Chandra:商业OCR的终结者
一个来自布鲁克林初创公司的4B参数模型正在90种语言上击败GPT-4o和Gemini。虽然OCR不是我的专业领域,但这个模型让我着迷。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
几个月前,一位开发者将斯里尼瓦萨·拉马努金1913年的一封手写信件通过一个开源OCR模型进行识别。这封信件墨迹褪色、数学符号密集、有着111年的手写笔迹——大多数现代工具都会完全失败。
模型清晰地识别出来了。它保留了布局、数学符号,甚至保留了淡墨的细节。
这个模型叫Chandra,由一家名为Datalab的布鲁克林小初创公司构建。大多数OCR工具都会在这封信件前放弃,但Chandra像处理任何普通页面一样处理了它。
这吸引了我的注意力。随后Datalab发布了Chandra OCR 2。基准测试结果令人难以置信。
1、Chandra OCR 2到底是什么
Datalab刚刚开源了Chandra OCR 2:一个40亿参数的模型,可以将图像和PDF转换为结构化的Markdown、HTML或JSON,同时保留原始布局。
创建者是Vik Paruchuri。你可能知道他创建的Marker和Surya,这是两个开源文档处理工具,在GitHub上合计约有5万颗星。Chandra是有人在潜心研究文档智能多年后,决定在一个端到端模型上全力以赴的成果。
基准测试结果毫不含糊。
2、让我停止滚动的数字
在由AllenAI维护的独立olmOCR基准测试上(不是Datalab维护的),Chandra OCR 2得分85.9%。这是业界领先。它击败了所有被测试的模型,包括那些获得数十亿美元计算资源支持的模型。作为参考:GPT-4o得分69.9%。这是16分的差距。
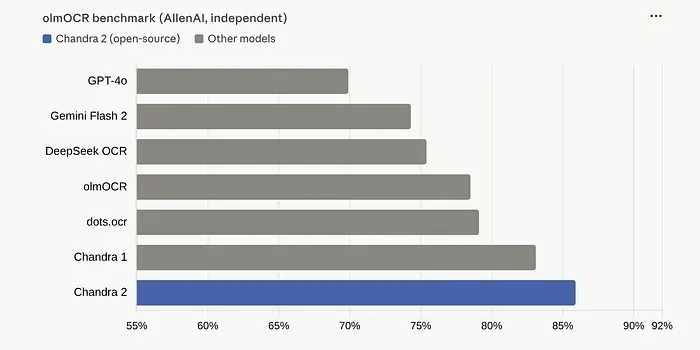
但真正的亮点来了。Datalab还构建了自己的多语言基准测试,覆盖90种语言。结果如下:
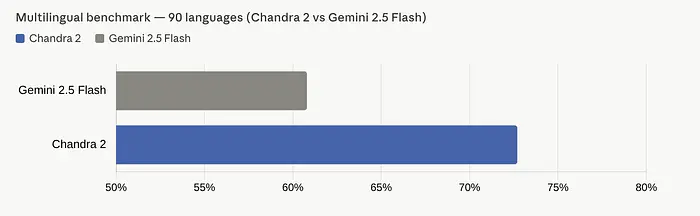
Chandra OCR 2得分72.7%,Gemini 2.5 Flash得分60.8%。这不是边际改进。这是跨越90种语言的12分领先。
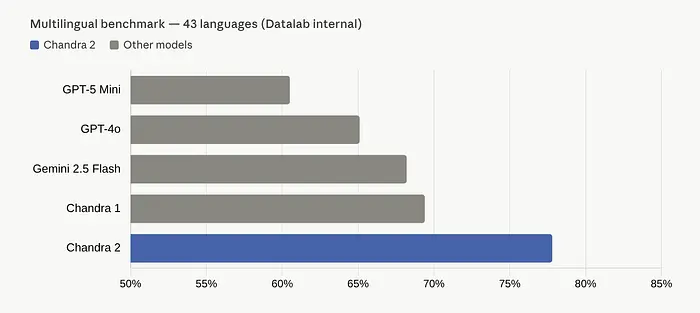
在43种最常用语言上,差距进一步扩大:Chandra达到77.8%,而GPT-5 Mini仅为60.5%。一些个别语言的提升令人惊讶:卡纳达语提升了42.6分,马拉雅拉姆语提升了46.2分,泰卢固语相比Chandra 1提升了39.1分。
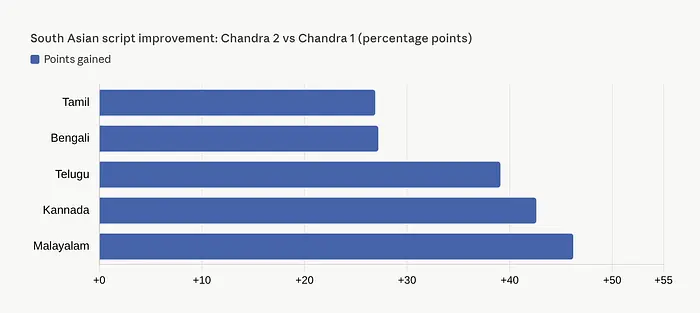
如果你处理南亚文字,这些数字不仅仅是令人印象深刻。它们是变革性的。
3、它实际能处理什么
大多数OCR工具都能很好地读取干净打印的英文文本。这从来不是难题。真正的难题是其他一切。
Chandra OCR 2能处理大多数工具无法处理的内容:具有复杂布局和嵌套表头的表格、数学符号(包括旧扫描件上的手写数学)、输出中保留复选框的多列文档、具有正确阅读顺序的多列文档、带有自动生成标题提取的图像和图表,甚至能转换为Mermaid流程图格式。
最后一项让我出乎意料。你输入一个带有流程图的文档,它会输出一个Mermaid流程图。对于一个本应该只是"读取文本"的模型来说,这是一种不同的雄心。
4、更小、更快、更好
最让我惊讶的部分来了。Chandra OCR 2是一个4B参数的模型。Chandra 1是9B。
他们将模型大小削减了一半以上,但在每个类别上仍然提高了准确率。olmOCR分数从83.1%提高到85.9%。多语言平均分从69.4%提高到77.8%。吞吐量翻倍。
在单张NVIDIA H100 GPU上,它在实际使用中每秒处理约2页。你可以通过HuggingFace本地运行,使用简单的pip install chandra-ocr[hf]。或者通过vLLM服务器和Docker远程部署用于生产工作负载。
pip install chandra-ocr
# 使用vLLM(推荐)
chandra_vllm
chandra input.pdf ./output
# 使用HuggingFace
pip install chandra-ocr[hf]
chandra input.pdf ./output --method hf
五行。仅此而已。无需API密钥。无云依赖。无需按页付费。
5、更宏观的视角
让我退一步看。
OCR一直是那种听起来已解决但实际未解决的问题。Tesseract已经存在了几十年。Google Document AI存在。Azure有自己的方案。每个主要云提供商都提供某种版本的文档提取。
然而,任何真正尝试在这些工具之上构建生产管道的人都知道痛苦。无尽的边缘情况。静默的失败。一个扫描中正常渲染的表格在另一个扫描中完全失效。手写识别在英文草书上行得通但在梵文字母上失败。
Datalab用Chandra采取了一种根本不同的方法。Chandra不是使用将页面分割成块、处理每个块、然后拼接的管道,而是使用全页解码。它一次性看到整个页面。这就是它具有布局意识的原因,也是为什么输出质量如此之高的原因。
这不仅仅关乎OCR。如果你正在构建RAG管道,文档解析的质量就是下游一切的天花板。糟糕的OCR意味着糟糕的分块,糟糕的分块意味着糟糕的检索,糟糕的检索意味着你的聊天机器人自信地给出错误答案。Chandra不会修复你的检索逻辑。但它在检索开始之前就消除最大的失败点之一。
6、诚实的注意事项
我不应该在不提及注意事项的情况下写这篇文章。首先是许可证。代码是Apache 2.0,完全开源。但模型权重使用修改后的OpenRAIL-M许可证:免费用于研究、个人使用,以及资金或收入低于200万美元的初创公司。如果你是一家更大的公司或想与Datalab自己的API竞争,你需要商业许可证。这不是最纯粹的"开源"。这是带有限制的开源权重。
其次是基准测试。Datalab创建自己的多语言基准测试是因为没有好的公共基准测试。这是合理的,但也意味着他们在多语言方面是自己给自己打分。olmOCR基准测试是独立的,Chandra在那里占主导。但我希望看到更多第三方对多语言方面的评估。
第三,GPT-4o的比较值得一个脚注。olmOCR基准测试使用固定提示,意味着GPT-4o的分数反映了它没有优化提示的性能。使用自定义提示,GPT-4o可能表现得比69.9%更好。差距是真实的,但在每个现实场景中可能不那么显著。
第四,手写识别。Chandra在手写笔记上得分不错(约90.8%),但在复杂手写表单上显著下降(约50.4%)。如果你主要使用案例是從手写表单中提取结构化内容,请在承诺之前仔细测试。
7、为什么这很重要
Datalab是一家位于布鲁克林的初创公司,成立于2024年。他们从Pebblebed获得了350万美元的种子轮融资,Pebblebed是由OpenAI和FAIR的前创始成员创立的基金。他们的网站上列出了Anthropic作为客户。
他们不是万亿美元实验室。他们是一个小团队,训练了一个4B参数的模型,在最广泛接受的OCR基准测试上击败了所有前沿模型。
我一直回到这一点。不是因为这是一个以弱胜强的故事(虽然也是)。而是因为它表明,在专业领域,较小的专注模型仍然可以击败通用巨头。前沿实验室正在构建能做所有事情的模型。Datalab构建了一个在一件事情上做得异常出色的模型。
对于任何构建文档处理管道、RAG系统或任何需要从混乱的现实文档中可靠提取结构化信息的工作流程的人来说:Chandra OCR 2是新的基准。
所有模型权重都是开放的。代码在GitHub上。如果你想尝试而不想安装任何东西,有一个免费 playground。
去在你最糟糕的PDF上测试它。那个让其他一切失效的PDF。这是Chandra赢得基准测试分数的地方。
原文链接: RIP Commercial OCR. An Open-Source Model Just Topped Every Benchmark.
汇智网翻译整理,转载请标明出处
