传统机器学习与现代AI
“AI”,更具体地说大语言模型/基础模型,是神经网络,这是一个可以追溯到 1943 的机器学习概念,当时由于二战计算挑战(如破译密码),很多基础 AI 研究浮出水面。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我第一次接触机器学习是在本科认知科学专业(侧重计算机科学)的时候。
当我 19 岁时,一个同学给我画了这个函数,我假装听懂了他说的每一个字,内心却偷偷哭泣。这通常是我的策略:微笑、点头,然后感觉自己非常非常愚蠢。
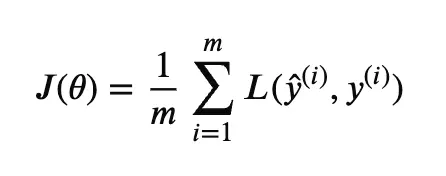
但他优雅地向我展示的内容(容我这么说)定义了我接下来十年的生活。虽然仍然感觉自己很愚蠢,而且经常内心仍在哭泣,我进入了一个机器学习的高级学位,最终获得了机器学习教育博士学位。那个特殊的函数(一个通用的损失函数)教会了我真正需要知道的基础知识。我于 2024 年获得博士学位,而整个 AI 领域正在转变。ChatGPT 于 2023 年发布,在此之前 GPT 模型已经可用了几 年(GPT-1 早在 2018 年,就在著名的 transformer 论文发布后)。现在,当然,一切都是关于 AI 代理。
我经常和学生开玩笑说,在 AI 变酷之前我就在做机器学习了。我很感激我的教育:1)主要在传统机器学习领域,2)我必须自己编写代码。我看到了理解机器学习基础的价值,所以让我直接切入正题,与你分享这些。以下是我作为 2023 年后的 AI 专业人员可能想要了解的关于机器学习的 6 个最重要要点。
1、最小化损失是一个基础概念
你知道线性回归通常是你学习的第一个“机器学习”算法吗?y = mx + b 对于解释其余的机器学习内容出奇地有用。下面是一个线性回归方程,展示了 y=mx + b 如何扩展到更多维度(特征),而不仅仅是你在高中学惯用的 2D 图表。简单来说,每个 特征 获得一个 权重,代表它对你正在建模的关系的重要性(加上一个截距和一点误差)。
例如*,我可以把学生考试成绩映射到他们每周学习的小时数,可能会得到一个线性关系。每增加一小时学习对最终考试成绩有一定 权重,但这只是 一个特征。其他事情可能也很重要,比如他们需要通勤多远、父母的工作、是否正在经历健康问题、他们参加多少课外活动,以及更多 特征。每个对最终考试成绩 (y) 有一些 权重。学习时间有多重要?大量缺勤有多重要?我们用回归来 学习这些权重。
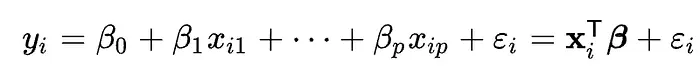
线性回归有我们所说的“闭式解”。你可以从方程中计算权重。神经网络没有这样的东西,这使它们非常神秘。采取更机器学习化的方法(这是一个科学术语),你可以做所谓 的 梯度下降,通过最小化预测线(如下所示的红色)与观察到的真实值之间的距离来迭代学习最佳权重。这些距离称为 残差。换句话说,你最小化 损失 以减少你预测的和你实际观察到的之间的差异。当你这样做时,你得到 最佳拟合线。
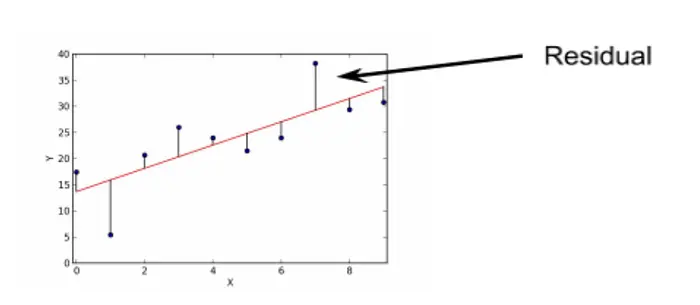
从本质上讲,所有机器学习都在做这种形式的事情。
- 世界上存在一些观察到的情境。考试成绩和参加考试的学生。康复率和完全康复的人。温度和我们使用的空调量。肌肉质量和得分……
- 一个 模型 是对观察数据如何产生的数学猜测(我非常贝叶斯)。
- 如果 模型预测 非常接近观察到的 真实值,你可能有一个好模型!你用数学的力量捕捉到了一个真实现象!
- 你甚至可以说模型告诉我们一些关于底层 数据生成过程 的事情,或者关于世界的一种真相。或者,你只是 使用 模型来对你需要了解的事情做出预测,比如预测四月春雨会产生多少五月花朵。☔🌸
最小化损失使你的模型尽可能接近数据中的真实关系。有许多不同的算法来做这个,但主要想法是尝试让 预测 与 真实值 最佳匹配的模型。
2、今天的 AI 仍然只是一个神经网络
“AI”,更具体地说大语言模型/基础模型,是神经网络,这是一个可以追溯到 1943 的机器学习概念,当时由于二战计算挑战(如破译密码),很多基础 AI 研究浮出水面。
与线性回归不同,神经网络没有训练它的闭式解。从本质上讲,它们更多地依赖“猜测和检查”,但通过对训练作为 凸优化问题 的非常 明智 的猜测,可以用 梯度下降 来解决。但从本质上讲,权重仍然被学习以密切匹配观察到的数据,并产生一个能够根据该观察到的数据可靠地 预测输出 的模型。
我喜欢请人们完成这个句子:🍋 “当生活给你柠檬,做…… ________”🍋如果你想到“柠檬水”,恭喜!你的大脑训练得就像一个大语言模型一样。经过多年的观察,它学会了最可能的输出是“柠檬水”,尽管其他答案也可以接受,取决于你的大脑的 温度参数。
大语言模型也学会了这个关联,还有数十亿个。通过将语言编码为 向量空间 中的 嵌入,单词可以用几何方式表示,相似的单词靠得更近。这样,“柠檬”和“柠檬水”的向量在空间中更接近,特别是当它们的嵌入使用现代大语言模型中的上下文注意力机制学习时。
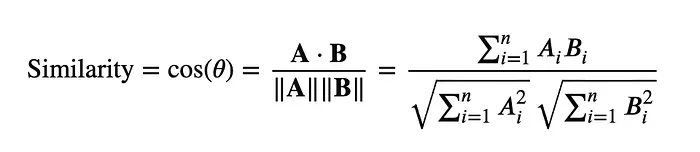
这些庞大的基础模型的权重已经被仔细调整,直到大语言模型的输出与预期输出匹配。损失 已经被最小化。非常简单,你可以给这些句子每个一个分数:
- ✅ 当生活给你柠檬,做 _柠檬水_!+1.00(目标)
- 当生活给你柠檬,做 _柠檬棒_!+.80(技术上正确)
- 当生活给你柠檬,做 _猫_!+.15(至少是名词?)
- 当生活给你柠檬,做 _是_!+0.01(语法上不合理)
因此,与期望最对齐的权重组合是“最佳”模型。不幸的是,这些模型不仅仅是预测一个句子完成,而是数万亿个。而且“柠檬水”可以出现在所有不同种类的句子中,不仅仅是这一个。所以我们陷入了一种情况,我们不能再简单地 查看 权重和残差来理解底层模型。相反,我们必须通过它的表现来近似模型学到了什么。
3、评估:训练集 vs 测试集
这就带我们回到传统机器学习。另一个基本概念是我们如何判断模型的质量。仅仅最小化损失实际上是不够的,由于所谓的 过拟合。让我们再 用柠檬举例。如果我的模型训练来回答“当生活给你柠檬,做 _柠檬水_!”,我可以得到满分。但现在想象一下这是我的测试集上的结果:
- ✅ 当生活给你柠檬,做 _柠檬水_!
- 我们推荐的饮料是 _柠檬水_!
- 汽油价格很高,你应该用 _柠檬水_ 加满你的油箱!
我的模型只知道预测柠檬水,别的都不会。我原来的测试项目得到了满分,但我的模型非常糟糕。这是一个基本的机器学习概念——模型在一些数据上训练,然后在它从未见过的数据上测试。如果模型在训练数据上表现很好但在测试数据上表现很差,它可能已经 过拟合 到训练数据,并且没有用。如果模型在两者上都表现很差,它可能是 欠拟合。如果模型在训练数据上表现很差但在测试数据上表现很好,你的数据划分需要重新检查,有些东西出了问题。
大语言模型在如此大量的数据上训练,以至于当它们的输出不正确时很难争论 什么 出错了。但我可以用一个 合成数据 的例子来说明一点。如今,合成数据非常流行。只要让一个大语言模型生成一些数据,然后基于该数据的系统就可以用它来推断或形成模式!问题是,大语言模型可能 过拟合 到合成数据,实际上无法在现实世界的真实数据中工作。我们称这为 模型崩溃,当 AI 模型使用递归生成的数据训练时会崩溃,或者我们所说的“AI 垃圾”。
“策划高质量、针对性的测试用例比以往任何时候都更重要”。
如今许多 AI 专业人员无法访问底层基础模型,除非你使用具有开放权重的小型语言模型。所以我们的训练 vs 测试过程会有所不同。“训练”部分通常有点不在我们手中(尽管微调基础模型是一个选项)。但“测试”部分通常是我们可以从传统机器学习中吸取教训的地方。策划高质量、针对性的测试用例比以往任何时候都更重要。在机器学习中,我们使用数据的第三个分区,称为 验证集,可用于迭代评估模型。但测试集是 不可触碰的!我再说一遍,不可触碰!测试集是一组 真实 数据,随机选择,用于衡量你的系统在任意给定时间对任意给定输入的表现。模型应该用 类似于 它的数据训练,但像我们的柠檬水例子一样,它不应该用你测试的确切示例来训练。在真实系统中,我们也经常获得更多测试数据——这被称为上线。
4、可解释性和不确定性
我从传统机器学习中非常想念的是有意义的不确定性指标。在我们之前的线性回归例子中,你可以知道你的模型离数据有多“偏离”。这些残差给了我们模型的“偏离程度”,你可以得到一个关于你的模型总体上有多“偏离”的标准误差。误差越大,不确定性越小。不确定性越小,你对模型输出的信心就越低。但如今,不确定性通常看起来像这样:
“🔴 置信度:低!我预测低置信度,因为柠檬水被多次推荐为你可能喜欢的饮料,这意味着我可能缺乏关于你的一些数据。然而,你可能真的很喜欢柠檬水。还需要我帮忙吗?”
没错,我们有大语言模型在解释自己。虽然这项技术有一些希望(大语言模型能解释自己吗?),我们也看到对这种方法 的警告(大语言模型无法解释自己)。
我们已经让大语言模型评估其他大语言模型很长时间了,称为“大语言模型即裁判”,起初我觉得这很糟糕。随着时间的推移,我慢慢被说服接受这项技术有一些效用,一些大语言模型即裁判的 表现与人类(非专家)基线相当。我们在 大语言模型解释和可追溯性技术 中看到了同样多的希望,尽管警告是相同的:大语言模型被对齐以听起来合理、自信、有帮助和聪明。大语言模型这种过度顺从的性质称为 谄媚,它在很多方面伤害着我们。
“我们测量、控制和理解大语言模型的方式 必须 超越'我提示它告诉我它做了什么'”
我们测量、控制和理解大语言模型的方式 必须 超越'我提示它告诉我它做了什么'。提示只是更多传递给大语言 model 的 token,将其输出的可能性转移到这些 token。要真正理解错误归因或为什么模型做它所做的事情,我们必须回到机器学习科学。查看 多代理系统中的错误归因 和 模型稳定化 中的最新技术来了解更多。
5、专注的诸多好处
“把 AI 扔向任何事情和一切的时代必须结束”
我们讨论了高质量、针对性的测试用例。但我也想谈谈高质量、针对性的 用例。把 AI 扔向任何事情和一切的时代必须结束。AI 不仅对我们的水和电力造成明显浪费,而且通常也不成功:95% 的 AI 初创公司失败。MIT 的建议之一?“最好的初创公司专注于狭窄但高价值的用例”。
在 大数据 之前的绝对疯狂时代,你知道机器学习是为 什么建造的吗?你猜对了!狭窄定义的问题,针对该问题的专门训练和测试集。搜索 UCI 机器学习库 上托管的任何数据集,你会看到这些问题的专注性质。基础模型是如此广泛,我们通过代理 AI 的最新趋势看到我们再次变得狭窄。
我们在以下方面变得狭窄:
- AI 代理的有效上下文工程
- 用(有效的)长期记忆构建更聪明的代理
- 专注的多代理,每个专门从事一个狭窄任务
- 为 AI 代理编写有效的工具
- 在多代理系统中嵌入负责任的实践(包括平衡狭窄关注与一些自主性)
- 小型语言模型的崛起,或为非常特定任务微调的模型
当 AI 系统服务更狭窄的目标时,它可以被更容易地控制、测试、监控,甚至扩展。让我们从传统机器学习中学习,不要试图用一个大而未定制的模型解决每个问题。
6、AI 伦理和监管已经存在了几十年
如果你读到这里,你知道如果我不谈一点负责任的 AI,我就有失职之嫌。你可能认为 欧盟 AI 法案 是第一个 AI 监管。而且它确实是同类中的第一个!但几十年来,我们有一些非常聪明的人在从事技术政策和算法正义方面的工作。你可能开始担心 AI 的当前状态。它将如何影响经济?我们的环境?我们的隐私?我们的机会?如果你感到一些担忧,你不是一个人。皮尤研究中心每年调查美国人如何看待 AI,今年天平终于倾向于多数“担忧”。
稍感安慰的是,我们中有一些人毕生致力于这些问题,而不仅仅是生成 AI 成为今天的样子。算法正义联盟 一直在揭露 AI 中的偏见和歧视,可以追溯到最初对深肤色人脸的面部识别偏见的工作。Ruha Benjamin 不仅写算法种族主义,还写我们可以创造的替代未来。Emily Bender 和 Alex Hanna 经常谈论我们如何可以“抵制 AI 接管”,包括为你设计“战略性拒绝”何时使用 AI 是或不合适的。如果你想要一篇特别辛辣的论文,看看如何在 21 世纪“反 AI”:克服不可避免性叙事。他们认为存在 AI 必须无处不在的“不可避免性”的替代方案。他们详细介绍了 5 个选项:驯服 AI、抵抗 AI、拆除 AI、逃离 AI 和粉碎 AI。虽然这听起来可怕,他们为每个级别可能是什么样子提供了实际建议。
- 驯服 AI:参与 AI 监管、保护、对齐、环境解决方案
- 抵抗 AI:集体行动抵抗 AI 或 AI 公司做出的决定,比如最近对 QuitGPT 运动 的回应,以回应 OpenAI 与国防部的合作
- 拆除 AI:想象公共生活的替代方案,承诺公共政策将以实质性方式从公共服务中移除 AI
- 逃离 AI: 夺回我们的隐私、我们的数据、不参与收集我们个人信息的系统,并创建更多不依赖这些技术的集体空间
- 粉碎 AI: 我会让你猜这个是关于什么的 😂
作为我持续“驯服”AI 努力的一部分,以下是你可能感兴趣的一些更多资源:绿色软件实践、AI 对残障人士的影响、世界各国 AI 法律(带地图)。
7、组合力量:LLM驱动的代理与机器学习工具
你(和我)终于走到了最后。我将给你留下一个 fancy 的想法,结合我到目前为止所说的一切。识别 AI 系统的狭窄用例是关键。你可能记得我厌倦了 AI 在实际问题被真正识别之前就成为解决方案。识别狭窄用例,要解决的高价值问题,这就是 你在 AI 方面成功的方式。接下来,考虑传统机器学习(回归、XGBoost、深度学习,甚至小型语言模型)用于你的用例,或者甚至作为 AI 代理可以调用的一个过程。最后,首先考虑风险和影响,这样你就在它周围构建,而不是以后感到惊讶。
愿你获得你应得的 AI 未来。
原文链接: What traditional Machine Learning can tell us about Agentic AI
汇智网翻译整理,版权归作者所有,转载需标明出处
