Vane 安装指南(本地AI问答引擎)
Vane让我可以拥有一个令人惊叹的本地Web应用,类似于Perplexity.ai,运行在我本地的LLM上,通过llama.cpp提供服务。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
上周我在GitHub上发现了一个超酷的项目,原名为Perplexica(现已更名为Vane)。对我来说这是一个不容错过的机会。事实上,我可以拥有一个令人惊叹的本地Web应用,类似于Perplexity.ai,运行在我本地的LLM上,通过llama.cpp提供服务。
Vane是一个开源、自托管的AI驱动的问答引擎,由ItzCrazyKns开发。它作为一个注重隐私的Perplexity AI替代品,支持使用SearxNG进行搜索、LLM(通过Ollama或云提供商)以及带引用的回复功能进行本地部署。
PS:llama.cpp不包含在内,但在本文中我将向你展示如何配置!
正如原始名称所暗示的,Vane(Perplexica)是一个模仿著名的Perplexity的项目,我已经使用Perplexity三个月了。
顺便说一句,如果你有Revolut账户且至少是高级账户,你可以免费使用Perplexity,作为该等级福利的一部分。
无论如何,Perplexity令人惊叹:模型本身非常好,所有回复都基于实时收集和评估的网络来源。模型响应中的每个声明都引用不同的来源,从第一个token开始就避免幻觉。
在我的旧联想X260上运行Perplexica,使用Qwen3.5和llama.cpp
在本文中,我将向你展示如何在你的电脑上运行Perplexica,获得与Perplexity相同的体验……但不需要支付一分钱。我还会给你一些示例,帮助你选择最适合这项工作的本地模型。
让我们开始吧。
1、什么是Perplexica?
Perplexica是一个受Perplexity AI启发的开源AI驱动搜索引擎。它使用SearxNG进行网络搜索、通过Ollama使用本地LLM如Llama3,以及相似性搜索和嵌入等先进技术来提供带引用的答案。
最初以Perplexica之名推出,该项目已更名为Vane,GitHub仓库位于https://github.com/ItzCrazyKns/Vane,通过频繁的提交、如v1.12.1的发布和Docker构建积极维护。
有很多有趣的功能:
- 支持速度模式、平衡模式、深度研究、文件上传和特定领域搜索(如学术、YouTube)
- 在您的硬件上100%本地运行以确保隐私,将本地LLM与可选的云模型相结合
- 包括智能建议、会话管理和用于集成的API端点
Vane可以在正常模式下运行直接网络搜索,或在Copilot模式(开发中)下生成多个查询并访问热门结果。它包括学术、YouTube、Reddit、Wolfram Alpha和写作助手等专注模式。
最突出的功能是它支持注重隐私的、最新的结果,而不依赖过时的索引。
Vane的搜索模式优化AI驱动的查询,以实现速度、深度或特定性。它们包括一般模式如速度、平衡和质量(或深度研究),以及针对学术、YouTube和Reddit等领域的专注模式。
在速度模式下,vane/Perplexica以最少的处理提供快速答案以获得快速结果。
平衡模式适合日常搜索,在速度和准确性之间取得平衡。
还有质量/深度研究模式:执行深入分析、多个查询和站点访问以获得深入回复。
在所有模式下,您可以:
- 将搜索限制在特定来源(例如,学术用于学术内容、YouTube用于视频、Reddit用于讨论)
- 通过提示、SearxNG修饰符和LLM支持自定义配置以实现用户定义的模板
- 通过嵌入和相似性排名增强相关性,支持文件上传和智能建议等选项
我们可以拥有所有这些而不用担心token成本:事实上,即使速度较慢,也有办法使用llama.cpp服务器和好的本地LLM在我们的电脑上运行Perplexica。以下是方法……
2、如何安装和使用Perplexica
有几种方法可以在您的电脑上安装Perplexica。最简单的方法是通过Docker镜像。我们将使用这种方法。
第一步是安装Docker桌面版,或者下载Windows二进制文件(我在Windows 11上测试所有这些,但您也可以在MacOS和Linux上做)
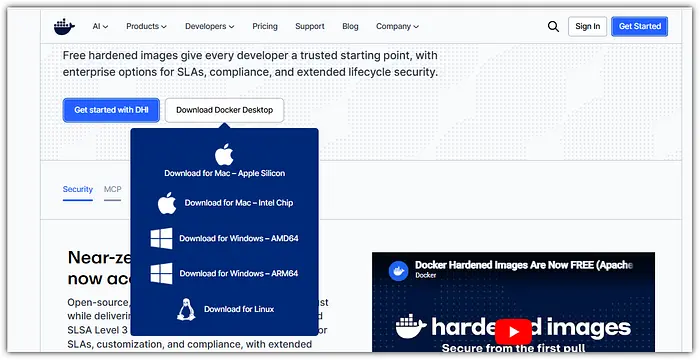
下载安装程序后,运行它。在过程结束时,Docker将自动启动。
3、安装vane/Perplexica docker容器
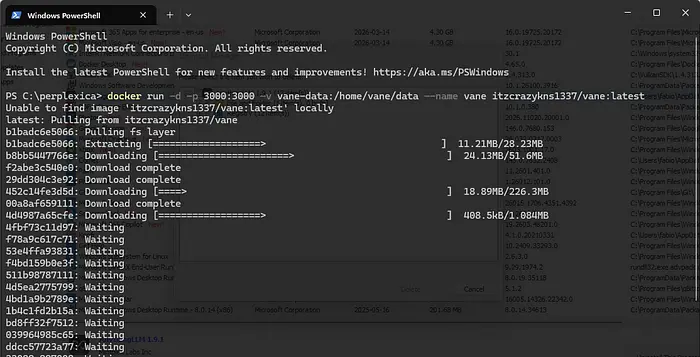
确保Docker Desktop正在运行。打开终端(在任何地方)并运行这个简单的命令:
docker run -d -p 3000:3000 -v vane-data:/home/vane/data --name vane itzcrazykns1337/vane:latest
Docker将获取vane项目(Perplexica)的镜像,下载并为我们启动它。
Docker镜像的好处是它们已经配置了所有依赖项和功能。
例如,Perplexica自带已安装的SearXNG,一个强大的本地运行搜索引擎,不需要任何API密钥!
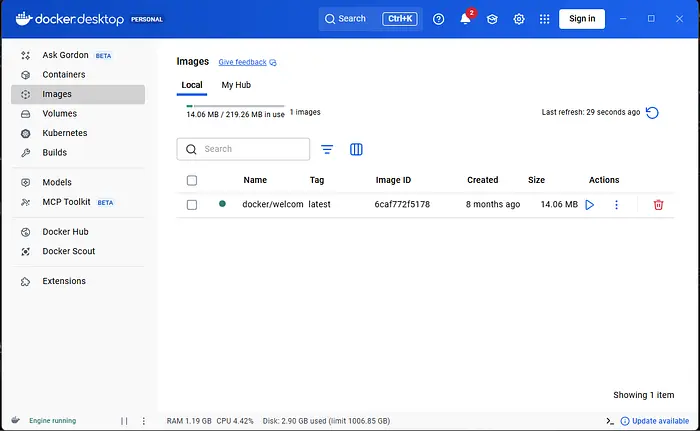
现在……在终端完成所有过程后(见上图),您的Docker Desktop将在容器中有一个新条目:
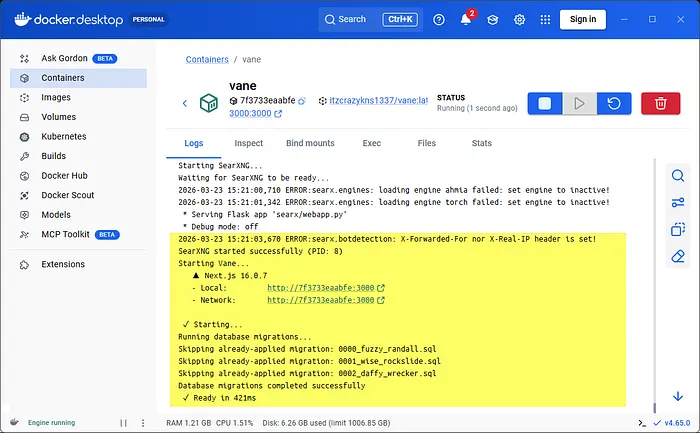
点击▶️播放按钮启动它:这就是您在电脑上运行Perplexica所需的全部。
如果您在浏览器中(我在这里使用Comet)指向localhost:3000,您可以看到它正在运行。
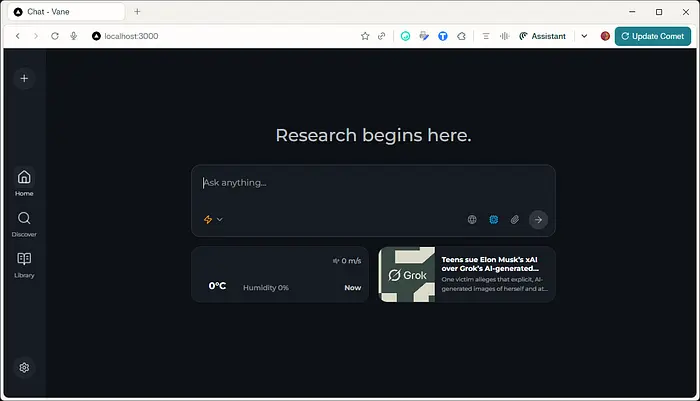
现在我们需要一个AI模型。
4、llama.cpp服务器只需一步之遥
这里真正的问题是vane/Perplexica没有为llama.cpp服务器内置配置。
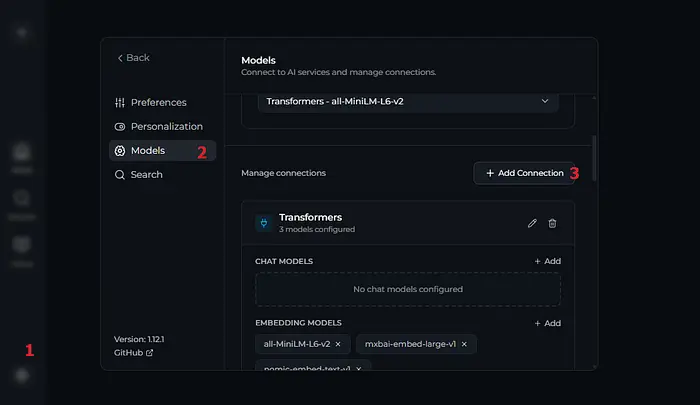
设置 > 模型 > 管理连接 > + 添加连接
默认可用选项是:
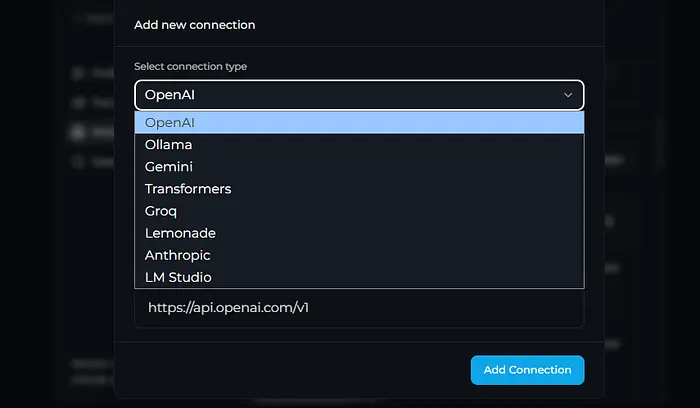
但通过一些技巧,我们可以利用标准的OpenAI连接,让它准备好与我们的llama-server一起工作!
4.1 首先……让我们谈谈模型。
并非每个聊天模型都适合这个应用:事实上Perplexica使用(就像原始的Perplexity……):
- 推理
- 工具调用
所以,并非所有模型都有这些功能,小型语言模型更是少之又少。
我自己在我的老旧的联想X260笔记本电脑上测试了以下模型:
- Gemma-3n-E2B-it
- LFM-2.5–1.2b-instruct
- Qwen3.5–0.8b
- Ministral-3–3B-Instruct-2512
- Granite-4.0-h-tiny
- Granite-3.1–3b-a800m-instruct
- Trinity-Nano-Preview
- Qwen3.5–2b
- Qwen3–4b-instruct
- NVIDIA-Nemotron3-Nano-4B
- Qwen3–1.7B
测试所有这些后,我明白了并非所有模型都适合Perplexica,即使是真正优秀的Ministral-3–3B-Instruct-2512,它通常在低规格硬件上运行得很好,具有准确性和可靠性。
稍后我会给你详细的反馈。现在让我们看看如何在你的电脑上让它工作。
注意:所有这些示例都是针对Windows操作系统用户的,但很容易适用于Linux和Mac用户。
4.2 安装llama.cpp二进制文件
从官方GitHub仓库下载仅CPU用户的最新llama.cpp二进制文件:
- 下载llama-b8508-bin-win-cpu-x64.zip
- 解压到一个名为
PerplexicaAI的新目录中
4.3 下载模型的量化权重
正如我向您展示的,我测试了几个小型语言模型,对于仅CPU用户最好的是Qwen3.5–0.8b-GGUF。
- 从Unsloth仓库下载Qwen3.5–0.8B-Q6_K.gguf(只需点击链接下载)。我选择Q6以尽可能减少质量损失。
- 放在同一个名为
PerplexicaAI的目录中
Unsloth仓库还为我们提供了建议的超参数:
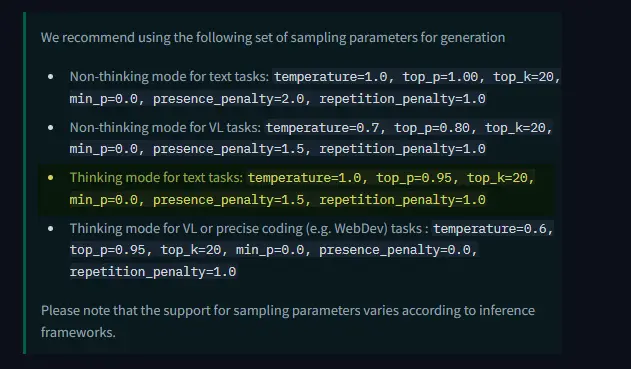
Perplexica建议使用思考模式进行文本任务:temperature=1.0, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=1.5, repetition_penalty=1.0
我们在下一步需要这些设置。
4.4 使用llama-server运行模型
在同一个名为PerplexicaAI的目录中打开终端,运行:
.\llama-server.exe -m .\Qwen_Qwen3.5-0.8B-Q6_K.gguf --mmap -ngl 0 -t 2 -c 32288 --host 0.0.0.0 --port 8888 --reasoning-budget -1 -fa on --temp 1.0 --top-k 20 --top-p 0.95 --presence-penalty 1.5 -a qwen3.5-0.8
此命令将启用思考模式(即使我们使用的是非思考设置),上下文长度为32k token(vane/Perplexica需要大量token),启用flash attention和内存映射。我们将只使用2个线程(但如果您有更多线程,请增加:为操作系统至少保留1个线程空闲)。
为了在网络上公开端点,我们设置--host 0.0.0.0在--port 8888
注意,我们使用选项-a qwen3.5–0.8为模型分配了一个别名:这意味着当您调用端点时,需要将模型名称指定为qwen3.5–0.8。
我们将在下一步中看到!
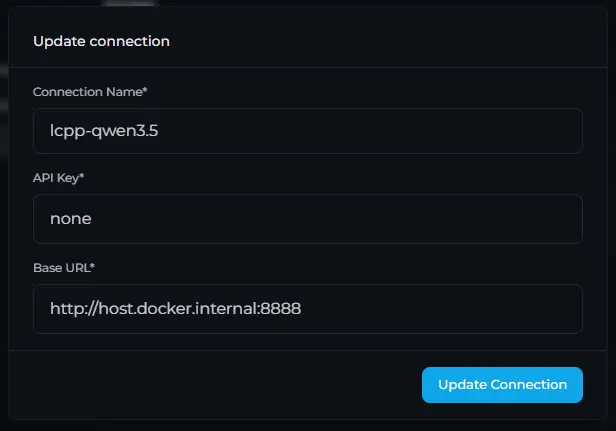
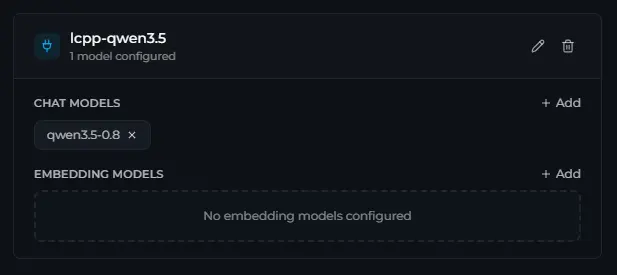
4.5 在Perplexica中配置模型连接
为此,点击设置 > 模型 > 管理连接 > + 添加连接并选择OpenAI。
给连接一个名称(如lcpp-qwen3.5),在API key中写一些东西(即使我们不使用它),非常重要的是,将Base URL设置如下:
http://host.docker.internal:8888
- 由于我们在Docker容器中运行Perplexica,我们指向我们电脑的本地主机,指向
http://host.docker.internal - 我们要求llama-server在端口
8888托管端点,因此最终的Base URL必须是http://host.docker.internal:8888
这只是主连接。现在我们需要链接一个聊天模型(见上图,右边那个)。
4.6 在聊天模型列表中添加模型
在设置中找到您的新连接,然后在聊天模型部分点击**+ 添加**。
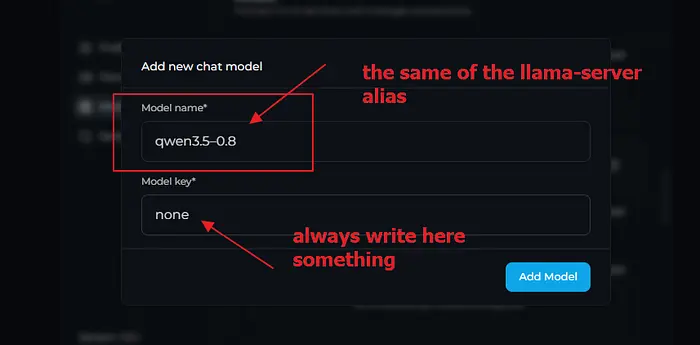
模型名称必须与我们在llama-server中使用选项-a qwen3.5–0.8设置的相同
记得我们说过,当您调用端点时,需要将模型名称指定为qwen3.5–0.8。即使我们不使用它,也不要让Model Key为空
点击添加模型。
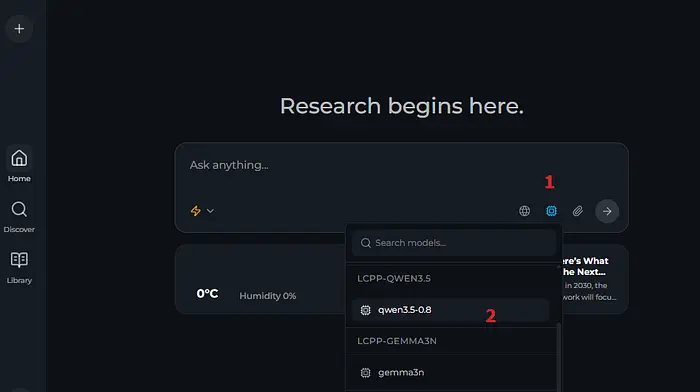
4.7 将新模型设置为Perplexica AI模型
转到Perplexica的首页,点击cpu符号并查找您的连接/聊天模型。
⚠️注意:有时如果您看不到新连接,需要重启容器,或者简单地刷新页面
4.8 运行测试
我还建议您将研究模式更改为平衡。
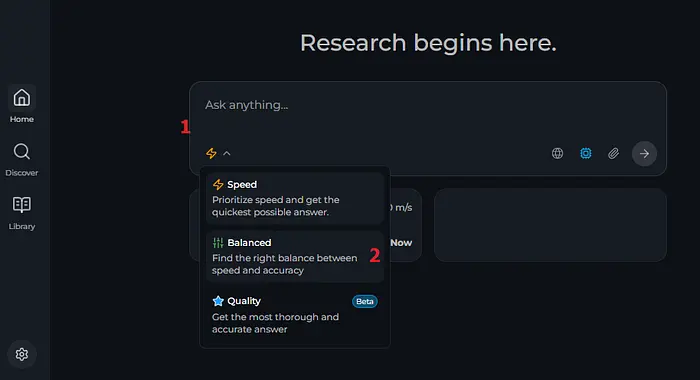
输入您的查询并运行。公平地说,我通过询问测试了所有模型:
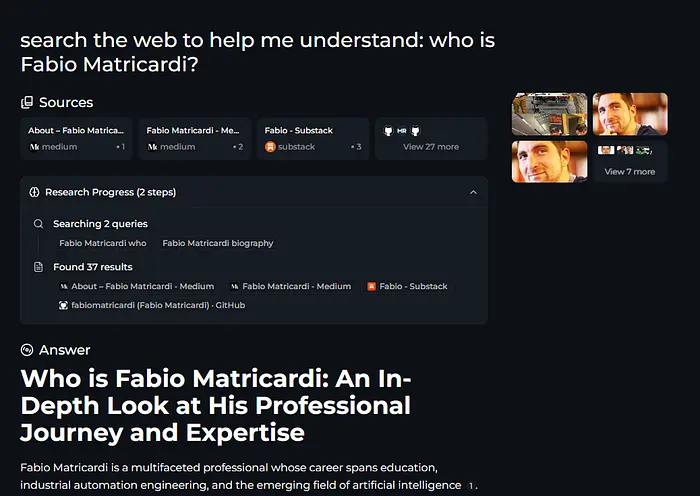
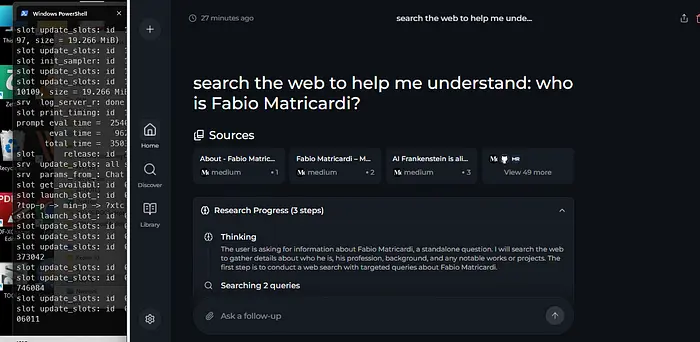
搜索网络帮助我理解:Fabio Matricardi是谁?
我不是很有名,所以肯定需要一个好的网络搜索。
在运行llama-server的终端窗口中,您应该能够看到新的POST调用进来:这意味着它正在工作
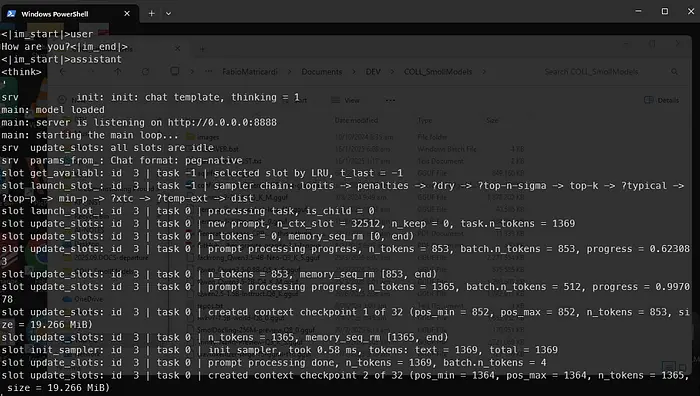
准备等待长达30分钟完成整个流程,而且token预算很高(但它在您的电脑上,所以不用担心奇怪的账单)。
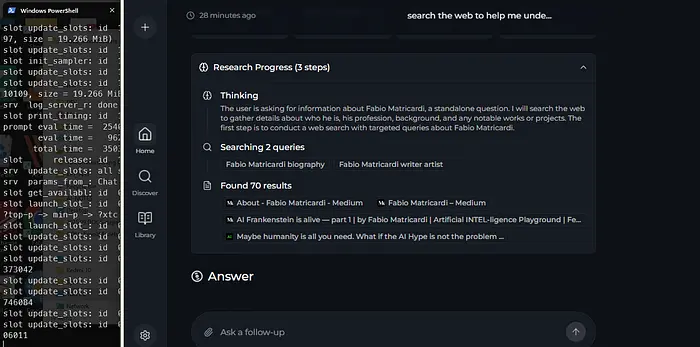
在流程接近尾声时,Perplexica将搜索与查询相关的图片。如果您看不到它们,请点击图标。
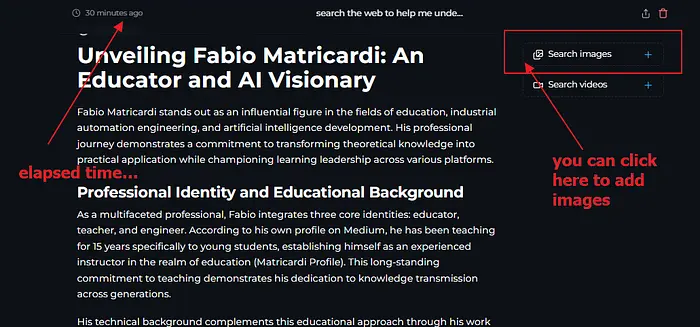
5、旁注
vane/Perplexica与本地AI一起运行是可能的任务。
即使使用像Qwen3.5–0.8b这样的小模型,结果也相当不错,推理过程流畅,幻觉几乎可以忽略不计。
但是……
- 一个查询需要长达30分钟,取决于您的CPU速度和可以使用多少线程
- 流程很费token:将您的上下文窗口至少增加到32k

6、最佳小型语言模型……以及原因
这是我对用于测试Perplexica的所有小型语言模型的简要报告:
Gemma-3n-E2B-it:这是一个稀疏模型,只有2B活跃参数。总体上相当不错,但它不能一次就得到正确结果。检索到的链接是一致的。可能一个未审查的版本会做得更好。推荐!
LFM-2.5–1.2b-instruct:我无法获得好的结果。如果您成功了,请留下评论告诉我您的设置。
Qwen3.5–0.8b:最小的一个,但令人惊讶地是最佳之一。它一次就得到了正确结果,但链接结果有一些问题。请注意,您需要超过25k token的上下文窗口。推荐!
Ministral-3–3B-Instruct-2512:正如预期的那样,它不好。
Granite-4.0-h-tiny:这是IBM的LLM,混合专家模型。通常不错,但引用链接有一些问题。但它一次就成功了!
Granite-3.1–3b-a800m-instruct:IBM的另一个混合专家模型。这一点都不好,从头到尾都在幻觉。
Trinity-Nano-Preview:这是一个MoE,总共6b参数但只有1b活跃。模型不错且响应迅速,但我们无法获得正确的链接。没有推理痕迹,但我们有图片。
Qwen3.5–2b:这是一个思考模型,阿里巴巴的最新一代。它比0.8b版本好一点,但慢得多。总体上非常好。推荐!
7、结束语
如果您设法读到最后……恭喜!
我试图给出所有步骤,因为我不想让你们中的任何人浪费我让它工作所花的同样多的时间。
如果您好奇,我会在以后的帖子中展示,可能也在我的Substack上,如何使用Perplexica:
- openrouter免费模型(开箱即用不可能,但我创建了我的方法)
- 在您本地网络的另一台计算机上运行的模型
原文链接: Your AI your rules: a free fully local Perplexity app on your PC
汇智网翻译整理,转载请标明出处
