用Gemma 4构建多模态助手
使用 Gemma 4 和 OpenVINO 构建多模态助手——在 Intel 硬件上运行图文推理并高效部署。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
使用语言模型曾经很简单。你加载一个模型,发送一个提示,然后收到一个回复。当大多数应用以文本为中心时,这种方法效果很好。
这个假设已不再成立。现代 AI 应用被期望能够理解图像、遵循结构化指令,并跨多个步骤进行推理。这种转变在 Gemma 4 中得到了清晰体现,它将多模态理解、长上下文交互和推理能力集中在一个模型家族中。
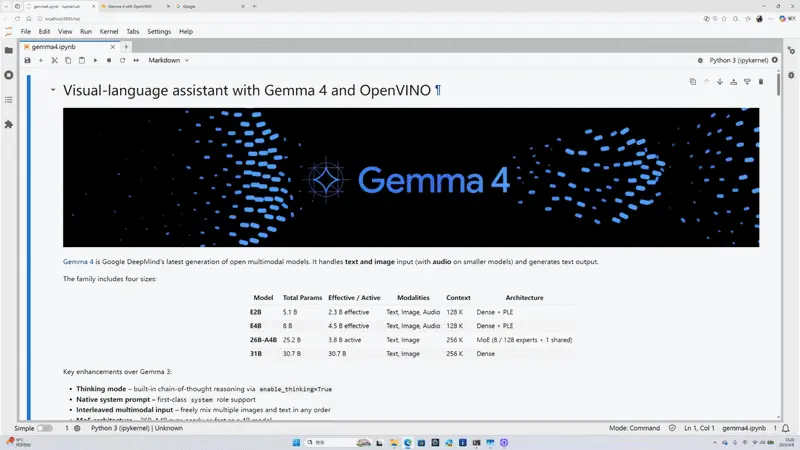
Gemma 4 是一个包含多种尺寸的模型家族,有助于实际的部署选择。但对开发者来说更重要的是它如何支持交互。
它引入了以下能力:
- 多模态理解,使文本和图像输入可以一起处理
- 一等公民级的系统角色支持,允许显式定义行为而不是嵌入到提示中
- 思考模式,通过
enable_thinking=True实现更结构化的、逐步的推理 - 交错多模态输入,其中多个图像和文本可以在一次交互中自由组合
这些不是孤立的功能。它们从根本上改变了应用的构建方式。
对话从*"它能回答吗?"转变为"它能在真实工作流中像助手一样行动吗?"*
这个差异是巨大的。一个能很好回复单个提示的模型是有用的。一个能在多模态交互中保持结构和上下文的模型是与产品相关的。
同时,以适合真实开发工作流的方式运行这些模型需要的不仅仅是加载权重。它需要一个运行时,能够接收通用模型并使其在受控和实用的设置中可用。这就是 OpenVINO™ 发挥作用的地方。它实现了从模型到推理的平滑过渡,而无需改变开发者与系统交互的基本方式。
OpenVINO™ 继续以其最新的 2026.1 版本演进,为现代生成式 AI 工作负载和多模态模型带来了更强的支持。OpenVINO 的核心是一个开源工具包,旨在跨 CPU、GPU 和 NPU 高效优化和部署深度学习模型。
在这篇博文中,我们采用实践方法。我们不会专注于孤立的功能,而是构建一个完整的流程,从 Gemma 4 模型开始,演变为一个多模态助手。目标是理解这些组件如何以一种可以直接应用于真实应用的方式组合在一起。
理解这个工作流的一个有用方式是转换视角。
我们不只是在运行一个模型。我们在构建一个能够接受文本和图像、以上下文理解来响应、遵循结构化指令,并在多次交互中不断演进的系统。
这个区别很重要。一旦你超越了单个提示,模型就变成了包含输入准备、行为控制和响应生成的更大管道的一部分。
1、端到端流程
OpenVINO™ 示例遵循从原始模型权重到可用多模态助手的实用路径。在实践中,过程如下:
➟ 设置环境, ➟ 选择一个 Gemma 4 检查点, ➟ 将其转换为 OpenVINO™ IR, ➟ 使用 OpenVINO 支持的运行时加载它, ➟ 准备文本和图像输入, ➟ 生成响应, ➟ 将工作流包装为简单的助手界面。
这也是当前启用价值变得清晰的地方。Gemma 4 功能预览支持目前在 OpenVINO™ 2026.0 和 2026.1 中可用,使开发者能够在支持的 Intel CPU 上高效运行多模态工作负载。这包括对完整 Gemma 4 系列(E2B、E4B、26B-A4B 和 31B)的支持,允许开发者开始在 Intel® Core™ Ultra 系列 CPU 和从第 14 代开始的 Intel® 桌面 CPU 上探索真实的助手工作流。GPU 支持目前通过 OpenVINO 每日构建版本提供,应被视为预览级功能。展望未来,还有更多即将推出:Hugging Face 上的预转换 OpenVINO IR 模型、GPU 支持、E2B 和 E4B 的 NPU 支持,以及带有分页注意力的 OpenVINO™ GenAI 集成,加上进一步的性能优化以推动模型家族的实用极限。换句话说,今天已经可用的只是第一步。
2、准备环境
克隆 GitHub 上的 OpenVINO_notebooks 仓库。按照这里的说明安装 OpenVINO_notebooks。安装完成后,使用 jupyter lab notebooks 加载所有笔记本。
然后打开 "gemma4" 笔记本,通过运行第一个代码单元开始安装模型转换和推理所需的组件。
3、选择 Gemma 4 模型和权重格式
Gemma 4 不是一个单一的检查点。它是一个涵盖小型和中型多模态模型的家族,包括 E2B、E4B、26B-A4B 和 31B。这很重要,因为模型选择是部署设计的一部分。较小的模型更容易在本地 CPU 上启动。较大的模型则开启了更强的多模态推理、更长的上下文处理和更丰富的助手行为。
OpenVINO™ 工作流还允许你决定在多大程度上优化内存和运行时行为。FP16 是直接的基线。当你想要减少占用空间并提高本地部署的实用性时,INT8 和 INT4 会变得有用。一个好的模式是从满足你质量目标的最小模型开始,验证交互流程,然后只在用例真正需要时才扩展。
4、将 Gemma 4 转换为 OpenVINO™ IR
一旦选择了模型(以 gemma-4-E2B-it 模型为例),下一步是导出。这是 Optimum-Intel 特别有用的地方。它处理从原始检查点到 OpenVINO IR 的转换,因此你可以在不重新设计工作流的情况下从原始模型文件转移到推理就绪的表示。
from optimum.intel import OVModelForVisualCausalLM
from transformers import AutoProcessor
model_id = "google/gemma-4-e2b-it"
processor = AutoProcessor.from_pretrained(model_id)
ov_model = OVModelForVisualCausalLM.from_pretrained(model_id, export=True)
ov_model.save_pretrained("gemma4_ov")
processor.save_pretrained("gemma4_ov")
完成此步骤后,你就有了 OpenVINO 版本的模型,更容易以一致的方式跨机器加载、测试和共享。
5、加载 OpenVINO 模型进行多模态推理
准备好 IR 后,你可以加载模型和处理器,开始运行实际的多模态提示。此时,交互模式保持一致。你仍然准备消息、通过处理器输入并生成文本。OpenVINO 现在位于流程之下,为 Intel 硬件优化执行。
ov_model = OVModelForVisualCausalLM.from_pretrained("gemma4_ov")
processor = AutoProcessor.from_pretrained("gemma4_ov")
6、运行图像理解推理
首先要验证的有用模式是最简单的多模态模式:一张图像加一个问题。这会一次性检查整个端到端路径。如果模型能正确加载图像、正确构建提示并生成有根据的响应,那么你的基本视觉-语言管道就在工作了。
典型的提示结构是:提供一张图像,提出一个关于它的具体问题,让模型解释它看到了什么。这足以验证文档理解、场景描述、视觉问答和许多早期助手场景。
messages = [
{"role": "user", "content": [
{"type": "image", "image": image},
{"type": "text", "text": "Describe what is happening in this image."}
]}
]
对于开发者来说,这是 Gemma 4 开始感觉不同于纯文本模型的时刻。你不再只是发送提示。你在组合交互。
7、使用原生系统指令
Gemma 4 中最重要的生活质量功能之一是对系统角色的原生支持。这听起来可能很小,但它改变了你构建应用的方式。你不再需要将行为指令隐藏在用户提示中,而是可以在交互开始时干净明确地定义助手行为。
在实践中,这意味着你可以说:作为一个有帮助的视觉助手回答,保持响应简洁,或将结果格式化为项目符号。优势是一致性。你的控制逻辑与用户查询分离,这使应用更容易维护,也更容易在以后扩展。
8、尝试交错多模态输入
当单图像流程工作后,转向更现实的助手模式:一次对话中混合多张图像和文本。Gemma 4 支持交错多模态输入,使比较、交叉引用和多步视觉推理变得更加自然。这对于比较图表、审查两个文档页面或询问两个屏幕截图之间发生了什么变化等场景非常有用。
关键点不是模型能看到两张图像。关键点是文本可以指导这些图像应该如何一起被解释。这正是开发者在从演示转向助手式工作流时需要的交互类型。
9、为更难的推理开启思考模式
Gemma 4 还支持可配置的思考模式。当你启用它时,模型在生成最终答案之前更适合结构化的、多步骤的推理。这对于需要分析而非描述的提示特别相关:比较视觉内容、从图表中提取含义,或遵循基于图像的一系列指令。
一如既往,推理功能应该有目的地使用。对于快速说明或简短回答,标准生成通常就足够了。对于需要更仔细逻辑链的任务,启用思考模式并与默认行为比较输出质量。在实际应用中,这可以成为路由选择而非固定默认值。
10、将管道包装为助手
最后一步不是关于又一个功能。它是关于封装。笔记本流程最后将模型加载、提示处理和多模态交互包装到一个轻量级的 Gradio 界面中。这将孤立的推理调用变成了开发者可以实际测试、演示和快速迭代的东西。
以下是在 Intel Core Ultra Series 3 笔记本电脑上运行时的效果。
11、实用配置和技巧
一些实用的习惯可以使 Gemma 4 的启动更顺畅。首先,如果你的目标是验证管道,从较小的检查点开始,如 E2B 或 E4B。这减少了故障排除的噪音,帮助你专注于提示结构、预处理和运行时行为,然后再推进到更大的模型。其次,将权重格式视为部署杠杆,而不仅仅是基准设置。FP16 是安全的基线,而 INT8 或 INT4 是当内存使用和响应速度开始变得重要时要探索的设置。第三,将正确性测试与性能调优分开。首先确认图像输入、系统指令和思考模式都按预期工作。然后再优化模型大小、精度和运行时配置。这个顺序可以节省时间。
12、结束语
当今 AI 开发中最重要的转变是概念上的:从提示-响应思维转向交互-系统思维。开发者不再将模型视为孤立的响应者,而是在设计管理上下文、结构和多步骤交互的系统。
Gemma 4 为构建多模态、指令感知的助手提供了强大的能力层,而 OpenVINO 提供了一个执行层,使这些能力在日常开发中变得实用。凭借 CPU 上 Gemma 4 系列已有的功能预览支持,你现在就可以开始实验,而不必等待生态系统完全成熟。今天就试试吧。祝编码愉快。
原文链接:Running Gemma 4 with OpenVINO: Building a Multimodal Assistant End-to-End
汇智网翻译整理,转载请标明出处
