9个最强大的本地开源LLM
可以在本地运行的开源模型家族,其在现实世界中的性能现在惊人地接近商业级模型。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署 | Tripo 3D | Meshy AI
除了排行榜头条之外,我还将介绍本地设置(例如 Claude Code 和 Codex)、硬件层级指南(NVIDIA GPU 和 Mac 设置),以及操作陷阱、故障模式和权衡:延迟、内存占用、工具使用、编码可靠性和指令遵循质量。
这种情况发生有两个主要原因。
首先,开源模型现在可以处理有意义的日常工作任务。对于大量的编码、写作、自动化和代理任务,你不再需要每一步都默认使用 Opus 4.6。
其次,本地备份有助于保留昂贵的积分。如果你正在运行代理集群、大量迭代或委托大量子任务,本地模型是避免在不需要 Opus 4.6 或 Codex 5.3 积分的工作上烧毁积分的最简单方法之一。
此外,如果你一年前告诉我,开源模型会在 SWE-bench Verified 上与顶级闭源模型接近,我会礼貌地表示怀疑。
但对于一组范围明确的任务,这种性能差距已经大幅缩小。
像 MiniMax M2.5、GLM-5 和 Qwen3.5(27B 密集型) 等模型的最新结果显示了在标准化编码评估上的真正竞争力,在某些情况下接近与较小或中端商业选项的平价。
我这里需要谨慎:基准测试仍然是基准测试。现实世界的编码性能取决于远不止一个分数的因素,包括工具使用、上下文处理、长时间会话中的一致性,以及模型在实际开发工作流程中的表现如何。
但趋势线是 unmistakable 的。
对于许多任务,开源模型正在成为默认选择,付费的前沿模型越来越成为升级路径。
0、架构革命
传统的密集模型为每个令牌激活每个参数。70B 模型需要加载并运行所有 70B 参数。MoE 模型不同,它们拥有庞大的总参数计数,但每个令牌只激活一小部分(与当前任务相关的专家)。
这是最新 Qwen 3.5 35B-A3B 模型的秘密武器,一个 35B 参数的模型超越了其 235B 参数的前身,同时每个令牌只激活 3B 参数。
这非常重要,因为 VRAM 要求主要由需要加载的模型的总参数(文件大小)决定,而活动参数决定了 LLM 的速度和计算要求。
这意味着一个拥有 10B 活动参数的 230B MoE 模型可以在比其密集版本更适度的硬件上运行。
让我分解一下现在值得了解的每个模型。
1、Qwen 3.5 Medium 系列
阿里巴巴的 Qwen 团队一直在发力,3.5 Medium 系列可以说是 2026 年对本地模型用户最重要的版本。
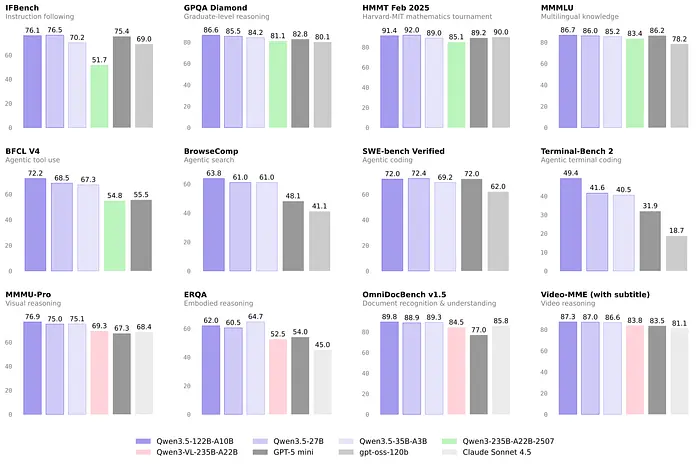
Qwen3.5–35B-A3B:这是消费级硬件的头条产品。350 亿总参数,但由于其混合注意力 + MoE 架构,推理时只有 30 亿活动参数。它超越了之前的 Qwen3–235B-A22B 旗舰产品。它在 SWE-bench Verified 上得分 69.2%,至关重要的是,当量化为 Q4 时,它可以在只有 8GB VRAM 的 GPU 上运行。这是一款笔记本 GPU。这是一款 2022 年的游戏 PC。
这里也有我最近发表的关于 Qwen3.5–35B-A3B 的深度分析:
Qwen3.5–27B(密集型):对于那些有更多空间的人来说,密集的 27B 版本在 SWE-bench Verified 上与 GPT-5 mini 打平,得分 72.4%。需要 16-24GB VRAM,因此单张 RTX 4090 或 M 系列 Mac 可以轻松处理。
Qwen3.5–122B-A10B:中端 MoE 选项。122B 总计,10B 活动,在 SWE-bench 上得分 72.0%。需要比 35B 版本更多的内存,但为拥有硬件的人提供更好的性能。
Qwen3.5 Flash:针对延迟敏感用例的速度优化变体。我自己还没有对它进行大量基准测试,但早期报告表明它对于需要近乎即时响应的交互式编码非常出色。
2、Qwen3-Coder 系列
与 Qwen 3.5 Medium 系列分开,Qwen3-Coder 家族是专门为编码任务而构建的。
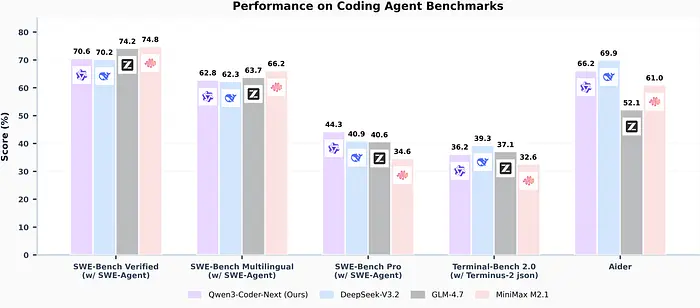
Qwen3-Coder-30B-A3B:另一个专门针对代码优化的 MoE 模型。需要约 18GB+ VRAM。它在 Terminal-Bench 2.0 Hard 上 15.2% 的分数单独看起来可能很低,但 Terminal-Bench Hard 测试复杂的多步骤终端操作,即使是顶级闭源模型也难以应对。
Qwen3-Coder-480B-A35B:旗舰编码器。480B 总参数,35B 活动。这是一个需要严肃硬件的严肃模型(我们说的是 64GB+ Mac 统一内存或多 GPU 设置),但它是 Qwen 产品线中最强大的开源编码专用模型。
Qwen3-Coder-Next-80B-A3B:一个有趣的中间地带,只有 3B 活动参数但 80B 总计。我还没有在本地运行它,但参数效率比是惊人的。
3、GLM-5
这个值得特别关注的原因有几个。来自智谱 AI 的 GLM-5 是一个拥有 40B 活动参数的 744B MoE 模型。它在 SWE-bench Verified 上得分 77.8%,在 Terminal-Bench 2.0 上得分 56.2%。这些数字使其接近 Claude Sonnet 4.6。
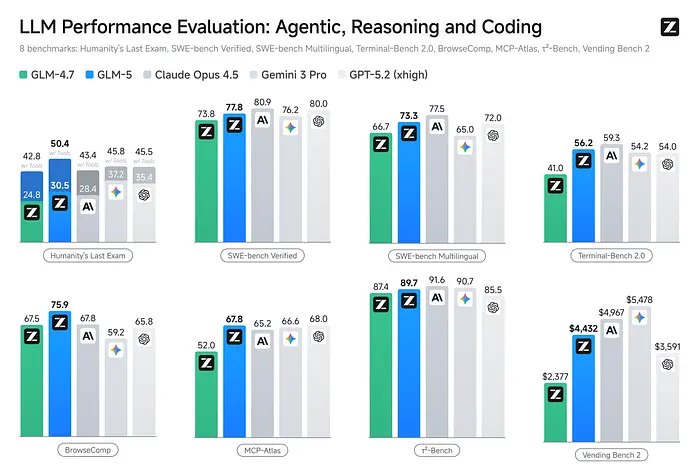
但这里真正有趣的是:它是 MIT 许可的,并且完全在华为昇腾芯片上训练,没有涉及 NVIDIA 硬件。从纯技术角度来看,在非 NVIDIA 加速器上训练的模型能够达到这些数字这一事实是重要的。
在本地运行 GLM-5 需要大量的硬件。拥有 40B 活动参数,你需要 128GB+ 的系统。配备 192GB 统一内存的 Mac Studio 或多 H100 设置。不适合所有人,但 MIT 许可意味着你可以随心所欲地部署它。
4、GLM-4.7
更易访问的兄弟版本。355B 总参数,32B 活动,在 SWE-bench Verified 上得分 73.8%,在 Terminal-Bench 2.0 上得分 41%。同样是 MIT 许可的,同样在华为昇腾上训练。这款适合 64GB Mac 或双 GPU 工作站,使其成为大多数开发人员更实用的选择。

GLM-4.7 与 GLM-5 争议
社区开始了重要的讨论,由一位独立开发人员的独立基准测试(70 个真实的 GitHub 任务,3000 美元以上自筹资金)发现,量化的 GLM-4.7 在困难的代理编码任务上超越了所有 Qwen 3.5 模型和 GLM-5(ELO 1572)。
推测是智谱可能故意降低了 GLM-5 的等级以管理计算要求,以便在其 IPO 之前。
5、MiniMax M2.5
好吧,我需要诚实,这个模型让我重新思考了一切。
MiniMax M2.5 在 SWE-bench Verified 上得分 80.2%。这与 Claude Opus 4.5(80.9%)相当。
它是一个拥有仅 10B 活动参数的 230B MoE 模型。
如果你有硬件,可以通过 llama.cpp 在本地运行它。10B 活动参数计数是可控的,它是需要大量 RAM/VRAM 进行加载的总模型大小。
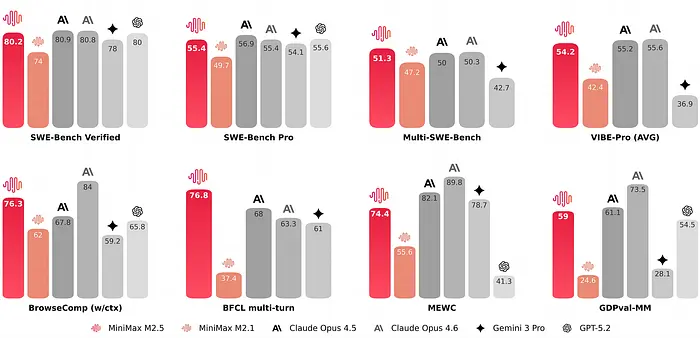
MiniMax M2:原始版本,相同架构(230B MoE,10B 活动),基准测试分数略低。仍然非常有能力,可能更容易找到量化权重。
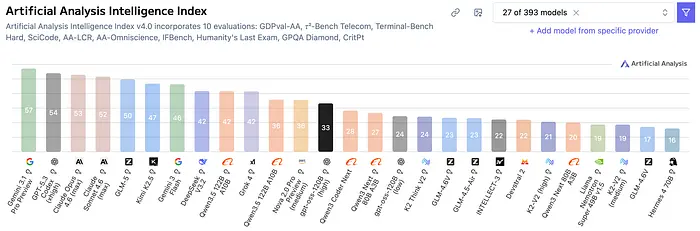
6、GPT-OSS(20B 和 120B)
GPT-OSS 是 Apache 2.0 许可的,使用 MoE 架构,有两种尺寸。
- GPT-OSS-20B:在 GPQA 上得分 71.5%(注意:与 SWE-bench 不同的基准测试,测量一般科学推理)。需要约 15GB RAM。这是极其可访问的,大多数现代笔记本电脑都可以处理。
- GPT-OSS-120B:更大的变体,适合那些想要更多能力并拥有支持它的硬件的人。
GPT-OSS-20B 拥有 3.6B 活动参数(21B 总计),GPT-OSS-120B 拥有 5.1B 活动参数。
我觉得 OpenAI 在 Apache 2.0 下发布真正开放模型的某种超现实。
更多用于本地部署的高质量选项。
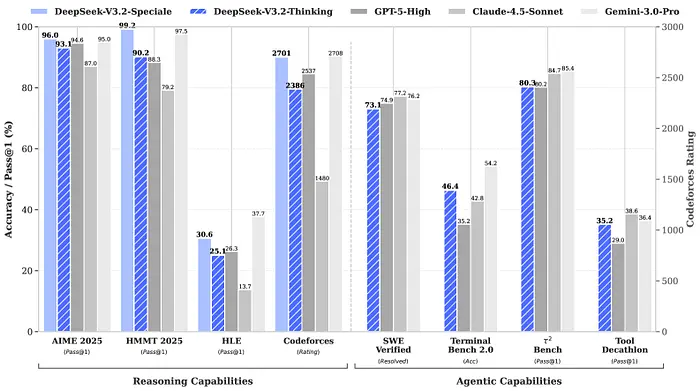
7、DeepSeek V3.2 和 V3.2-Speciale
DeepSeek 一直是开源模型空间中持续存在的存在。V3.2 在 SWE-bench Verified 上得分 72-74%(取决于思考模式),在 Terminal-Bench 2.0 上得分 37.7%。
Speciale 变体提供了一些优化。
不是此列表上最高的基准测试数字,但 DeepSeek 模型往往在实际编码场景中超越其重量,至少根据我的经验。
它们的训练数据和调整使它们在整体上理解代码库方面特别好。
8、Devstral Small 2
Mistral 的以编码为重点的模型。
作为 Apache 2.0 下的 24B 模型,它在 SWE-bench Verified 上得分 68.0%,并在单张 RTX 4090 或配备 32GB RAM 的 Mac 上运行。这使其成为中级类别中的强有力的竞争者。
为了透明起见,我还没有花太多时间在这个模型上,但 Mistral 在高效模型方面的记录是强有力的。
如果你已经在 Mistral 生态系统中,值得评估。
9、Kimi K2.5
来自月之暗面人工智能,Kimi K2.5 很雄心勃勃:1.04 万亿总参数,32B 活动,多模态,专为代理工作流程而设计。
Kimi K2.5 的旗舰功能是代理集群,能够协调多达 100 个并行工作的子代理,实现 4.5 倍的执行加速。这是一个真正值得强调的差异化功能。
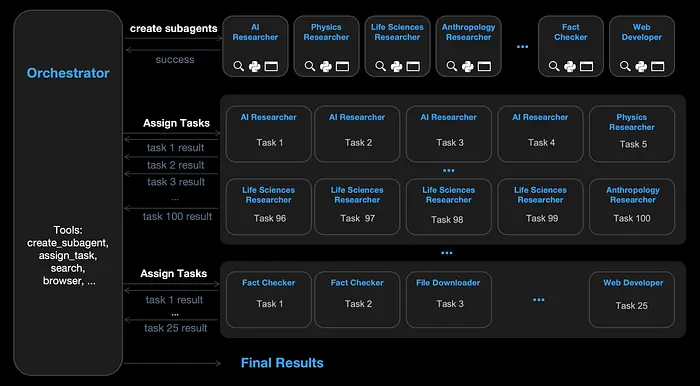
多模态方面对于编码也很有趣,想想截图到代码、从视觉输入进行 UI 调试或图表解释。
32B 活动参数计数意味着它需要不错的硬件,但总活动与活动的比例是此列表中最极端的。
10、设置本地模型
理论已经足够了。让我向您展示我实际上如何运行这些东西。
设置 1:Ollama + 使用本地模型的 Claude Code
这是我的日常驱动设置。
步骤 1:安装并拉取你的模型
# 安装 Ollama(如果你还没有)
curl -fsSL https://ollama.ai/install.sh | sh
# 拉取模型 - 我建议从 Qwen3.5-27B 开始
ollama pull qwen3.5:27b
# 或者如果你使用受限的硬件,使用 MoE 变体
ollama pull qwen3.5:35b-a3b-q4_K_M
步骤 2:配置 Claude Code 以使用你的本地模型
# 设置这些环境变量(添加到你的 .bashrc 或 .zshrc)
export ANTHROPIC_BASE_URL="http://localhost:11434"
export ANTHROPIC_AUTH_TOKEN="ollama"
# 现在正常运行 Claude Code
claude
就是这样。Claude Code 的代理循环,即文件读取、编辑、终端命令,整个东西都可以对你的本地模型工作。
ANTHROPIC_AUTH_TOKEN 可以是任何非空字符串,因为 Ollama 不需要身份验证。
确保 Ollama 实际上正在运行并已完成加载模型,然后再启动 Claude Code。我在调试连接错误时尴尬地花了二十分钟,然后才意识到我没有启动 Ollama 服务器。如果它没有作为系统服务运行,请在单独的终端中运行 ollama serve。
注意:多个用户报告了这种方法的问题,特别是 Qwen3.5–35B-A3B 卡在无限循环中。
你也有以下选项:
- 直接使用 llama.cpp 而不是 Ollama(多个用户报告更好的结果)
- 禁用扩展思考模式
- 使用 LiteLLM 作为代理以获得更好的超时控制
设置 2:使用本地模型的 OpenAI Codex CLI
OpenAI 的 Codex CLI 也通过其 --oss 标志支持本地模型:
# 安装 Codex CLI
npm install -g @openai/codex
# 使用本地 Ollama 模型运行
codex --oss
# 或者明确指定模型
OPENAI_BASE_URL="http://localhost:11434/v1" codex --model qwen3.5:27b
--oss 标志是一个不错的点缀,它会自动配置 CLI 以查找本地 Ollama 实例。减少对环境变量的摆弄。
设置 3:本地运行 Qwen3.5
让我介绍一下我推荐的起点的完整设置:
# 1. 确保 Ollama 正在运行
ollama serve
# 2. 拉取模型(27B 下载约 16GB,35B-A3B Q4 下载约 4GB)
ollama pull qwen3.5:27b
# 3. 首先交互式测试它
ollama run qwen3.5:27b "编写一个 Python 函数来解析嵌套 JSON 并进行错误处理"
# 4. 对于 Claude Code 集成
export ANTHROPIC_BASE_URL="http://localhost:11434"
export ANTHROPIC_AUTH_TOKEN="ollama"
cd your-project-directory
claude "重构身份验证模块以使用 JWT 令牌"
# 5. 对于 Codex CLI 集成
export OPENAI_BASE_URL="http://localhost:11434/v1"
export OPENAI_API_KEY="ollama"
codex "为 src/utils/ 添加全面的测试覆盖"
11、其他值得了解的 CLI 工具
OpenCode:这个工具已经在 GitHub 上悄悄积累了 100K+ 星星、700 个贡献者和 250 万月度开发者。它开箱即支持 75+ 提供商,包括本地 Ollama。如果你想要一个适用于所有内容的单一工具,这可能就是它。
Aider:本地模型编码工具空间的老手。出色的 git 集成,擅长多文件编辑。通过其 OpenAI 兼容的 API 支持与本地模型配合良好。
Cline 和 Roo Code:支持本地模型后端的 VS Code 扩展。如果你更喜欢留在编辑器中而不是使用 CLI 工具,这些是可行的选择。Cline 特别对 VS Code 环境中的代理工作流程有良好的支持。
12、硬件层级指南
好吧,真实谈话。你实际需要什么?
入门级(8GB VRAM) 0-300 美元(二手 GPU)
- 运行: Qwen3.5-35B-A3B Q4
- 体验:对于单文件任务出人意料地有能力。重构、测试编写、错误修复。难以应对大型代码库理解。
- 硬件示例: RTX 3060 8GB、RTX 4060、M1/M2 MacBook Air(8GB)
中级(16-24GB VRAM) 400-1200 美元
- 运行: Qwen3.5-27B、GPT-OSS-20B、Qwen3-Coder-30B-A3B
- 体验:这是最佳选择。这些模型处理多文件重构、理解项目结构,并持续生成生产质量代码。
- 硬件示例: RTX 4090、RTX 5080、M2/M3 Pro MacBook Pro(18–36GB)
高级(64GB+ Mac / 多 GPU) 2000-5000 美元
- 运行: GLM-4.7、Qwen3-Coder-480B 量化、Qwen3.5-122B-A10B
- 体验:对于大多数任务与云 API 接近平价。这些模型确实很优秀。
- 硬件示例: Mac Studio M2/M3 Ultra(64–192GB)、双 RTX 4090/5090
超高级(128-256GB) — 预算:5000 美元以上
- 运行: GLM-5(完整)、MiniMax M2.5(完整)
- 体验:如果你这样做,你可能不需要我告诉你关于它。
- 硬件示例: Mac Studio M4 Ultra 256GB、多 H100 工作站
这里有一个示例设置:配备 M2 Ultra 和 128GB 统一内存的 Mac Studio。它可以同时运行 GLM-4.7 和 Qwen3.5–27B,你可以根据任务在它们之间切换。包括机器在内的总成本约为 4000 美元(例如,翻新的)。
13、陷阱和故障模式
因为没有什么事情像文章所说的那样顺利,这里是我会咬你的事情的清单:
- 上下文窗口限制:大多数本地模型在 32K-128K 令牌处达到顶峰。像 Claude 这样的云模型提供 200K+。如果你正在处理非常大的代码库,你会遇到这个障碍。变通方法是使用智能上下文检索的工具(Aider 在这方面很好),而不是将整个仓库填充到上下文中。
- 首个令牌延迟:从磁盘加载大型模型需要时间。我的 GLM-4.7 从冷启动加载大约需要 45 秒。保持 Ollama 作为持久服务运行以避免这种情况。
- VRAM 不是 RAM:如果你的模型超过可用 VRAM 并溢出到系统 RAM,推理速度会下降 5-10 倍。检查
ollama ps以确保你的模型完全驻留在 GPU 上。 - Ollama 模型命名不一致:Ollama 注册表上的模型名称并不总是与论文或 Hugging Face 中使用的名称匹配。仔细检查你拉取的是正确的变体。
- 代理循环可能会失控。没有云提供商在其 API 中构建的护栏,本地模型有时会卡在循环中,特别是在模棱两可的任务上。密切注意令牌生成并准备按 Ctrl+C。在你的客户端配置中设置
max_tokens限制会有所帮助。 - 更新模型是手动的。没有自动更新机制。新模型版本定期发布。设置提醒每月检查更新,或者使用
ollama pull --update等命令。
14、这一切的方向
硬件正在快速变便宜。苹果的统一内存架构一直是本地模型推理的礼物。
配备 32GB 的 Mac Mini 可以运行两年前需要 10,000 美元 GPU 设置的模型。随着 M4 和 M5 芯片增加内存带宽和容量,我上面描述的高级设置将成为中级定价。
你可以根据你的硬件从 Qwen3.5–27B 或 Qwen3.5–35B-A3B 开始。使用具有 Ollama Anthropic API 兼容性的 Claude Code。在实际工作中运行一周,并跟踪与之前使用的云 API 相比你多久感觉有限制。
我想你会感到惊讶。
云没有消亡。
对于团队、对于生产系统、对于最高风险的应用程序,托管 API 仍然有意义,但对于个人开发人员工作流程,你的本地 GPU 现在是一个真正的替代方案。
它让你的代码留在你的机器上,每个令牌没有任何成本,并且在你的互联网不工作时也能工作。
原文链接: 7 Local LLM Families To Replace Claude/Codex (for everyday tasks)
汇智网翻译整理,转载请标明出处
