构建AI代理的6个常见错误
六个代理工程错误,它们会静默破坏生产系统,包含真实数据和修复方案

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
那是一个周四的下午,我收到了Slack消息。
我们的支持代理已经在生产环境中运行了六周。响应速度很快,用户似乎很满意,仪表板显示绿色。
然后我们的一位客户发来邮件: 代理两周来一直在提供相同的错误退款政策。不是报错。不是崩溃。而是大规模地自信地给出错误信息。
我们追溯到问题出在一个变得臃肿的上下文窗口,模型正在悄悄地将我们三周前添加的更新政策降权。政策在那里。模型忽略了它。每个"成功"响应都是我们没有 catch 到的谎言。
那一刻让我学到的代理工程知识比任何会议演讲、论文或书籍都多。
经过多年构建代理,我几乎将每次失败追溯到相同的六个错误。
它们单独看起来很小。在生产中,它们会复合成我刚才描述的那种静默灾难。
这是我从那些失败中构建的诊断框架。
0. AI代理实际上是什么——以及它如何破坏。
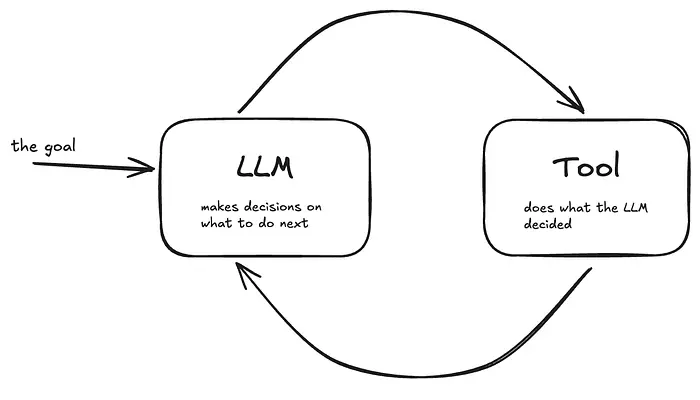
大多数人认为AI代理"只是一个带工具的模型。"不是。
代理是一个循环,模型在其中观察、决定、行动,并自主推理。
问题?大多数生产中的"代理"悄悄跳过后两个部分:
- 它们不规划。
- 它们不评估。
- 它们只是反应。
那不是代理。那是带随机性的循环。
这篇文章中几乎每个错误都最终来自那个单一误解。
错误1:把上下文窗口当作垃圾桶

当东西坏了,反射就是添加更多上下文。更多规则。更多历史。更多例子。推理听起来合理: 如果模型看到一切,它会表现更好。
实际发生的事情在"迷失在中间"研究中有记录:
模型显著更多地关注提示开头和结尾的内容。埋在密集中间部分的指令被降权。 这叫做上下文腐烂。
在一个内部测试中,将关键约束从6000令牌提示中的位置3000移动到位置500,在相同查询上 adherence 从61%提高到94%。
上下文窗口是工作内存,不是硬盘。
每个LLM调用应该有一个作用域任务,只有该任务需要的上下文。
在每次调用前问: 这个特定决定绝对最少需要什么?修剪其他一切。将持久化移到你选择性读取的内存层。
实际规则: 从单个提示开始。如果它能完成任务,停止。如果它在特定场景下失败,添加一个针对性步骤。不要分成数十个提示,因为那会产生更多LLM调用、更高延迟和更难的调试。上下文工程是深思熟虑的选择,不是积累。
可推文: "上下文窗口不是存储。你添加的每一字节都在与你最重要的指令竞争。"
错误2:在赢得复杂性之前构建架构
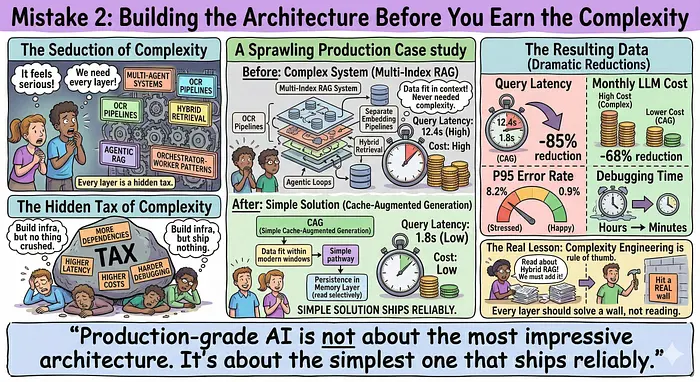
多代理系统有一种诱人的魅力。OCR管道。混合检索。编排器-工作模式。代理RAG。感觉像是构建AI的严肃方式。
每一层都是隐藏的税。更多依赖、更高的延迟、更高的成本、更难的调试。 团队花几个月构建基础设施,结果什么也没发布。
以下是生产案例的实际数据: 一个团队用缓存增强生成替换了他们的主要工作流的多索引RAG系统(带OCR管道、单独嵌入管道、混合检索和代理循环)。结果:
- 查询延迟:12.4秒→1.8秒(减少85%)
- 每月LLM成本:减少68%
- P95错误率:从8.2%降至0.9%
- 每次事件的调试时间:从小时缩短到分钟
数据适合现代上下文窗口。他们从不需要这种复杂性。
从可能工作的最简单解决方案开始。只有当你碰到真正需要它们的墙时才添加层。大多数团队添加复杂性是因为他们读到了它,而不是任务要求。
可推文: "生产级AI不是关于最令人印象深刻的架构。是关于最简单且能可靠发布的架构。"
错误3:能用工作流时却用代理
这个错误比其他任何都代价更高,而且从内部最难看到。
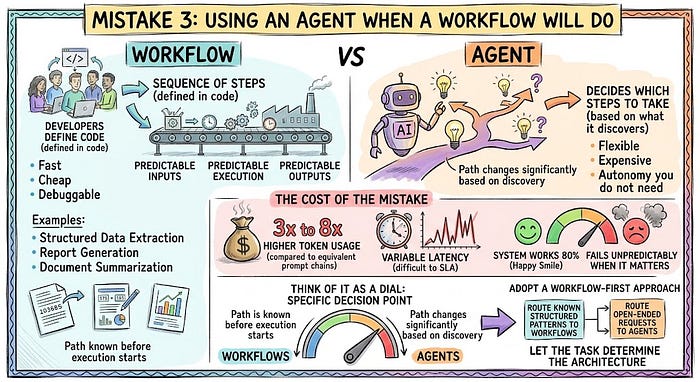
工作流是你在代码中定义的一系列步骤。可预测的输入、可预测的执行、可预测的输出。代理根据它发现的内容决定采取哪些步骤。工作流快速、便宜且可调试。代理灵活但昂贵。
大多数团队将代理架构分配给本质上是工作流任务。 结构化数据提取、报告生成、文档摘要。这些有已知路径。给它们代理架构意味着为你不需要的自主性付费。在实践中,这意味着:
- 与等效提示链相比,token使用量高3到8倍
- 难以SLA的可变延迟
- 一个系统80%的时间工作,但在关键时刻不可预测地失败
把它想象成一个带特定决策点的转盘:
- 工作流:任务路径在执行开始前已知
- 代理:路径根据代理发现的内容显著改变
采用工作流优先方法。只有当系统必须自主规划、探索未知路径或从设计时无法预测的失败中恢复时才引入代理。
对于垂直代理,将已知结构化模式路由到工作流,将开放性请求路由到代理。让任务决定架构。
错误4:像对待可靠文本一样解析LLM输出
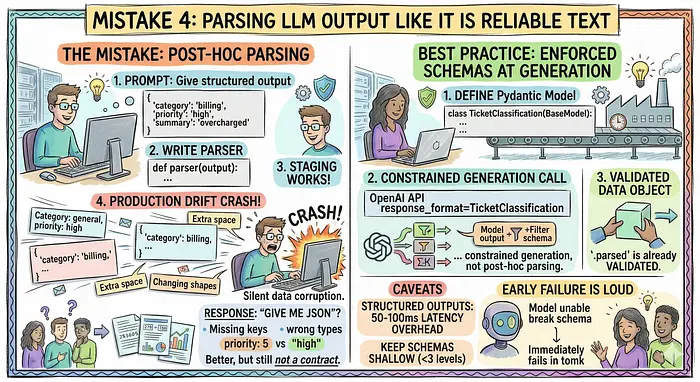
你提示模型获取结构化输出。它返回看起来像结构化的东西。你写了一个解析器。它在预发布环境工作了三周。
然后有一天,缺少一个逗号。多一个空格。不同的大小写模式。生产崩溃。模型没有改变。输出轻微漂移,非确定性系统会这样做。
许多团队通过对提示JSON来响应。
比自由形式文本好,但仍不是契约。你仍然会得到缺失的键、错误的类型,以及跨运行改变形状的嵌套字段。来自提供商的模型更新会以你没有测试的方式破坏你的解析器。
停止将LLM输出当作文本对待。在生成时将其当作有模式 enforced 的数据对待。
from pydantic import BaseModel, Field
from openai import OpenAI
client = OpenAI()
class TicketClassification(BaseModel):
# Field descriptions become part of the model's schema constraint
category: str = Field(description="One of: billing, technical, general")
priority: str = Field(description="One of: high, medium, low")
summary: str = Field(description="One sentence summary, max 20 words")
response = client.beta.chat.completions.parse(
model="gpt-4o",
messages=[{"role": "user", "content": f"Classify this ticket: {ticket_text}"}],
response_format=TicketClassification, # constrained generation, not post-hoc parsing
)
# .parsed is already a validated TicketClassification object.
# If the model cannot conform to the schema, it fails here.
# The failure is loud and immediate, not silent and three functions later.
result = response.choices[0].message.parsed
response_format=TicketClassification 告诉API将生成约束为匹配模式的有效JSON。当模式说它必须是三个特定值之一时,模型不能产生 "category": "urgent"。违规在边界处失败,而不是破坏你的数据管道。
值得知道的注意事项:结构化输出增加50到100ms延迟开销。保持模式浅,嵌套少于三级。只有在结构真正需要时才使用这个。如果你需要纯文本,接受字符串。
错误5:只是带随机性的循环
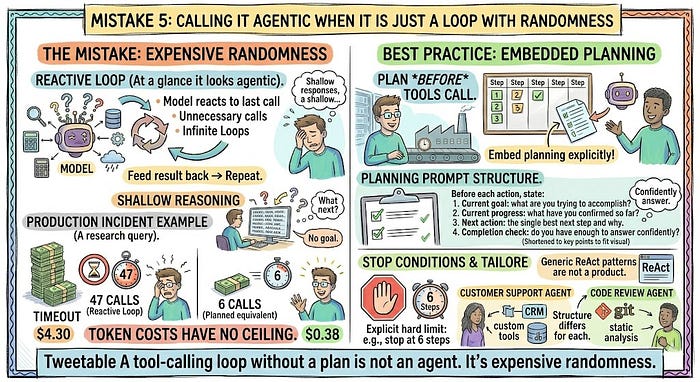
图片由作者提供
一个不断出现的模式: 给模型工具,让它选一个,将结果反馈,重复。
乍一看它看起来像代理。不是。
模型在响应上一次工具调用,而不是朝向目标推进。它没有计划。它没有停止条件。它没有办法评估自己的进度。
没有嵌入规划,循环会产生不必要的工具调用、无尽循环和浅层推理。
Token成本没有上限。
在一个生产事件中,一个处理研究查询的代理在超时前做了47次顺序工具调用,每次会话成本4.30美元,而等效有计划的平均6次调用仅0.38美元。
在任何工具被调用之前,明确地将规划嵌入循环。
PLANNING_PROMPT = """
Before each action, state:
1. Current goal: what are you trying to accomplish?
2. Current progress: what have you confirmed so far?
3. Next action: the single best next step and why.
4. Completion check: do you have enough to answer confidently?
Hard limit: stop at 6 steps regardless of completion status.
If you cannot answer within 6 steps, say so explicitly. Do not fabricate.
"""
停止条件不是可选的,它们不是建议。
没有在提示中的明确硬限制,模型将继续。博客文章中的通用ReAct模式不是产品。根据你的特定工具、数据和失败模式定制规划结构。客户支持代理和代码审查代理需要不同的规划结构。**
可推文: "没有计划的工具调用循环不是代理。是昂贵的随机性。"
错误6:没有评估就发布,然后从用户那里发现回归
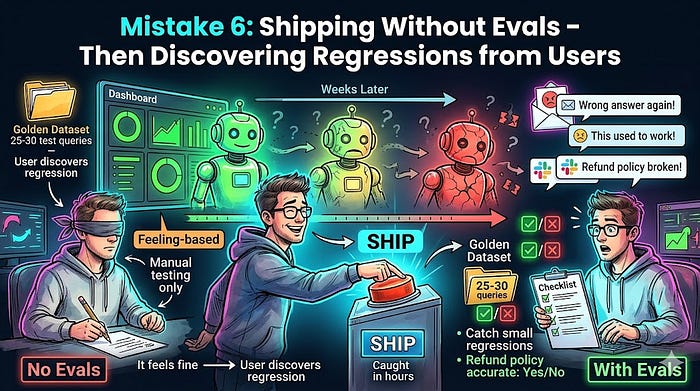
图片由作者提供
这个错误有最长的损害尾巴,而且最容易无限期推迟。
你构建功能、手动测试、发布。没有正式指标。没有自动化评估。没有定义的成功标准。每次发布都是赌注。你从用户发邮件而不是你自己的系统发现回归。
痛苦现实: AI系统不会坏。它们会衰减。
提示变更、提供商的模型升级、链中的新工具,任何这些都会导致微妙的行为变化,这些变化 invisible 直到它们在数周内复合。
没有评估,你无法判断变更改进了还是降解了系统。你用感觉回答"它工作吗?"
在发布前定义二进制、任务特定的指标。不是"有用性:3.7/5。"那告诉你什么都不是。
相反:"正确工具选择:是/否。""响应匹配基本事实:是/否。""退款政策准确引用:是/否。"二进制指标是可自动化的、跨版本可比较的,以及失败时可操作的。
发布前构建黄金数据集: 25到30个有已知正确答案的真实查询,涵盖主要用例和五个已知边缘案例。每次部署前运行。不是为了100%通过率。为了增量:什么改变了,变更是有意的吗,是改进吗?
持续这样做的团队在数小时而不是数周内 catch 回归。 平均检测时间的差异通常是生产事件和周二早晨修复之间的区别。
隐藏的复合问题
这六个错误都不存在于孤立状态。它们堆叠。
- 臃肿的上下文窗口使模型不一致。
- 不一致的行为使你的解析器不可预测地失败。
- 解析器失败意味着你没有干净的数据来评估。
- 没有评估,你发布了一个回归。回归添加不规则行为。
- 不规则行为触发"通过添加更多上下文修复",这使错误1更糟。
每个陷在PoC(概念验证)炼狱中的代理系统至少同时有这三个活跃。 感觉无法解决的原因是你在调试症状,而根本原因不断相互触发。
修复顺序很重要:
- 首先评估和输出解析:它们让你看到实际发生了什么
- 然后上下文和规划:它们修复行为不稳定性
- 最后架构:一旦你理解系统实际需要什么,就简化
按错误的顺序修复意味着你在调优一个你无法测量的系统。
没人告诉你的事
大多数AI工程内容专注于让代理更有能力:更好的模型、更聪明的提示、更花哨的架构。
这是生产系统的错误焦点。
能力是简单的部分。模型有能力。困难的是让它周围系统可靠:紧凑的上下文窗口、正确的自主级别、强制输出合约、嵌入规划、持续评估。构建脚手架,上面的大多数生产失败永远不会发生。跳过它,你就在构建演示,不是产品。
"不可预测的AI代理不是智能。是工程糟糕。"
生产中工作的代理不是那些有最聪明模型的。是那些工程师对上下文、架构、规划、输出处理和测量做出深思熟虑决定的。这六个错误都是工程决策,不是模型限制。
模型从来不是问题。它从来不是。
原文链接: 6 Mistakes I Learned the Hard Way That Break Every Agentic App in Production
汇智网翻译整理,版权归作者所有,转载需标明出处
