用Agent Lightning训练Agent
创建自定义vLLM工具解析器以支持多工具Agent工作流的GRPO训练。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署 | AI工具导航 | Tripo 3D | Meshy AI
Agent Lightning通过VERL为Agent启用GRPO微调。它从执行多步推理和工具调用的Agent中收集轨迹,允许模型学习诸如SQL ReAct agent的工作流,这些agent使用工具进行模式搜索、列检查、SQL生成和查询执行。
然而,官方的Agent Lightning文本到SQL示例主要展示了LangGraph推理流,而在推出过程中没有实际使用工具。在实践中,默认的vLLM工具解析器无法可靠地与某些模型一起工作,例如Qwen2.5-Coder-1.5B-Instruct,这会阻止在训练期间检测到工具调用。在本文中,我们创建一个自定义vLLM工具解析器,以便使用Agent Lightning和VERL将带有Qwen2.5-Coder-1.5B的agent训练为多工具ReAct agent。
像Qwen3这样的较新模型在vLLM中已经有内置解析器(qwen3_coder和qwen3_xml)支持,不需要此自定义。
1、工具解析问题
当训练带有多个工具的agent时,训练系统必须正确检测模型产生的工具调用。在推出过程中,模型生成表示工具调用的文本。推理服务器必须解析此文本并将其转换为结构化的tool_call对象,以便agent运行时可以执行工具并将观察结果返回给模型。
然而,在使用Qwen2.5-Coder-1.5B-Instruct进行训练期间,模型生成的工具调用经常以纯文本形式返回。默认的vLLM Hermes解析器期望特定的<tool_call>格式,但Qwen经常产生不同的格式,例如<tools>标签、JSON块或原始JSON对象。由于这些格式不被默认解析器识别,工具调用被忽略,并且agent在推出期间从不执行它们。

因此,agent循环塌陷为单轮。不执行任何工具,轨迹仅包含一个响应,并且强化学习信号变得非常弱。
两种可能的方法可以解决这个问题。解决方案1是创建一个自定义工具解析器,它可以识别模型产生的多种工具调用格式。解决方案2是在GRPO之前进行简短的SFT冷启动阶段,以便模型学习一致地生成vLLM使用的正确Hermes<tool_call>格式。通过此冷启动,GRPO训练可以专注于改进推理和工具使用,而不是学习工具调用的语法。在本文中,我们采用解决方案1,实现自定义解析器以处理训练期间的格式变化。
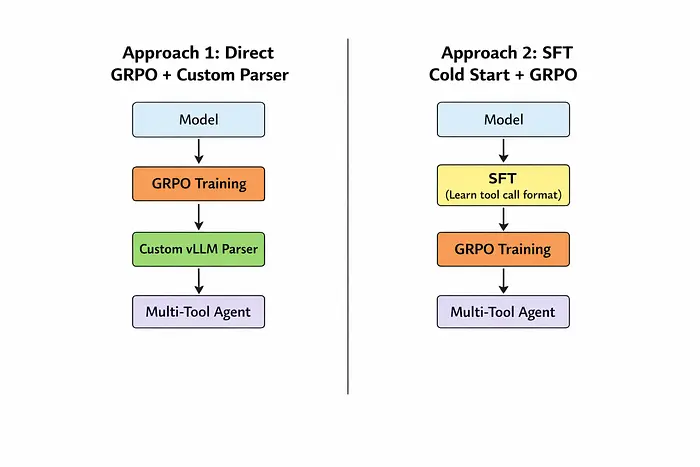
2、创建自定义vLLM工具解析器
在本节中,我们实现一个自定义vLLM工具解析器,它检测这些Qwen风格的变体并将它们规范化为vLLM期望的标准tool_calls结构。
默认的vLLM工具解析器是为Hermes工具调用格式设计的,它期望以下输出:
<tool_call>{"name": "...", "arguments": {...}}
自定义解析器qwen25_coder_parser.py扫描模型输出以查找已知模式,提取函数名称和参数,并将它们作为结构化ToolCall对象返回:
"""Custom vLLM tool parser for Qwen2.5-Coder tool-call variants."""
import json
import re
from vllm.entrypoints.openai.protocol import (
DeltaMessage,
ExtractedToolCallInformation,
FunctionCall,
ToolCall,
)
from vllm.entrypoints.openai.tool_parsers.abstract_tool_parser import (
ToolParser,
ToolParserManager,
)
# Common Qwen variants we observed in rollouts
_PATTERNS = [
re.compile(r"<tool_call>\s*(.*?)\s*</tool_call>", re.DOTALL),
re.compile(r"<tools>\s*(.*?)\s*</tools>", re.DOTALL),
re.compile(r"```(?:json)?\s*\n?(.*?)\n?\s*```", re.DOTALL),
]
def _normalize(obj):
"""Return a list of tool call dicts from multiple JSON shapes."""
if isinstance(obj, dict):
if isinstance(obj.get("tool_calls"), list):
return obj["tool_calls"]
if "name" in obj or "function" in obj:
return [obj]
if isinstance(obj, list):
return [x for x in obj if isinstance(x, dict) and ("name" in x or "function" in x)]
return None
def _extract_calls(text: str):
"""Parse tool call dicts from tagged blocks, fenced JSON, or raw JSON."""
for p in _PATTERNS:
matches = p.findall(text)
if not matches:
continue
calls = []
for m in matches:
try:
obj = json.loads(m.strip())
except json.JSONDecodeError:
continue
norm = _normalize(obj)
if norm:
calls.extend(norm)
if calls:
return calls
# last resort: entire text is JSON
try:
obj = json.loads(text.strip())
return _normalize(obj)
except json.JSONDecodeError:
return None
class Qwen25CoderToolParser(ToolParser):
def __init__(self, tokenizer):
super().__init__(tokenizer)
def adjust_request(self, request):
return request
def extract_tool_calls(self, model_output: str, request):
parsed = _extract_calls(model_output)
if not parsed:
return ExtractedToolCallInformation(
tools_called=False,
tool_calls=[],
content=model_output,
)
tool_calls = []
for call in parsed:
fn_name = call.get("name") or (call.get("function") or {}).get("name")
args = (
call.get("arguments")
or call.get("parameters")
or (call.get("function") or {}).get("arguments")
or {}
)
if not fn_name:
continue
if not isinstance(args, str):
args = json.dumps(args, ensure_ascii=False)
tool_calls.append(
ToolCall(
type="function",
function=FunctionCall(name=fn_name, arguments=args),
)
)
return ExtractedToolCallInformation(
tools_called=bool(tool_calls),
tool_calls=tool_calls,
content=None, # tool-only output during training
)
def extract_tool_calls_streaming(
self,
previous_text,
current_text,
delta_text,
previous_token_ids,
current_token_ids,
delta_token_ids,
request,
):
# Keep streaming simple; tool extraction happens in non-streaming rollouts
return DeltaMessage(content=delta_text)
def register():
ToolParserManager.register_module(
"qwen25_coder",
module=Qwen25CoderToolParser
)
3、在vLLM和VERL中注册解析器
实现自定义解析器后,下一步是使其在训练期间可用于vLLM。这是使用vLLM插件系统完成的,该系统允许外部模块注册自定义组件,如工具解析器。
在基于uv的Python项目中,这是在pyproject.toml中使用vllm.general_plugins组下的Python入口点配置的。当vLLM启动时,它会自动发现这些插件并执行它们的register()函数,该函数向ToolParserManager注册解析器。
[project.entry-points."vllm.general_plugins"]
qwen25_coder_parser = "src.vllm_plugins.qwen25_coder_parser:register"
在自定义解析器脚本内,解析器插件注册如下:
ToolParserManager.register_module(
"qwen25_coder",
module=Qwen25CoderToolParser
)
注册后,可以通过在VERL训练配置中设置来启用解析器:
"multi_turn": {"format": "hermes"},
"engine_kwargs": {
"vllm": {
"enable_auto_tool_choice": True,
"tool_call_parser": "qwen25_coder",
...
}
},
...
安装插件包后,当VERL推理worker启动时,vLLM通过vllm.general_plugins入口点机制自动发现并注册解析器。
项目布局:
project/
pyproject.toml
src/
vllm_plugins/
__init__.py
qwen25_coder_parser.py
4、多工具Agent的上下文要求
现在工具调用被正确解析和执行,下一个考虑是多轮工具交互如何在训练期间增加上下文大小。
训练多工具agent需要比单步任务(如模式链接)更大的上下文。每个工具调用将新信息附加到对话中,包括生成的SQL、工具响应,有时还有错误消息。由于agent携带前几轮,上下文在轨迹上快速增长。
例如,典型的SQL agent推出可能如下所示:
Turn 1: prompt (~4K) + SQL generation (~200) + tool result (~500)
Turn 2: prompt (~4.7K) + revised SQL (~200) + tool result (~500)
Turn 3: prompt (~5.4K) + final SQL (~200)
Total trajectory: ~6K+ tokens
由于每一轮都包括以前的对话历史,多工具工作流可以超过用于更简单任务的上下文限制。这就是为什么在训练具有多个工具调用的SQL agent时,通常需要增加VERL配置参数,如max_prompt_length、max_model_len和ppo_max_token_len_per_gpu。
例如,SQL ReAct agent通常在推出期间与几个工具交互,例如search_schema、get_columns和execute_sql。每个工具调用返回一个观察结果,在下一个推理步骤之前附加到对话中。
User: Find top 5 customers by total claim amount.
Agent → search_schema("claim")
Tool → tables: claim, claim_payment
Agent → get_columns("claim_payment")
Tool → columns: customer_id, claim_amount, claim_date
Agent → execute_sql(
SELECT customer_id, SUM(claim_amount)
FROM claim_payment
GROUP BY customer_id
ORDER BY SUM(claim_amount) DESC
LIMIT 5
)
Tool → result rows
每一步都向上下文添加新token。由于agent携带前几轮,上下文随着每次工具交互而增长。
对于这种类型的agent,典型配置可能会增加上下文限制以支持多轮轨迹:
"data": {
"max_prompt_length": 8192,
"max_response_length": 1024,
},
"actor_rollout_ref": {
"rollout": {
"engine_kwargs": {
"vllm": {
"max_model_len": 8192,
"enable_auto_tool_choice": True,
"tool_call_parser": "qwen25_coder"
}
}
},
},
"actor": {
"ppo_max_token_len_per_gpu": 32768
}
这些更大的限制确保多步工具交互可以在GRPO训练期间适应模型上下文。请注意,这些更大的上下文限制也会增加KV缓存使用,因此最大上下文大小最终受到可用GPU VRAM的限制,这可能需要调整诸如gpu_memory_utilization之类的参数或减少批量大小以避免内存不足。
以下是用于GRPO训练和LoRA微调的完整VERL配置:
VERL_CONFIG = {
"algorithm": {
"adv_estimator": "grpo",
"use_kl_in_reward": False,
},
"data": {
"train_files": "data/sql_train.jsonl",
"val_files": "data/sql_val.jsonl",
"train_batch_size": 8,
"max_prompt_length": 8192,
"max_response_length": 1024,
"truncation": "error",
},
"actor_rollout_ref": {
"rollout": {
"name": "vllm",
"n": 2,
"tensor_model_parallel_size": 1,
"gpu_memory_utilization": 0.6,
"log_prob_micro_batch_size_per_gpu": 2,
"multi_turn": {"format": "hermes"},
"enforce_eager": True,
"engine_kwargs": {
"vllm": {
"enable_auto_tool_choice": True,
"tool_call_parser": "qwen25_coder",
"max_model_len": 8192,
"enforce_eager": True,
"num_gpu_blocks_override": 256,
}
},
},
"actor": {
"ppo_mini_batch_size": 16,
"ppo_micro_batch_size_per_gpu": 1,
"ppo_max_token_len_per_gpu": 32768,
"optim": {"lr": 1e-5},
"use_kl_loss": False,
"kl_loss_coef": 0.0,
"entropy_coeff": 0,
"clip_ratio_low": 0.2,
"clip_ratio_high": 0.28,
"fsdp_config": {
"param_offload": True,
"optimizer_offload": True,
},
},
"ref": {
"log_prob_micro_batch_size_per_gpu": 2,
"fsdp_config": {"param_offload": True},
},
"model": {
"path": os.getenv(
"SFT_MODEL_PATH", "Qwen/Qwen2.5-Coder-1.5B-Instruct",
),
"lora_rank": 16,
"lora_alpha": 32,
"use_remove_padding": False,
"enable_gradient_checkpointing": True,
"override_config": {
"attn_implementation": "sdpa",
},
},
},
"trainer": {
"n_gpus_per_node": 1,
"total_epochs": 3,
"val_before_train": True,
"test_freq": 16,
"project_name": "sql-agent-grpo",
"logger": ["console", "wandb"],
},
}
5、结束语
这种方法通过使用自定义解析器扩展vLLM来为不严格遵循Hermes工具调用格式的模型,实现了使用Agent Lightning和VERL的可靠多工具agent训练。
有关Agent Lightning、VERL和vLLM工具解析的更多详细信息,请参阅官方文档。
原文链接: Training Multi-Tool Agents with Agent Lightning and VERL
汇智网翻译整理,转载请标明出处
