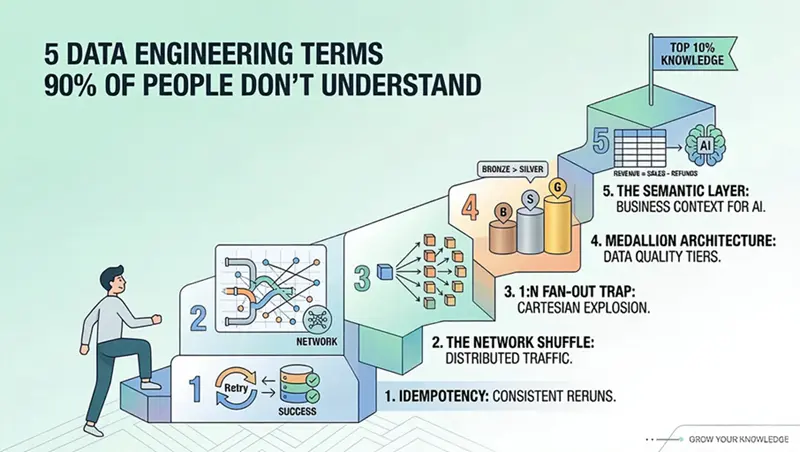
90%人不懂的5个数据工程术语
掌握数据架构的核心物理原理,不被SaaS炒作迷惑。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
坦白说。
今天大多数谈论数据工程的人,要么听起来像是在读SaaS工具清单——Airflow、Snowflake、dbt、Kafka——要么当有人真正问他们为什么PySpark作业刚刚搞崩了集群时,他们完全不知所措。
你不必成为他们中的任何一个。
我认为有5个术语——5个核心架构概念——如果你真正理解它们(不仅仅是记住定义),你会领先于房间里几乎所有人。无论你是初级开发者、一个厌倦了管道崩溃的数据科学家,还是一个试图搞清楚为什么云账单这么高的领导者。
开始吧。
1. 幂等性(Idempotency)
你大脑中必须首先记住的是数据管道会失败。它们不断地失败。API宕机,集群内存不足,或者源数据迟到了。
那么当一个管道运行到一半失败,你必须重新运行它时会发生什么?
这就是幂等性发挥作用的地方。
一个幂等的管道是一个可以运行一次、两次或连续五十次,而数据库的最终状态将保持与只运行一次完全相同的管道。
如果你的管道只是使用INSERT命令,运行两次意味着你刚刚重复了所有数据。你的仪表板现在显示双倍的收入,CEO会恐慌。如果你的管道是幂等的,它使用MERGE(Upsert)之类的命令,或者安全地删除和替换特定分区。它查看数据库并说:"如果这行已经存在,更新它。如果不存在,插入它。"
为什么这对你很重要?
因为初级工程师构建管道时假设一切都会顺利。高级工程师构建幂等管道时知道一切都会出错。当你理解了幂等性,你不再在凌晨3点冷汗淋漓地醒来, wondering自己是否因为在Airflow DAG上点击了"重试"而损坏了生产数据库。
2. 网络洗牌(Network Shuffle)
想象你经营一个商业厨房。你有10个厨师(执行器)在他们各自的工位上切蔬菜。这快得令人难以置信。
但突然间,你让厨师们把所有切好的洋葱集中到一张桌子上,所有胡萝卜到另一张,所有芹菜到第三张。混乱随之而来。厨师们在厨房里跑来跑去,互相碰撞,端着蔬菜碗,排着队。没有人真正在切菜了;他们只是在搬食物。
这就是洗牌(Shuffle)。
在分布式计算中(如Spark或Databricks),你的数据被分割在多个工作节点上。如果你运行一个.filter()命令,节点就地处理数据。这快如闪电。但如果你运行一个.groupBy()或.join()命令,引擎就必须在网络上物理移动大量数据,将匹配的键组合在一起。
为什么这对你很重要?
洗牌是数据工程中单次最昂贵、最耗时的操作。它是你的管道需要4小时而不是4分钟的原因。
当你理解了洗牌,你不再盲目地通过向集群添加更多内存来修复慢代码。相反,你改变逻辑。你在join之前过滤数据。你广播较小的表。你优化的是数据的物理学,而不仅仅是硬件。
3. 1:N 扇出陷阱(Fan-Out Trap)
这是我个人最喜欢解释的一个,因为它是云计算预算的无声杀手。
当你使用SQL将两个表连接在一起时,你是在基于一个键匹配行。
如果表A有1000行,你将它LEFT JOIN到表B,你期望结果仍然是1000行,对吧?
并非如此,如果表B有重复项。
如果你将一个users表连接到一个purchases表,而一个用户做了5次购买,那个用户行就在你的输出中重复了5次。这就是一对多(1:N)关系。
现在,想象在一个有1亿行的表上不小心这样做,将其连接到一个有数十亿次点击的日志表。
为什么这对你很重要?
你刚刚触发了一个笛卡尔爆炸。你1亿行的表在几秒钟内就"扇出"成一个500亿行的怪物。你的Spark集群耗尽RAM,溢出到磁盘,最终崩溃,在此过程中烧掉数百美元的云计算费用。
理解扇出陷阱意味着你永远不会在未严格验证所连接表的粒度(唯一性)的情况下写一个JOIN。
4. 奖牌架构(Medallion Architecture)
这是每个人都在用但很少有人正确执行的术语。
如果你只是把应用中的原始JSON文件直接倒进一个仪表板给业务部门看,你会遇到大麻烦。数据是混乱的、嵌套的,充满错误。
奖牌架构是你如何为数据湖屋带来秩序的方法。它是一个简单的概念,将数据组织成三个质量级别:
- 青铜层: 原始的、未经过滤的数据,完全按照到达时的样子。如果源系统出故障,你总是有原始的青铜层数据可以重放。
- 白银层: 清洗过的、过滤过的和带类型的已去重和标准化数据。
- 黄金层: 业务级别的聚合。这是高度精细化的星型模式,数据已预先连接并准备好供高管查询。
为什么这对你很重要?
如果业务利益相关者抱怨一个指标不对,奖牌架构准确地告诉你如何调试它。你不需要解开一个500行的SQL查询。你检查黄金层表。如果那里的逻辑有误,你修复它。如果黄金层表没问题,你检查白银层是否有缺失数据。它将一个混乱的数据沼泽变成了一个可管理的、经过审计的供应链。
5. 语义层(Semantic Layer)
这是五个概念中最容易被误解的,尤其是现在人工智能加入了对话。
目前,每个CEO都想要一个"文本到SQL"的聊天机器人,他们可以输入:*"我们上个月的收入是多少?"*并获得即时答案。
如果你把LLM直接指向你的原始数据库,它会产生幻觉。它不知道"Revenue"是指gross_sales列还是net_arr列。它不知道需要过滤掉已退款的事务。
这就是语义层发挥作用的地方。
语义层(使用dbt等工具)是你用代码定义业务指标的地方。你写一个严格的定义,比如:"收入 = gross_sales - refunds,其中 status = 'active'。"
为什么这对你很重要?
当你有语义层时,你不会让AI猜测SQL连接。你只是让AI查询语义层。AI只需要请求"收入"指标,语义层就会将其翻译成完美无缺的、经过人工批准的SQL代码。
如果你想构建在企业中真正有效的AI代理,你不需要更好的提示工程。你需要一个语义层。
6、欢迎来到前10%
知道如何写Python脚本的人和真正理解分布式系统如何工作的人之间的差距是巨大的。
你不需要记住ProductHunt上发布的每一个新工具。但理解幂等性意味着你的管道能安全度过夜晚。理解洗牌和扇出陷阱意味着你为公司节省了数千美元的云计算费用。理解奖牌架构意味着你的数据实际上是受治理的。而理解语义层意味着你已准备好构建明天的AI基础设施。
就是这样。五个概念。真正的工程。
欢迎来到前10%。
原文链接:If You Understand These 5 Data Engineering Terms, You're Ahead of 90% of the Industry
汇智网翻译整理,转载请标明出处
