Gemini嵌入API + LLM
我们提出了这样一个问题:能否将Gemini Embedding API重新用作冻结语言学习模型 (LLM) 的多模态编码器?

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
Google 的 gemini-embedding-2-preview 是 Gemini API 中首个多模态嵌入模型。它将文本、图像、视频、音频和文档映射到一个统一的 3072 维嵌入空间——支持跨 100 多种语言的跨模态搜索、分类和聚类。
我们提出了这样一个问题:能否将其重新用作冻结语言学习模型 (LLM) 的多模态编码器?
设置非常简单——只需一次 API 调用、一个小型学习适配器和一个冻结的 Qwen3-4B 模型。无需自定义编码器,无需对 LLM 进行微调,即可获得 1700 万个可训练参数。在单个 GPU 上训练只需不到 1 分钟。
代码和权重可以从这里下载。
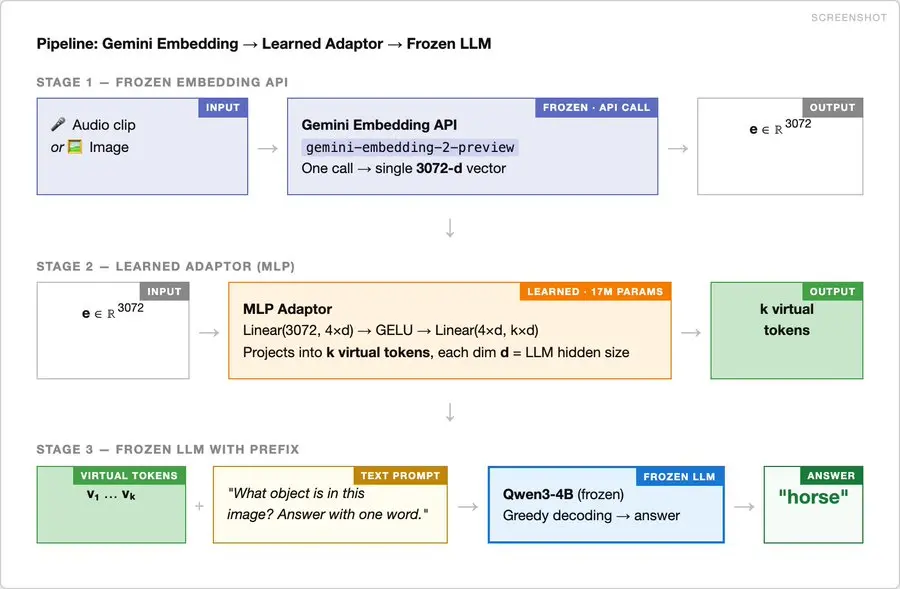
1、流程
每个输入(图像或音频)都经过三个阶段:
- 冻结的 Gemini Embedding API — 一次调用 → 3072 维向量
- 学习 MLP 适配器(1700 万个参数)— 投影到 k 个虚拟标记
- 冻结的 Qwen3-4B — 虚拟标记 + 文本提示 → 自由格式答案
仅训练 MLP 适配器。任务提供监督信息:分类任务提供(图像,标签)对,语音转文本任务提供(音频,文本转录)对。使用交叉熵损失函数,以真实标签标记作为基准。
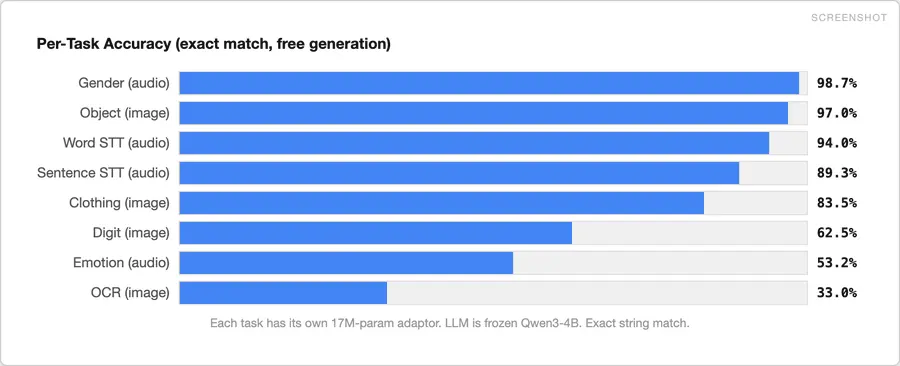
2、各个任务的结果
我们针对音频和图像的 8 个任务分别训练了适配器。所有数据均为在预留测试集上的精确匹配准确率(自由生成,贪婪解码):
- 物体分类(CIFAR-10):97%
- 性别分类(RAVDESS):99%
- 词级语音转录(语音命令):94%
- 句子级语音转录(流畅语音命令):89%
- 服装分类(Fashion-MNIST):83%
- 数字分类(SVHN):62%
- 情感分类(RAVDESS):53%
- 场景文本/OCR(IIIT-5K):33%
一个3072维向量、一个1700万参数的多层感知器(MLP)和一个冻结的LLM——物体分类准确率达到97%,句子级命令转录准确率达到89%。
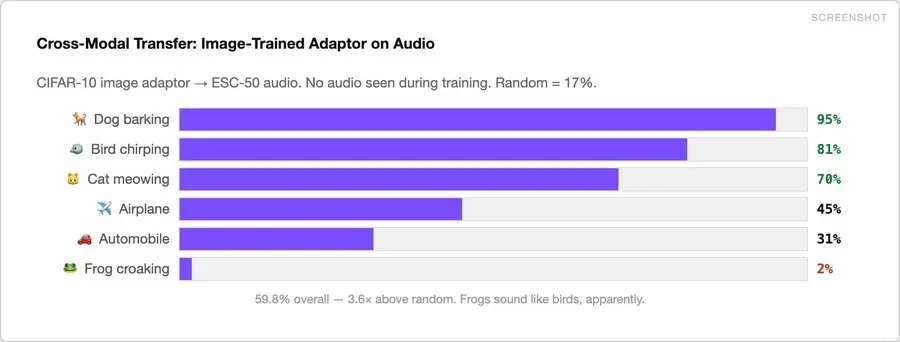
3、最令人惊讶的结果:跨模态迁移
我们使用CIFAR-10图像训练的适配器,并将其输入ESC-50的环境声音。训练期间未接收到任何音频。
- 🐕 狗吠 → “狗”识别率 95%
- 🐦 鸟鸣 → “鸟”识别率 81%
- 🐱 猫叫 → “猫”识别率 70%
- 🐸 蛙鸣 → “鸟”识别率 2%(显然,青蛙的叫声听起来像鸟)
总体识别率 59.8%,比随机基线高出 3.6 倍。
Gemini 嵌入空间具有真正的跨模态对齐能力。“狗”或“鸟”等语义概念形成跨越音频和图像的聚类。
经过音频训练的性别分类器也能部分迁移到人脸图像:在训练期间仅听到声音的情况下,对 CelebA 人脸的识别率达到 62%。
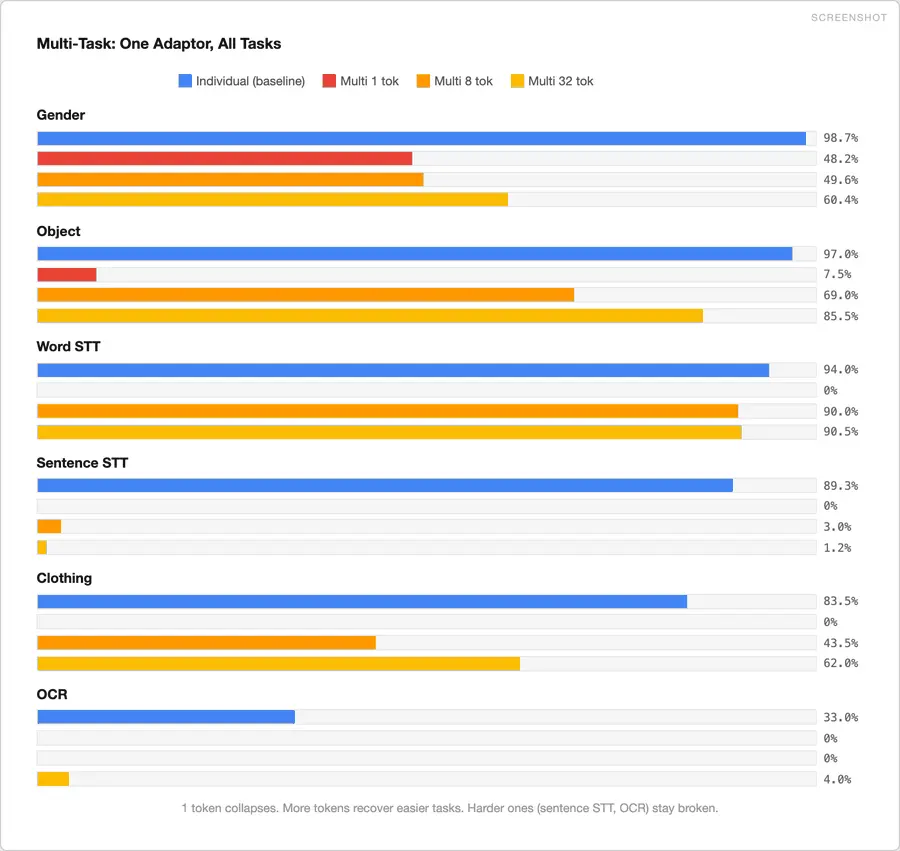
4、一个适配器可以完成所有任务吗?
我们随后训练了一个共享的适配器,用于所有 8 个任务(4 个音频任务 + 4 个图像任务)。使用相同的 MLP,每个任务使用不同的文本提示。并改变了虚拟标记的数量。
使用 1 个虚拟标记时,模型崩溃。所有单词默认识别为“狗”。
使用 8 个标记时,单词 STT 恢复到 90%,物体恢复到 69%。
使用 32 个标记(2.61 亿个参数,LLM 仍然冻结)时,物体达到 85%,服装达到 62%。但句子 STT 和 OCR 仍然无法正常工作。
标签集较小的简单任务可以恢复。需要精细输出的复杂任务则无法恢复。
5、问题所在:开放词汇表转录
89% 的句子 STT 适用于包含 169 个命令的封闭数据集。它能进行真正的转录吗?
我们在 LibriSpeech(1000 个不同的句子)上进行了测试。完全匹配率 0% — 我们尝试的所有设置:
- 单嵌入,1 个 token → 0%
- 单嵌入,32 个 token → 0%
- 2 秒片段,每个片段 1 个 token → 0%
- 1 秒片段,每个片段 1 个 token → 0%
该模型生成的英语流畅自然,与实际语音的词语重叠度为零。在封闭数据集上看似转录的结果实际上是聚类识别——适配器学习的是它正在识别的 169 个已知聚类中的哪一个,而不是实际内容。
8、结论
对于单个任务,Gemini 嵌入作为开放式 LLM 的即插即用多模态编码器表现出色。只需一次 API 调用,一个不到一分钟即可训练完成的小型适配器,一个冻结的 LLM——图像分类准确率达 97%,命令转录准确率达 89%,开箱即用,支持跨模态迁移。
无需自定义编码器。无需 LLM 微调。对于任何开放权重模型而言,这都是一个极具吸引力的起点,可以添加多模态功能。
原文链接:Turning Gemini's embedding API into a universal multimodal encoder for LLMs
汇智网翻译整理,转载请标明出处
