Claude Code倾向的技术栈
mplifying.ai 最近发布了一项研究,系统性地测试了 Claude Code 在跨 20 个工具类别的开放编码提示下默认使用什么。

AI编程/Vibe Coding 遇到问题需要帮助的,联系微信 ezpoda,免费咨询。
读完这篇文章后,你将理解为什么训练数据的存在 —— 而不是产品质量或 DevRel 投入 —— 正成为新项目采用开发工具的主要驱动因素。
而且,你将拥有一个思考如何应对它的框架。
以下是触发这项分析的数据:
AWS、GCP 和 Azure 在 Claude Code 对 20 个工具类别的系统测试中获得的零主要部署选择。零。地球上三个占主导地位的基础设施提供商 —— 对世界最先进的编码代理来说是不可见的。
与此同时,Vercel 和 Railway 这两家相对较小的公司,占据了 Claude Code 部署默认值的 100%。Vercel 用于 JavaScript,Railway 用于 Python。没有例外。
这不是一个 bug。这是一个信号。
虽然这些数据专门针对 Claude Code,但来自使用 Cursor 和 Copilot 的开发者的早期报告显示了类似的集中模式 —— 这不是一个模型的怪癖。
1、数字背后的研究
Amplifying.ai 最近发布了一项研究,系统性地测试了 Claude Code 在跨 20 个工具类别的开放编码提示下默认使用什么。不是它在被指示时能使用什么 —— 而是当开发者未指定时它选择什么。
结果是惊人的。shadcn/ui 占据了 90% 的 UI 组件选择。Stripe 占据了 91% 的支付集成。GitHub Actions 获得了 94% 的 CI/CD 推荐。Drizzle,一个相对较新的 ORM,占据了 100% 的 JavaScript ORM 选择 —— 而长期的市场领导者 Prisma 获得的正是零。
在 20 个类别中的 12 个中,Claude Code 根本不推荐任何工具。它构建自定义解决方案 —— 手动实现的认证、内存缓存、配置文件的功能标志。自定义/DIY 累计了 252 个总选择,超过了研究中的任何单个工具。
这不是市场份额数据。这是偏好数据。市场实际使用的内容与 LLM 推荐的内容之间的差距是故事变得有趣的地方。
驱动这些默认值的是不透明的 —— 训练数据组成、RLHF 调整和系统级配置的某种组合。确切的机制不如结果重要:工具推荐正以大规模、不可见的方式做出,没有透明度说明原因。
2、隐形的影响者
一位 Hacker News 评论员完美地捕捉到了含义:这是 LLM 广告不可避免的地方 —— 完全不可见。终极影响者。
这个观察比听起来更尖锐。当开发者读到推荐 Vercel 的博客文章时,他们可以看到作者的从属关系,检查评论区,根据替代方案进行权衡。
当 Claude Code 生成针对 Vercel 的部署配置时,没有任何这种背景存在。开发者不知道为什么 Claude 选择了 Vercel。他们甚至没有意识到做出了选择。
把它想象成 Google 的"手气不错"按钮 —— 只是用户永远看不到搜索结果。他们直接获得顶级选择,没有可见的排名,没有替代方案,没有归属。
这从根本上改变了开发工具采用的经济。传统的开发者营销通过漏斗运作:意识 → 评估 → 采用。LLM 推荐将这个漏斗折叠成单个步骤。没有评估阶段。工具只是出现在你的代码库中。
对于获得默认位置的工具来说,这是有史以来最高效的渠道。对于没有获得默认位置的工具来说,就好像它们不存在一样。
3、默认值实际上揭示了什么
以下是开发者在未指定时 Claude Code 选择的内容 —— 以及它与市场现实的比较:
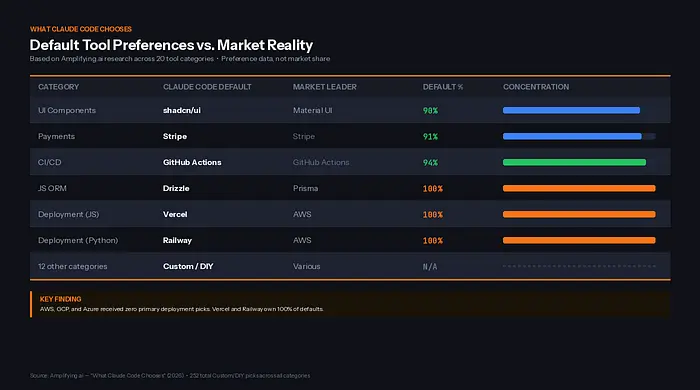
代际转变是戏剧性的。Drizzle 占据 100% 的 JS ORM 选择而 Prisma 获得零,这并不是当前市场的反映。Prisma 拥有更多的生产部署、更大的社区和多年的 Stack Overflow 答案。但 Drizzle 更新,其文档是为现代模式设计的,并且在最近的训练窗口中其代码库增长更快。更新的模型选择更新的工具。
云提供商的抹除是最挑衅的发现。部署完全由技术栈决定 —— JavaScript 使用 Vercel,Python 使用 Railway。传统的云提供商甚至没有被考虑。一位 HN 评论员分享了一个具体例子:Claude Code 试图在 NeonDB 和 Fly.io 上创建账户,尽管项目已经在 AWS EC2 实例上成功运行,并且所有内容都在项目的内存文件中有详细记录。
自定义/DIY 的主导地位是双刃剑。Claude 在 20 个类别中的 12 个中更倾向于构建而不是采用,这表明它并不总是在推动特定工具。但这也意味着整个工具类别 —— 功能标志、缓存、作业队列 —— 正在用定制代码而不是成熟的产品来解决。LaunchDarkly、Redis Cloud 及其同行没有被拒绝。它们被绕过了。
4、没有人定价的飞轮
这是动态变得令人担忧的地方。
准确地说:Amplifying.ai 的数据显示的是偏好,而不是确认的采用结果。
我们还没有关于有多少开发者将 Claude Code 的默认值原封不动地部署到生产的数据。但方向压力是明确的 —— 它只需要影响部分新项目就可以重塑工具采用曲线。
循环的工作方式如下:LLM 推荐工具 → 更多新项目采用它 → 更多代码、文档、教程和 Stack Overflow 答案包含它 → 下一个训练数据集过度代表它 → 下一个模型版本更强烈地推荐它。
这是一个赢家通吃的动态。已经处于默认位置的工具在它们接触的每个项目中积累更多的训练信号。不处于默认位置的工具不仅失去市场份额 —— 它们失去可发现性。在一个越来越多的开发者通过提示编码代理而不是阅读比较博客文章来开始项目的世界里,可发现性就是市场份额。
我们以前见过这个飞轮。Google 搜索排名为网络内容创造了相同的动态。排名靠前的网站获得更多流量,这产生了更多反向链接,这推动了它们在排名中更高。SEO 成为一种存在主义学科 —— 不是因为内容更好,而是因为算法需要优化。
"LLM 优化" —— 称之为 LMO —— 可能是开发工具的等价物。问题不在于你的工具是否好。而在于训练数据是否使它可见。
同一位 HN 评论员提出了一个尖锐的预警测试:Google 的 Gemini 是否偏向在 GCP 上构建?如果是,利益冲突就变得结构性了。基础模型提供商不仅在推荐工具 —— 它们在塑造市场。
5、重要的反驳论点
Hacker News 上的几位经验丰富的开发者提出了一个公平的观点:他们总是指定自己的技术栈。他们使用 Claude Code 作为执行者,而不是架构师。偏差主要影响给出模糊提示并接受默认推荐的开发者。
这是真的 —— 这正是为什么它重要。
使用开放提示开始项目的开发者群体是巨大的并且增长迅速。氛围编码 —— 描述你想要什么并让 AI 构建它 —— 正在将开发者群体扩展到传统软件工程师之外。这些用户没有强烈的工具偏好。他们接受模型给他们的一切。
值得注意的是模型会更新,今天的默认值不是永久的。更新的模型已经转向更新的工具。但这创造了一种不同类型的风险:存在主义波动。工具可以在单代模型中从 100% 默认变为零。Prisma 从 Claude Code 的 JS ORM 选择中消失是这种样子的预览。
6、这对你意味着什么
如果你正在构建开发工具: 你的进入市场剧本刚刚改变。文档质量、开源存在、教程密度和 GitHub 活动不再只是社区商品 —— 它们是训练数据输入。一个拥有优秀文档和活跃 GitHub 讨论的工具比具有稀疏公开足迹的更好产品具有结构性优势。
如果你正在投资开发工具: LLM 可发现性应该是一个尽职调查标准。一个对 Claude Code、Cursor 和 Copilot 不可见的投资组合公司面临复合劣势。护城河不仅是产品质量 —— 它是训练数据存在,这会随时间复合增长。
如果你在 AWS、GCP 或 Azure: 抽象层正在你之上移动。如果 Claude Code 从不生成 aws deploy,你的开发者营销越来越多地针对萎缩的受众 —— 仍然手动选择基础设施的开发者。
如果你是开源维护者: 优先考虑清晰文档、一致命名约定和可访问示例的项目将不成比例地受益。不是因为模型评估质量 —— 而是因为结构良好的内容更容易从中学习。
7、结束语
我们花了二十年的时间优化 Google 的算法。整个行业 —— SEO —— 涌现出来,以逆向工程使内容排名的因素。数十亿美元流向理解并玩转一家公司的相关性信号。
下一个十年可能是关于优化 LLM 的训练数据。机制不同 —— 没有关键词填充的等价物,没有反向链接方案。但激励是相同的:如果你不在模型的默认推荐中,你就不在对话中。
首先弄清楚这一点的公司 —— 将训练数据存在视为核心分发策略而不是社区建设的副作用 —— 将在最字面的意义上拥有开发者思维份额。
原文链接: Claude Code Has Opinions About Your Stack. You Should Pay Attention.
汇智网翻译整理,转载请标明出处
