从零到AI工程师:我的学习路线图
在这篇博客中,我将分享我从零开始精通机器学习的旅程,从构建对现代 GenAI LLM 架构和前沿技术的理解,到分享资源。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
许多人对人工智能(AI)和机器学习(ML)感到困惑,通常认为它们是相同的,但事实并非如此。AI 是一个更广泛的领域,专注于构建能够智能行为的系统,而 ML 是 AI 的一个子集,使系统能够从数据中学习。ML 模型不是被显式编程的,而是在数据上训练以识别模式并做出未来决策。
现代系统如大语言模型(LLM)和计算机视觉模型主要由 ML 驱动。然而,AI 不仅限于 ML。其他方法也在业界广泛使用,例如基于图的技术(常用于游戏中的智能移动)和进化算法等。
在这篇博客中,我将分享我从零开始精通机器学习的旅程,从构建对现代 GenAI LLM 架构和前沿技术的理解,到分享资源。这不是一段短旅程;有许多技术栈、教训、挑战和洞见,我将在整篇博客中分享。
我没有深入探索 AI 的其他领域。我研究了一些基于图和进化的技术,但我大部分时间都专注于机器学习,这也是我今天继续工作的方向。原因很简单:许多现实世界的问题都可以用 ML 有效地解决。
在此基础上,ML 社区构建了像大语言模型(LLM)这样强大的系统,它们已经彻底改变了许多用例和应用。
1、学习机器学习的先决条件
学习机器学习的先决条件包括对数学的基本理解,因为 ML 在很大程度上基于数学。你应该熟悉概率、微分(微积分)和线性代数等概念。话虽如此,如果你不是这些领域的专家也不必担心。随着你学习和实现不同的模型,你将在实践工作中逐渐建立对这些概念的理解。
此外,对编程的基本理解也很重要。Python 是 ML 的最佳选择,因为它简单且生态系统强大。如果你不熟悉 Python,可以快速入门——大多数初学者教程可以在几小时内让你上手,这足以开始你的旅程。
2、理解传统机器学习
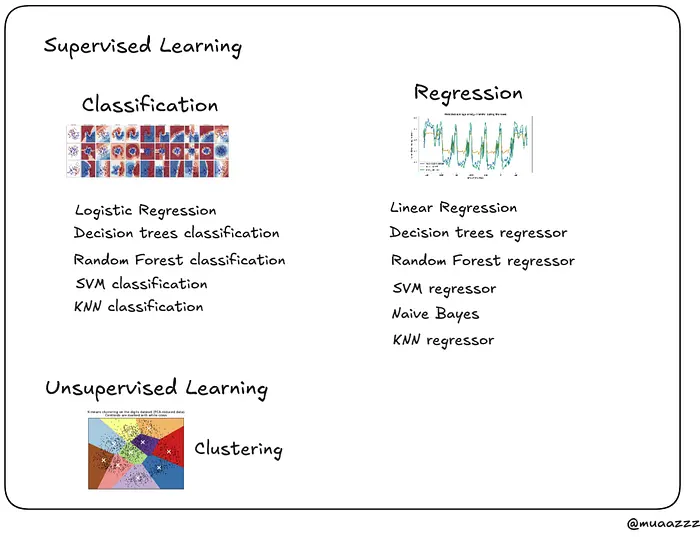
在开始阶段,你应该专注于传统机器学习模型。从理解基本概念开始,比如监督学习与无监督学习、回归与分类。大多数统计 ML 模型都属于这些类别。
你应该涵盖一些基本模型,包括线性回归、逻辑回归、决策树、随机森林、支持向量机(SVM)、K 近邻(KNN)、朴素贝叶斯和梯度提升。这些是构成机器学习基础的核心模型,也是面试中常被问到的。
虽然还有许多其他模型可用,但它们通常更针对特定用例。你可以从下面的链接探索它们,但掌握这些基本模型是最重要的第一步。
3、理解深度学习
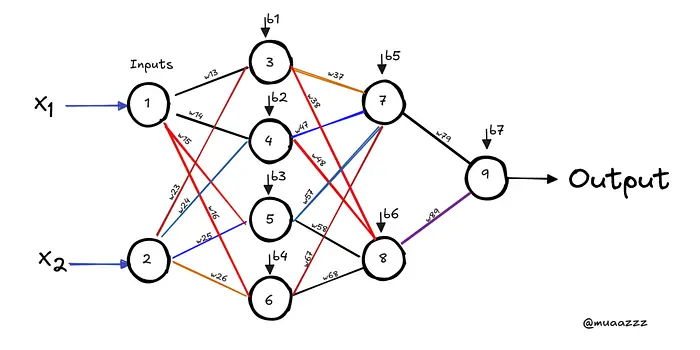
在这一步中,你应该从理解神经网络开始深度学习的基础。从人工神经网络(ANN)开始,探索它们的工作原理。
关注关键概念,如激活函数的作用、损失如何计算,以及反向传播如何在训练期间更新模型。你还应该理解不同的损失函数以及学习率在优化模型中的重要性。
此外,学习单层感知器的架构,然后过渡到多层感知器(MLP),它们构成了深度学习模型的基础。
一旦你在神经网络方面建立了坚实的基础,下一步就是并行探索自然语言处理(NLP)和计算机视觉。然而,在深入这些领域之前,重要的是对数据预处理有扎实的理解。
数据预处理是任何 AI 系统的关键部分。它涉及准备和转换数据,使模型能够有效学习。在以下部分中,我们将讨论结构化数据以及文本和图像数据的预处理方式。每个都将在各自的章节中涵盖,让我们从数据预处理的基础开始。
3.1 数据预处理:机器学习的基础
在机器学习中有一件事非常清楚:"垃圾进,垃圾出。" 你提供给模型的数据质量直接影响其预测质量。如果输入数据质量差,模型的输出也将不可靠。
这就是为什么数据预处理是训练任何模型之前的关键步骤。它涉及应用各种转换和技术,使数据变得干净、一致且适合学习。
从结构化数据的角度来看,你应该理解以下关键概念:
- 数据类型(连续和分类)
- 集中趋势度量(均值、中位数、众数)
- 离散程度度量(方差和标准差)
- 数据偏度
- 处理异常值(使用 IQR 和 z-score 等方法)
- 协方差和相关性
- 分箱和平滑
- 归一化和标准化
- 降维技术如 PCA
数据转换取决于你的具体用例和使用的模型类型。例如,如果你正在处理分类模型,你可能会应用与回归(连续值预测)不同的技术。转换的选择始终取决于数据的性质和你试图解决的问题。
4、自然语言处理
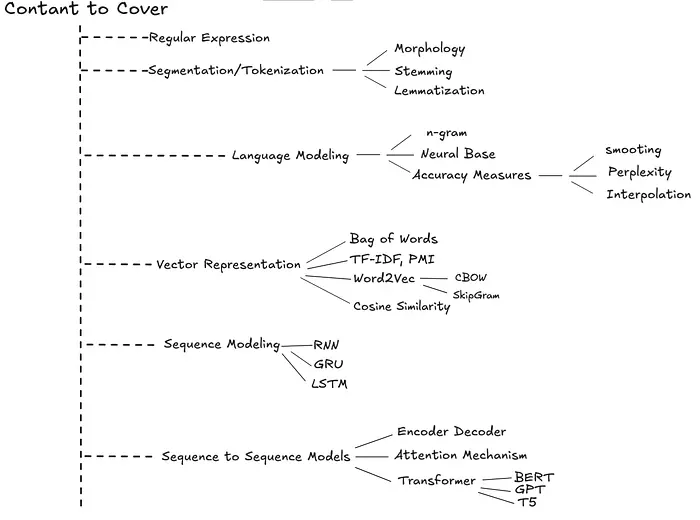
自然语言处理(NLP)专注于从文本中提取洞察并使系统能够理解人类语言。
要开始并理解 NLP 的每个概念,请参考下图。
4.1 机器学习中的文本预处理
现在让我们谈谈文本数据的预处理方面。机器学习模型不能直接处理原始文本——它们需要数值输入。因此,第一步是将文本转换为数字。
在此之前,我们需要通过删除不太有价值的元素来清理文本。这包括数字(在某些情况下)、像"the"、"a"、"an"这样的常见词(称为停用词)、多余空格和其他不必要的字符。
为了处理这些任务,有几个流行的文本预处理库,如 SpaCy、NLTK 和 Gensim,它们提供了高效的工具来清理和准备文本数据。
5、理解计算机视觉
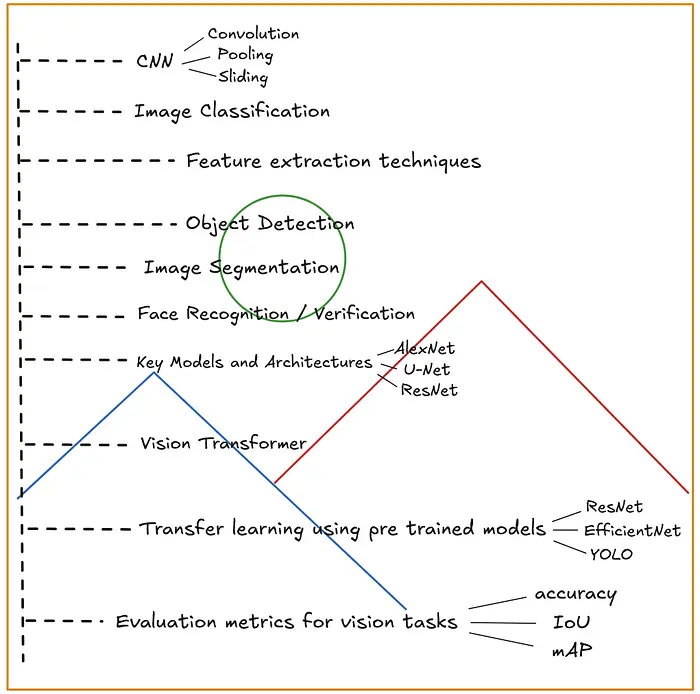
在计算机视觉中,我们经常听到这样一句话:"一张图片胜过千言万语。"这是因为一张图像包含数千(甚至数百万)个像素,每个像素都为描述图像做出贡献。机器学习模型使用这些像素值来理解图像并执行分类、检测和分割等任务。
为了更好地理解计算机视觉,了解它是如何演变的很有帮助。在机器学习兴起之前,计算机视觉严重依赖传统的图像处理技术,如滤波器和边缘检测。虽然许多这些方法已经被 ML 改进,但操作像素值的核心思想——通常通过滤波器——在现代计算机视觉模型中仍然发挥着基本作用。
要开始并理解计算机视觉的每个概念,请参考下图。
5.1 机器学习中的图像/视频预处理
图像和视频预处理包括图像缩放、归一化、图像增强(旋转、翻转、缩放、裁剪)、降噪、色彩空间转换(RGB 到灰度/HSV)、帧提取(用于视频)、帧采样、填充、直方图均衡化和标准化等技术。
6、理解生成式 AI
要建立对生成式 AI 的深入理解,你需要从其核心基础开始。今天,许多人仅将 GenAI 与使用 LLM API 或构建代理联系起来,但这不是全貌。要真正理解并在这个领域成长,遵循超越 API 使用的结构化学习路径很重要。
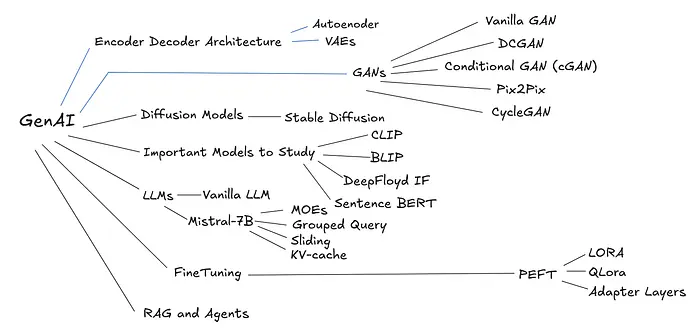
7、ML 中的其他重要领域
除了结构化数据、NLP、计算机视觉和生成式 AI 之外,AI 中还有其他几个值得探索的重要领域。这些包括音频和语音处理,模型处理语音识别、说话人识别和音频生成等任务。另一个关键领域是视频理解,将计算机视觉扩展到时序数据,用于动作识别和视频分类等任务。光学字符识别(OCR) 也广泛用于从图像和扫描文档中提取文本。此外,时间序列分析、推荐系统 和强化学习 等领域在跨行业的现实世界 AI 应用中也发挥着重要作用。
8、机器学习和 AI 中常用的工具和库
在机器学习和 AI 中,根据数据类型和问题使用不同的工具和库。
对于结构化数据,Pandas、NumPy、BeautifulSoup、Selenium、Matplotlib 和 Seaborn 等库通常用于数据收集、处理和可视化。对于建模,流行的框架包括 Scikit-learn、TensorFlow 和 PyTorch。
在自然语言处理(NLP)中,预处理通常使用 NLTK、SpaCy 和 Gensim 等库完成,而建模使用 Scikit-learn、TensorFlow、PyTorch 和基于 transformer 的库来处理。
对于计算机视觉,预处理通常使用 OpenCV 和 NumPy 执行,建模使用 TensorFlow、PyTorch 和基于 transformer 的方法完成。
在生成式 AI 领域,基于 transformer 的框架发挥核心作用,PyTorch 和 TensorFlow 被广泛使用。对于构建检索增强生成(RAG)等应用,LangChain、OpenAI API 和 Claude 等工具常被使用。
工具: 除了核心库之外,几个外部平台和工具在现代 AI 开发中也发挥着重要作用。Hugging Face 被广泛用于访问预训练模型、数据集和基于 transformer 的流水线。其他重要工具包括用于构建基于 LLM 的应用和代理的 LangChain,以及用于高效检索的向量数据库如 Pinecone 和 FAISS。这些工具大大简化了构建现实世界生成式 AI 应用的过程。
9、结束语
人工智能是一个广阔的领域,远不止使用 API 或构建简单应用。在这篇博客中,我们探索了一条涵盖机器学习、深度学习、NLP、计算机视觉和生成式 AI 基础的结构化学习路径,以及实践中使用的基本工具和库。我们还看了其他对现实世界 AI 系统做出贡献的重要领域。关键要点是,在 AI 中建立专业知识需要坚实的基础、持续的实践以及对理论和实践应用的清晰理解。
原文链接: From Zero to AI Engineer: My Roadmap from Machine Learning to Generative AI
汇智网翻译整理,转载请标明出处
