真正落地的5个AI智能体案例
我一直在寻找在编程领域之外运作的新型AI智能体和应用。本文整理的几个案例,引人注目的不是这些系统有多么神奇,而是它们出现在了那些速度、判断力和对正确数据的获取至关重要的日常业务工作流中。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我一直在寻找在编程领域之外运作的新型AI智能体和应用。所谓智能体,我指的是一个能够设定目标、使用工具、保持上下文,并通过多个步骤来工作的系统,而不是简单地回答提示词。
通过回顾我在最近的AI Agent Conference上的笔记,我从与这些系统的构建者以及会议上的朋友们的交流中,整理出了几个突出的案例。引人注目的不是这些系统有多么神奇,而是它们出现在了那些速度、判断力和对正确数据的获取至关重要的日常业务工作流中。
1、当市场平台开始代劳
Upwork的 Uma Recruiter 从一个常见的问题出发:招聘不仅仅是搜索。客户可能会写出一个不完整的职位描述,遗漏重要的约束条件,或者未能将必需技能与加分项区分开来。Uma Recruiter将这些杂乱的输入转化为结构化的招聘任务,然后搜索人才市场,并从过往工作、作品集深度、可用性、先前的客户关系和Job Success Score等多个维度评估候选人。接着它会邀请有潜力的候选人并对收到的提案进行排名。Upwork正在将职位描述视为多步招聘流程的起点,而不是一次性查询。早期结果表明这不仅仅是一个演示:Upwork表示Uma Recruiter可以在六小时内生成候选人名单,初步测试显示使用该名单的录用率提高了30%,招聘时间缩短了11%,2025年11月至2026年3月期间七天内完成的工作数量增长了10%。
DoorDash的商户工具更像是一套直接嵌入商户运营的AI驱动工作流组合,而不是单一的招聘类智能体。其核心理念是消除独立餐厅通常没有时间或人手处理的设置和增长任务。其AI驱动的入驻流程从商户现有的网络形象中提取信息,包括照片、营业时间和菜单项,这样商户只需审核和编辑,而不必从头开始。DoorDash表示这帮助商户的上线速度提升了超过35%。该套件还包括AI照片工具,可以在保留底层菜品的同时对食物图片进行精修或重新摆盘,用于直接点餐的AI生成品牌网站,以及用于邮件内容和排期的AI辅助营销活动。已有数百万张照片得到了增强,AI驱动的网站的平均订单转化率接近10%,商户报告在入驻和营销方面的显著节省。
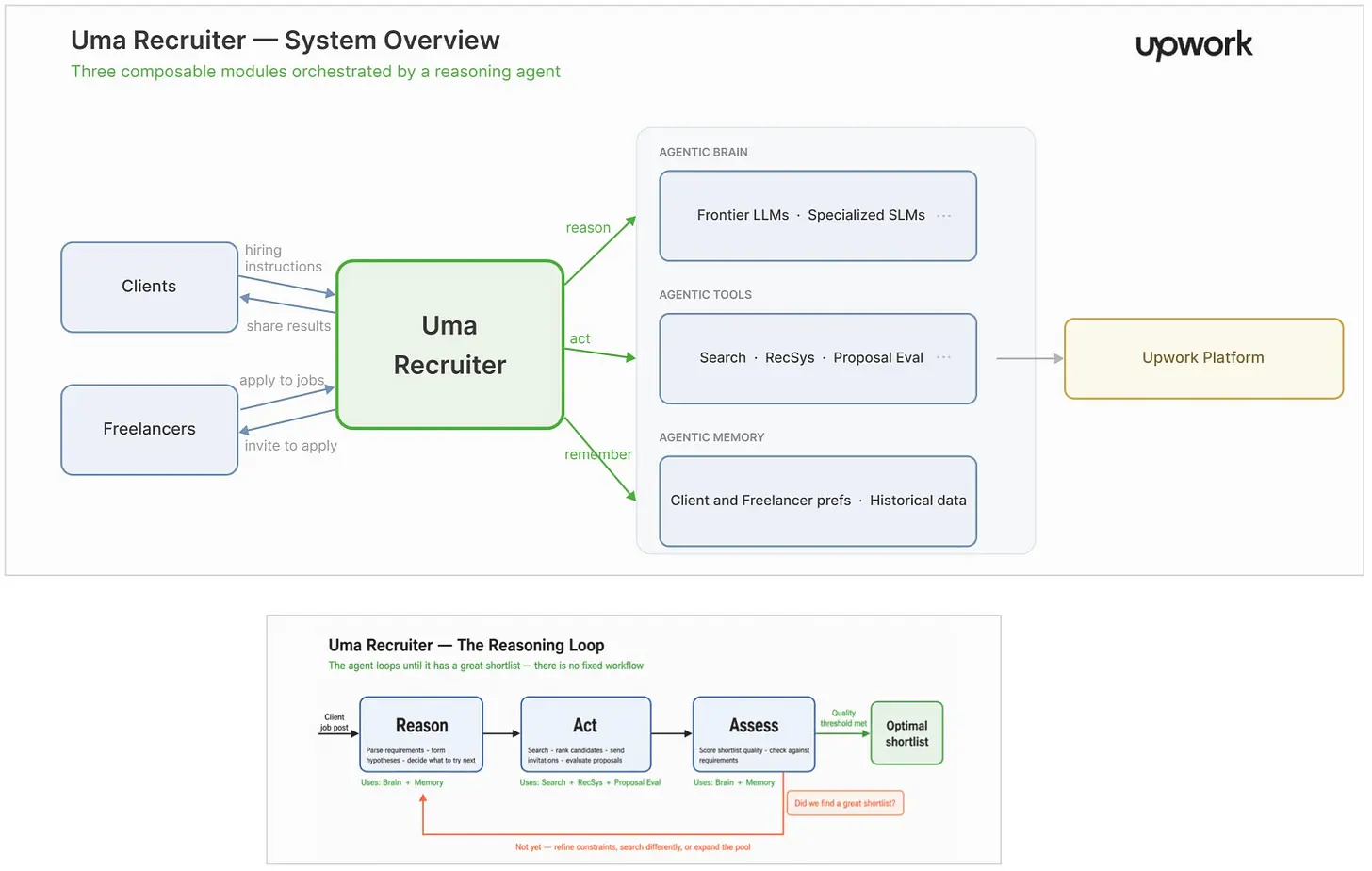
共同点是,两家公司都在用AI使他们的平台更易于使用,而不是取代市场平台本身。Uma Recruiter更加明确地具有智能体特征:它拥有推理核心、专用工具、记忆,以及一个迭代式的计划-行动-评估循环,运行直到生成高质量的候选人名单。DoorDash则更加嵌入和任务特定,表现为在已知的生命周期节点减少商户摩擦的产品功能。对于构建者来说,这种区别很重要。Upwork自动化的是一个需要大量判断的工作流,系统必须在候选人和结果之间进行推理。DoorDash自动化的是设置、内容和营销工作,其中可用性、护栏和与商户门户的紧密集成可能比一个明显自主的智能体更为重要。
2、通往企业智能体的两条路径
Meta的AI Second Brain解决了一个大多数知识工作者立刻就能认识到的问题:完成工作所需的上下文分散在文档、会议、任务、代码审查和内部讨论中。与其每次开会都从零开始,该系统为AI智能体提供了一个围绕PARA方法组织的持久工作空间——一个用于项目(Projects)、领域(Areas)、资源(Resources)和档案(Archives)的轻量级结构,告诉智能体你正在做什么、需要按需加载什么,以及将会议笔记等新信息路由到哪里。智能体通过经过认证的MCP服务器连接到内部工具,获得了对内部系统的有范围、有权限的访问,以及命令行界面。采用数据令人瞩目:大约三个月内超过63,000次安装,约10,000名日活跃用户,以及数千个用户用纯markdown编写的技能。这种内部吸引力通常意味着工具解决了一个真实的问题。
EY的智能体AI针对的是一种非常不同的知识工作:审计和鉴证。该公司正在将一个多智能体框架直接嵌入EY Canvas——其基于Microsoft Azure、Microsoft Foundry和Microsoft Fabric构建的全球鉴证平台。该系统旨在帮助审计团队协调复杂任务、调取最新的会计和审计指引、优化风险评估并减少管理开销,同时明确保持人类判断在决策回路中。其规模是制度性的而非病毒式传播:130,000名鉴证专业人员,160,000个审计项目,覆盖超过150个国家,并规划到2028年支持端到端的审计活动。
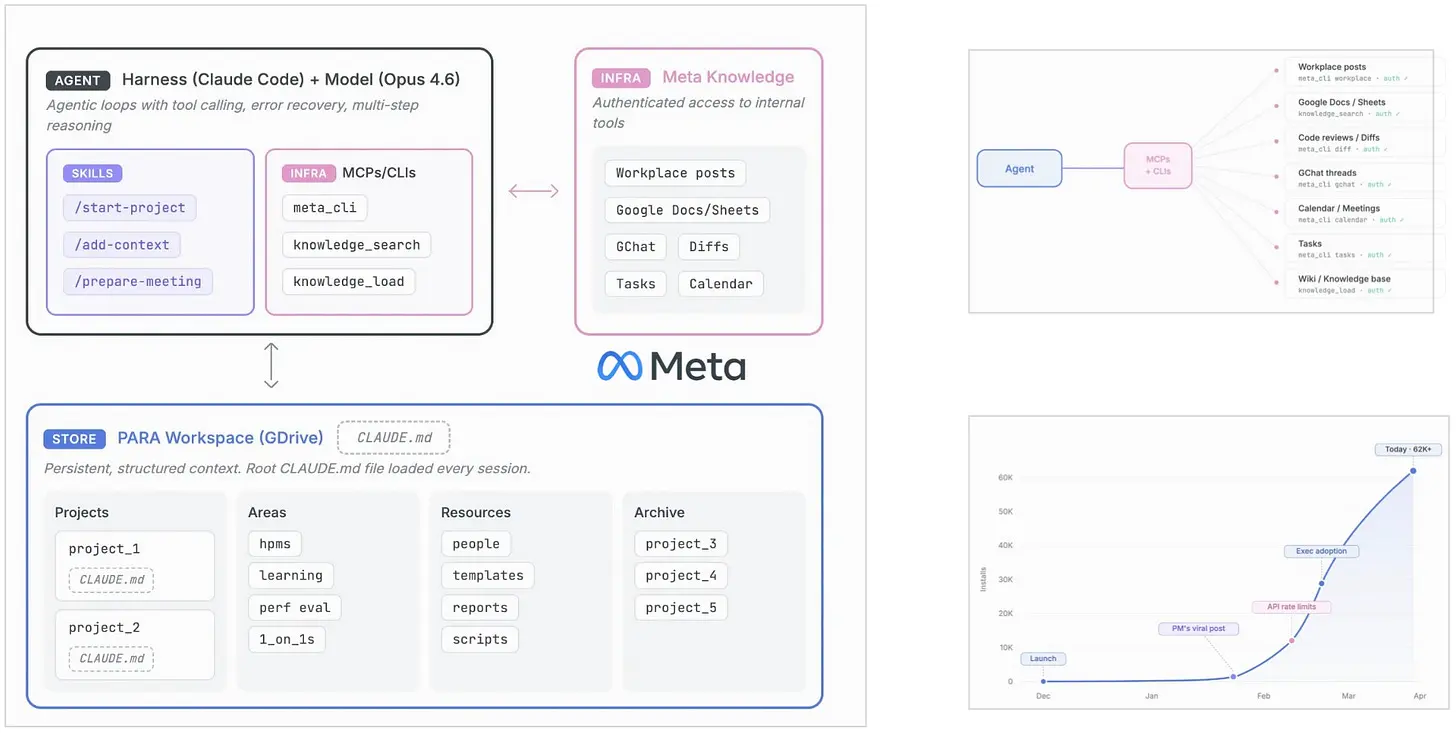
共同的教训是,内部智能体需要的远不止一个强大的底层模型。它们需要访问控制、结构化的上下文、工作流集成,以及AI辅助与人类决策之间的明确边界。这两个案例的分歧在于理念。Meta的系统是自下而上生长的:用户编写自己的技能,团队扩展工作流,采用率之所以扩散,是因为入门门槛低且系统可组合。EY的部署在设计上是自上而下的,嵌入在一个受监管的专业平台中,其中治理、质量控制和培训与生产力提升同样重要。有些智能体之所以能扩散,是因为人们可以适应它们。而另一些智能体之所以能赢得信任,恰恰是因为它们不能被自由修改。
3、当数据成为护城河
RealAI是一个面向投资者、多户型住宅专业人士、房产经纪人、购房者和租客的AI房地产分析师。其卖点是,曾经需要专业团队或昂贵的机构工具才能完成的房产和市场分析,现在可以通过对话完成。RealAI可以比较市场、评估房产、建模回报,并调取涵盖全美住宅物业的租金、销售历史、人口统计、家庭财务、迁移趋势和市场动态等数据。Fundrise声称曾经需要数天的承做工作现在可以在几秒钟内完成。纽约世界贸易中心的业主开发商表示,曾经需要数天才能完成的复杂分析现在可以在几分钟内完成。RealAI的定价对历史上无法负担此类服务的个人投资者和较小公司来说是可负担的。
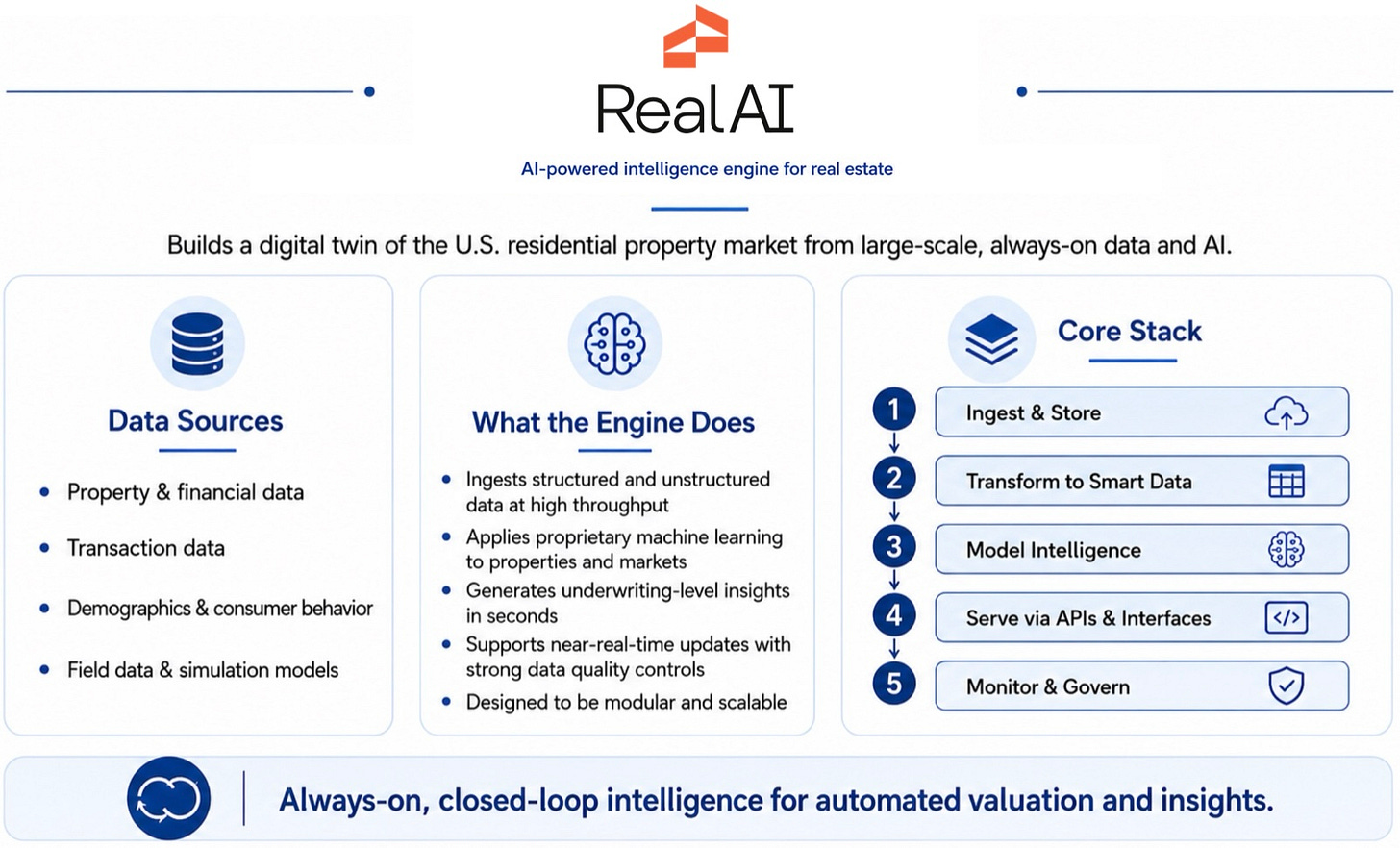
RealAI最重要的部分可能不是聊天界面或智能体框架(即将任务路由到正确工具和数据源的层),而是其底层数据。Fundrise描述了一个经过数万小时内部团队经验训练的系统,以及一个覆盖全国每一处住宅物业的约3.5万亿个数据点的数据库,数据来源于公共记录和私人数据库,并实时更新。界面可以重新设计,编排层也可以替换。但是以如此规模进行领域特定数据的组装、清理、连接和持续刷新才是真正困难的部分。在许多应用型智能体系统中,持久优势存在于模型之下——在数据中。
4、什么让智能体真正落地
这些案例让我对智能体作为一个类别的兴趣减弱了,反而更加关注使它们有用的条件。模式不仅仅是"给模型配备工具"。更好的案例嵌入在真实的工作循环中,利用领域特定的数据,在判断力重要的地方保留人类控制,并且有足够的记忆来跨步骤携带上下文,而不是在每次会话中都倾倒所有内容。它们还需要不那么光鲜的机制:访问控制、工具失败时的重试、解释智能体为何采取行动的日志、与业务成果挂钩的评估,以及成本管控,使得每一步都不需要最昂贵的模型。这才是许多智能体项目将成功或失败的地方,而不是在演示中。
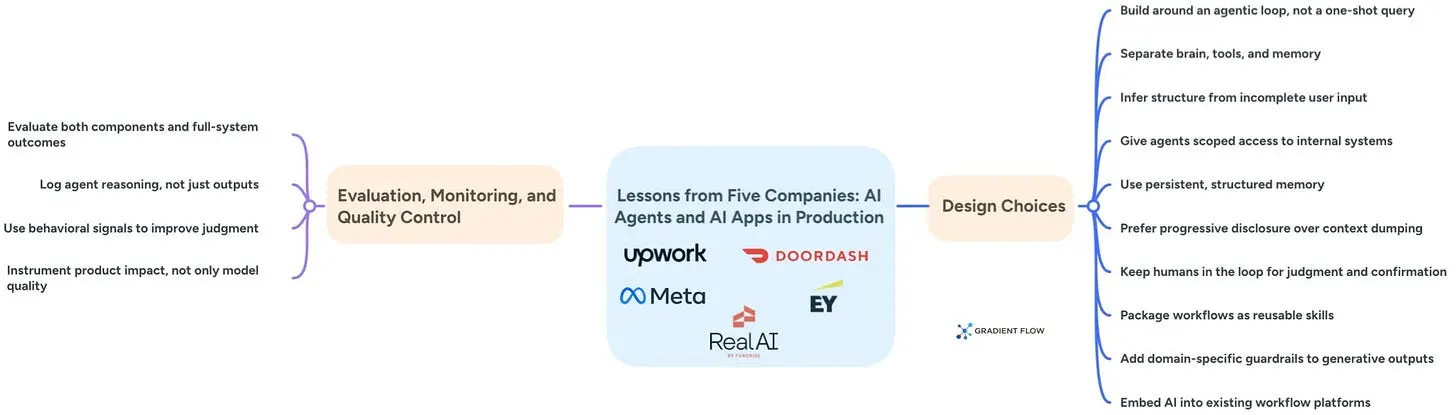
劳动力问题也潜伏在大多数这些部署的表面之下,即使没有被公开提及。Fundrise的Ben Miller对劳动力后果的表述异常直白。他说AI将在商业地产领域造成工作岗位的流失,虽然Fundrise尚未裁员,但公司已经放缓了招聘速度。这比大多数公司愿意公开提供的表述更加坦率,值得认真对待。这里描述的系统并没有替代高风险时刻的人类判断,但它们确实压缩了围绕这些时刻的大量工作。对于任何正在构建或购买智能体的人来说,价值是真实的,但组织后果也是如此。
原文链接:Beyond the Demo: What Real AI Agents Actually Do at Work
汇智网翻译整理,转载请标明出处
