数据标注流水线快速指南
大多数ML失败不是由错误的模型架构引起的。糟糕的标签才是罪魁祸首。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
一个视频平台的信任与安全团队花了四个月时间构建了一个他们称之为最先进的毒性分类器。他们通过一家主要的众包供应商标注了80万条评论,达到了0.91的标注者间一致性(Cohen's kappa超过0.85即为优秀),训练了一个在保留集上达到F1 = 0.94的transformer模型。他们将其上线了。
两周之内,倡导团体就提出了正式投诉:该模型系统性地漏标了用于骚扰特定社区的暗语。模型没有坏。是标签坏了。标注者池——通过英语流利度筛选在全球招募——普遍无法识别特定的暗语,因此他们一致将其标记为"非有毒"。标注者间一致性达到了0.91,因为标注者们都共享着同样的盲点。模型准确地学到了标签所表达的内容。
本文将从一条评论——一个47个字符的文本片段——通过标注系统的每一个层级进行追踪,指出每个层级旨在防止的具体失败模式。
1、核心洞见
大多数ML失败不是由错误的模型架构引起的。糟糕的标签才是罪魁祸首。
2022年对大型科技公司生产环境ML事件的一项分析发现,数据质量问题——标签噪声和不一致性、模式漂移、标注者偏差——比任何算法选择都造成了更多的模型性能下降。你在Google或Meta的面试官几乎肯定知道这一点。问题是你是否知道。
标注流水线是将原始未标注数据转化为模型可以实际学习的内容的系统。这听起来很简单。在实践中,它是一个多阶段操作,每个阶段都内嵌着四种失败模式:
需要捕捉的四种失败模式
───────────────────────────────────────────────────────────────────
1. 噪声 标签本身是错误的
→ 质量控制来捕捉这个问题
2. 偏差 标注者始终在错误答案上达成一致
→ 黄金标准验证集来捕捉这个问题
3. 漂移 指南在第1周和第12周含义不同
→ 版本化本体 + 跨时间IAA来捕捉这个问题
4. 停滞 标签只覆盖简单案例,模型永远学不会难的
→ 主动学习循环来捕捉这个问题
本文中的每个模式都对应这四种之一。每个反模式都是未能捕捉到其中一种问题的不同方式。
2、基准设置
领域 : 视频平台 · 公开评论
任务 : 多类毒性分类(5个类别)
非有毒 / 轻度 / 骚扰 / 仇恨 / 威胁
数量 : 80万条评论待标注 · 池中有1200万条未标注
模式版本 : v3(2024-08-15法律审查后修订)
标注者池 : 通过Scale AI的240名众包工人 · 12名专家审核员
每任务标注数 : 3名众包工人 + 分歧时1名专家审核
成本 : 每条众包标签$0.04 · 每条专家标签$5.00
质量门槛 : 5%蜜罐率 · Cohen's kappa最低0.85
黄金标准集 : 2400个示例 · 领域专家裁决
锚定示例 : 那条导致生产环境崩溃的47字符评论
到模型上线时,这条评论已经被三位独立的众包工人、两位高级审核员、一个协调投票的标签模型、以及一个决定是否信任共识的置信度校准器看过。每个阶段都是bug可能藏身的地方。
3、工作原理:五个阶段,不是一个
大多数候选人将标注描述为"把数据发送给Scale AI,拿回标签"。这只是更长链条中的一步。完整的生命周期有五个不同的阶段:
1. 摄入 原始评论从产品日志和未标注池中排队
│
↓
2. 任务分解 "这是有毒的吗?"被分解为原子决策
│ → 包含侮辱性词语?针对某个群体?威胁暴力?
↓
3. 标注 平台将任务路由给标注者(Scale、Labelbox...)
│ IAA评分在标签返回时运行
↓
4. 质量控制 蜜罐准确率 · IAA阈值 · 裁决队列
│ 只有通过审查的标签才会被写入
↓
5. 版本化导出 标签与元数据一起写入:谁、何时、模式版本、
置信度、黄金标准一致性
→ 被训练流水线消费
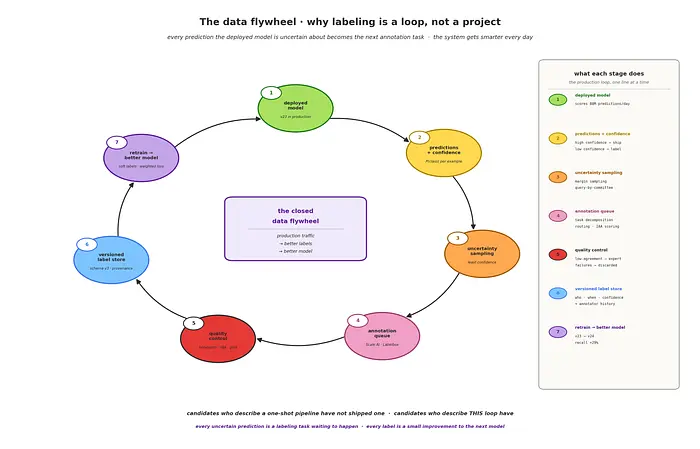
这是离线生命周期。五阶段流水线是最低限度——但它也是一次性的过程。实际的生产系统有一个闭环的第六阶段:
流水线是一个循环,不是一个一次性过程。 一旦模型部署,其低置信度预测就成为下一批标注数据。模型告诉系统它在哪些方面遇到困难。这个反馈循环是将标注流水线与标注项目区分开来的关键。
这是整个面试中最重要的框架。如果你把标注描述为设置好、运行一次、然后忘记的东西——你已经表明你没有在生产环境中交付过这样的系统。
4、四种模式
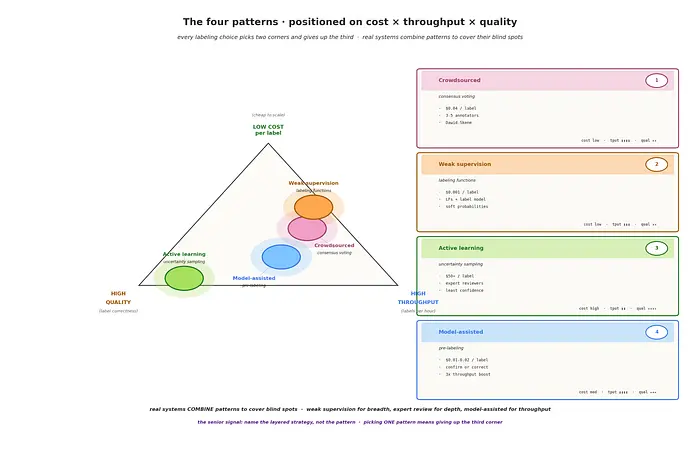
每种模式都处于成本×吞吐量×质量三角形的不同位置。真实的生产系统会将它们组合使用。
模式1:带共识投票的众包标注
将同一个示例发送给多个独立的标注者(通常3到5人)。标注者看不到彼此的答案。共识引擎解决投票——简单端用多数投票,复杂端用Dawid-Skene(根据每个标注者的历史可靠性来加权他们的投票)。分歧超过阈值的示例被路由到裁决队列。
权衡:低成本高吞吐量,但个别标注者的质量参差不齐。通过冗余和质量门槛(蜜罐任务)来补偿。当任务需要真正的专业知识时,这种模式就会失效——比如放射科扫描、法律条款、暗语检测。
成本:低。吞吐量:高。质量:中等。适用于:内容审核、情感分析、日常图片中的物体检测。
模式2:编程式弱监督
你有数百万个示例,但没有预算手动标注它们。编写标注函数(LFs):简短的启发式规则、正则表达式模式、关键词列表,或调用预训练模型。每个LF对标签投一个噪声票。没有单个LF是可靠的——但一个标签模型(Snorkel的生成模型是经典示例)学习每个LF的准确度以及与其他LF的相关性,然后将它们的投票组合成概率性的软标签。
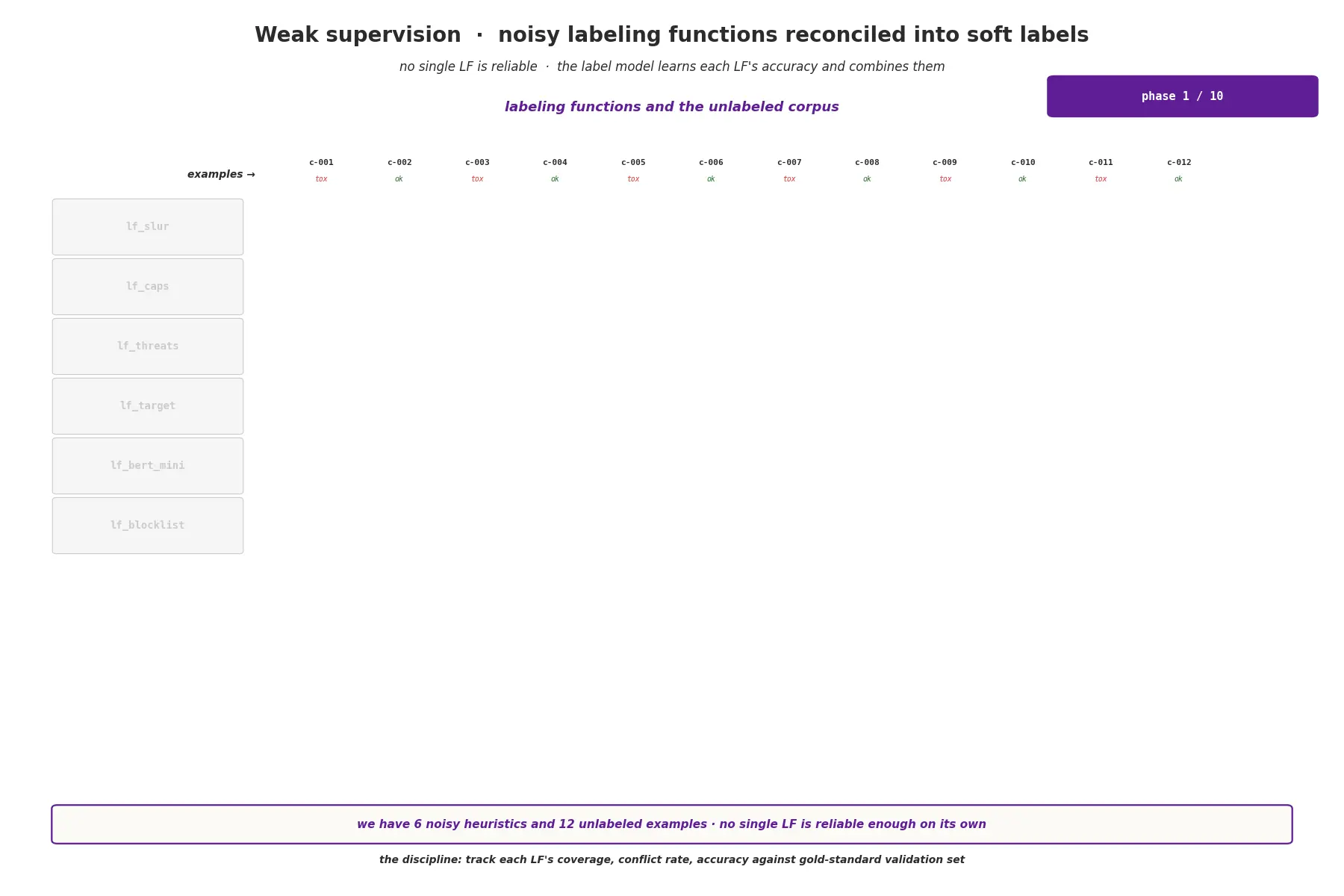
下游训练流水线直接消费软标签,通常按标签置信度对示例进行加权。你永远得不到完全干净的标签——但你能在几小时而非几周内覆盖整个语料库。
面试制胜句子: "标签模型学习每个LF的经验准确度以及LF之间的相关性,然后生成校准的软标签——不仅仅是平均投票。这种校准是弱监督真正起作用的原因。"
这种模式的纪律性在于维护一个LF分析仪表板:跟踪每个函数的覆盖率(它在多少比例的示例上触发)、与其他LF的冲突率,以及针对小型黄金标准验证集的经验准确度。
成本:极低。吞吐量:极高。质量:有噪声(概率性)。适用于:垃圾邮件、医疗记录分类、正则能捕捉到有意义信号的NLP任务。
模式3:主动学习循环
翻转通常的工作流程。不是随机采样接下来标注什么,而是由当前模型对未标注池进行评分,挑出它觉得最困惑的示例。这些示例——如果被标注——将最大程度地移动决策边界。
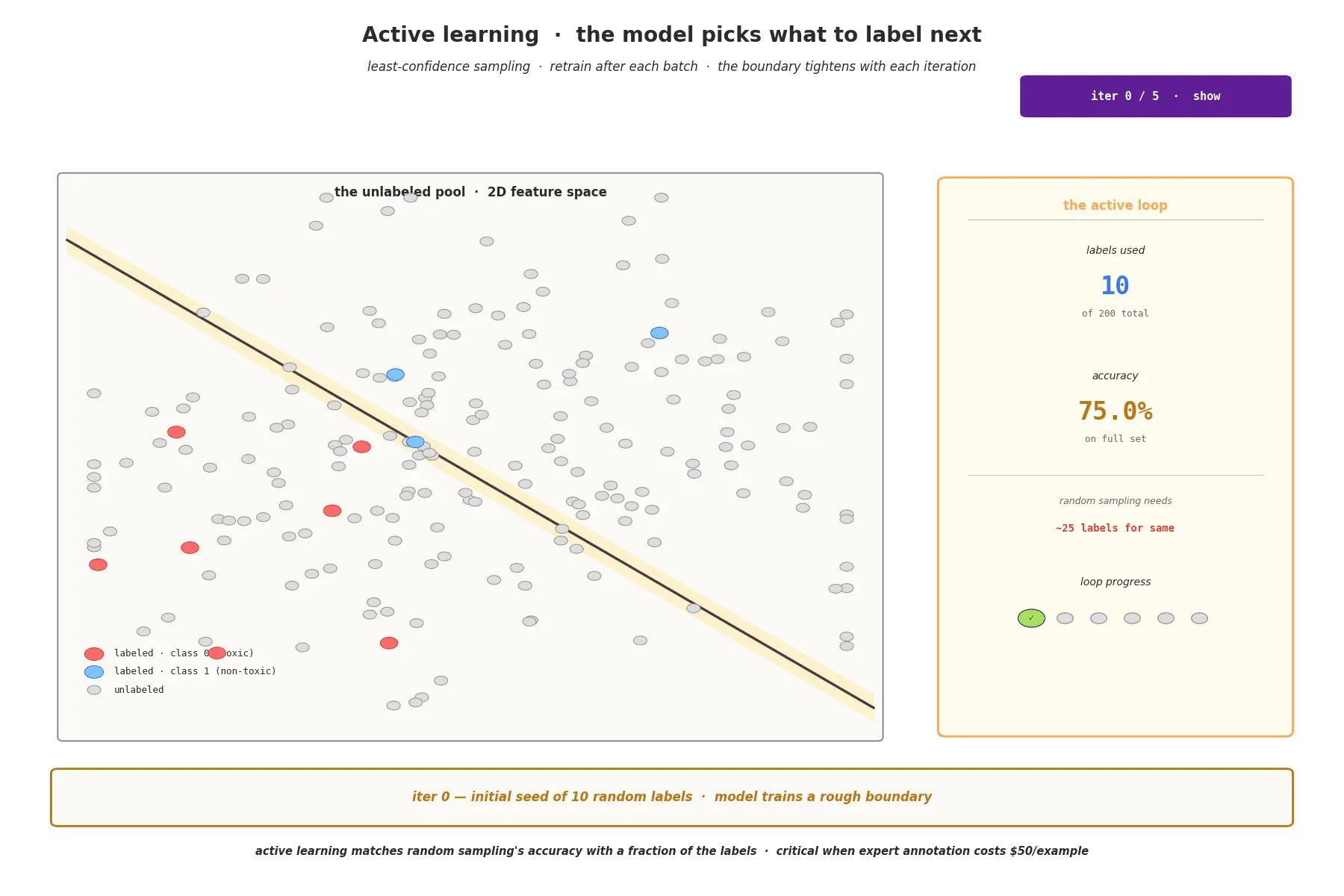
三种常见的采样策略:
- 最低置信度:选择最高预测类别概率最低的示例
- 间隔采样:前两个类别之间差距最小
- 委员会查询:模型集成中最高分歧
循环:训练 → 评分未标注 → 将最不确定的发给标注者 → 添加新标签 → 重新训练 → 重复。将不确定性采样批量处理,而不是每次标注后都重新训练,因为重新训练很昂贵。
回报是显著的:主动学习可以用一小部分标注数据匹配随机采样的性能。当专家标注成本为$50/示例时,这至关重要。
引导问题:你需要一个初始标注种子(几百个示例)来训练第一个模型。没有它,就没有模型来生成不确定性分数。
成本:高(专家时间)。吞吐量:低。质量:高。适用于:昂贵的标注(医学影像、法律审查)、专业领域适应。
模式4:模型辅助(预标注)标注
大多数候选人都忘记了这一个。在未标注数据上运行一个现有模型——即使是GPT-4这样的基础模型或微调过的BERT——来生成草稿标签。一个置信度过滤器将输出分割:高置信度预测被自动接受;低置信度案例交给人工标注者,标注者能看到草稿标签,只需要确认、纠正或拒绝。
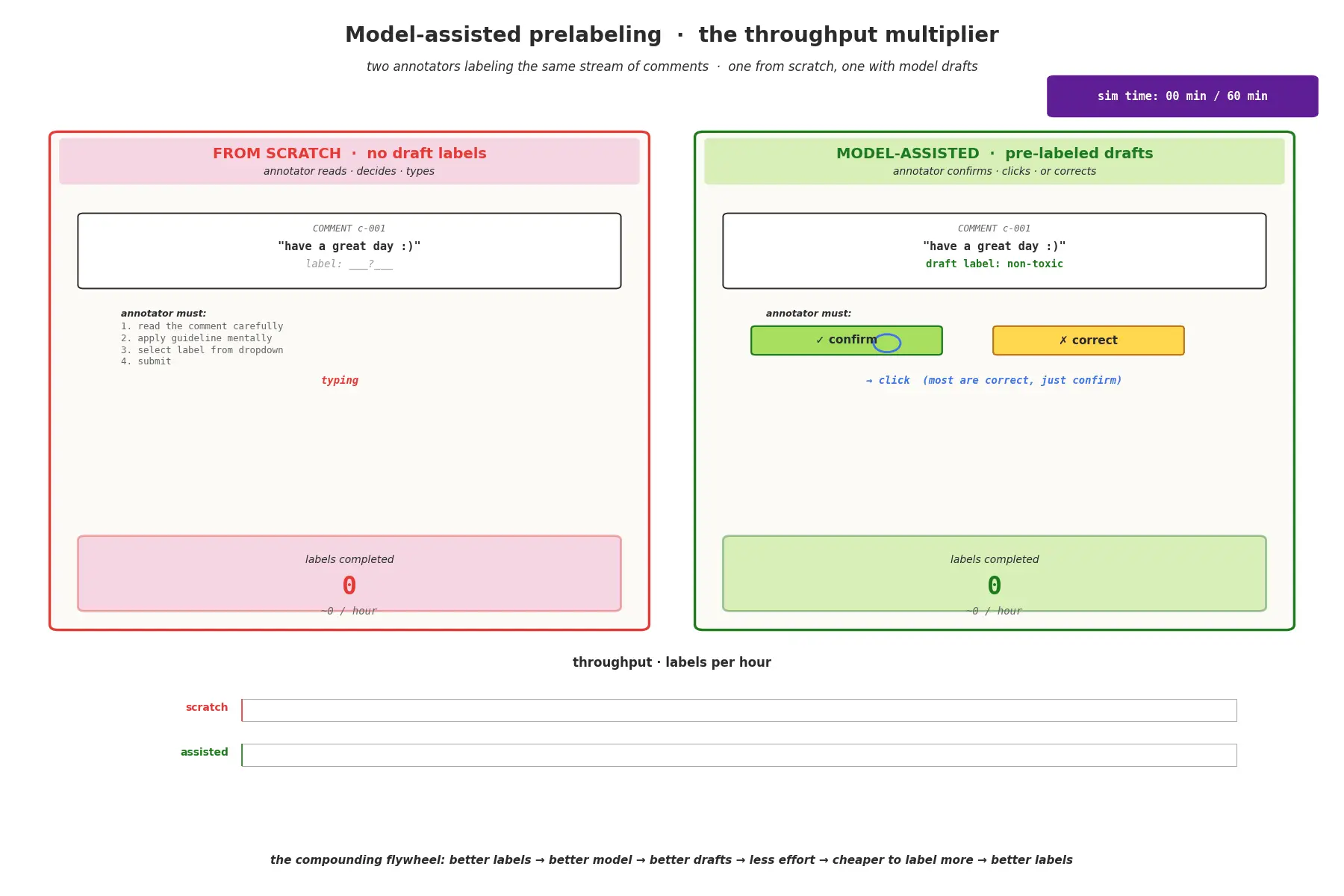
那个"确认或纠正"的UI就是吞吐量倍增器。从零开始的标注者每小时标注约200张图片。审查模型草稿的标注者达到每小时600到800张,因为大多数预测是正确的,点击确认比从头输入标签快得多。
复合飞轮:更好的标签 → 更好的模型 → 更好的预标签 → 更少的标注者工作量 → 标注更多数据更便宜 → 更好的标签。在面试中不请自来地提到这一点,你就表明你把标注视为一个工程问题,而不仅仅是采购问题。
成本:低到中等。吞吐量:极高。质量:高(人工验证)。适用于:任何时候有一个可工作的模型存在。
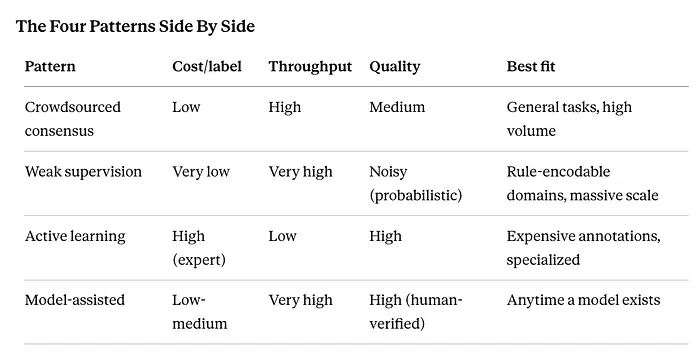
真实系统很少只选一种。常见的组合:弱监督在数百万示例上生成噪声标签,主动学习识别最高不确定性的子集,专家标注者只审查那些案例,并通过模型辅助预标注保持高吞吐量。这种分层方法才是高级答案。
5、四种反模式
反模式1:将标签视为二元
"一旦数据标注完成,我们就将其送入训练。 完了。没有提到置信度、标注者可靠性或分歧。
面试官问:"如果其中一些标签有噪声怎么办?" 候选人僵住了——或者更糟,说"我们就重新标注。
真实流水线中的每个标签都有一个置信度分数、一个标注者可靠性权重,以及一个记录了多少人同意的历史记录。将标签当作真实标签来训练就是在欺骗你的模型。
修复方法:以概率方式对待标签。来自可靠标注者的高一致性标签在训练中获得完全权重。低置信度标签获得降低的损失权重(标签平滑、噪声感知损失)或被路由回去审查。软标签是默认值,不是例外。
反模式2:忘记标签模式会变化
这是微妙的一个。你设计了一个内容审核系统,将50万示例标注为"有毒"或"非有毒",六个月后你的政策团队重新定义了"有毒"的含义。现在你有了50万个基于一个已不存在的定义构建的标签。
没有提到模式版本控制的候选人隐含地假设指南是静态的。它们不是。随着边缘案例的出现、法律要求的变化、产品的改变,指南会不断演化。
修复方法:版本化本体。每个标签都标记有它所依据的模式版本。当模式发生变化时,你有一个明确的决定:重新标注受影响的子集、丢弃,或将模式版本作为特征进行混合训练。静默混合模式版本就是破坏数据集的方式。
反模式3:将一致性等同于正确性

这就是开篇轶事中的bug。"我们测量标注者间一致性以确保标签质量高。"
高IAA意味着标注者彼此同意。它并不能说明他们是否正确。对于主观任务(毒性、情感),一群标注者可以始终一致地同意,但同时一致地偏向同一个方向。如果你的标注者池偏向特定人群,他们会统一地漏标某些类型的有害内容。IAA看起来很棒。你的模型学到了一个有偏见的伤害定义。
修复方法:将一致性指标与准确度指标分开。维护一个黄金标准验证集——由领域专家或通过正式裁决构建——用它来测量标注者的准确度,独立于他们彼此之间的一致程度。IAA是必要的但不够。不请自来地提出这一点是你可以发出的最清晰的高级信号之一。
反模式4:将生产环境视为标注系统之外
候选人描述了一个优雅的离线标注流水线。面试官问:"这个系统如何随时间改进?" 候选人说:"我们会定期收集更多数据并标注它。"
这是把最好的信号留在了桌上。生产环境不断产生隐含标签。用户纠正、拒绝率、升级模式、点击行为——都是弱监督信号。用户将推荐标记为不相关就是一个标签。审核员覆盖自动决策就是一个标签。
修复方法:将流水线构建为闭环。部署后,低置信度预测排队返回进行人工审查。用户反馈被捕获为弱标签。系统在每次交互中都变得更聪明,而不仅仅是在训练运行之间。
6、完整追踪:一条评论通过整个流水线
第0天 · 10:23 │ 评论 c-1f8a 发布在视频 v-3201 上
│ "you're really not what we said you'd be lol"
│ 47字符 · 表面上含糊不清
│
第0天 · 10:24 │ 已部署模型对评论评分
│ P(非有毒)=0.32 P(骚扰)=0.41 P(仇恨)=0.27
│ 置信度间隔 = 0.41-0.32 = 0.09 → 低
│ → 路由到标注队列
│
第0天 · 11:15 │ 进入 Scale AI 任务池
│ 模式版本 = v3
│ 任务分解:
│ Q1: 包含侮辱性词语? → 否
│ Q2: 针对某个群体? → ???
│ Q3: 暗示威胁? → ???
│ Q4: 需要上下文才能理解? → 是
│
第0天 · 14:02 │ 3名众包标注者独立标注
│ 标注者_a47 → "非有毒" (置信度 0.7)
│ 标注者_b12 → "骚扰" (置信度 0.6)
│ 标注者_c89 → "非有毒" (置信度 0.5)
│ 简单多数共识:非有毒
│ 此三者的 Cohen's kappa:0.31 → 低于阈值
│
第0天 · 14:03 │ 低IAA标志触发裁决
│ → 路由到高级审核员队列
│
第1天 · 09:30 │ 专家审核员 e-04 带上下文查看
│ 上下文:针对 v-3201 创建者的先前评论线程
│ 判定:骚扰 (置信度 0.95)
│ + 附加备注:"常见的暗语模式,升级"
│
第1天 · 09:31 │ 写入版本化标签存储:
│ 标签 = 骚扰 · 模式_v3
│ 审核员 = e-04 · 黄金标准 = 待定
│ 置信度 = 0.95
│ 标注者历史 = 已存储
│ 同时:添加到黄金标准候选集
│
第7天 │ 每周汇总:此示例用于更新
│ 标注者 a47、b12、c89 的可靠性分数
│ → a47 可靠性:0.78 → 0.74
│ → b12 可靠性:0.71 → 0.76
│ → c89 可靠性:0.65 → 0.61
│
第14天 │ 批量重新训练
│ 评论现在是训练集的一部分
│ + 弱标签模型在整个语料库上重新训练
│ + 新增预标注启发式:"依赖上下文"
│
第30天 │ 部署的v2模型对照黄金标准评估
│ 暗语骚扰召回率:0.42 → 0.71
│ → 循环闭合
7、仍然开放的问题
标注流水线是决定你的模型学到什么的系统。五个阶段(摄入 → 分解 → 标注 → 质量控制 → 版本化导出)加上一个闭合的反馈循环。四种模式(众包、弱监督、主动学习、模型辅助)。四种反模式(二元标签、模式漂移、一致性 ≠ 正确性、生产环境在循环之外)。一个复合的闭环。
但这层打开的最深层问题是治理和问责必须回答的:
你的标注流水线产生了80万标签。六个月后,外部审计问:"这些标签是怎么产生的?谁做的决定?在什么指南下?标注者池在人口统计学上是否有代表性?如果监管者要求,你能重现你训练用的标签吗?"如果这些问题的任何答案是"我们不知道"或"我们需要查一下",那你的流水线存在的是治理缺口,而不是质量缺口。你如何构建标注之上的那一层,使每个标签可审计、每个标注者可问责?
来源追溯、标注者池的人口统计学平衡、裁决审计轨迹、解释的权利——这些是大多数团队尚未构建的下一层ML基础设施。一旦你的标注流水线产生了数百万标签,瓶颈就不再是吞吐量,而是信任。
原文链接: Machine Learning System design — Data Labeling Pipelines, With One Content Moderation System…
汇智网翻译整理,转载请标明出处
