加载会静默地对你说谎。CDC就是解决方案。
以下是使用CDC的示例:
# CDC is typically configured at the infrastructure level, not written as a script.
# This example shows how you'd consume CDC events from Kafka using kafka-python.
from kafka import KafkaConsumer # pip install kafka-python
import json
consumer = KafkaConsumer(
"db.public.customers", # Debezium topic — follows database.schema.table format
bootstrap_servers="localhost:9092",
auto_offset_reset="earliest", # start from the beginning of the log
value_deserializer=lambda m: json.loads(m.decode("utf-8"))
)
for message in consumer:
event = message.value
operation = event["op"] # 'c' = create, 'u' = update, 'd' = delete
after = event.get("after") # row state after the change
before = event.get("before") # row state before the change (None for inserts)
if operation == "c":
print(f"INSERT: {after}")
elif operation == "u":
print(f"UPDATE — before: {before} | after: {after}")
elif operation == "d":
print(f"DELETE: {before}")
4、流式摄入
流式摄入意味着数据持续地、逐个事件地流入你的系统,而不是按计划批次。没有"凌晨2点运行这个作业"——数据在产生的瞬间到达,你的管道实时(或近实时)处理它。
流式管道围绕消息代理构建——像Apache Kafka或AWS Kinesis这样的工具,位于数据生产者(应用、传感器、服务)和消费者(管道、分析引擎)之间。
生产者将事件发布到主题。消费者订阅这些主题并在每个事件到达时处理它。代理将事件保存在缓冲区中,这样如果消费者短暂宕机,它可以在不丢失数据的情况下追赶。
如果批处理摄入就像每天收到一份报纸,那么流式处理就像实时新闻滚动条。报纸对于昨天的新闻来说很好。滚动条存在是因为有些事情不能等到早上。
4.1 需要流式处理的实际场景
- 一个需要在可疑交易清算之前标记它的欺诈检测系统——24小时的批处理延迟不是选项
- 电商网站在促销活动期间显示实时订单数的实时仪表板
- 来自工厂设备的物联网传感器数据,需要立即进行异常检测
4.2 常用工具
Apache Kafka、AWS Kinesis、Google Pub/Sub、Apache Flink、Spark Structured Streaming
以下是Apache Kafka的示例
from kafka import KafkaProducer, KafkaConsumer # pip install kafka-python
import json
import time
# --- Producer side: simulating an app that publishes order events ---
producer = KafkaProducer(
bootstrap_servers="localhost:9092",
value_serializer=lambda v: json.dumps(v).encode("utf-8")
)
order_event = {
"order_id": "ORD-20241101-9921",
"customer_id": 4401,
"amount": 149.99,
"timestamp": "2024-11-01T14:23:01Z"
}
producer.send("orders", value=order_event) # publish event to the 'orders' topic
producer.flush()
# --- Consumer side: pipeline that processes events as they arrive ---
consumer = KafkaConsumer(
"orders",
bootstrap_servers="localhost:9092",
auto_offset_reset="latest", # only process new events, not historical ones
value_deserializer=lambda m: json.loads(m.decode("utf-8"))
)
for message in consumer:
event = message.value
print(f"Processing order {event['order_id']} — ${event['amount']} at {event['timestamp']}")
# downstream: write to a real-time analytics table, trigger alerts, etc.

38毫秒——从事件发布到事件处理的时间——这就是为什么流式处理是为时间敏感用例而构建的。
5、基于API的摄入
大多数现代SaaS工具——Salesforce、Stripe、HubSpot、Google Analytics——不会给你直接的数据库访问。相反,它们暴露一个API:一个结构化接口,让你可以以编程方式逐个端点请求数据。
基于API的摄入意味着你的管道调用这些端点,对结果进行分页,处理速率限制,并将数据存放到你可以工作的地方。
API摄入的技术现实比其他方法更复杂,这就是为什么它排在最后。
你需要处理:
- 身份验证(OAuth令牌、API密钥)
- 速率限制(大多数API限制每分钟或每天的请求数)
- 分页(数据以100或1,000条记录的页面返回,所以你必须循环遍历所有页面)
- 模式变更(API提供商可以在不警告的情况下添加、重命名或删除字段)
一个构建良好的API摄入作业会优雅地处理所有这些。当我第一次构建API摄入时,我很容易就达到了速率限制,这让我学会了如何策略性地处理它。
如果你想深入了解如何逐步构建生产级API摄入管道,我在本文末尾的链接中写了一篇完整的 walkthrough 文章。
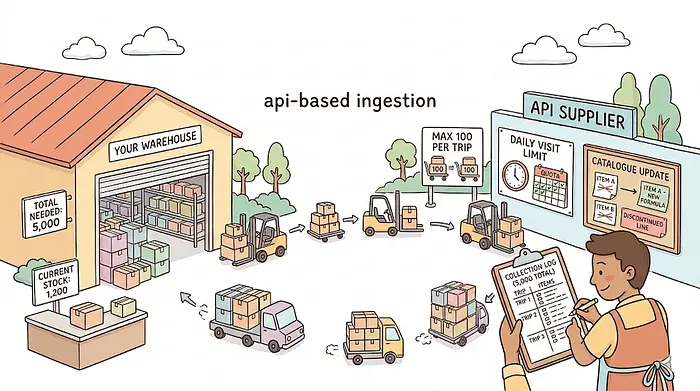
把它想象成从一个每次只让你收取100个单位的供应商那里补充仓库。你总共需要5,000个单位,所以你计划50次行程,并保留每次运行收集内容的清单(分页)。
供应商执行每日访问限制,所以你安排行程以保持在配额内(速率限制)。如果供应商重新组织了他们的目录——重命名产品或停产一条产品线——你的清单将不再匹配,你必须更新请求方式(模式变更)。
与走进你自己的仓库拿你需要的东西不同,通过API工作意味着按照别人的规则行事。
5.1 需要API摄入的实际场景
- 将Stripe支付记录拉入你的数据仓库用于收入分析
- 每晚摄入Google Analytics页面浏览数据用于营销归因模型
- 从第三方API获取天气数据以丰富配送路线规划
5.2 常用工具
Airbyte(预构建连接器)、Singer(开源taps)、requests(Python)、httpx、dlt(数据加载工具)
Requests是一个帮助我处理API调用的流行库。我在项目中经常使用它。以下是代码:
import requests # pip install requests
import pandas as pd
API_KEY = "your_stripe_api_key"
BASE_URL = "https://api.stripe.com/v1/charges"
all_charges = []
params = {"limit": 100} # Stripe returns max 100 records per page
while True:
response = requests.get(
BASE_URL,
auth=(API_KEY, ""), # Stripe uses API key as basic auth username
params=params
)
data = response.json()
all_charges.extend(data["data"]) # append this page's records
if not data["has_more"]:
break # no more pages — exit the loop
# Cursor-based pagination: use the last record's ID as the starting point
params["starting_after"] = data["data"][-1]["id"]
df = pd.DataFrame(all_charges)
print(f"Fetched {len(df)} charges from Stripe API")
# Save to destination
df.to_csv("stripe_charges.csv", index=False)

12页拉取了1,147条记录——速率限制窗口中还剩88个请求,足以进行下一次运行。
6、常见错误:对所有事情使用一种方法
最昂贵的摄入错误不是选错了工具——而是将摄入视为一刀切的决策。
工程师选择全量加载因为它简单,然后想知道为什么当源表增长到8000万行时他们的管道在凌晨3点超时了。
或者他们在一个记录会被删除的表上构建增量加载,然后花一周时间调试为什么他们的分析不对。
方法应该跟随数据。在构建任何东西之前问三个问题:
- 这个数据多久变化一次?
- 它有多大?
- 它会被删除吗?
答案几乎总是会指向正确的方法。
7、选择正确的方法
以下是每种方法最适合的快速参考——以及什么时候不适合。
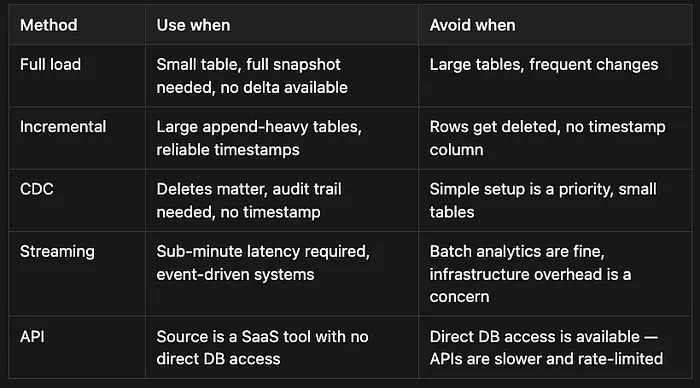
原文链接: 5 Data Ingestion Methods Every Data Engineer Should Know
汇智网翻译整理,转载请标明出处
