5个降低AI成本的有效技巧
在建议任何人自托管LLM之前,我会先推荐以下几项措施。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
自托管有很多好处。我不否认这一点。
但是自托管很难说是优化推理成本的解决方案。在做出自托管决定之前,还有很多事情可以做。我会逐一讲解。
我并不是说自托管在经济上是个糟糕的选择。在特定条件下它确实有优势。但总的来说,对于大多数用例,通过API消费推理服务更为明智。
几乎所有主流推理提供商(OpenAI、Anthropic、Gemini和OpenRouter)都支持我们这里讨论的大部分技术。因此,这些都是与平台无关的技术,你可以立即开始实施。
话虽如此,我们也会讨论自托管何时在经济上更有意义。
1、自托管LLM的种种弊端
如果你和大多数人一样,你可能先用OpenAI的API开发了一些东西,并为此感到自豪,直到账单出现。你可能会想测试开放模型,也许是借助OpenRouter这样的API提供商。然后你意识到,如果自己托管LLM可能更便宜。
我也经历过这个阶段。
但自托管不是免费托管;免费模型不等于免费托管。
LLM托管基础设施的成本对大多数人来说往往不合理。例如,即使在半精度下,托管一个像Gemma 4 31B这样的模型至少需要34 GB显存。这相当于两块RTX 3090/4090并行运行。一个经验法则是:模型的每10亿活跃参数需要2GB显存。
自托管不仅在初始基础设施成本上代价高昂,还使得扩展变得困难。
如果我建议某人自托管他们的LLM,那要么是出于数据隐私原因,要么是需要边缘计算。尽管自托管有成本优势,但我认为对于日常用例并不值得。
那么,你还能做什么?以下是你今天就可以应用的、经过实战检验的技巧,无论你使用哪个提供商。
2、降低推理成本的所有方法
话虽如此,在建议任何人自托管LLM之前,我会先推荐以下几项措施。其中一些技巧即使你自托管也同样适用。但在纯粹为了降低成本而决定是否自托管之前,你应该先试试这些方法。
2.1 提示缓存可降低高达90%的输入token成本
像Anthropic和OpenAI这样的提供商允许你缓存重复的提示前缀。这可以带来巨大的成本节省。
在我们开发的AI系统中,我们几乎总是会包含一个系统提示。它告诉LLM在整个会话中应该如何行事。它可能包含与输出结构相关的指令、保护AI系统安全的护栏、静态上下文等。但是系统指令从不改变。既然如此,为什么模型每次都要将其作为新信息来读取呢?
缓存重复的提示前缀,享受它带来的成本节省。
提示缓存帮助我们存储提示的前几部分,仅按需更改剩余部分。每次有新请求进来时,提供商会检查你提示的开头部分是否最近被处理过。如果是,模型就跳过处理它们。相反,它们从注意力层的KV(键值)缓存中检索。
提示缓存可以节省高达90%的输入token成本。以下是一个实际案例:
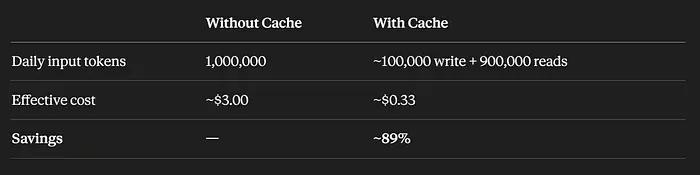
以下情况适合使用提示缓存:
- 长系统提示(指令、角色设定、规则)
- 嵌入在提示中的少样本示例
- 每次请求都包含的RAG文档
- 具有大型共享上下文的多轮代理
但每个提供商处理缓存的方式有所不同。了解这些差异将帮助你更好地影响缓存过程并获益更多。
**OpenAI**自动缓存前1024个token。它们将后续请求路由到处理过你第一个请求的同一服务器,以便重用缓存的前缀。你可以设置prompt_cache_key请求头以确保它们经常命中同一服务器。
而Anthropic略有不同。Claude模型默认不启用缓存。你需要包含cache_control请求头来启用。但Claude对缓存过程提供了更多控制。你甚至可以标记单个内容块进行缓存,只要它们在缓存token限制范围内。不过,这些限制因Claude模型而异。
提示缓存甚至在 OpenRouter等第三方提供商中也可用。
2.2 裁剪对话历史简单而有效
我付出了惨痛的代价才学到这一课。幸运的是,我只花了5美元就学到了。
我用Claude Code进行了一次vibe coding(氛围编程)。Claude Code在几分钟内创建了应用的第一个版本。那只花了1.33美元。但在我还没启动开发服务器之前,我就用完了5美元的预算。
花5美元不是问题。但以每小时5美元的速率,我一年很容易就会烧掉1万美元。
这个问题的根源在于重复使用同一个聊天线程进行调试。聊天线程中已经塞满了我的指令、AI生成的代码、内容等。
裁剪对话历史,总结较早的对话轮次,或使用更短的系统提示。
我在问Claude为什么这不行、怎么修那个等等。这些问题我完全可以在不同的聊天线程中处理。如果确实需要同一线程,我可以压缩历史记录。
即使在我们开发AI系统时,我们也使用这种技术来控制成本。
2.3 使用模型路由/级联
我们交给AI的任务并非同样困难。大多数任务只需要简单的摘要。有些需要思考,还有少数需要深度思考和更高的智能。
为什么不使用更小或更便宜的模型来处理简单查询,只将复杂的路由到更大的模型?——这就是模型路由。
这也被称为模型融合。
截至撰写本文时,我没有看到OpenAI或Anthropic提供原生的模型路由选项。但OpenRouter让这变得很简单。
2.4 批量处理请求可大幅节省成本
如果你有大量相似的请求,为什么不批量处理呢?它可以节省高达50%的预算。此外,所有主流推理提供商都支持批处理(OpenAI和Anthropic)。
OpenAI要求我们准备一个JSONL文件,其中每一行是一个请求。然后你可以上传并启动批处理。这样做会返回一个批处理对象。你可以使用批处理对象中返回的ID来检查进程状态。一旦进程完成,你将获得output_file_id来下载输出文件。
Anthropic遵循类似的工作流程。但不涉及JSONL文件。你可以直接创建一个批处理对象并获取批处理ID。然后你可以检查状态并在完成后下载输出。
批处理对于前置加载AI工作负载非常高效。它提供了大幅折扣、更快的完成速度,而且根据OpenAI的说法,还有更高的速率限制。
2.5 控制输出长度
这看起来可能微不足道,但它也是控制推理成本的有效方法。让AI不要浪费token。
你可以通过在大多数API提供商中设置max_tokens参数来实现。但你也可以明确要求AI保持回答简洁。更好的做法是,在你的系统提示中说明这一点。
一个稍微更高级的技巧是要求结构化输出。你可以要求AI以JSON格式响应。即使你的目标是获取一个段落,且段落结构已知,你也可以要求AI输出一个JSON来填充你在提示中提供的段落中的空白。
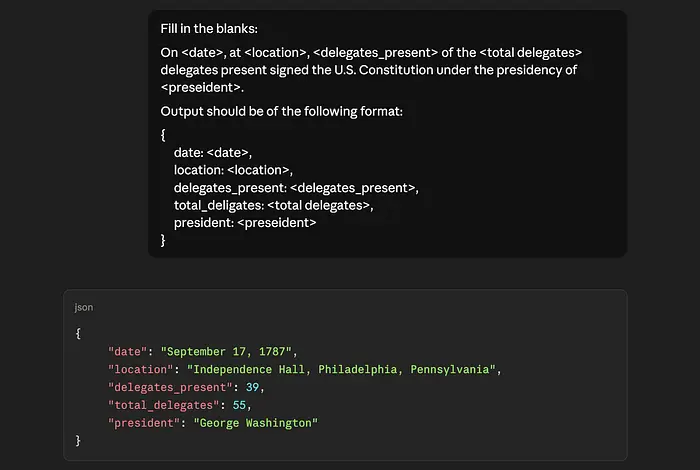
实际上,你正在将token从高成本的输出token转移到低成本的输入token。
3、自托管何时才划算?
一个经验法则是:如果你每月处理超过5万个请求,就考虑自托管。以下是计算过程。
如果每个请求消耗4k个输出token,那大约是每天200万token。像Claude Sonnet 4.6这样的模型每天将花费你30美元,每月900美元。
然而,这个经验法则并非标准。它还取决于你使用的是哪个模型以及你打算替换成什么。
但大多数专家一致认为,在每天1万个请求以下,自托管的基础设施成本不合理。盈亏平衡区间在每天1万到10万个请求之间。超过这个点,你的GPU利用率开始回本。对于超过100万个请求的情况,最好自托管。
4、结束语
自托管有几个好处:更好的数据控制和合规性、低延迟、边缘部署等。
虽然降低成本被认为是自托管的好处之一,但对大多数用户来说这很少成立。因为我们大多数人使用AI的量不足以跨过盈亏平衡点。
如果成本是我们关心的问题,在自托管之前,我们还有很多其他选择可以尝试。
原文链接: Proven Techniques to Reduce Inference Cost Without Self-Hosting AI
汇智网翻译整理,转载请标明出处
