语音AI代理开发指南
大多数语音AI教程跳过了决定其他一切的架构决策,以下是生产团队实际部署的内容,包含可运行的代码。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署 | Tripo 3D | Meshy AI
我们停止说话和语音代理响应之间有一个小差距。
大多数人注意到它,但没有给它命名。
不到500毫秒,对话感觉自然。 不到300毫秒,感觉像在和人说话。 超过800毫秒,即使措辞完美,也感觉有问题。
那个差距、里面填充了什么、持续多长时间、内部发生了什么,是目前语音AI的全部工程故事。
每个架构决策、每个框架选择、每个模型选择只有一个工作:
让那个差距尽可能短、尽可能像人。
本指南涵盖完整内容:定义该领域的三个架构、支持生产部署的开源框架、每个主要路径的快速入门、比其他任何东西都更扼杀语音代理的技术细节,以及选择正确方法的明确决策框架。
1、语音AI实际发生了什么变化
在讨论架构之前,理解为什么去年是一个真正的拐点而不是炒作会有所帮助——但这是同时改变语音AI经济和质量的三个具体因素。
定价崩溃。 OpenAI将Realtime API音频定价降低了60%以上,并以原价的一小部分引入了gpt-4o-mini-realtime。过去花一美元的东西现在只需几美分。构建与购买的成本计算一夜之间改变了。
原生音频模型投入生产。 Google的Gemini 2.5 Flash Native Audio在Vertex AI上全面可用。OpenAI发布了gpt-realtime,平均延迟低于300毫秒。
这些不是研究项目,而是具有SLA的GA API。
框架成熟度超越了原型阶段。
Pipecat部署的生产语音流量超过1亿小时,获得了NVIDIA作为参考平台合作伙伴,并发布了托管云。 LiveKit Agents v1.0与负载均衡和Kubernetes支持一起推出。 Agora的TEN Framework发布了自己的VAD和轮次检测模型,在企业基准测试中优于Silero。
现在开源中确实存在认真构建这项工作的基础设施。
问题不再是是否构建,而是如何正确构建。
2、三个语音代理架构
语音AI中的一切都映射到三个基础模式之一。正确选择这个决定了我们的延迟上限、成本下限,以及随着时间推移调试和改进系统的能力。
架构1:级联管道
用户说话
│
▼
[ STT ] ← Deepgram Nova-3, AssemblyAI Universal-Streaming,
│ gpt-4o-transcribe
│ 文本
▼
[ LLM ] ← GPT-4o-mini, Claude Sonnet, Gemini 2.5 Flash,
│ Llama 4, Mistral
│ 文本
▼
[ TTS ] ← Cartesia Sonic, ElevenLabs, gpt-4o-mini-tts, Rime
│
▼
用户听到
这是目前主导的生产架构。
三个专业模型顺序运行,纯文本是它们之间的共享货币。
每个模型都擅长做一件事。
现实的端到端延迟:500-800毫秒。
优势是模块化。
我们可以独立交换Deepgram和AssemblyAI、交换GPT-4o-mini和Claude、交换Cartesia和ElevenLabs……而不影响系统的其他部分。
我们获得完整的转录日志以满足合规要求、组件级可观察性,以及单独微调每个部分的能力。
大多数高音量、基于电话、对合规敏感的系统都运行在这个架构上,不是因为它最复杂,而是因为它最可控。
弱点是那些交接。
每个模型之间的边界都会增加延迟,而PSTN电话(普通电话)运行在8kHz音频上,会降低链中每个模型的质量。
架构2:半级联
用户说话
│
▼ 原生音频输入
[ 音频感知LLM ] ← Gemini Live 2.5 Flash,
│ ElevenLabs Agents后端
│ 文本标记
▼
[ 专业TTS ] ← Cartesia, ElevenLabs语音合成
│
▼
用户听到
这是大多数文章错过的架构……但可以说这是目前最有趣的。
输入原生进入多模态模型,直接保留语调、口音和情感寄存器。
输出仍然通过专业TTS模型,保持语音质量和可控性。
现实的端到端延迟:300-500毫秒。
我们获得的是输入端真正的音频理解。
模型听到用户听起来很沮丧,或者他们用上升语调提问,或者他们在句子中间切换了语言……不需要转录步骤告诉它。
我们保持的是对输出语音的细粒度控制。
ElevenLabs Agents和Google的生产Gemini Live模型(gemini-live-2.5-flash-preview)都使用这种模式。
架构3:原生语音到语音
用户说话
│
▼ 原始音频输入
[ 单一多模态模型 ] ← OpenAI gpt-realtime,
│ Gemini 2.5 Flash Native Audio,
│ Ultravox(开放权重)
▼ 原始音频输出
用户听到
一个模型。
音频输入,音频输出。没有文本中间商,没有交接,没有单独的组件。
模型被训练直接在音频空间中推理,它捕捉情感语调、非语言线索、句子中间的语言切换——文本根本无法表示的东西。
现实的端到端延迟:200-300毫秒。 gpt-realtime平均低于300毫秒。
这真的在接近人类对话的节奏。
低于300毫秒,体验不再感觉像在和软件说话,开始感觉像在和某人说话。
权衡是真实的。
首先,成本:S2S模型使用上下文累积定价,意味着模型在每次对话中重新处理所有之前的对话标记。 一个在按分钟计算器上看起来像0.30美元/分钟的通话,在长对话中实际上可以达到1.50美元/分钟以上。 其次,控制:我们不能交换组件,我们在一个提供商的系统内。 第三,电话质量下降:8kHz的PSTN音频剥离了使原生音频理解有价值的大部分内容,在电话上显著缩小了与级联管道的质量差距。
3、诚实的比较
我们选择的框架决定了我们管理多少基础设施、有多少灵活性,以及从想法到部署代理的速度有多快。
3.1 生产级语音编排框架
这些是支持严肃生产部署的框架。
它们处理困难的部分:实时音频传输、上下文聚合和轮次检测。
Pipecat(by Daily.co)
最广泛部署的开源语音编排框架。构建在基于帧的管道模型上:音频、文本和视频都作为类型化的"帧"通过可交换的"处理器"链传输。
我们管道中处理器的顺序就是架构。
NVIDIA将其作为官方语音代理参考平台采用。 年度语音流量1亿小时以上。 0+个AI服务集成。 Apache 2.0。
当我们想要最大控制、最大生态系统,并能够确切理解代理在每个阶段在做什么时,选择Pipecat。
LiveKit Agents
WebRTC原生语音代理基础设施。不是管道,我们的代理是LiveKit房间的参与者,作为实时同行加入、监听和响应。
抽象比Pipecat更高级。我们告诉它使用什么STT、LLM和TTS,它处理协调。
由OpenAI和Character.ai在生产中使用。 Python和Node.js。 Apache 2.0。
当我们想要最干净的API、最快的代理工作路径,以及紧密的WebRTC基础设施集成时,选择LiveKit。
TEN Framework(by Agora)
多模态、多语言、实时代理的基于图的扩展框架。
Pipecat用管道思考,TEN用节点和图思考……每个"扩展"可以用Python、Go、C++或TypeScript编写,使其特别适合多语言团队和边缘/物联网部署(它可以在ESP32硬件上运行)。
它发布了自己的VAD(TEN-VAD)和轮次检测模型,在企业数据集上基准测试优于Silero。
当我们需要多语言运行时支持、硬件/物联网集成,或复杂的基于图的对话流程时,选择TEN。
3.2 轻量级入口点
为更快的启动、原型或特定用例设计的更简单工具。
Vocode: Python语音代理空间中最简单的抽象。
三个对象:转录器(STT)、代理(LLM)、合成器(TTS)。
将它们连接在StreamingConversation中,我们就有了一个可工作的语音机器人。
非常适合初学者、快速电话机器人和Zoom集成。
不适合高容量部署的生产加固。
FastRTC(Hugging Face):从想法到我们可以实际呼叫的语音代理的最快路径。调用stream.ui.launch(),我们得到一个浏览器界面。
调用stream.fastphone(),Hugging Face给我们一个可以呼叫的真实电话号码,几分钟内,无需基础设施。
非常适合ML研究人员和快速演示。
3.3 开放权重S2S模型
不是框架,这些是模型本身,可用于自托管。
Ultravox: 基于Llama 3.3 70B构建的开放权重语音到语音模型。
目前在VoiceBench(87.1)和Big Bench Audio(91.8)语音模型中排名第一。 可在Hugging Face上自托管或通过ultravox.ai的托管API(0.05美元/分钟,前30分钟免费)。 是S2S用例中OpenAI Realtime和Gemini Live唯一的严肃开放权重替代品。
Moshi(Kyutai Labs,通过Gradium商业化):真正的原生音频S2S,一个模型,在任何阶段都没有文本中间商。
Gradium以7000万美元种子资金启动,将Moshi商业化用于企业用例。 自托管需要A100/H100级GPU。
早期客户在游戏和客户支持领域。
4、Pipecat,级联管道
这是大多数开发者的正确第一个构建。它教我们各部分如何组合在一起,提供完全控制,并产生生产就绪的代理。
我们将构建: 一个通过WebRTC(在浏览器中)聆听的语音助手,用Deepgram转录,用GPT-4o-mini推理,用Cartesia回复,支持完全中断和对话记忆。
安装:
# 创建项目
uv init my-voice-agent && cd my-voice-agent
# 安装Pipecat及我们需要的服务
uv add "pipecat-ai[daily,openai,deepgram,cartesia,silero]"
uv是现代Python包管理器(比pip快)。括号中的额外内容拉入特定服务集成……Daily用于WebRTC传输,其他用于AI服务。
API密钥:
# .env
DAILY_API_KEY=your_daily_key # WebRTC房间(免费层:10K分钟/月)
OPENAI_API_KEY=your_openai_key # GPT-4o-mini用于推理
DEEPGRAM_API_KEY=your_deepgram_key # Nova-3用于语音转文本
CARTESIA_API_KEY=your_cartesia_key # Sonic用于文本转语音
Daily是Pipecat背后的公司,提供WebRTC层、音频路由、浏览器兼容性、噪声消除。
他们的免费层涵盖原型设计和轻量开发。
代理:
# voice_agent.py
import asyncio
import os
from dotenv import load_dotenv
from pipecat.audio.vad.silero import SileroVADAnalyzer
from pipecat.pipeline.pipeline import Pipeline
from pipecat.pipeline.runner import PipelineRunner
from pipecat.pipeline.task import PipelineParams, PipelineTask
from pipecat.processors.aggregators.openai_llm_context import OpenAILLMContext
from pipecat.services.cartesia import CartesiaTTSService
from pipecat.services.deepgram import DeepgramSTTService
from pipecat.services.openai import OpenAILLMService
from pipecat.transports.services.daily import DailyParams, DailyTransport
load_dotenv()
async def run_agent(room_url: str, token: str):
# ── Transport ──────────────────────────────────────────────
# WebRTC mechanics: connects the browser to our agent,
# routes audio, manages connections.
transport = DailyTransport(
room_url,
token,
"Assistant",
DailyParams(
audio_out_enabled=True,
vad_enabled=True,
vad_analyzer=SileroVADAnalyzer(),
),
)
# ── STT ────────────────────────────────────────────────────
# Deepgram Nova-3: streaming transcription, ~20ms word latency.
stt = DeepgramSTTService(api_key=os.getenv("DEEPGRAM_API_KEY"))
# ── LLM ────────────────────────────────────────────────────
# GPT-4o-mini: 300-400ms TTFT, excellent instruction following.
llm = OpenAILLMService(
api_key=os.getenv("OPENAI_API_KEY"),
model="gpt-4o-mini",
)
# ── TTS ────────────────────────────────────────────────────
# Cartesia Sonic: ~90ms time-to-first-byte.
# LLM tokens stream directly into TTS.. speech begins before
# the LLM has finished generating the full response.
tts = CartesiaTTSService(
api_key=os.getenv("CARTESIA_API_KEY"),
voice_id="71a7ad14-091c-4e8e-a314-022ece01c121",
)
# ── System prompt ──────────────────────────────────────────
# Voice prompts need different writing than chat prompts.
# Short sentences. No bullet points. No markdown. Write for
# the ear.
messages = [
{
"role": "system",
"content": (
"You are a sharp, friendly voice assistant. "
"Keep every response under three sentences. "
"Never use lists, or bullet points. "
"You are speaking aloud - write for the ear, "
"not the eye."
),
}
]
# ── Context ────────────────────────────────────────────────
# Conversation memory: holds the full history of what the
# user said and what the agent responded.
context = OpenAILLMContext(messages)
context_aggregator = llm.create_context_aggregator(context)
# ── Pipeline ───────────────────────────────────────────────
# Frames flow left to right. Pipecat handles all async
# coordination, backpressure, and interruption logic.
pipeline = Pipeline([
transport.input(),
stt,
context_aggregator.user(),
llm,
tts,
transport.output(),
context_aggregator.assistant(),
])
task = PipelineTask(
pipeline,
params=PipelineParams(
allow_interruptions=True,
enable_metrics=True,
),
)
@transport.event_handler("on_client_connected")
async def on_connected(transport, client):
messages.append({
"role": "system",
"content": "Warmly greet the user and ask how you "
"can help."
})
await task.queue_frames(
[context_aggregator.user().get_context_frame()]
)
runner = PipelineRunner()
await runner.run(task)
运行和测试:
# Pipecat的本地运行器创建一个WebRTC房间并提供浏览器UI
python voice_agent.py --local-test
# 打开 http://localhost:7860 → 点击Join → 开始说话
# 控制台打印实时转录和每轮延迟指标
当我们准备好跳过本地测试时,将--local-test换成start,代理注册到Daily的云并等待大规模调度会话。
5、LiveKit Agents,最快路径
LiveKit的抽象比Pipecat更高级。我们声明我们想要什么服务,框架将它们连接在一起。
更少的代码,更少的控制……但对于许多用例,这是正确的权衡。
同样的语音助手,用LiveKit Agents编写:
pip install "livekit-agents[openai,deepgram,cartesia,silero,turn-detector]~=1.0"
python -m livekit.agents download-files # 下载本地VAD模型一次
# agent.py
import os
from dotenv import load_dotenv
from livekit import agents
from livekit.agents import AgentSession, Agent
from livekit.plugins import openai, deepgram, cartesia, silero
load_dotenv()
class VoiceAssistant(Agent):
def __init__(self):
super().__init__(instructions=(
"You are a friendly voice assistant. "
"Keep responses under three sentences. "
"Never use markdown or lists."
))
async def entrypoint(ctx: agents.JobContext):
await ctx.connect()
session = AgentSession(
stt=deepgram.STT(model="nova-3"),
llm=openai.LLM(model="gpt-4o-mini"),
tts=cartesia.TTS(
voice="71a7ad14-091c-4e8e-a314-022ece01c121"
),
vad=silero.VAD.load(),
)
await session.start(
room=ctx.room, agent=VoiceAssistant()
)
await session.generate_reply(
instructions="Greet the user warmly and ask how you "
"can help."
)
if __name__ == "__main__":
agents.cli.run_app(
agents.WorkerOptions(entrypoint_fnc=entrypoint)
)
# 开发模式:使用本地麦克风,无需浏览器
python agent.py dev
# 通过浏览器测试:访问 https://agents-playground.livekit.io
同样的技术栈……Deepgram、GPT-4o-mini、Cartesia,但代码少约60%。
我们放弃的是帧级控制和在各阶段之间插入自定义处理器的能力。
对于大多数标准语音助手用例,LiveKit的抽象完全正确。
6、OpenAI Realtime API,语音到语音路径
当我们需要尽可能低的延迟,并构建原生Web或面向消费者的体验时,Realtime API完全移除了管道。
一个WebSocket连接,一个模型,音频进音频出。
注意: OpenAI Python SDK现在有内置的Realtime支持。下面的原始WebSocket方法显示了在引擎盖下发生的事情…… 在生产中,考虑使用SDK的OpenAIRealtimeWS助手或浏览器的WebRTC路径。pip install openai websockets pyaudio
# realtime_agent.py
import asyncio, json, os, base64
import websockets
from dotenv import load_dotenv
load_dotenv()
async def voice_agent():
url = (
"wss://api.openai.com/v1/realtime"
"?model=gpt-realtime"
)
headers = {
"Authorization": f"Bearer {os.getenv('OPENAI_API_KEY')}",
"OpenAI-Beta": "realtime=v1",
}
async with websockets.connect(
url, additional_headers=headers
) as ws:
# 配置会话..系统提示等价物
await ws.send(json.dumps({
"type": "session.update",
"session": {
"modalities": ["text", "audio"],
"instructions": (
"You are a concise, friendly voice "
"assistant. Keep all responses under "
"three sentences."
),
"voice": "cedar",
"input_audio_format": "pcm16",
"output_audio_format": "pcm16",
"turn_detection": {
"type": "server_vad",
"threshold": 0.5,
"silence_duration_ms": 500,
},
},
}))
print("Connected. Speak now.")
async for raw in ws:
event = json.loads(raw)
if event["type"] == "response.audio.delta":
audio = base64.b64decode(event["delta"])
# play_audio(audio) ← 平台音频输出
elif event["type"] == (
"conversation.item"
".input_audio_transcription.completed"
):
# 侧信道:用户说了什么的转录
print(f"User: {event['transcript']}")
elif event["type"] == "response.done":
print("Agent finished responding.")
asyncio.run(voice_agent())
这里发生的事情与管道方法真的不同。
没有单独的STT、LLM和TTS API调用。模型接收原始音频字节,原生推理它们,并生成原始音频字节作为响应……全部通过一个持久的WebSocket。
我们看到的转录是侧信道输出,而不是管道阶段。
对于浏览器客户端,OpenAI也直接支持WebRTC,浏览器与模型对话,无需后端中继。这再移除一个网络跳数,进一步降低延迟。
提交前要做的成本计算: 5分钟带有上下文累积的对话可能比按分钟定价页面上看起来贵4-6倍。
在扩展之前,始终将实际对话长度与真实定价模型进行基准测试。
7、扼杀语音代理最多的那件事
基于Hamming AI对10000个部署代理的400万次生产语音通话的分析,单个被抱怨最多的失败不是转录准确性,不是响应质量,也不是延迟。
是代理在用户说了一半时打断。
从技术上讲,这是假阳性中断——系统错误地确定用户已经完成轮次,而实际上还没有。这令人不安,它打破了对话流程,用户报告为"代理不听话",即使其他一切都正常工作。
问题有三层解决方案,每个都越来越复杂。
第1级:基于沉默的VAD: 等待最小持续时间的沉默,然后假设轮次结束。Silero VAD在CPU上本地执行此操作,开销接近零,它是生产中最常见的基线。
它在句子中间停顿时失败——某人在查找数字、选择措辞、思考中途中断。代理突然介入,用户感到被打断。
第2级:语义轮次检测: LiveKit的句末停顿模型和AssemblyAI的通用流式轮次检测分析所说的音频和语言内容。
具有上升语调和不完整语义结构的句子(如"我的信用卡号码是……")即使之后有沉默,也不会注册为完成的轮次。
这是当前的生产标准。
第3级:韵律感知轮次检测。 前沿。ElevenLabs专有的轮次检测结合音调、节奏和语言内容的语音强调进行分析。
它认识到句子中间的"嗯"意味着"我仍在思考"……而不是"轮到你了"。它理解领域背景很重要:客户服务电话中的轮次模式与 casual对话中的不同。
尚未以开源形式广泛可用。
实际上:从Silero VAD开始获得可工作的原型,转移到语义轮次检测进行生产,并跟踪假阳性中断作为KPI。这是我们的代理对真实用户感觉多自然的金丝雀指标。
8、部署语音代理到生产
托管云(最快):
Pipecat和LiveKit都提供托管云部署,处理容器化、自动扩展和监控,无需我们自己的基础设施。
# Pipecat Cloud
pip install pipecat-cli
pipecat deploy voice_agent.py
# LiveKit Cloud.. 注册代理工作者,LiveKit调度会话
python agent.py start
# 然后访问 https://agents-playground.livekit.io 连接
两者都自动处理负载均衡……当流量增加时,添加更多工作者进程,平台跨它们分发会话。
自托管Docker(最大控制):
当我们超过每月约50,000分钟时,自托管通常节省70-80%成本。
代理是无状态的,所以水平扩展很简单。
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install "pipecat-ai[daily,openai,deepgram,cartesia,silero]"
# 在构建时下载Silero VAD模型,而不是运行时
RUN python -c \
"from pipecat.audio.vad.silero import SileroVADAnalyzer; \
SileroVADAnalyzer()"
COPY . .
CMD ["python", "voice_agent.py"]
docker build -t voice-agent .
docker run --env-file .env voice-agent
# 水平扩展
docker run --env-file .env voice-agent # worker 2
docker run --env-file .env voice-agent # worker 3
关于电话的说明:所有主要框架都通过Twilio、Telnyx或Plivo支持SIP/PSTN集成。Pipecat有TwilioTransport。 LiveKit有一级SIP支持。 VAPI和Retell在平台级别管理这个。 但是,8kHz的PSTN音频明显低于基于浏览器的16-48kHz WebRTC……计划在电话上可衡量的准确性下降,并相应调整STT模型选择。9、我们应该选择哪个语音代理技术栈
一张表,所有级别,基于数千个部署团队的真实观察模式。
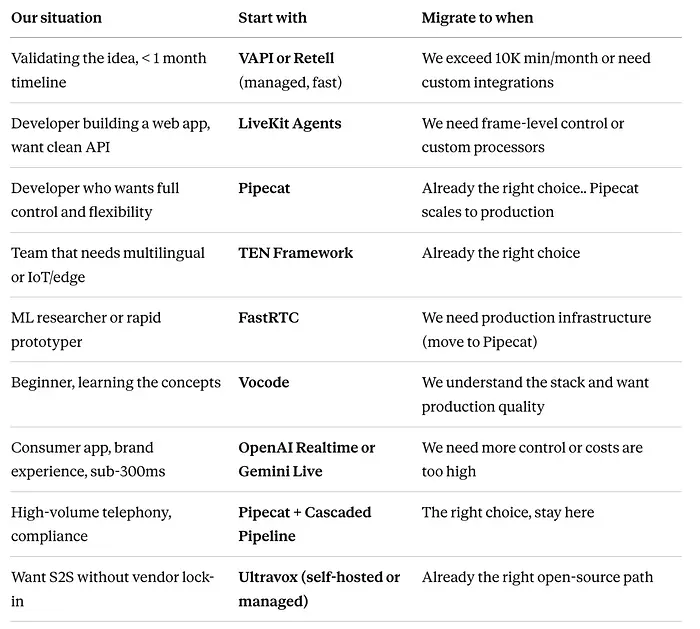
最常重复的模式: 团队从VAPI或Retell开始快速验证,然后在他们知道自己在构建什么并需要拥有基础设施时迁移到Pipecat。
迁移并非微不足道,但经济学令人信服……每月50K+分钟,自托管Pipecat通常比托管平台便宜5-10倍。
10、语音AI代理的下一步发展
开放权重S2S将达到生产质量。 Ultravox已经在语音特定评估上基准测试优于专有替代品。
Gradium(Moshi商业化)最近加入了第一批企业客户。生产规模的可自托管语音到语音比大多数人意识到的更接近。
Pipecat Flows 添加结构化对话状态管理,我们将分支对话逻辑设计为具有前置动作和后置动作的可组合节点。
这是生产代理如何处理复杂多步骤工作流而不产生脚本外幻觉的方式。
上下文累积成本将强制架构重新评估。 随着S2S部署扩展,研究人员和团队发现长对话可能比粗略估计的成本高5-10倍。定价模式创新即将到来。
11、结束语
语音AI不是一件事。它是一系列刻意叠加的选择:架构第一,框架第二,模型选择第三,轮次检测策略第四,部署路径第五。
上面的代码是真实的,并根据官方文档进行了测试。
延迟数字来自生产基准,而不是实验室条件。
框架比较反映了数千个团队实际如何构建和重建他们的系统。
构建伟大语音代理最难的部分不是代码。是在理解问题形态之前的快速行动冲动。
第一周做出的架构决策在第八周改变是昂贵的。
花时间。理解差距。然后好好填补它。
原文链接: The Voice AI Agent Architectures Every Developer Must Know
汇智网翻译整理,转载请标明出处
