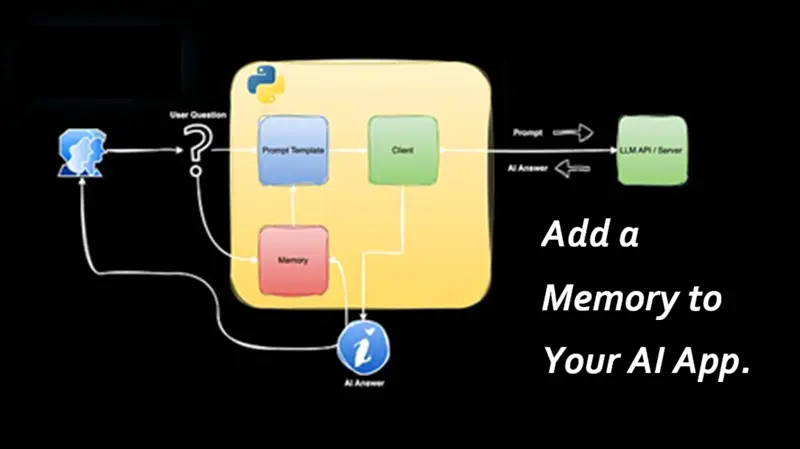
为 AI 应用添加记忆
本文的目标是理解记忆如何工作、它的限制以及与之相关的成本。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在概率论中,抛硬币序列是一组独立事件。如果你第一次抛到反面,它不会改变下一次得到正面或反面的概率——硬币没有"记忆"。
大语言模型(LLMs)表现类似。给定一个提示,LLMs 的响应在 API 调用之间是无状态的,除非明确提供先前的上下文。换句话说,开箱即用,LLMs 的功能就像《海底总动员》中的多莉——一条没有记忆的鱼。
那么,AI 应用,如聊天机器人和 AI 代理,如何与用户长时间进行对话?答案很简单:记忆。
在本教程中,我们将学习如何使用几行 Python 和 OpenAI Python SDK 从头开始设置记忆。你应该在生产环境中这样为你的 AI 应用构建记忆吗?绝对不! 这里的目标是理解记忆如何工作、它的限制以及与之相关的成本。
本教程的完整 Python 代码可在 这个仓库中找到。
1、记忆类型
一般来说,AI 应用使用两种类型的记忆:
- 短期记忆:应用在单个会话期间"记住"对话,并在会话结束时清除它。
- 长期记忆:应用"记住"单个会话之外的对话。
你可以将这想象为 RAM 和硬盘驱动器的区别。RAM 是短暂的,在机器重启时会被清除,而硬盘驱动器在任何单个会话之外持续存在。
在本教程中,我们将专注于设置短期内存。

2、无状态 AI 应用
让我们从构建一个没有内存的简单聊天应用开始(即无状态),看看当用户试图进行对话或跟进之前的对话时它如何表现(或失败)。这个简单应用将有以下组件:
- LLM 客户端
- 提示模板

2.1 LLM 客户端
我们将使用 OpenAI API Python SDK 来调用本地 LLM。我正在使用 Docker Model Runner 来本地运行模型,你可以轻松修改 OpenAI 客户端设置(即 base_url、api_key 和 model)来使用任何其他与 OpenAI API Python SDK 兼容的方法:
import openai
base_url= "http://model-runner.docker.internal/engines/v1"
api_key = "docker"
model = "ai/llama3.2:latest"
client = openai.OpenAI(
base_url = base_url,
api_key = api_key
)
2.2 提示模板
prompt_template 函数遵循标准的聊天提示结构,它使我们能够在提示中嵌入用户问题:
def prompt_template(question: str):
return [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": question},
]
2.3 聊天应用
最后但同样重要的是,我们将用以下 while 循环连接这两个组件,它从用户接收输入,将输入嵌入到提示模板中,发送到 LLM,并返回答案:
while True:
question = input("Question: ")
if question == 'quit':
break
completion = client.chat.completions.create(
model= model,
messages = prompt_template(question),
temperature=0
)
print(f"AI: {completion.choices[0].message.content} ")
让我们将上述代码设置为一个 Python 脚本文件 并从终端运行它:
/opt/python-3.11-dev/bin/python 01_stateless_app.py
这将打开一个对话,我们可以问一个简单的问题,比如美国的首都是什么:
Question: What is the capital of the USA?
AI: The capital of the United States of America is Washington, D.C. (short for District of Columbia).
LLM 答案标记为"AI"返回了正确的答案——华盛顿特区。
让我们尝试问一个关于英国(首都)的后续问题:
Question: and UK?
这返回了以下答案:
AI: You're referring to the United Kingdom (UK). The UK is a sovereign state located off the northwestern coast of Europe, comprising four constituent countries: England, Scotland, Wales, and Northern Ireland.
Here are some key facts about the UK:
1. **Capital city**: London is the capital and largest city of the UK.
2. **Population**: The estimated population of the UK is around 67 million people.
3. **Language**: English is the primary language spoken in the UK, but Welsh, Scottish Gaelic, and Irish are also recognized as official languages.
4. **Currency**: The official currency of the UK is the Pound Sterling (GBP).
5. **Government**: The UK is a parliamentary democracy, with a constitutional monarchy as its head of state.
6. **History**: The UK has a rich history, with various empires and dynasties having ruled the region over the centuries.
7. **Economy**: The UK has a mixed economy, with a strong service sector, a significant manufacturing sector, and a substantial financial sector.
Some popular attractions and landmarks in the UK include:
* Buckingham Palace (London)
* Stonehenge (Wiltshire)
* The Tower of London (London)
* Edinburgh Castle (Scotland)
* The Lake District (Cumbria)
* The British Museum (London)
These are just a few examples of the many amazing places to visit in the UK.
Is there something specific you'd like to know about the UK?
因为每个请求是独立发送的,模型无法访问之前的问题或自己之前的响应
3、为应用添加记忆
现在我们已经设置了基准聊天应用,下一步是为它添加短期记忆。添加记很简单:将之前的对话附加到提示中,为 LLM 提供更广泛的上下文。这使 LLM 能够评估给定的问题是是否与之前的对话相关,如果相关,则相应地回答。

让我们从修改提示模板开始。我们将添加一个名为 conversation 的列表元素并将其嵌入到提示模板中:
# Store conversation memory
conversation = []
def prompt_template(question: str):
return (
[{"role": "system", "content": "You are a helpful AI assistant."}]
+ conversation
+ [{"role": "user", "content": question}]
)
这将使我们能够使用之前的聊天历史发送用户的新的问题。
接下来,我们将更新聊天应用以附加新的问题和相应的 LLM 响应:
while True:
question = input("Question: ")
if question == "quit":
break
completion = client.chat.completions.create(
model=model,
messages=prompt_template(question),
temperature=0
)
answer = completion.choices[0].message.content
print(f"AI: {answer}")
# Update memory
conversation.append({"role": "user", "content": question})
conversation.append({"role": "assistant", "content": answer})
让我们在终端上运行这个 Python 脚本,并尝试问与之前相同的问题:
/opt/python-3.11-dev/bin/python 02_ai_app_with_memory.py
Question: What is the capital of the USA?
AI: The capital of the United States of America is Washington, D.C. (short for District of Columbia).
Question: and UK?
AI: The capital of the United Kingdom is London.
太棒了!
现在,如果我们有一个与之前对话无关的新问题,会发生什么?LLM(至少我测试过的那个)知道如何切换上下文。我在上述问题之后问了以下问题:
Question: How much is 2 times 2?
AI: 2 times 2 is 4.
4、局限性
虽然这种方法简单且容易实现,但没有免费的午餐,它有一些限制。让我们回顾一些。
4.1 令牌增长和成本爆炸
每次你向提示添加新的用户消息或 AI 响应,发送到模型的总令牌数量都会增加。假设你正在使用按令牌收费的专有 LLM API,这意味着:
- 更长的对话变得越来越昂贵
- 相同的历史上下文在每个请求中反复重新发送
- 成本随着对话长度**线性(或更糟)**增长
4.2 上下文窗口限制
LLMs 有固定的上下文窗口。一旦累积的对话超过该限制:
- 较旧的消息必须被截断或删除
- 重要信息可能会丢失
- 模型可能表现不一致或"忘记"关键事实
这迫使你实现额外的逻辑,比如:
- 滑动窗口
- 总结
- 选择性内存保留
所有这些都增加了复杂性。
4.3 没有对内存的语义理解
这种方法将内存视为原始文本,而不是结构化知识:
- 模型无法理解哪些信息重要
- 关键事实与无关的闲聊混合
- 没有优先级或检索逻辑
结果,模型可能:
- 错过重要上下文
- 过度重视最近但不相关的消息
- 产生不稳定或不一致的答案
4.4 脆弱的提示工程
虽然这种方法适用于演示和短会话,但在现实世界的应用中它很快就会崩溃。
虽然我们在前面的例子中看到 LLM 可以从首都问题切换到数学上下文,但随着内存直接注入到提示中,模型性能水平的风险会下降:
- 小提示更改可能会显著改变行为
- 错误很难调试
- 意外的提示格式问题可能破坏系统
这使得系统随着增长而更难维护。
在下一个教程中,我们将审查如何处理令牌增长和上下文窗口限制。
5、结束语
在本教程中,我们从头开始构建了一个简单的 AI 聊天应用,并探索了如何通过将对话历史显式传递给模型来添加短期记忆。
从无状态基准开始,我们看到了当每个请求独立处理时 LLMs 如何表现,以及即使是最小的内存机制如何显著改善对话连贯性。
我们还检查了这种方法的限制,包括令牌增长、上下文窗口约束和脆弱的提示工程。虽然这种方法不适合生产系统,但它为记忆如何在底层工作提供了清晰的思维模型。
原文链接:Setting Up a Memory for an AI Application — The Hard Way
汇智网翻译整理,转载请标明出处
