向量索引和近似最近邻算法
暴力搜索的隐藏成本,以及ANN、IVF和HNSW如何将查询时间从100秒降低到10毫秒。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我曾经这样做过,滚动浏览数千张照片来寻找一张我的狗的照片。我知道它在那里。我只是找不到它。
你的手机上可能有数千张家人、朋友、狗狗的照片,但没有标签或标注。
在某个时候,你尝试过类似"显示我所有狗狗的照片"这样的操作。听起来简单。但并非如此。
这正是大多数AI系统正在解决的相同问题。Spotify判断接下来播放什么。聊天机器人拉取正确的文本块。照片应用尝试找到相似的图像。
在底层,它们都在回答同一个问题:
什么与此相似?
它们的做法是将所有相关信息转化为向量——基本上是数学空间中的点,相似的东西最终会靠在一起。这实际上是我之前文章的主题再次出现的地方,将文本、图像或用户活动等内容转化为向量,以便进行比较。
一旦你定义了向量,问题就变成了几何学上的:
找到空间中最近的点。
对于小型数据集,这可能很容易。你只需将查询与所有内容进行比较,然后选择最接近的匹配项。
当数据集增长时,它仍然有效。
直到它不再有效。
一旦你处理数百万甚至数十亿个向量时,这种方法不仅会变慢;它实际上会崩溃。在那个极限下,问题不再是找到相似的项目。而是要足够快地找到它们才能使用。
这就是所谓的向量索引和近似最近邻(ANN)方法发挥作用的地方。
1、为什么向量相似性搜索在规模上会失效
许多现代AI系统只被分配了一个任务,即回答这个问题:
这与此或彼相似吗?
无论是Spotify推荐你的下一首歌、聊天机器人从文档中提取上下文,还是照片应用查找你宠物的所有照片,它们都在使用某种向量搜索方法。
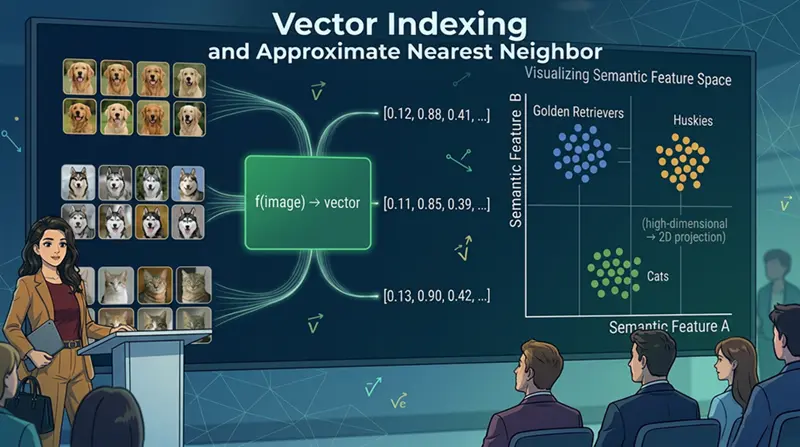
如上图所示,当你为每个项目创建一个向量时,它就变成了一组数字。一旦创建,模型就可以"学习"这些数字,将相似的项目在高维空间中分组在一起。所以具有相似氛围的一组歌曲会非常接近。
在小规模下,这很简单。你将查询与每个向量进行比较,然后返回最接近的匹配项。
几行NumPy代码就能实现。
然而,当你超越玩具数据集进入真实世界的规模时,问题就出现了。在生产环境中,系统通常处理数百万甚至数十亿个向量。在那个规模下,朴素的代码不仅感觉慢;它实际上变得极其不切实际。
2、理解向量嵌入:狗狗照片类比
让我们从上面的同一图示来理解这一点。你的手机上可能有数千张你的金毛猎犬和它的朋友——哈巴狗、哈士奇、比格犬的照片。现在你想找到你的金毛猎犬的每一张照片,但你从未给它们打标签。你不记得日期或地点。简单的筛选不会有帮助。
嵌入模型解决了这个问题。它检查每张照片——颜色、纹理、毛发图案、体型——并输出一长串数字:[0.12, 0.88, 0.41, ...]。每张照片都变成了高维空间中的一个点。你会看到金毛猎犬的照片最终在该空间的一个区域聚集在一起。哈士奇的照片形成了不同的簇。你的猫的照片则完全生活在另一个岛屿上。
我们可以将相同的机制应用于文本。例如,"外面是晴天吗?"产生一个与天气文章相近的向量,而这些文章实际上从未使用过那些确切的词(晴天、外面),因为整体语义上(在上下文意义方面)相似的句子最终会靠在一起。
纯粹的数据类型实际上无关紧要——然而几何结构是相似的。
现在将照片集合从几千张扩展到一亿张,几何问题就变成了计算问题。
3、为什么暴力搜索在规模上会失效
找到最近向量的最简单方法是检查所有向量。你将查询与数据库中的每个项目进行比较,按距离排序,然后返回顶部结果。这被称为"扁平搜索",实际上工作得很好——它几乎总是返回精确答案。然而,问题在于,
在规模上的成本。
在单个CPU核心上,朴素的距离计算可能需要每个向量微秒级别的时间,这取决于维度和硬件。即使有批处理和并行化,为单个查询扫描1亿个向量仍然涉及大约10^8次距离计算,这使得实现亚10毫秒延迟极其具有挑战性。
在1亿个向量的情况下,每个查询大约需要100秒(将近2分钟)。
那不是一个慢的应用——而是一个根本不能用的应用。
现在将其扩展到Spotify的6亿用户,分布在各个时区,没有安静窗口,暴力搜索就不再只是变慢了。它变得计算上不可行。
更多的硬件有帮助,但不是成比例的——即使有GPU加速和批处理,大部分计算都浪费在永远不会出现在最终结果中的向量上。
扁平搜索并非无用。在大约50,000个向量以下的数据集、构建评估基准、调试嵌入是否正常工作时使用它——如果扁平搜索返回不好的邻居,任何近似索引都无法挽救你。但在生产规模下,扁平搜索不是优化目标。它完全就是不合适的算法。100秒和10毫秒之间的差距不能仅靠硬件来弥补。
4、向量索引实际做什么
解决办法是停止将每个查询视为一次全新的完整扫描。向量索引是一种你在所有向量上预先构建的数据结构。它组织向量,使相似的项目落在可导航的区域。这意味着查询可以直接跳转到相关区域并跳过其他所有内容。你只需支付一次构建成本。每个后续查询都会受益。
在高层面上,这就是引入向量索引时发生的变化。以下图示解释了这一点。
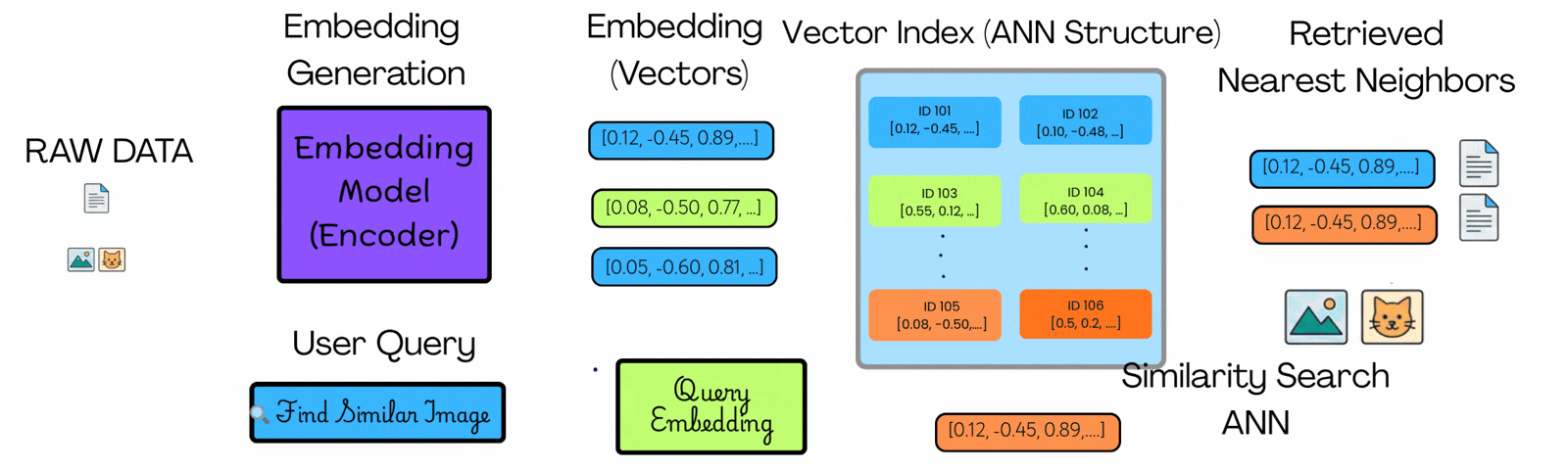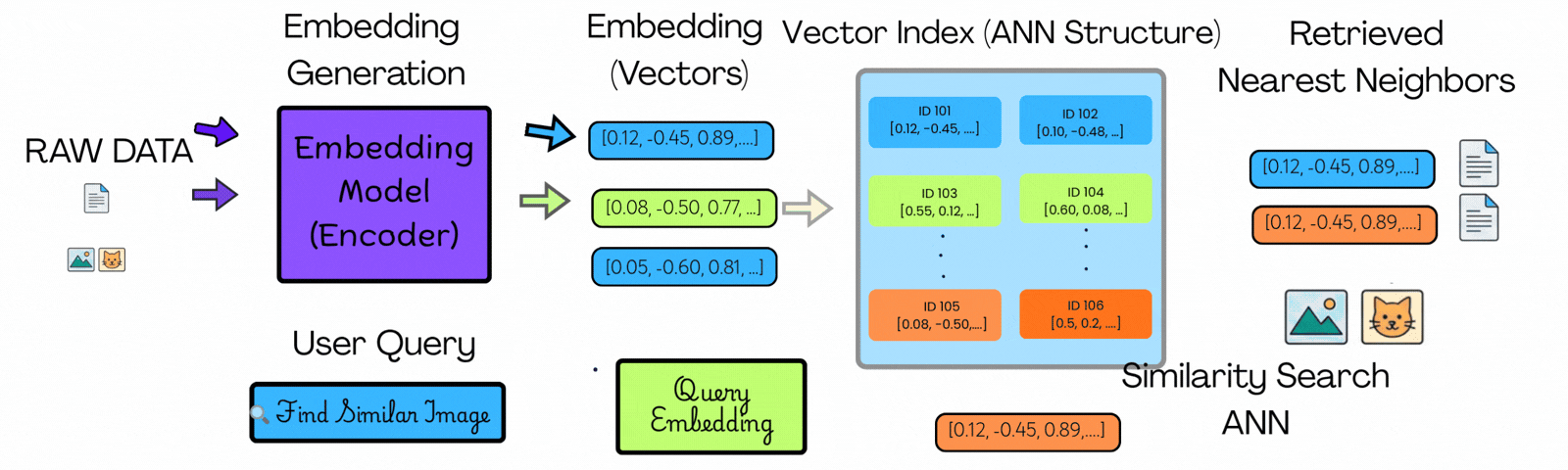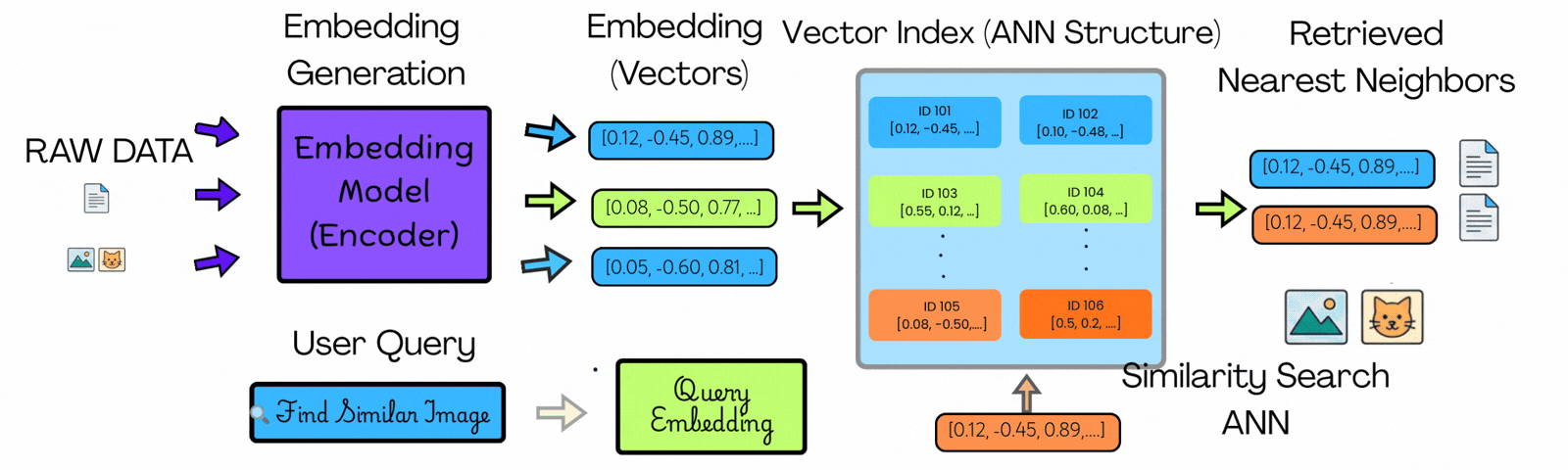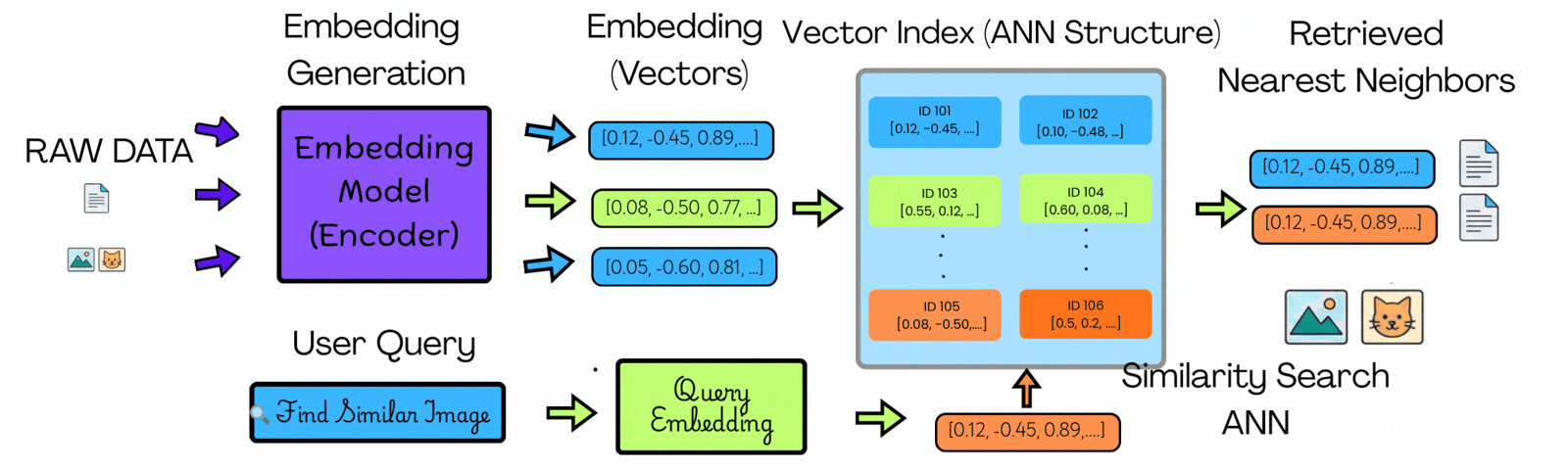
在左侧,你可以看到原始数据(如图像、文本或文档)使用嵌入模型转换为向量。每个项目都变成了一组捕捉其上下文含义的数字。
用户查询经历相同的过程,在同一空间中产生用户查询向量。
在中间,你可以看到这些向量不仅仅是存储——它们被组织在所谓的向量索引中。这种结构将相似的项目分组在一起,因此系统不需要到处查找。
当查询到来时,搜索不会扫描所有向量。它导航索引到一个小的、上下文相关的候选子集。
在右侧,你可以看到只有该子集中最近的匹配项作为结果返回。
关键区别不是更快的比较——而是更少的比较。
不需要扫描所有内容,查询直接进入一个小的相关区域。这就是100秒变成10毫秒的方式。
在许多生产工作负载中,ANN索引可以达到90-99%的召回率,而成本只是精确搜索的一小部分,一旦你调整了nprobe或ef_search等参数。
索引和搜索在完全不同的时间尺度上运行。构建时间以分钟或小时衡量——你只需支付一次的成本。查询时间以毫秒衡量——你需支付数十亿次的成本。
围绕这种分离进行设计就是整个游戏。
三种不同的索引策略在不同规模上以不同的权衡解决这一挑战。每种策略都回答相同的问题"如何跳过不相关的数据?"但方式不同。
不幸的是,大多数教程只告诉你每个算法是什么。但它们很少解释为什么相同的城市地图隐喻(IVF的分区、HNSW的分层高速公路)以三种不同的方式回答相同的基本问题。这就是下面图示所展示的。
策略1:扁平索引——精确搜索基线
看下面的动画。一个查询,比如一张狗的照片,被转化为一个向量,空间中的一个点。从那里,系统将其与数据库中存储的每个向量进行比较。
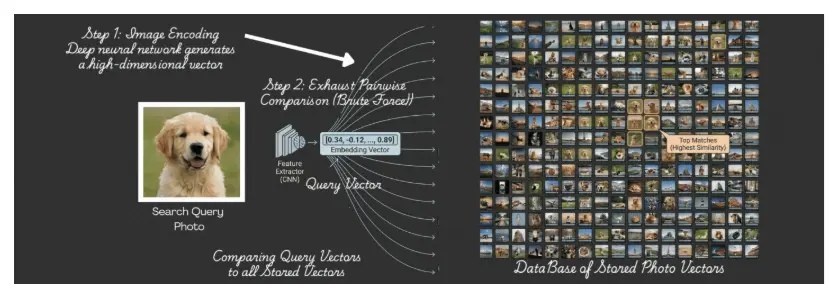
没有筛选步骤或候选列表;每个项目依次被检查。每次比较都是距离计算:"这个存储的项目离查询有多远?"
这就是扁平索引。它不组织数据,也不将搜索引导到有前景的区域。它只是评估每个候选并返回最接近的匹配项。
对于小集合,这种方法效果很好并给出精确结果。然而,在1亿个向量时,它变得不切实际,因为比较次数会压垮系统。
问题不在于距离计算——而在于你需要计算多少个距离。
建议在数据集少于50K向量、评估或调试嵌入时使用此方法。
策略2:IVF——将向量空间划分为分区
下面的动画清晰地展示了IVF(倒排文件索引)的两步逻辑。让我们来看看这种方法的两个主要步骤。
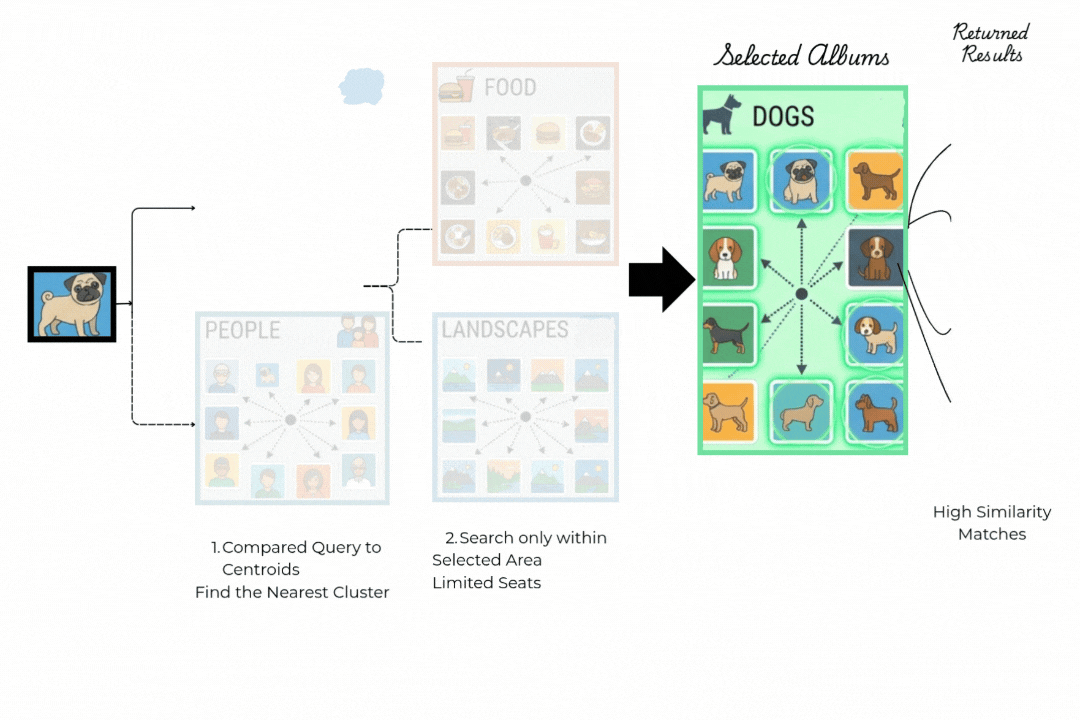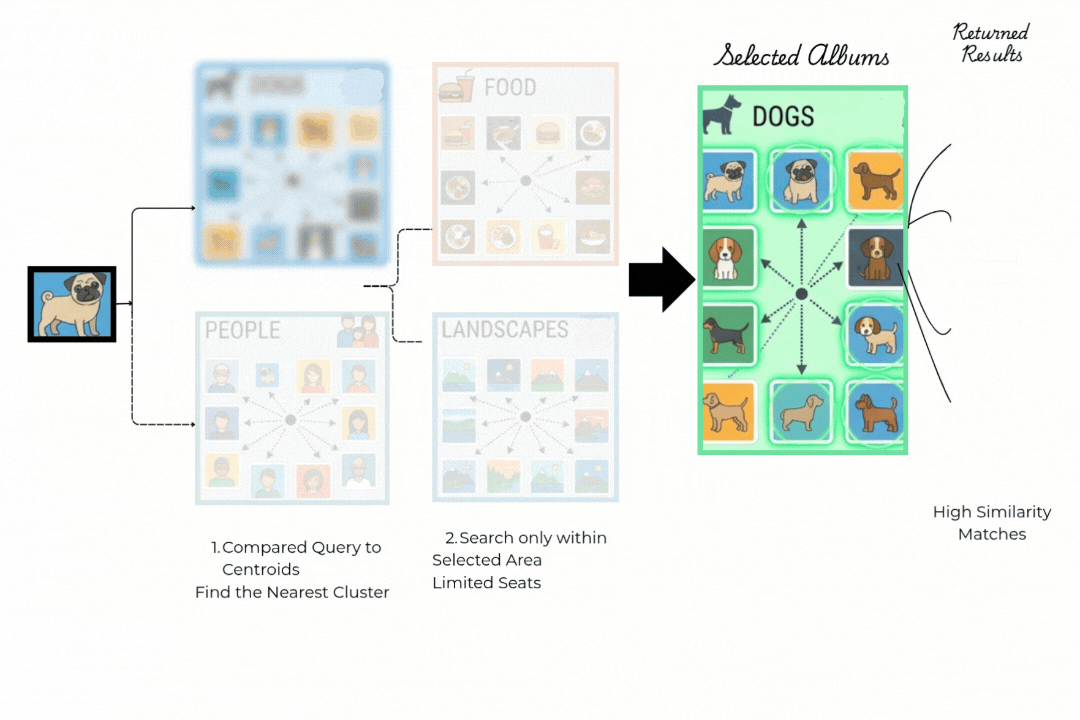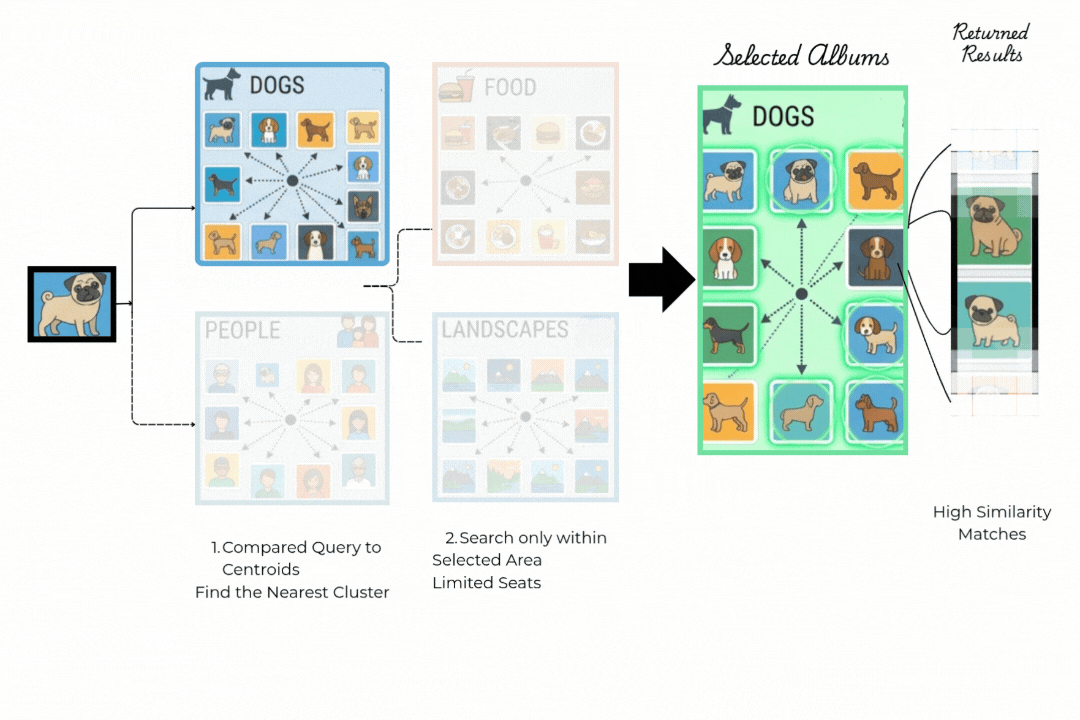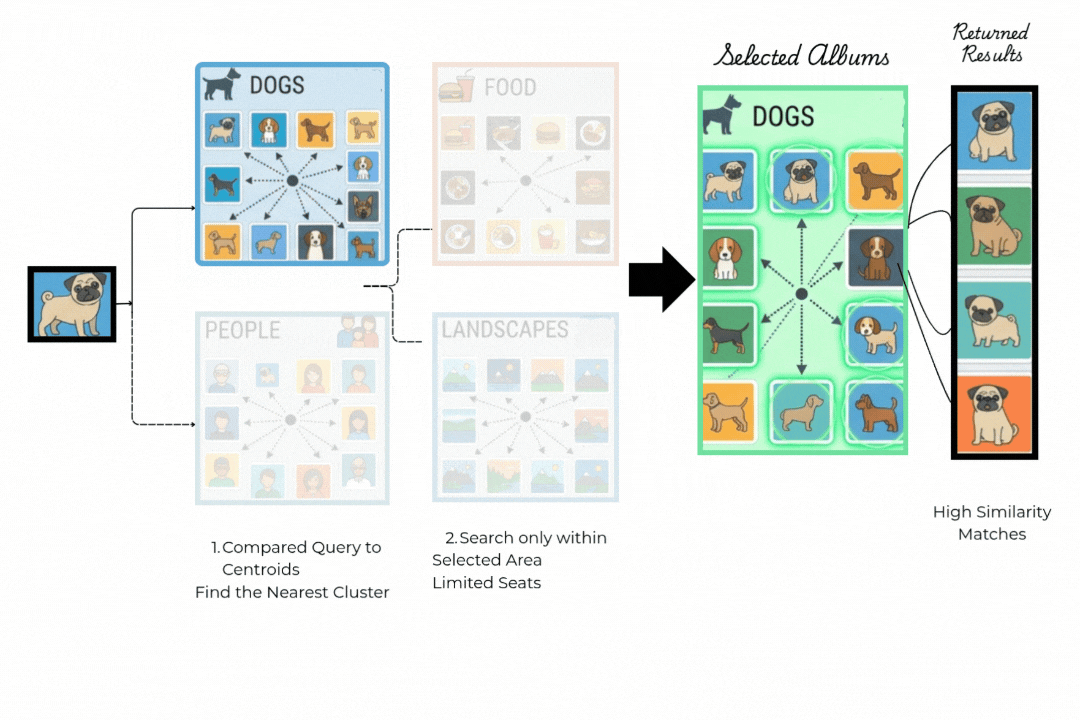
步骤1:路由到正确的簇。
你的查询(哈巴狗)不是与每张照片比较,而是与一小部分所谓的簇质心比较,比如食物、人物、风景、狗。IVF找到最近的质心并完全忽略所有其他簇。这一个比较决定了整个搜索实际发生的位置。
步骤2:仅在获胜者内部搜索。
只搜索狗的簇。从簇中心出发的箭头到达该区域中最相似的项目。
调优参数nprobe控制检查多少个簇。增加它可以提高召回率,而减少它可以加快搜索速度。大多数团队调整它直到召回率达到95%。
建议在大型静态数据集、需要可预测查询延迟时使用此方法。
策略3:HNSW——向量高速公路
下面的图示通过三层展示了HNSW(分层可导航小世界)。将每一层理解为一种道路类型。
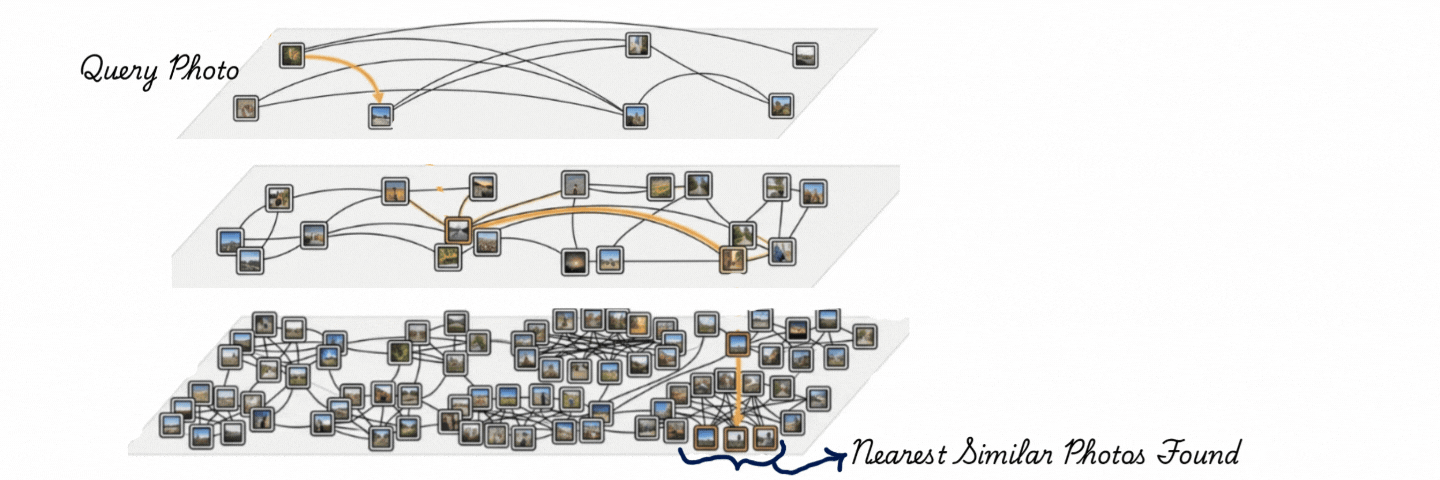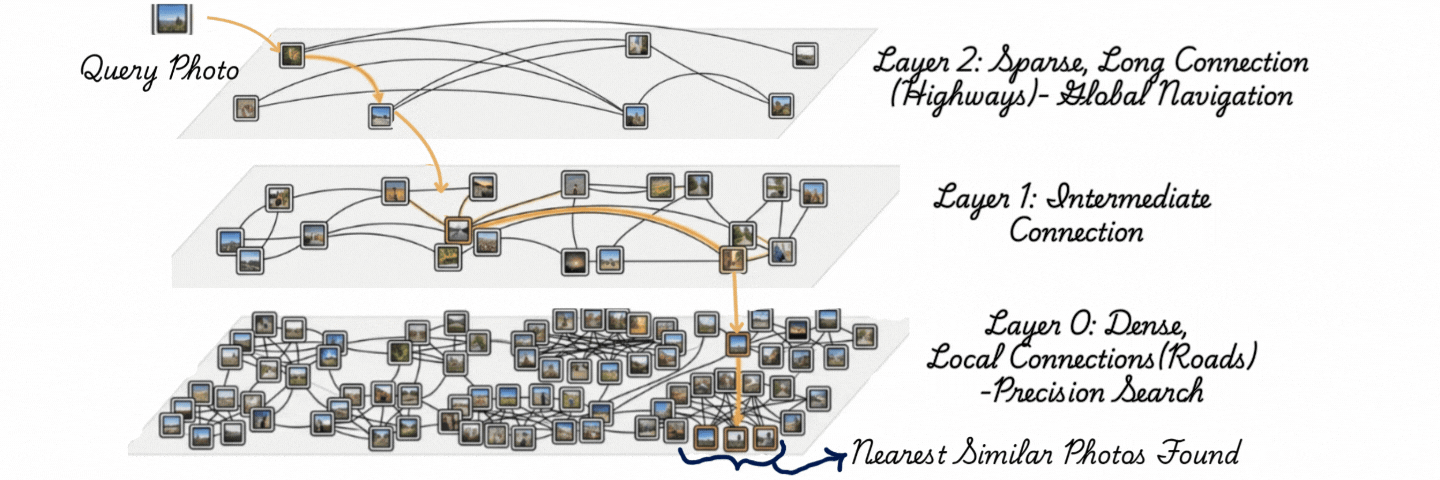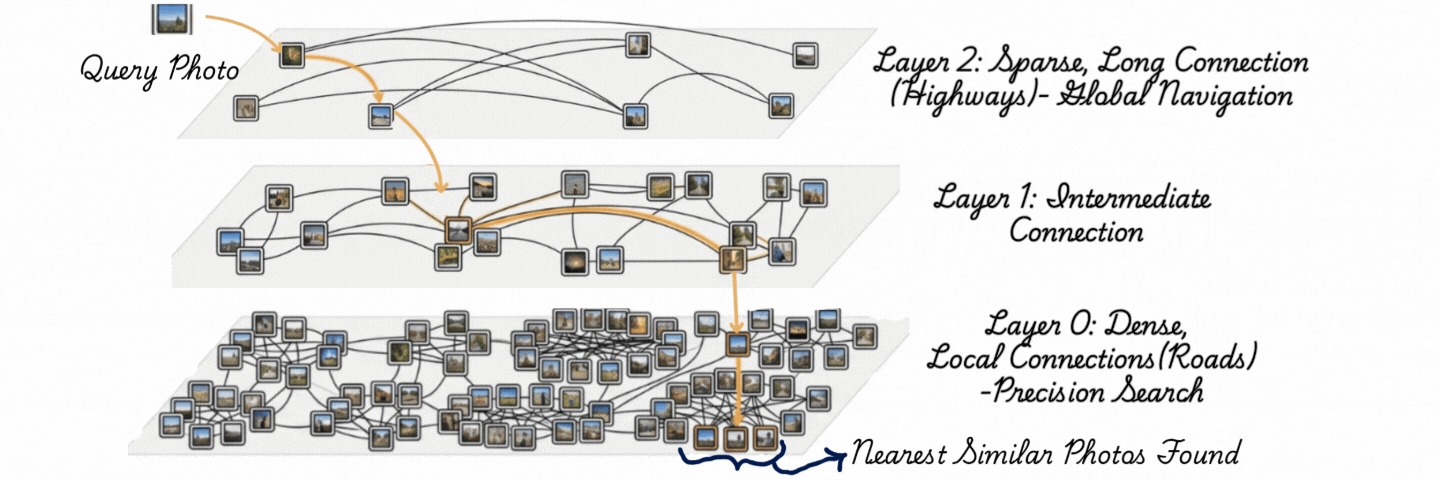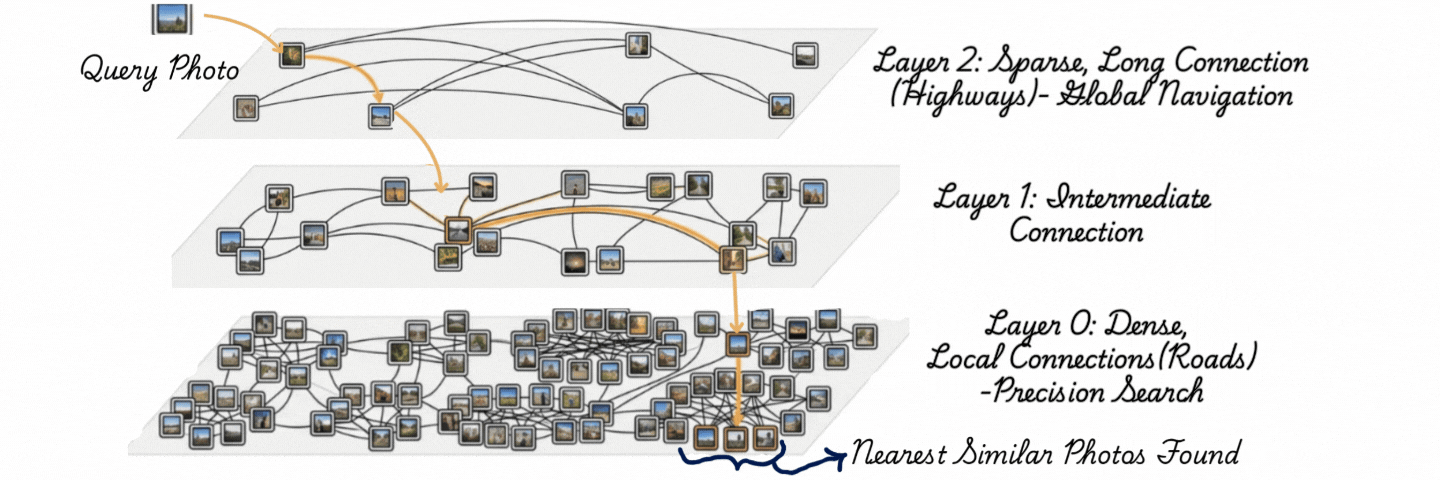
HNSW(分层可导航小世界)搜索:查询导航分层图,使用长距离连接进行全局搜索,使用密集的本地连接进行精确的最近邻检索。
顶层是高速公路——稀疏的节点,跳过整个空间的长边。
中间层是主干道——更多的节点,更短的连接。
底层是本地街道——每个向量都住在这里,与邻居密集相连。
搜索从高速公路进入,贪心地向目标跳跃,当无法再接近时下降一层,用更短的步长细化。到达街道层时,它已经从完整数据集缩小到少数候选。
在构建时,向量逐一插入;每个向量被分配一个随机的最大层级,并在它所占据的每个层级与其附近的邻居相连。在查询时,在底层遍历期间维护一个有界的候选池(由ef_search控制)。理论复杂度是𝒪(log n)——数据集翻倍只会增加少量额外的跳跃。
HNSW还支持增量插入,无需完全重建。这意味着你可以随时添加新向量,而无需修改现有图。这就是为什么它是大多数生产向量数据库中的默认索引。
权衡在于内存:HNSW显式存储节点间连接,除了向量本身外,每个向量大约需要50-100字节的开销。
HNSW不搜索一切——它导航空间。
建议用于推荐、语义搜索、RAG——任何需要在线更新的系统。
5、ANN:为什么速度胜过完美准确率
扁平搜索返回精确结果。IVF和HNSW以明显更低的延迟返回近似结果(通常95%到99%的召回率)。然而,问题在于哪种适合你的工作负载,而不是哪种在抽象上更好(见下图)。
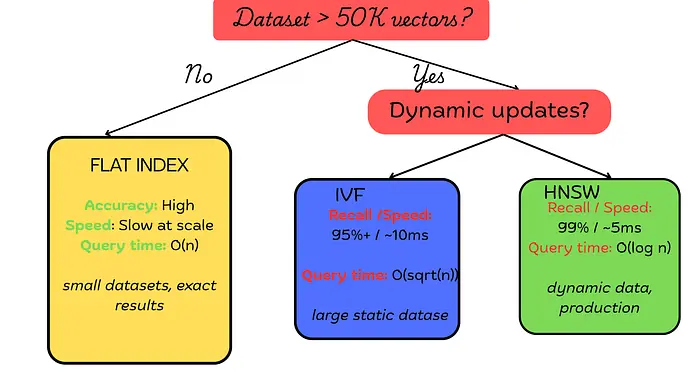
三种索引策略,一个决定:将算法与你的数据集大小、更新频率和准确率要求相匹配。
IVF和HNSW都是ANN(近似最近邻)算法。它们返回很可能正确但不是数学保证的结果。
为什么要接受这种权衡?——因为精确搜索无法扩展。
如前所述,在高维向量空间中,随着数据集增长,暴力搜索很快变得计算昂贵。
这种权衡是否重要完全取决于应用场景。当系统推荐歌曲或展示相似产品时,精确最近邻和前几个最相似结果之间的差异对用户来说实际上感觉不到。
你可以使用扁平搜索进行离线评估和审计;它给你基准来衡量其他所有方法。你可以使用近似索引处理实时流量(推荐、语义搜索、RAG流水线),其中小的失误率对用户是不可见的,毫秒级延迟是必需的。
如果你在严格的法律或合规要求下运营,这可能需要可重现的精确结果。那么你可以在离线运行扁平搜索作为审计层,同时通过近似索引处理实时请求。所以这两种策略是互补的,而不是竞争的。
ANN不追求完美——它在约束条件下优化有用性。

ANN向量搜索如何工作:离线构建嵌入和索引(HNSW或IVF),然后执行快速近似最近邻查询,在毫秒内检索top-k相似结果。使用Canva创建
你不需要完美的答案——你需要一个足够好的答案,而且要快。
6、索引之外:为生产扩展向量数据库
索引精确解决了一个问题,即如何快速找到最近的向量。然而,它不存储原始文档、不按元数据筛选、不处理插入和删除、也不跨机器扩展。向量索引是一种搜索算法。但生产AI系统需要更多。这就是我下一篇文章将要涵盖的内容——理解这种区别是区分构建可用系统的团队和陷入概念验证基础设施的团队的关键。
原文链接: How AI Finds Results Without Searching Everything
汇智网翻译整理,转载请标明出处
