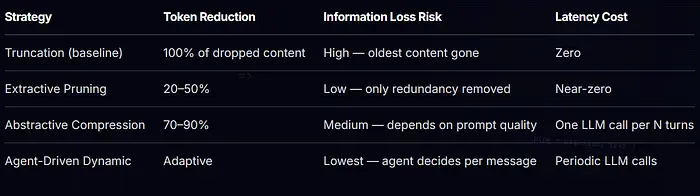
LLM上下文压缩的3个策略
每次 LLM 调用都是一场与硬限制的谈判。GPT-4o 给你 128K token。Claude 3.7 给你 200K。Gemini 1.5 Pro 扩展到 1M……
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
每次 LLM 调用都是一场与硬限制的谈判。GPT-4o 给你 128K token。Claude 3.7 给你 200K。Gemini 1.5 Pro 扩展到 1M。这些数字看起来很慷慨,直到你在多轮编程会话中奋战三小时、将一份 90 页的合同输入法律分析智能体、或运行一个需要最近 200 条消息才能维持连贯上下文的客服机器人时,你才会感受到限制。
天真的解决方案是截断:丢弃最旧的消息,希望里面没有重要的内容。RAG 的解决方案是检索:嵌入所有内容并按需拉取分块。两者都是妥协。截断会破坏信息。RAG 是无状态的——它无法像人类线性阅读文档那样在检索到的片段之间进行推理。
存在第三条路:压缩。在保留语义内容的同时,减少已有内容的 token 数量。做得好时,压缩可以让你将 32K token 的对话塞进 8K token,而 LLM 察觉不到差异。做得不好时,它会引入幻觉、丢失关键命名实体并破坏推理链。
本文介绍了三种递进的压缩策略,每种都建立在前一种之上:
- 提取式剪枝——在不重写任何内容的情况下移除低信号 token 和消息
- 摘要式压缩——使用 LLM 将历史重写为密集摘要,无损保留事实
- 智能体驱动的动态上下文——一个智能体管理实时的压缩预算,决定哪些内容要压缩、哪些保留原文,并按需重新展开
每个阶段都包含完整的、可运行的 Python 实现。到最后,你将拥有一个生产就绪的上下文管理层,可以无缝集成到任何 LLM 应用中。
0、为什么压缩优于截断
考虑一个 40 轮的编程会话。前 20 轮确定了架构:数据库 schema、API 设计、选择异步而非同步。最后 20 轮正在积极调试一个特定的 bug。天真的截断只保留最后 20 轮——而 LLM 已经丢失了前半部分中做出的每一个架构决策。
RAG 检索理论上可以恢复这些信息,但 RAG 是为文档语料库设计的,而非对话上下文。对话具有顺序、因果关系和引用。"我们在第 3 轮写的函数"、"我之前提到的 bug"、"两步之前的 schema 变更"——这些不是可检索的事实;它们是推理线索的组成部分。
压缩保留了线索。不是丢弃第 3 轮,而是将其从 800 token 压缩到 80 token,保留函数签名、关键决策和结果。LLM 现在拥有了一个压缩但连续的历史记录。
1、提取式剪枝
提取式剪枝在不重写任何内容的情况下移除 token。它识别低信号材料——填充短语、重复内容、冗余的工具输出、稀疏的 JSON——并在字符级别将其剥离。不需要 LLM;这是纯文本处理。
关键原则:信号密度在对话中差异极大。一个工具调用返回了 3000 token 的 JSON,其中 2800 token 是空字段,实际信息只有约 200 token。一条以"当然!我很乐意帮你。让我一步步思考这个问题。"开头的助手消息,前 25 个 token 中零信息量。
提取式剪枝针对四个类别:
- 填充短语——开场客套话、过渡句、结束时的帮助提议
- 冗余重复——在回复之前复述上一条消息的消息
- 稀疏工具输出——高密度空值的 JSON/XML、带空页面的分页结果
- 过大的代码块——当只需要函数签名和文档字符串时,不需要完整的 200 行实现
extractive_pruner.py:
import re
import json
import tiktoken
from dataclasses import dataclass, field
from typing import Optional
from difflib import SequenceMatcher
FILLER_PATTERNS = [
r"^(Certainly|Sure|Of course|Absolutely|Great|Happy to help)[!,.]?\s*",
r"^I'd be happy to (help|assist) (you )?with that\.?\s*",
r"^Let me (think|walk you) (through|about) (this|that)\.?\s*",
r"\s*Is there anything else (I can help|you'd like to know)\??$",
r"\s*Let me know if you (need|have) (any|more) (questions|clarification)\.?$",
r"\s*Feel free to ask if (you need|there's) anything else\.?$",
]
COMPILED_FILLERS = [re.compile(p, re.IGNORECASE | re.MULTILINE) for p in FILLER_PATTERNS]
@dataclass
class Message:
role: str
content: str
token_count: int = 0
@dataclass
class PruningResult:
original_tokens: int
pruned_tokens: int
messages_pruned: int
reduction_pct: float
messages: list[Message]
class ExtractivePruner:
"""
Reduces token count by removing low-signal content without rewriting.
Operates purely on text — no LLM calls required.
"""
def __init__(
self,
model: str = "gpt-4o",
min_message_tokens: int = 10,
max_json_null_ratio: float = 0.4,
prune_code_bodies: bool = False,
):
self.enc = tiktoken.encoding_for_model(model)
self.min_message_tokens = min_message_tokens
self.max_json_null_ratio = max_json_null_ratio
self.prune_code_bodies = prune_code_bodies
def count_tokens(self, text: str) -> int:
return len(self.enc.encode(text))
def strip_fillers(self, text: str) -> str:
"""Remove filler phrases from the beginning and end of a message."""
for pattern in COMPILED_FILLERS:
text = pattern.sub("", text)
return text.strip()
def compress_json(self, text: str) -> str:
"""
Compact JSON tool outputs by removing null/empty fields.
Falls back to original if not valid JSON.
"""
try:
data = json.loads(text)
except (json.JSONDecodeError, ValueError):
return text
def remove_nulls(obj):
if isinstance(obj, dict):
return {
k: remove_nulls(v)
for k, v in obj.items()
if v is not None and v != "" and v != [] and v != {}
}
if isinstance(obj, list):
return [remove_nulls(i) for i in obj if i is not None]
return obj
cleaned = remove_nulls(data)
original_size = len(text)
compact = json.dumps(cleaned, separators=(",", ":"))
null_ratio = 1 - (len(compact) / original_size)
if null_ratio > self.max_json_null_ratio:
return compact
return text
def prune_code_block(self, text: str) -> str:
"""
If prune_code_bodies is enabled, replace function bodies with '...'
while preserving signatures and docstrings.
"""
if not self.prune_code_bodies:
return text
pattern = re.compile(
r"(def \w+\([^)]*\).*?:[ \t]*\n(?:[ \t]+['''\"]{3}.*?['''\"]{3}\n)?)((?:[ \t]+.*\n)+)",
re.MULTILINE,
)
def replace_body(match):
signature = match.group(1)
body = match.group(2)
body_tokens = self.count_tokens(body)
if body_tokens > 150:
indent = re.match(r"[ \t]+", body)
ind = indent.group() if indent else " "
return f"{signature}{ind}...\n"
return match.group(0)
return pattern.sub(replace_body, text)
def deduplicate(self, messages: list[Message]) -> list[Message]:
"""
Remove messages whose content is a near-exact repeat of the previous message.
Threshold: >85% character overlap using SequenceMatcher ratio.
"""
if len(messages) < 2:
return messages
result = [messages[0]]
for msg in messages[1:]:
prev = result[-1]
if msg.role == prev.role:
ratio = SequenceMatcher(None, prev.content, msg.content).ratio()
if ratio > 0.85:
continue
result.append(msg)
return result
def prune_message(self, msg: Message) -> Message:
"""Apply all pruning strategies to a single message."""
content = msg.content
if msg.role == "assistant":
content = self.strip_fillers(content)
if msg.role == "tool" or (msg.role == "assistant" and content.strip().startswith("{")):
content = self.compress_json(content)
if "```" in content or "def " in content:
content = self.prune_code_block(content)
return Message(
role=msg.role,
content=content,
token_count=self.count_tokens(content),
)
def prune(self, messages: list[Message]) -> PruningResult:
"""
Apply all extractive pruning strategies to a message list.
Args:
messages: List of conversation messages.
Returns:
PruningResult with token counts and pruned messages.
"""
original_tokens = sum(self.count_tokens(m.content) for m in messages)
pruned = [self.prune_message(m) for m in messages]
pruned = self.deduplicate(pruned)
pruned = [m for m in pruned if m.token_count >= self.min_message_tokens]
pruned_tokens = sum(m.token_count for m in pruned)
reduction = (original_tokens - pruned_tokens) / original_tokens * 100 if original_tokens else 0
return PruningResult(
original_tokens=original_tokens,
pruned_tokens=pruned_tokens,
messages_pruned=len(messages) - len(pruned),
reduction_pct=round(reduction, 1),
messages=pruned,
)
提取式剪枝应用了四种技术——填充词移除、JSON 压缩、代码体替换和去重——无需任何 LLM 调用,在典型对话日志上可实现 20-50% 的 token 缩减。
关键洞察:提取式剪枝对于信息密集的内容是无损的。函数签名和文档字符串被保留;只有函数体会被替换。JSON 结果被保留;只有空字段被移除。没有事实被发明或扭曲——内容要么原样保留,要么完全移除。
但提取式剪枝有天花板。你可以移除填充词和压缩 JSON,但每条消息的核心语义内容仍然保持在原始 token 大小。要实现 70-90% 的缩减,你需要重写历史——而不是移除它。
2、摘要式压缩
摘要式压缩使用 LLM 将最近的消息窗口转换为密集摘要。挑战在于不丢失信息的情况下做到这一点。一个天真的"总结这个对话"提示会产生流畅的文本,听起来正确但会遗漏具体细节:确切的变量名、精确的数值、错误消息、函数签名——正是下一条 LLM 调用需要的细节。
解决方案是一个结构化压缩提示,带有明确的保留规则。压缩器必须被指示将代码标识符、数字和错误字符串视为神圣不可侵犯——压缩散文,绝不压缩数据。
该架构有两个组件:
- 滑动窗口压缩器——当上下文超出预算时,将最旧的 N 轮压缩为摘要块,保留最新的 M 轮原文不变* 渐进式摘要——每个新摘要都合并之前的摘要,因此历史信息会累积而不会增长
abstractive_compressor.py:
import asyncio
import tiktoken
from dataclasses import dataclass, field
from typing import Optional
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate
COMPRESSION_SYSTEM = """You are a context compression engine for LLM conversations.
Your task: compress a block of conversation turns into a dense, lossless summary.
CRITICAL RULES — never violate these:
1. Preserve ALL named entities: variable names, function names, class names, file paths, URLs.
2. Preserve ALL numerical values: counts, prices, IDs, versions, scores, timestamps.
3. Preserve ALL error messages and exception types verbatim (in backticks).
4. Preserve ALL code snippets that were agreed upon or defined — use inline code.
5. Preserve ALL decisions: "we decided to use X", "user rejected Y", "the bug was Z".
6. Compress prose aggressively. Remove pleasantries, repetition, and verbose explanations.
7. Use structured format: bullet points, key:value pairs, inline code for identifiers.
8. Never invent information. Never generalize specific facts into vague statements.
9. Target compression ratio: 8:1 (800 tokens -> ~100 tokens).
Output format:
[COMPRESSED HISTORY - turns {start} to {end}]
• Context: <1-2 sentences of what was being worked on>
• Decisions: <bullet list of key decisions made>
• Code defined: <inline code for any functions/classes/variables established>
• Errors seen: <exact error messages if any>
• Current state: <where things stood at the end of this block>
"""
COMPRESSION_HUMAN = """Compress these conversation turns:
{conversation_block}
Previous compressed history (incorporate this context):
{previous_summary}
"""
@dataclass
class ConversationMessage:
role: str
content: str
@dataclass
class ContextWindow:
"""Manages a live conversation context with a token budget."""
budget_tokens: int
verbatim_turns: int = 8
compressor_model: str = "gpt-4o-mini"
full_model: str = "gpt-4o"
messages: list[ConversationMessage] = field(default_factory=list)
compressed_summary: str = ""
_total_turns: int = 0
def __post_init__(self):
self.enc = tiktoken.encoding_for_model(self.full_model)
self.llm = ChatOpenAI(model=self.compressor_model, temperature=0.0)
def count_tokens(self, text: str) -> int:
return len(self.enc.encode(text))
def total_tokens(self) -> int:
msg_tokens = sum(self.count_tokens(m.content) for m in self.messages)
summary_tokens = self.count_tokens(self.compressed_summary)
return msg_tokens + summary_tokens
def add_message(self, role: str, content: str):
"""Add a new message to the context."""
self.messages.append(ConversationMessage(role=role, content=content))
self._total_turns += 1
async def compress_oldest_block(self, block_size: int = 6) -> str:
"""
Compress the oldest `block_size` turns into a summary.
Incorporates any previously compressed summary for continuity.
Args:
block_size: Number of turns to compress in one pass.
Returns:
The new compressed summary string.
"""
if len(self.messages) <= block_size:
return self.compressed_summary
to_compress = self.messages[:block_size]
self.messages = self.messages[block_size:]
turn_start = self._total_turns - len(self.messages) - block_size + 1
turn_end = turn_start + block_size - 1
conversation_block = "\n\n".join(
f"[{m.role.upper()}]: {m.content}" for m in to_compress
)
prompt = ChatPromptTemplate.from_messages([
("system", COMPRESSION_SYSTEM.format(start=turn_start, end=turn_end)),
("human", COMPRESSION_HUMAN),
])
chain = prompt | self.llm
response = await chain.ainvoke({
"conversation_block": conversation_block,
"previous_summary": self.compressed_summary or "None — this is the first compression.",
})
new_summary = response.content.strip()
original_tokens = sum(self.count_tokens(m.content) for m in to_compress)
compressed_tokens = self.count_tokens(new_summary)
ratio = original_tokens / compressed_tokens if compressed_tokens else 0
print(
f"[Compressor] Turns {turn_start}-{turn_end}: "
f"{original_tokens} -> {compressed_tokens} tokens ({ratio:.1f}x compression)"
)
self.compressed_summary = new_summary
return new_summary
async def ensure_fits(self) -> bool:
"""
Compress until the context fits within the token budget.
Keeps the most recent `verbatim_turns` messages uncompressed.
Returns:
True if compression was performed, False if already within budget.
"""
if self.total_tokens() <= self.budget_tokens:
return False
print(f"[ContextWindow] Budget exceeded: {self.total_tokens()} / {self.budget_tokens} tokens. Compressing...")
while self.total_tokens() > self.budget_tokens and len(self.messages) > self.verbatim_turns:
compressible = len(self.messages) - self.verbatim_turns
block = min(6, compressible)
if block < 2:
break
await self.compress_oldest_block(block_size=block)
print(f"[ContextWindow] After compression: {self.total_tokens()} tokens")
return True
def build_prompt_messages(self) -> list:
"""
Build the final list of LangChain messages to send to the LLM.
Injects compressed history as a system context block.
"""
result = []
if self.compressed_summary:
result.append(SystemMessage(content=(
"The following is a compressed summary of earlier conversation history. "
"All facts, names, and code in this summary are accurate and should be treated "
"as if you had the full conversation.\n\n"
+ self.compressed_summary
)))
for msg in self.messages:
if msg.role == "user":
result.append(HumanMessage(content=msg.content))
elif msg.role == "assistant":
result.append(AIMessage(content=msg.content))
else:
result.append(SystemMessage(content=f"[{msg.role.upper()}]: {msg.content}"))
return result
ContextWindow 类维护一个滚动压缩预算。当总 token 数超出限制时,最旧的块使用结构化提示进行压缩——保留所有代码标识符、错误消息和决策——然后用一个密集摘要替换,后续压缩会在其基础上逐步构建。
渐进式摘要方法至关重要。每次压缩并不是丢弃之前的摘要——而是合并它们。压缩器同时接收要压缩的块和现有摘要,生成一个捕获完整历史的新统一摘要。这意味着无论对话运行多久,摘要始终保持有界,同时持续积累事实。
3、智能体驱动的动态上下文管理
提取式剪枝和摘要式压缩都是机械式的——它们应用固定规则而不考虑内容。第三种也是最强力的方法是智能体驱动:一个理解当前任务语义的智能体,做出关于压缩什么、保留什么原文以及按需从压缩摘要中重新展开什么的智能决策。
核心洞察:在當前任务的上下文中,不是所有消息都是平等的。在一个长的调试会话中,第一次识别出 bug 的那条消息是神圣的——它绝不能因压缩而丢失。它之前的三条消息,智能体在错误方向上搜索的那些,可以安全地进行激进压缩。机械压缩器无法区分这些;智能体可以。
智能体驱动的方法在前两种方法之上增加了三种能力:
- 重要性评分——智能体根据当前任务目标评估每条消息,并分配保留优先级
- 选择性压缩——
critical和high优先级的消息保持原文;low和droppable的消息被激进压缩或移除 - 按需展开——如果智能体检测到需要压缩块中的细节,它可以请求原始内容的重新展开
dynamic_context_manager.py
import asyncio
import json
import tiktoken
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
class RetentionPriority(str, Enum):
CRITICAL = "critical"
HIGH = "high"
MEDIUM = "medium"
LOW = "low"
DROPPABLE = "droppable"
@dataclass
class ManagedMessage:
role: str
content: str
turn_id: int
priority: RetentionPriority = RetentionPriority.MEDIUM
compressed_version: Optional[str] = None
is_compressed: bool = False
original_tokens: int = 0
current_tokens: int = 0
SCORER_SYSTEM = """You are a context importance scorer for an AI agent conversation.
Given the current task goal and a set of conversation turns, score each turn's
importance to the ongoing task.
For each turn, output a JSON object with:
- turn_id: the integer turn ID
- priority: one of "critical", "high", "medium", "low", "droppable"
- reason: one sentence explaining the score
Priority definitions:
- critical: Contains the core problem definition, key constraints, agreed solution, or active bug
- high: Contains important decisions, working code, or data that is actively referenced
- medium: Contains useful context that might be referenced later
- low: Contains exploratory discussion, failed attempts, or verbose explanations
- droppable: Contains filler, off-topic content, or complete repetition of other turns
Output a JSON array of these objects, one per turn. Nothing else.
"""
class DynamicContextManager:
"""
Agent-driven context manager that scores message importance against
the current task goal and makes intelligent compression decisions.
"""
def __init__(
self,
budget_tokens: int = 8000,
scorer_model: str = "gpt-4o-mini",
compressor_model: str = "gpt-4o-mini",
working_model: str = "gpt-4o",
):
self.budget_tokens = budget_tokens
self.enc = tiktoken.encoding_for_model(working_model)
self.scorer = ChatOpenAI(model=scorer_model, temperature=0.0)
self.compressor = ChatOpenAI(model=compressor_model, temperature=0.0)
self.messages: list[ManagedMessage] = []
self.task_goal: str = ""
self._turn_counter = 0
def count_tokens(self, text: str) -> int:
return len(self.enc.encode(text))
def set_task_goal(self, goal: str):
"""Set the current task goal used for importance scoring."""
self.task_goal = goal
def add_message(self, role: str, content: str) -> ManagedMessage:
"""Add a message and track its token count."""
tokens = self.count_tokens(content)
msg = ManagedMessage(
role=role,
content=content,
turn_id=self._turn_counter,
original_tokens=tokens,
current_tokens=tokens,
)
self.messages.append(msg)
self._turn_counter += 1
return msg
def total_tokens(self) -> int:
return sum(m.current_tokens for m in self.messages)
async def score_importance(self, messages: list[ManagedMessage]) -> list:
"""
Ask the scorer LLM to evaluate each message's importance
relative to the current task goal.
"""
turns_text = "\n\n".join(
f"Turn {m.turn_id} [{m.role.upper()}]: {m.content[:500]}"
for m in messages
)
prompt = (
f"Current task goal: {self.task_goal}\n\n"
f"Conversation turns to score:\n\n{turns_text}"
)
response = await self.scorer.ainvoke([
SystemMessage(content=SCORER_SYSTEM),
HumanMessage(content=prompt),
])
try:
return json.loads(response.content)
except (json.JSONDecodeError, ValueError):
return [{"turn_id": m.turn_id, "priority": "medium", "reason": "parse error"} for m in messages]
async def compress_message(self, msg: ManagedMessage) -> str:
"""Compress a single low-priority message, retaining the original for re-expansion."""
prompt = (
f"Compress this conversation turn to its minimum essential content.\n"
f"Preserve: all code identifiers, numbers, error messages, file names, and decisions.\n"
f"Remove: prose explanations, pleasantries, verbose context already captured elsewhere.\n"
f"Output only the compressed content, no preamble.\n\n"
f"Turn [{msg.role.upper()}]: {msg.content}"
)
response = await self.compressor.ainvoke([HumanMessage(content=prompt)])
return response.content.strip()
async def optimize(self) -> dict:
"""
Main optimization loop. If context exceeds budget:
1. Score all uncompressed messages by importance against the task goal.
2. Compress low/droppable priority messages first.
3. Repeat until within budget or only critical/high messages remain.
Returns:
Stats dict with before/after token counts and actions taken.
"""
before = self.total_tokens()
if before <= self.budget_tokens:
return {"action": "none", "before": before, "after": before}
print(f"[DynamicCtx] Optimizing: {before} / {self.budget_tokens} tokens")
uncompressed = [m for m in self.messages if not m.is_compressed]
raw_decisions = await self.score_importance(uncompressed)
priority_map = {d["turn_id"]: RetentionPriority(d["priority"]) for d in raw_decisions}
for msg in self.messages:
if msg.turn_id in priority_map:
msg.priority = priority_map[msg.turn_id]
compress_order = [
RetentionPriority.DROPPABLE,
RetentionPriority.LOW,
RetentionPriority.MEDIUM,
]
actions_taken = []
for priority_level in compress_order:
if self.total_tokens() <= self.budget_tokens:
break
candidates = [
m for m in self.messages
if m.priority == priority_level and not m.is_compressed
]
for msg in candidates:
if self.total_tokens() <= self.budget_tokens:
break
if priority_level == RetentionPriority.DROPPABLE:
original_tokens = msg.current_tokens
msg.content = f"[DROPPED - {msg.role} turn {msg.turn_id}]"
msg.current_tokens = self.count_tokens(msg.content)
msg.is_compressed = True
actions_taken.append({"turn": msg.turn_id, "action": "dropped", "saved": original_tokens - msg.current_tokens})
else:
compressed = await self.compress_message(msg)
original_tokens = msg.current_tokens
msg.compressed_version = msg.content
msg.content = compressed
msg.current_tokens = self.count_tokens(compressed)
msg.is_compressed = True
actions_taken.append({"turn": msg.turn_id, "action": "compressed", "priority": priority_level.value, "saved": original_tokens - msg.current_tokens})
after = self.total_tokens()
print(f"[DynamicCtx] Optimized: {before} -> {after} tokens ({len(actions_taken)} actions)")
return {"action": "optimized", "before": before, "after": after, "actions": actions_taken}
def expand_message(self, turn_id: int) -> bool:
"""
Re-expand a previously compressed message back to its original content.
Returns True if expansion was possible, False if original is unavailable.
"""
for msg in self.messages:
if msg.turn_id == turn_id and msg.compressed_version:
msg.content = msg.compressed_version
msg.current_tokens = self.count_tokens(msg.content)
msg.is_compressed = False
print(f"[DynamicCtx] Expanded turn {turn_id}: {msg.current_tokens} tokens restored")
return True
return False
def build_prompt_messages(self) -> list:
"""Build the final message list for the working LLM."""
result = []
for msg in self.messages:
if msg.role == "user":
result.append(HumanMessage(content=msg.content))
elif msg.role == "assistant":
result.append(AIMessage(content=msg.content))
else:
result.append(SystemMessage(content=f"[{msg.role.upper()}]: {msg.content}"))
return result
DynamicContextManager 根据当前任务目标对每条消息进行评分,然后先压缩低优先级的消息——保留活跃 bug 报告、已商定的代码模式和关键决策等关键上下文的原文——同时激进压缩探索性讨论和失败的尝试。方法 expand_message 让智能体可以在需要细节时恢复任何被压缩的轮次。
与前两种方法的关键区别:智能体知道当前任务是什么。当任务目标是"调试一个 422 错误"时,首次引入 422 的消息被评分为 critical。早期关于表 schema 的架构讨论被评分为 medium。探索性的偏离被评分为 low。后续的压缩是语义感知的,而非机械应用的。
4、组合所有三层
在生产系统中,你将所有三层堆叠起来:
- 每条新消息——首先运行提取式剪枝。零延迟,零成本。
- 接近预算时——触发最旧块的摘要式压缩。一次便宜的
gpt-4o-mini调用。 - 任务定义明确时——运行一次智能体驱动的评分,让它指导哪些消息被激进压缩,哪些保持原文。
这给你一个优雅的退化曲线:系统永远不会被迫进入二元的截断或不截断决策。它找到适合你的 token 预算的对话的最高保真度表示——自动地、在每一轮。
这种模式不仅适用于聊天:长智能体循环中有数百次工具调用、文档处理流水线、多会话智能体内存,以及任何 token 预算将你与完整上下文隔开的地方。
本文的所有代码示例可在 GitHub 上获取。
原文链接: Context Window Compression: Fitting More Into Every Token
汇智网翻译整理,转载请标明出处
