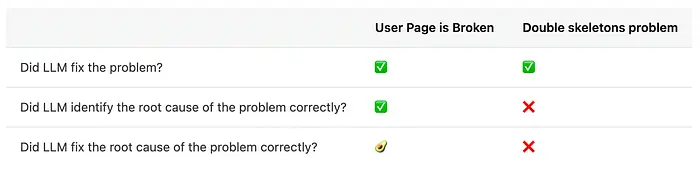
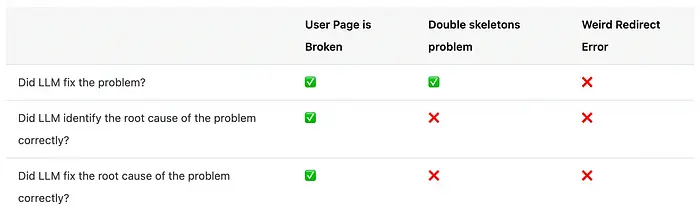
AI调试的3个调查
AI能否调试复杂的React/Next.js问题?我在三个真实bug上进行了测试,亲手调查了根本原因,并记录了结果。

AI编程/Vibe Coding 遇到问题需要帮助的,联系微信 ezpoda,免费咨询。
大家好使用AI的体验如何?喜欢还是讨厌?我在过去几个月里工作中大量使用AI,所以我想开始分享一些如何在使用AI时不失去理智(和技能)的技巧。
但是写另一篇"更好的提示工程10个技巧"文章真的太无聊了。想不想换个方式当侦探,去调查一些奇怪的事情?在这个过程中,我们会发现AI在调试和修复问题方面有多优秀。也希望能学到一两件关于React和Next.js内部原理的东西,这对于喜欢深入研究的读者来说很有意思。
为此,我实现了一个包含几个问题的应用。在本文中,我会用"修复它"的提示把这些bug扔给LLM,看看结果如何。然后我会手动调查同一个bug,展示我实际会如何修复它,并验证AI是否正确修复了bug及其根本原因。如果你想跟着一起调查,我也会分享我的调试过程和思路。
希望你的调试工具已经准备好了!
1、项目和工具设置
学习项目在GitHub上,如果你想跟着做或者尝试自己的AI工具。这是一个React/Next.js应用,有几个页面、几个API端点、用于数据获取的TanStack和用于模式验证的Zod。就像一个真实的app一样!
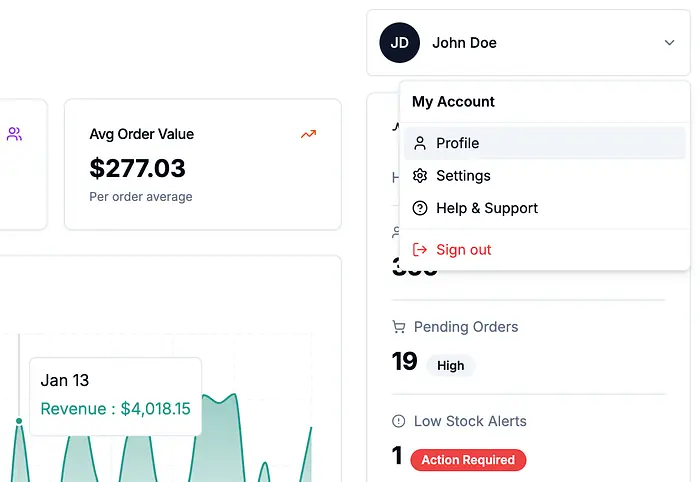
打开它,你会看到一个漂亮的仪表板页面。点击Order ID查看更详细的订单信息。点击Product ID查看产品更多信息。点击右上角的用户名会打开一个包含更多链接的下拉菜单。点击"User Profile"会进入一个显示用户所有信息的页面。
或者,准确地说,它应该是这样的。但那个路由在几个方面都是坏掉的。今天我们要修复的就是这个问题!
对于与LLM一起的调查部分,我会首先假装我对技术栈一无所知,尝试"盲目"调查。然后用我对技术栈的知识手动调查来验证修复,因为我确实有这些知识。
如果你从未使用过Next.js、TanStack和/或Zod,尝试先自己做提示和手动调查,以获得最大的乐趣。然后分享结果,我很好奇你的调查会是什么样子!
我打算使用个人Claude Pro订阅中的Opus 4.5。我觉得这对这个测试来说足够了。如果你有其他工具或模型的访问权限,也想比较一下,请也分享结果!
最后,在整个调查过程中,我想了解以下几点:
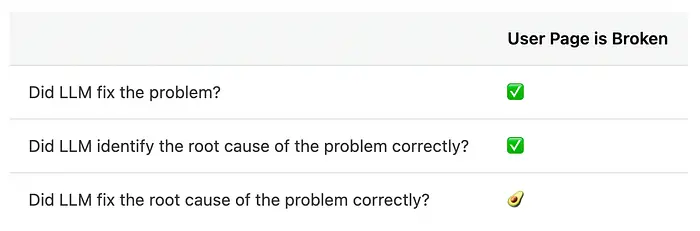
- LLM是否修复了问题?
- LLM是否正确识别了问题的根本原因?
- LLM是否正确修复了问题的根本原因?
让乐趣开始吧!
2、调查1:用户页面坏了
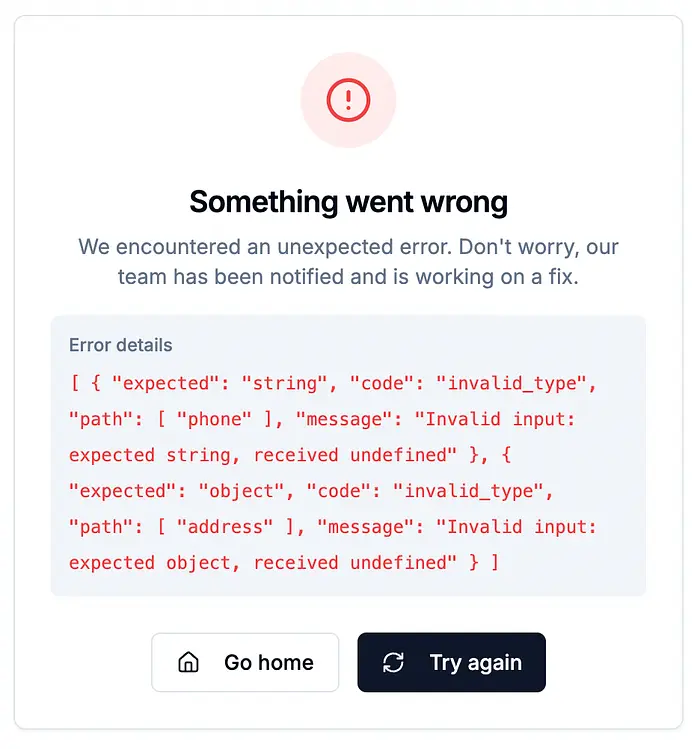
用npm run dev启动项目,通过下拉菜单或直接通过/users/1路由导航到用户Profile页面。你会看到"出了点问题"的页面,上面有便捷的错误信息:
在浏览器控制台中,你会看到更详细的错误格式:
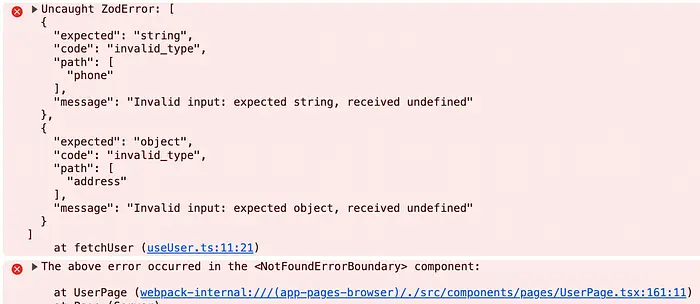
服务器日志完全干净,所以错误明显在前端。
2.1 LLM尝试
让我们把所有这些信息提供给LLM,看看它会想出什么。
LLM提示
当我导航到/users/1路由时,页面显示"出了点问题"错误。在浏览器控制台中,我看到以下错误[复制粘贴整个错误堆栈]。服务器日志是干净的。你能修复它吗?
LLM做它的工作,报告说完成了,我刷新页面——哇哈!页面不再坏了!我可以把"LLM是否修复了问题?"标记为成功。
看起来这会是一篇很短的文章😅
Opus对问题的看法是这样的:
LLM调查
问题是getUser服务返回的用户对象缺少UserSchema在src/lib/schemas.ts:238–255中要求的phone和address字段。当Zod在客户端验证API响应时,因为这些必需字段是undefined,所以抛出了错误。我给用户数据添加了缺失的字段。/users/1页面现在应该可以正常加载了。
也就是说,发送给客户端的数据缺少字段。它的修复方案是在数据文件中添加这些缺失的字段:
// 文件:src/services/user.ts
export const getUser = async () => {
const user = {
id: 1,
name: 'John Doe',
email: 'john.doe@example.com',
// LLM添加了这个缺失的字段:
phone: '+1 (555) 123-4567',
// 还有这个:
address: {
street: ' city: '123 Main Street',
San Francisco',
state: 'CA',
postalCode: '94102',
country: 'United States',
},
... // 一堆其他字段
};
if (!user) {
throw new Error('User not found');
}
return user;
};
现在让我们验证修复是否正确。
2.2 人工概览
为了理解修复是否正确,我需要真正理解问题是什么。如果我想100%确定,需要自己来理解。
所以让我们再看一下。在浏览器控制台中我看到:
Uncaught ZodError: [ { "expected": "number", ...
at fetchUser (useUser.ts:11:21)
at UserPage (webpack-internal:///(app-pages-browser)/./src/components/pages/UserPage.tsx:161:11)
在UserPage组件触发的fetchUser函数中有一些Zod相关的问题。
在UserPage.tsx中,我看到这段代码:
// 文件:src/components/pages/UserPage.tsx
const { data: user, isLoading, error } = useUser();
其中useUser是一个TanStack Query:
// 文件:src/queries/useUser.ts
export function useUser() {
return useQuery({
queryKey: ['user'],
queryFn: fetchUser,
});
}
其中fetchUser是一个获取用户信息的函数:
async function fetchUser() {
const response = await fetch('/api/user');
const data = await response.json();
// 用Zod验证响应
return UserSchema.parse(data);
}
它确实使用Zod来解析和验证来自REST端点的数据。如果你从未使用过Zod,它的目的就是:根据模式解析和验证原始数据。如果数据不正确,就抛出错误。
这正是我们案例中发生的事情:UserSchema失败了。所以来自/api/user的data有问题。在网络面板中,我可以看到端点及其输出:
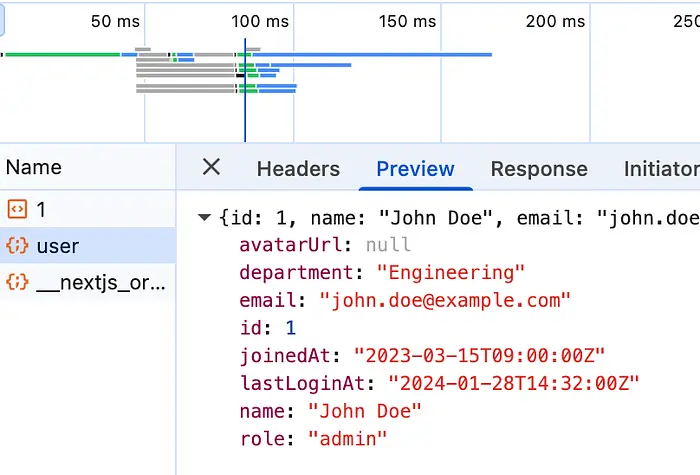
端点工作得很好,这从干净的后端日志可以证实。
唯一的解释是,返回的数据虽然看起来很好,但不满足我们的模式。如果我实际读取浏览器控制台中的错误输出:
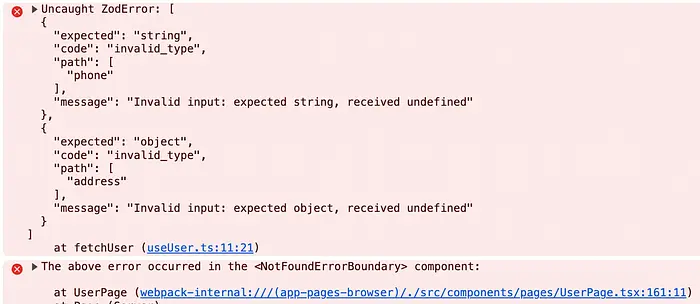
我会确切地看到哪些字段违反了模式以及如何违反:phone字段预期是string但收到undefined。address字段预期是object但收到undefined。
这是模式:
export const UserSchema = z.object({
... // 其他字段
phone: z.string(),
address: z.object({
street: z.string(),
city: z.string(),
state: z.string(),
postalCode: z.string(),
country: z.string(),
}),
... // 其余字段
});
确实,phone和address预期是存在的,否则它们会是.optional()。
这正是LLM告诉我的!多么聪明的机器人🤖。我也可以把"它是否识别了根本原因"部分标记为成功:
现在说修复。
有两种修复方法。我们要么需要确保数据始终存在,这正是LLM通过向mock添加phone和address数据所做的。
或者我们可以使这些字段的模式可选,像这样:
export const UserSchema = z.object({
... // 其他字段
phone: z.string().optional(),
address: z.object({
... // 相同的字段
}).optional(),
... // 其余字段
});
哪个修复是正确的?
嗯,实际上这取决于上下文。如果它是单元测试的mock,那么LLM修复mock可能是正确的。通过放松模式来让单元测试通过是测试工作方式的反面。虽然这也取决于测试。
在我们的案例中,我们的mock明显是作为来自后端的真实数据的替代品,后端可能是下一步实现的。在这样的真实应用中,phone和address字段作为通用User profile的必需字段是非常、非常不可能的。
所以这里的"正确"修复是放松模式:使这些字段可选或可空(取决于后端和仓库中的数据约定)。
有趣的是,在有真实后端的"真实"应用中,LLM会立即放松模式:它倾向于松散地引入可选和any作为所有问题的默认解决方案。我使用mock的事实把它搞糊涂了。
当我撤销LLM的修复,使模式中的字段可选,并刷新页面,体验又坏了。
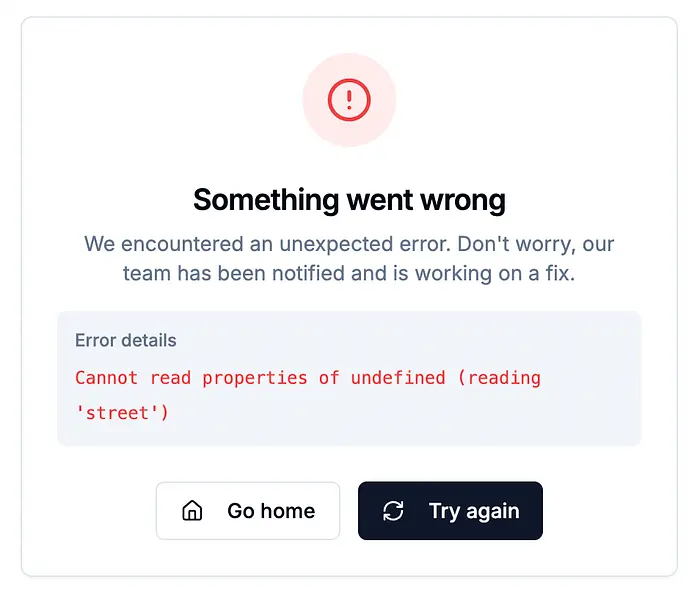
控制台显示同样的东西:
installHook.js:1 TypeError: Cannot read properties of undefined (reading 'street')
at UserPage (UserPage.tsx:177:58)
... // 其余错误
考虑到我们刚刚放松了模式,这里会发生什么应该很明显:我们试图访问现在可选的address值的street属性。我们只需要条件性地渲染这些字段:
user.address && <div ... >// 一堆渲染地址的东西
LLM实际上几乎可以零提示修复这个,干織净。
但考虑到它没有修复原始根本原因,我给它半分而不是满分。
3、调查2:双加载器问题
我们修复了最明显的bug,但这个页面上还有更多需要调查。
加载根页面/,刷新以清除所有缓存,将网络节流到至少"快速4G",然后通过右上角的下拉菜单导航到Profile页面。网速越慢,问题越明显:页面加载时会出现两个不同的加载"骨架"。
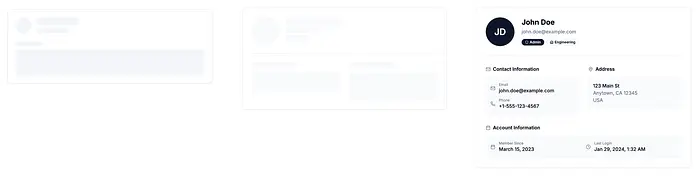
但如果你只是刷新User页面,无论网络设置如何,都只会显示第二个骨架。
这太奇怪了。日志中什么都没有🤔让我们看看LLM是否能解决这个问题。
3.1 LLM尝试
让我们把问题描述中正在发生的情况准确提供给LLM。
LLM提示: 当我在根页面上并导航到User页面时,我看到两个不同的加载骨架出现。然而,当我只是刷新User页面时,我只看到一个。为什么会这样以及如何修复?
这变得有趣了。在之前的调查中,Claude基本上只是向mock添加数据。
在这种情况下,每次我尝试这个确切的提示时,它都会想出不同的根本原因和不同的修复方案。
有时,它认为根本原因是Next.js首先显示来自app文件夹的根级loading.tsx,然后是来自app/users/[id]文件夹的路由级loading.tsx文件。
有时,它认为Next.js首先显示来自app/users/[id]文件夹的路由级loading.tsx文件,然后是UserPage.tsx内的<UserPageSkeleton />组件。
对于解决方案,它有时建议删除app/users/[id]文件夹内的loading.tsx。有时,它将根loading.tsx连同page.tsx从app文件夹移动到app/(dashboard)文件夹。
不过这些都不起作用。
当被提示时,它有时会说解决方案是在服务器上获取数据,并将应用重构为使用useSuspenseQuery而不是useQuery。
这实际上有效。
有时它会立即提出useSuspenseQuery解决方案,但解释各有不同。
大多数时候,它会说刷新时不会发生双加载是因为User页面是服务器渲染的,所以那里的loading.tsx不会被触发。
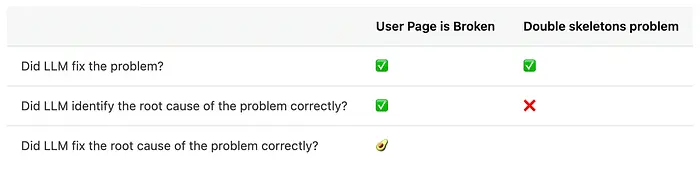
所以我会给它一个✅用于修复问题,即使不是第一次尝试。并给它一个❌用于找到真正的根本原因,因为它显然没有:这里有太多矛盾的根本原因了。
让我们手动调查上述哪个实际上是真正的根本原因,以及useSuspenseQuery是否是正确的修复。
顺便说一下,如果你尝试自己的提示,在某处保存LLM关于正在发生什么的详细解释。这样你就可以将那些与手动调查和真正的根本原因进行比较。
3.2 人工概览
所以,首先,让我们找出在导航过程中实际上显示哪些加载状态。正如LLM正确识别的,我们至少有三个:
app文件夹内的根级loading.tsxapp/users/[id]文件夹内的路由级loading.tsx- 客户端骨架,形式为
<UserPageSkeleton />,当UserPage.tsx文件内的isLoading为true时条件渲染
它们看起来相似,但实现方式不同,所以从视觉上很难识别哪个是哪个。在这种情况下,我通常使用老派的"红边框"方法😅任何在Tailwind之前调试过CSS问题的人都知道这个方法。基本上,如果我给根级骨架添加红色边框,给路由级添加绿色,给客户端添加黑色,我就会立即看到哪个跟在哪个后面。
在这种情况下,是绿色然后黑色。我们看到路由级loading.tsx骨架的闪现,然后是客户端的<UserPageSkeleton />。根级骨架不在画面中,Claude在那个部分错了。
第二个问题——为什么刷新页面时只显示客户端骨架?
Claude认为这是因为这个页面是服务器渲染的,所以loading.tsx不会被触发。
这个也不是真的😉实际上,这个模式在page.tsx文件中的页面级Server Component周围创建了一个Suspense边界。它与服务器渲染无关——无论你是否使用Server Components,Next.js中的一切都是服务器渲染的。
当创建这个Suspense边界时,Next.js会渲染loading.tsx的内容,直到异步page.tsx的promise被解决,然后将其内容交换。我们看不到"绿色"加载的唯一原因是因为我们在page.tsx中没有任何异步操作。所以没有什么要等待的,promise几乎立即被解决。
尝试添加这样的延迟,"绿色"加载将如预期显示:
const delay = (ms) => new Promise((resolve) => setTimeout(resolve, ms));
export default async function Page({ params }) {
const { id } = await params;
await delay(10000); // 模拟一些异步操作
return <UserPage userId={id} />;
}
如果Server Components和Server Rendering之间的区别让你的脑袋爆炸,别担心,这经常发生。这些主题非常复杂和令人困惑。如果你想要更详细的阅读,我有几篇非常详细的文章可能会有帮助:React开发者的SSR深度探讨和React Server Components:它们真的能提高性能吗?
同时,这里有第三个问题:如果promise解决得如此之快以至于我们在刷新时看不到"绿色"加载,为什么从仪表板导航时我们看到它?🤔
弄清楚这个问题最简单的方法是记录导航的性能配置文件。首先,用npm run build构建项目,然后用npm run start启动它。始终在生产构建上记录性能,除非有必要看dev的某些东西。
然后,在Chrome DevTools中,打开Performance选项卡,点击左上角的"Record"按钮,然后通过Profile下拉菜单中的链接导航到User页面。记录应该是这样的:
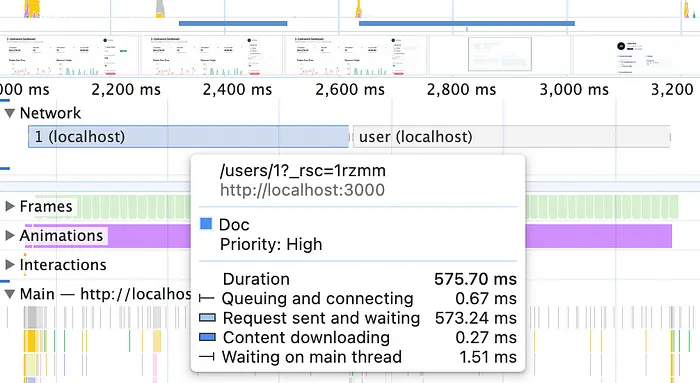
如果你悬停在截图区域,你会看到在蓝色1 (localhost)条之前,显示的页面是仪表板。当蓝色条存在时,我们看到"绿色"路由加载。当它结束,灰色的user (localhost)条开始时,"黑色"客户端骨架是可见的。
悬停在这些条上会给你关于是什么的信息。蓝色条显示浏览器正在下载User页面的RSC有效载荷,灰色条显示对/api/userAPI端点的请求。那个返回用户数据。
这个RSC有效载荷是Page server component生成的布局,React需要它来构造页面的实际HTML。当我们直接访问该页面(通过刷新)时,该布局与第一个HTML响应一起返回。当我们通过SPA转换(通过Link导航)访问该页面时,该布局作为自己的文件通过网络下载。因此,在节流的网络上,需要一些时间,Suspense边界启动,我们总是看到"绿色"加载骨架。
这实际上提出了另一个问题:为什么这里没有预取?我以为Next.js以激进缓存和默认预取所有东西而闻名。是什么让这个用例不同?🤔
搜索文档给出了一些答案:预取只在动态路由上有部分工作。动态路由是动态生成的路由,即我们路径中的[id]部分。不太清楚"部分"在这种情况下是什么意思,但我的猜测是它不包括页面的RSC。否则,它已经被预取,我们就不会看到"绿色"加载骨架了。
为了验证这个理论,我需要在导航到Page的Link组件上强制预取:
// 文件:src/components/dashboard/UserProfileDropdown.tsx
<Link href={`/users/${user.id}`} prefetch={true}>
<User />
Profile
</Link>
如果我构建npm run build,再次启动项目npm run start,并从仪表板导航到User页面,"绿色"加载状态将消失。只有"黑色"客户端加载在那里。预取有效!
然而,这不是正确的修复。你不会想手动给每个Link组件添加预取。这只是一种测试和验证我们对应用中数据获取和预取的心理模型的方法。
这个心理模型最重要的是,"绿色"路由级加载,即通过loading.tsx实现的加载,会一直显示,直到该路由上的Page组件保持挂起状态。
使用useSuspenseQuery而不是useQuery似乎正是做这件事——让组件"挂起"直到查询被解决。这就是为什么Claude提出的修复有效。
然而,这是正确的修复吗?
如果你在文档中阅读更多关于useSuspenseQuery的内容,你会看到:
"虽然我们不 necessarily推荐它,但可以替换这个[useQuery]为useSuspenseQuery,只要你始终预取所有查询。"然后这个:"如果你在使用useSuspenseQuery时忘记预取一个查询,后果将取决于你使用的框架。在某些情况下[...],你会得到标记水合不匹配,因为服务器和客户端尝试渲染不同的东西。"
基本上,这可能很糟糕,取决于框架。实际上,如果你应用Claude建议的useSuspenseQuery修复,当你刷新User页面时,你会在Chrome控制台中看到错误。
所以我会给Claude关于这个问题的最终❌:它的修复在后面引入了另一个问题。
那么,真正的修复是什么?
这里有三件事可以做,取决于我们愿意在重构上投入的时间。
最简单、最简单、最"hack"的修复是重用"黑色"骨架而不是"绿色"(反之亦然)。在这种情况下,我们仍然会按顺序显示两个骨架,但因为它们看起来相同,用户不会注意到。
我们也可以重构User页面,只在骨架下隐藏动态数据。所以不是显示覆盖整个页面的加载骨架,在"绿色"骨架之后,我们会几乎立即显示一些文本,给用户页面正在逐步加载的印象。
或者,最先进且可能是最"正确"的解决方案(考虑到我们已经使用Next.js)是在Server Component中获取用户数据。因此完全消除对"黑色"客户端加载器的需求。
如果你想练习更多AI技能,在看下面的解决方案之前,尝试用提示实现那个。
Server Components数据获取的解决方案是这样的。
我们已经使用TanStack获取数据,重构整个仓库是不明智的。然而,TanStack是一个可以在服务器上水合的先进库。也包括来自Next.js App router。
仓库已经正确设置使其工作;我们只需要使用它。
// 文件:src/app/users/[id]/page.tsx
export default async function Page({ params }) {
const { id } = await params;
// 创建TanStack查询客户端
const queryClient = new QueryClient();
// 触发并等待预取
await queryClient.prefetchQuery({
queryKey: ['user'],
queryFn: async () => {
// 复制粘贴API端点做的相同逻辑
await new Promise((resolve) => setTimeout(resolve, DELAYS.USER));
const user = await getUser();
// 返回用户数据
return user;
},
});
return (
<!-- 将脱水状态传递给HydrationBoundary组件 -->
<HydrationBoundary state={dehydrate(queryClient)}>
<UserPage userId={id} />
</HydrationBoundary>
);
}
只有三个步骤:初始化queryClient,触发并等待预取(立即接收数据),并将客户端传递给<HydrationBoundary />组件。
结果,无论是从仪表板导航还是刷新页面,你都应该只看到"绿色"加载状态。而且如果你在Chrome中打开网络面板,你会看到对用户信息的客户端请求不再存在。
4、调查3:奇怪的重定向错误
最后一个调查。
导航到/usersURL:你 会看到错误页面快速闪烁,然后它会重定向到/users/1。重定向是预期的。意图是重定向非管理员:他们应该能够看到自己的信息,但不应该有访问管理用户的权限。
然而,错误不是预期的,需要消失。在浏览器的控制台中,我看到相同的错误:Rendered more hooks than during the previous render.
让我们再试一次LLM!
4.1 LLM尝试
同样的提示:解释发生了什么以及我在控制台中看到什么。
LLM提示
当我导航到/users页面时,我看到"出了点问题"页面,在控制台中我看到以下错误:[错误代码]。调查为什么错误发生以及如何修复。
这个彻底失败了。
LLM只是在兜圈子。在调查过程中,它非常自信地尝试用以下方式修复问题:
- 将重定向移到
useEffect(不,谢谢,你知道这会对性能做什么吗?)。 - 将重定向移到
next.config.ts文件(不会起作用,我很快就需要访问数据库)。 - 将重定向移到
proxy.ts/middleware.ts(不可维护,我很快就会需要一堆带有大量逻辑的重定向,而且我不想在那里重新实现路由)。 - 搞乱
QueryProvider并将其移到状态(没有修复它)。 - 说重定向应该被返回(不)。
- 说Next.js版本过时了(没有修复它)。
- 在带有重定向的
page.tsx旁边添加loading.tsx(不,没有修复它)。
对于每一个,它都有一个非常可信和详细的解释为什么那个解决方案应该修复问题。
所以这个真的是一个需要适当调查的头痛问题。
4.2 人工概览
在大多数修复尝试中,LLM会提到抛出错误是redirect应该有的行为方式。这很有趣,值得一些传统的谷歌和文档阅读。
实际上,在Next.js文档中提到的是,redirect抛出错误,所以当使用try/catch语句时应该在**try块之外调用。*所以我想象在根部某处,Next.js捕获那个错误,将其与"常规"错误分开,然后执行实际的重定向。
虽然这对这个问题有点误导:我在UI和控制台中看到的错误是关于hooks的,不是重定向。
更多的谷歌搜索发现了Next.js仓库中的这个GitHub问题:"使用App Router时渲染的hooks比上一次渲染多"。正是我们的用例。
阅读评论后,其中一个提到他们有相同的问题,通过添加loading.tsx修复。这可能是为什么LLM一半时间试图在页面旁边添加加载状态来修复它。不幸的是,在我们的案例中,它没有修复它。
然后,稍低一点有另一个评论,解释我们只需要正确使用重定向。仔细检查代码表明我们这边一切正常。
另一个评论提到,除了完全删除loading.tsx之外,他们什么都没用。我Wonder如果我这样做会发生什么?
它实际上修复了错误!🤯虽然删除所有loading.tsx可能不是一个好的解决方案,用户将无法在没有它的情况下快速导航页面。
继续阅读那个GitHub线程,但就是这样。没有更多建议,另一个死胡同。😭
好的,让我们从另一端处理它。如果看到错误是正常行为,互联网早就充满了抱怨,问题早就被修复了。同样,如果错误非常常见和明显。LLM早就修复了。
所以,我们应用的代码中有一些问题,而且相当独特。
现在是时候做老派无聊的调试了,也就是"一个一个杀掉东西直到错误消失"。基本上,我需要开始从layout/page/loading结构中撕掉所有组件和一切,只留下最基本的Next.js。
从User页面删除所有内容没有帮助。错误仍然存在。与从app/users/layout.tsx中删除除children之外的所有内容相同。但从根布局中删除<SendAnalyticsData />组件终于移动了针!🎉错误消失了!
恢复根中除<SendAnalyticsData />之外的所有内容,只是为了确保我们已经隔离了根本原因,并且...错误又回来了🤦🏼♀️幸运的是,我们现在是专业的调试者,所以应该相对容易找出原因:UserLayout组件在第二个layout.tsx文件中也有一个<SendAnalyticsData />组件。
在现实生活中,我花了好几天调试那东西,实际上是一个不同组件和函数调用的非常复杂的组合😅
好的,所以<SendAnalyticsData />组件内部有问题。该组件本身相当原始:
export function SendAnalyticsData({ value }: { value: string }) {
useEffect(() => {
sendAnalyticsData(value);
}, [value]);
return <></>;
}
只是一个调用函数的小useEffect。但那个函数是...一个Server Action:
'use server';
export async function sendAnalyticsData(name: string) {
console.log('analytics data sent', name);
}
这不可能是真的?完全合法的方式调用一个Action造成这么多麻烦?🤔
容易验证。我只需要恢复一切到原始形式并注释掉那个Action。
错误就消失了!🤯现在我知道要谷歌什么了(即"Suspense, Next.js, Actions, Redirect, Error"的组合),我可以找到关于正是这个问题的一些提及。终于,真正的根本原因!看起来是服务器端重定向和Suspense中进行的Action的组合让Next.js感到困惑。
到底哪里被混淆了其实现在不重要。虽然如果你谷歌得足够多,你会发现线索。但我会留给你作为家庭作业。
因为这里的解决方案很清楚:我只需要删除这个Action或将其重构为简单的REST端点,错误就修复了。又是另一个不使用Action的理由。如果你错过了之前的理由,这里有另一个深度探讨:你能用React Server Actions获取数据吗?
但是对于这个调查,是时候收尾了。
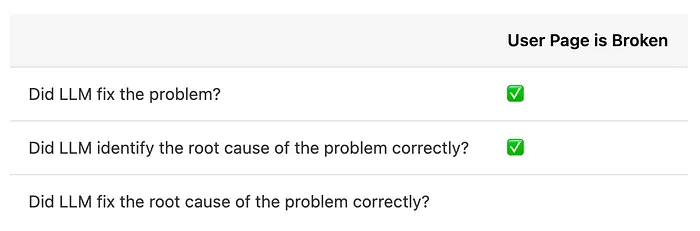
5、调查总结
那么, verdict是什么?AI能替代经验丰富的开发者进行调试吗?
不,当然不是。AI非常擅长模式识别,而且它可以非常、非常有帮助。它会在标准的东西上做得非常好:模式验证失误、忘记的空检查、常见的运行时错误,你已经亲眼看到了。老实说,我这些天的调试几乎总是从LLM开始。使用 literally 上面的提示:"这是发生了什么,这是日志,修复它"。一半的时间,它能做到这一点。
但即使修复有效,我总是逐步重新追踪它,并确保它是真正的根本原因。然而,如果修复不起作用,我几乎从不与LLM迭代,除了让它在仓库中找些东西给你。正如你所看到的,在这种情况下,它的回答一半会是非常自信的幻觉。
当问题需要真正理解系统为什么以这种方式行为,或者它应该如何行为,特别是从未来或用户的角度来看,AI就会摔倒。我想它有屁股。
这里的技能不是知道如何更好地提示。是知道什么时候停止提示,开始思考。
同时,这是调查的结果。
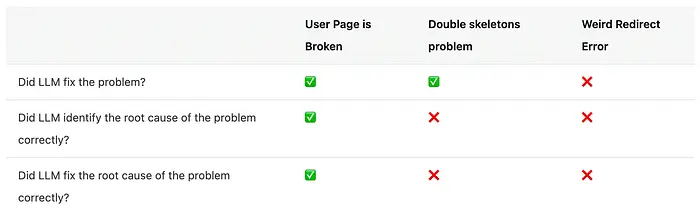
如果你能不用看我的解释就能调试所有这些问题,你可能没问题。如果你偷看了并学到了一些新东西,现在能够使用它,你也很好。
当AI在第一步就获得✅在每个步骤时,就会是担心的时候😅
原文链接: Debugging with AI: Can It Replace an Experienced Developer?汇智网翻译整理,版权归原作者所有,转载需注明出处
