ZincSearch轻量全文搜索引擎
完全用Go构建,由Bluge索引库驱动,ZincSearch以显著更低的开销处理全文搜索。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
设置简单,资源消耗只是零头,完全API兼容:这真的吗?
Elasticsearch是大规模搜索和分析的 powerhouse,但许多独立开发者,开发团队正在慢慢转向ZincSearch用于日常项目。完全用Go构建,由Bluge索引库驱动,ZincSearch以显著更低的开销处理全文搜索。它在单个二进制文件或Docker容器上运行,秒级启动,无需Elasticsearch项目中常见的减速就能提供生产就绪的结果。
让我们谈谈ZincSearch如何改变游戏规则,以及它今天如何使你的团队受益。
1、区别
从一开始就能体验到资源使用的差异。单个ZincSearch实例可以索引和查询数百万文档,而只消耗几百MB RAM和最少CPU。相比之下,Elasticsearch即使在加载第一个数据集之前就经常需要几GB内存。对于运行在云实例、边缘设备或紧张开发预算的团队来说,这些节省直接转化为更低的账单和更简单的基础设施。
ZincSearch还消除了长期以来定义Elasticsearch的复杂性。你不需要配置几十个旋钮用于堆大小、线程池或分片分配才能开始。相反,你设置几个环境变量,指向数据目录的卷,就可以运行了。这种设计选择源于对开发者体验的刻意关注:快速获取价值,需要时扩展,避免运维负担。
2、Elasticsearch vs ZincSearch对比
为了让优势具体化,这里是选择开发工作搜索引擎时最重要的功能的清晰并列分解。
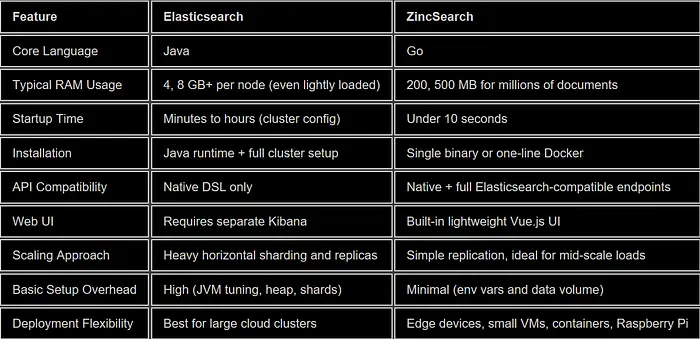
3、这些差异如何影响开发
上述数字改变了团队每天构建、发布和维护搜索功能的方式。
- 显著更低的RAM和CPU使用意味着你可以在廉价云实例甚至边缘硬件上运行生产搜索,在许多情况下将基础设施成本削减60-90%,使全文搜索对于曾经排除它的项目变得可行。
- 近即时启动和单一二进制简单性将本地开发时间从数小时的集群启动削减到秒级,因此工程师保持flow状态,原型更快到达用户。
- 完全API兼容性让你重用现有客户端库、Logstash管道和批量摄取脚本,几乎无需更改,消除通常的迁移摩擦,让团队渐进采用ZincSearch或运行混合环境。
- 内置Vue.js UI为大多数日常探索取代了整个Kibana堆栈,为想要快速查询数据的小团队或独立开发者节省设置时间和持续维护。
- 更简单的扩展模型让开发者从持续的分片重平衡和JVM调优中解放出来,将注意力转回应用逻辑而不是照看基础设施。
兼容性
这个故事最好的部分是兼容性。ZincSearch暴露其原生API和Elasticsearch兼容端点。你可以继续使用熟悉的批量摄取格式、查询DSL结构,甚至现有客户端库在Python、Java或Node.js中,只需最小更改。像Fluentd、Logstash或Filebeat这样的工具通过指向ZincSearch的Elasticsearch输出端点开箱即用。这种兼容性降低了迁移风险,让团队渐进采用ZincSearch,无需重写管道。
可访问性
内置Vue.js Web UI增加了另一个实用层。无需安装和维护Kibana,你在浏览器中打开4080端口,登录,立即浏览索引、运行查询和探索结果,高亮和分页已处理。界面即使在普通硬件上也保持轻量和响应迅速。
性能
社区报告和生产部署的性能比较持续突出差距。ZincSearch在磁盘上高效索引实时数据,同时保持低内存占用。Elasticsearch在大规模水平集群(数千节点)方面很棒,但对于大多数应用、日志分析、应用搜索、内容目录或内部工具,开销很快变得不必要。你会体验到设置时间从数小时的集群配置降到ZincSearch的两分钟内。
资源效率
资源效率也开辟了新的部署模式。你可以在Raspberry Pi级硬件、小型云VM或Kubernetes中资源受限的容器中舒适地运行ZincSearch。这种灵活性对边缘计算、物联网数据搜索或之前因Elasticsearch太重而完全避免全文搜索的成本敏感初创公司很重要。
4、设置
ZincSearch的设置在环境中遵循一致、可重复的过程。最快路径使用Docker,在macOS、Linux和Windows上工作相同。
创建一个简单的docker-compose.yml文件,内容如下:
version: "3.8"
services:
zinc:
image: public.ecr.aws/zinclabs/zinc:latest
ports:
- "4080:4080"
environment:
ZINC_FIRST_ADMIN_USER: admin
ZINC_FIRST_ADMIN_PASSWORD: passWord#123
ZINC_DATA_PATH: /data
ZINC_PROMETHEUS_ENABLE: "true"
volumes:
- zinc_data:/data
restart: unless-stopped
volumes:
zinc_data:
运行docker compose up -d,服务立即启动。用快速健康检查验证:
curl -u admin:passWord#123 http://localhost:4080/api/fauxy
在浏览器中打开http://localhost:4080,用admin凭证登录,你就有了一个功能齐全的搜索引擎,带有干净的UI,可以立即处理数据。
对于本地二进制安装,从GitHub仓库下载最新版本。在Linux或macOS上,解压二进制,创建数据目录,用环境变量运行:
mkdir data
ZINC_FIRST_ADMIN_USER=admin ZINC_FIRST_ADMIN_PASSWORD=passWord#123 ./zincsearch
macOS上的Homebrew用户可以用brew install zinclabs/tap/zincsearch安装。Windows用相同模式使用.exe并设置环境变量。使用仓库提供的官方部署YAML或Helm chart,Kubernetes部署同样简单。
一旦运行,数据摄取镜像Elasticsearch模式,简化集成。创建带可选映射的索引以获得更好控制,或让ZincSearch自动检测字段用于快速原型。这里是创建products索引的示例:
curl -X POST http://localhost:4080/api/index \
-u admin:passWord#123 \
-H "Content-Type: application/json" \
-d '{
"name": "products",
"storage_type": "disk",
"mappings": {
"properties": {
"name": { "type": "text", "index": true, "store": true, "highlightable": true },
"price": { "type": "numeric", "index": true, "store": true, "sortable": true }
}
}
}'
批量摄取使用熟悉的Elasticsearch格式,使得重用现有脚本或管道变得 trivial:
curl -X POST http://localhost:4080/api/_bulk \
-u admin:passWord#123 \
-H "Content-Type: application/json" \
-d '
{"index": {"_index": "products"}}
{"name": "Wireless Headphones", "price": 149.99}
{"index": {"_index": "products"}}
{"name": "Mechanical Keyboard", "price": 89.99}
'
对于日志密集型工作负载,通过配置Elasticsearch输出插件指向ZincSearch,直接与Fluentd或类似传输器集成。相同兼容性扩展到搜索查询。你可以使用原生/api/{index}/_search端点或Elasticsearch兼容的/es/{index}/_search路径,支持match、bool、query_string等常见子句。
在应用代码中,现有Elasticsearch客户端通常只需更改base URL就能工作。使用requests的简单Python示例展示了集成感觉多么自然:
import requests
ZINC_URL = "http://localhost:4080"
AUTH = ("admin", "passWord#123")
def search_products(query):
response = requests.post(
f"{ZINC_URL}/api/products/_search",
auth=AUTH,
json={"query": {"match": {"name": query}}}
)
return response.json()
如果你决定指向完整的Elasticsearch集群,这段代码不加更改就能运行。灵活性降低了锁定,支持渐进测试。
5、ZincSearch用例
- 日志分析和可观测性管道从其低开销和实时索引中受益。团队用应用日志、审计跟踪或监控数据替换重型Elasticsearch集群,在许多情况下将基础设施成本削减60-90%。
- 电子商务和CMS平台的产品目录或内容搜索获得快速、模式灵活的索引,无需手动管理分片或副本。
- 内部工具和开发者仪表板使用内置UI在原型设计期间快速探索数据,然后将相同API暴露给前端应用。
6、从ZincSearch学到的编程教训
- 优先考虑最小可行基础设施。通过专注于单个二进制文件和基于Bluge的磁盘索引,创建者避免了将Elasticsearch变成运维重型系统的复杂性蔓延。
- API兼容性加速 adoption。ZincSearch不是强迫用户学习新的查询语言或客户端库,而是在开发者已经在的地方与他们相遇。
- Go的优势:编译时安全、低内存使用和易于并发使其成为在负载下必须保持精简的服务的理想选择。
- ZincSearch对严格映射和自动字段检测的支持鼓励迭代开发。你可以从无模式开始以获得速度,然后在需求明确时细化映射,无需停机或重新索引头疼。
超过数十亿文档的超大规模集群、高级机器学习功能或与完整Elastic Stack的深度集成仍然偏向原始Elasticsearch。需要Kibana丰富可视化或企业安全模块的团队可能继续使用Elasticsearch或OpenSearch。ZincSearch在当前状态也缺少一些高级聚合类型和地理功能,尽管核心全文和基本分析覆盖大多数用例。
7、结束语
期待更多项目采用Go或Rust用于核心服务,强调API兼容性以实现无缝迁移路径,并在原始查询延迟旁边优先考虑开发者体验指标。ZincSearch的成功也强化了一个关键教训:最好的工具通常用20%的复杂性解决80%的问题。早期为边缘情况过度工程会造成不必要的负担。
我希望ZincSearch帮助你在降低 cost 和 complexity的情况下推动你的新想法,这样你可以专注于最重要的事情:向用户交付价值。感谢阅读。
原文链接: ZincSearch Vs Elasticsearch: You'll Love This Go Search Engine
汇智网翻译整理,发表于2026-03-19
