用Meridian创建营销组合模型
学习使用 Meridian 训练营销数据并获取有价值的见解。

前段时间,Google 宣布计划从 Google Chrome 中移除第三方 Cookie,这是 Google 隐私沙盒倡议的一部分,旨在减少用户受到监控广告的暴露,并降低跨站跟踪。
对这一传言的反应,无论是当时还是现在,都极其两极分化。一方面,重视隐私的用户对这个决定感到高兴。另一方面,营销人员将其视为对业务方式的威胁。
截至目前,这一措施尚未全面实施,只有很小比例的用户受到影响。然而,许多浏览器(如 Brave 和 Firefox)默认就已经阻止了第三方 Cookie,甚至 Chrome 也正在转向用户选择的方式,这使得整体的 Cookie 环境不再是用户信息的可靠来源。
随着用户跟踪变得不那么有效,营销人员无法自信地确定哪些渠道正在推动 ROAS(广告支出回报率)。
这就是**营销组合模型(MMM)**发挥关键作用的地方。
MMM 分析多个渠道的聚合数据(支出、展示次数、覆盖范围、销售额),并使用时间序列数据来估算这些活动如何影响销售(有机和非有机销售)
有一些值得探索的 MMM 框架,如 Meta 的 Robyn、PyMC Marketing 和 Meridian,但在本文中,我们将专注于后者,不仅因为它极其用户友好和开源,还因为它明确考虑了付费和有机渠道的组合。
我们将首先了解营销组合模型的工作原理,然后深入探讨训练模型的步骤,并使用 Meridian 的内置函数和动态图表来收集见解。
1、营销组合模型的工作原理
营销组合模型,顾名思义,是一种分析方法,它使用营销输入的"组合"(如支出、展示次数、点击次数、覆盖范围、促销等),通过机器学习(ML)算法来估算其对销售和收入的影响。
MMM 背后的统计模型通常是多元回归或贝叶斯模型。它们依赖于所有营销渠道的历史时间序列数据,以及季节性和趋势。
Google 的 Meridian 框架遵循贝叶斯方法,结合先验知识和观测数据来估算媒体效果,同时量化不确定性。
Meridian 使用的贝叶斯回归模型基于贝叶斯定理,由以下方程表示:
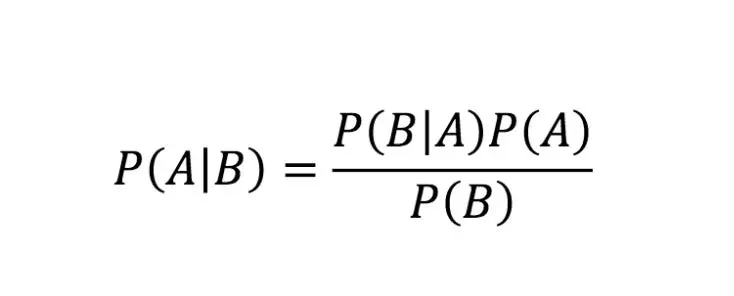
通用贝叶斯定理
其中:
- P(A|B)(后验概率):在 B 为真的情况下,A 发生的概率。
- P(B|A)(似然度):如果 A 为真,看到证据 B 的概率。
- P(A)(先验概率):在看到证据之前,你对 A 的初始信念。
- P(B)(证据):在所有可能场景下,证据发生的总概率。
那么,你会如何思考将贝叶斯定理应用于营销组合模型?
不像公式所建议的单个观察,定理用于估算时间序列数据中的渠道效果。例如,我们可能从先验信念开始,关于 Google Ads 等渠道的预期贡献,这由历史表现或领域知识提供信息。
然后,似然度结合观测数据,同时考虑季节性、重叠渠道和有机需求等因素。通过将先验与似然度结合,模型推断出渠道贡献的后验分布。
定理看起来更像这样:
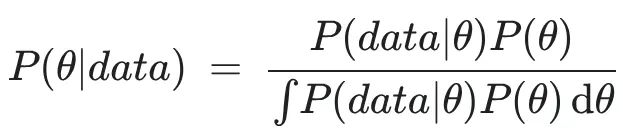
MMM 中的贝叶斯定理
这里的分母(证据)表示在所有可能的渠道效果、季节性和有机趋势组合下,看到实际销售数据的概率。
为什么选择 Meridian 而不是其他 MMM 框架
现在我们对贝叶斯定理更加熟悉了,我们可以定义关于 Meridian 设计回答的问题类型的先验期望。在实践中,这些通常包括:
- 每个营销渠道对收入或其他 KPI 有什么贡献?
- 广告支出回报率(ROAS)是多少?
- 我应该如何分配未来的营销预算以最大化影响力?
- 每个营销渠道的收益递减从哪里开始?
使用 Meridian,我们将能够回答所有这些问题以及更多问题。以下是该框架的一些关键特性:
- 适用于本地、区域和国家数据:在区域或城市级别分析营销表现,而不仅仅是在国家层面。
- 关于渠道表现的先验知识:你可以包含你已经知道的营销信息,例如过去实验的结果。
- 考虑收益递减和延迟效应:使用参数化转换函数对付费和有机媒体的饱和度和滞后效应进行建模。
- 支持覆盖范围和频率数据:除了展示次数,Meridian 还可以利用覆盖范围和频率来深入了解曝光如何影响表现。
- 优化营销预算:你可以根据总预算确定跨渠道的最优预算分配。
- 运行"假设"场景:你可以模拟不同的营销策略,例如重新分配支出,并估算在这些场景下 ROI 会如何变化。
- 评估模型质量:你可以评估模型对历史数据的拟合程度以及它在未见数据上的表现。
- 包括非媒体和有机因素:你可以选择性地包括价格变化或促销等因素。
在下一章中,我们将看到如何使用包含有机和付费渠道的数据框来训练模型。
2、如何训练 Meridian MMM
在训练数据之前,首先要解决的问题是决定使用哪种时间粒度更有意义:每日、每周还是每月。
使用每日数据训练 MMM 不仅会花费大量时间,尤其是考虑数年的数据,而且可能导致过拟合,而每月或每季度粒度会删除大量关于季节性和趋势的信息,导致欠拟合。
因此,每周粒度是最佳方法,但这也取决于数据集中特征的数量以及拥有的数据点数量。根据几篇文章,营销组合模型中有一条经验法则:每个特征应该有 10 个数据点(行)。因此,如果你使用例如 2 年的数据(约 104 周)和数据集中有 10 个特征,建议使用每周粒度。
在本文中,我们将使用 3 年的信息工作,因此我将数据按周级别分组,但我还添加了关于月份和季度的信息,因为这有助于将真实的营销效果与季节性和趋势分离开来。
我们现在将训练上述数据集,其中包括媒体支出、非支出和有机渠道。
3、安装和设置 Meridian
训练数据最简单、最快速的方法是使用带有远程 GPU 的 Google Colab 笔记本。为此,你需要打开一个笔记本,在右上角将运行时类型更改为T4 GPU。
将运行时类型更改为 T4 GPU
现在,在你的笔记本的第一个单元格中,你可以连接到 Google Drive 以直接从那里存储和获取数据。
from google.colab import drive
drive.mount('/content/drive')
要安装 Meridian,你可以运行这个 pip 命令:
!pip install --upgrade google-meridian[colab,and-cuda]
安装完成后,我们可以开始按照以下方式构建数据集的特征:
MEDIA = [
"instagram_impressions",
"x_impressions",
"google_clicks",
"tik_tok_impressions",
"facebook_impressions"]
MEDIA_SPEND = [
'instagram_spend',
'x_spend',
'google_spend',
'tik_tok_spend',
'facebook_spend']
ORGANIC_COLS = [
'direct_sessions',
'organic_impressions',
]
CONTROL_COLS = ['week', 'month', 'quarter', 'year']
mapping_media_spend = {
'instagram_spend': 'Instagram',
'x_spend': 'X',
'google_spend': 'Google',
'tik_tok_spend': 'Tik Tok',
'facebook_spend': 'Facebook'
}
mapping_media = {
"instagram_impressions": "Instagram",
"x_impressions": "X",
"google_clicks": "Google",
"tik_tok_impressions": "Tik Tok",
"facebook_impressions": "Facebook"
}
MEDIA 列表包含用户活动,如展示次数和点击次数。MEDIA_SPEND 列表包含相同的渠道,但侧重于支出。MEDIA_SPEND 和 MEDIA 通过 mapping_media_spend 和 mapping_media 链接,因此确保两个字典都有列值。ORGANIC_COLS 列表包含不需要支出的特征。CONTROL_COLS 是所有与时间相关的列。
我们可以使用上述列表和字典为模型创建映射对象:
from meridian.data import load
coord_to_columns = load.CoordToColumns(
time='week',
controls=CONTROL_COLS,
kpi='revenue',
media=MEDIA,
media_spend=MEDIA_SPEND,
organic_media=ORGANIC_COLS
)
KPI 是你试图预测的内容(目标),在我们的案例中是收入。
4、创建先验
现在到了营销组合模型步骤中最棘手的部分,即创建先验。正如我们之前看到的,先验就像后验一样,是分布,它们代表你在模型"看到"数据之前提供给模型的信息。
先验可以来自多个来源,包括过去实验的结果、行业基准、之前的 MMM 结果以及你团队的领域专业知识。在本教程中,我们没有关于数据的先前信息,因此我们将使用 Meridian 提供的默认先验。
你可以在此处阅读更多关于先验(信念)的信息。
要计算默认先验,我们将使用 Meridian 库中的 PriorDistribution 对象。此外,我们将使用 tensorflow_probability 包来创建分布。
pip install tensorflow-probability
我们不会对默认输入值进行任何修改,但我仍然会显示它们并添加注释,以便你更好地理解它们:
import tensorflow_probability as tfp
from meridian.model import spec, prior_distribution
prior = prior_distribution.PriorDistribution(
# LogNormal 使用是因为 ROI 必须为正数。
# 这些是 Meridian 在不存在先验知识时推荐的默认值。
roi_m=tfp.distributions.LogNormal(
loc=0.2, # log-mean
scale=0.9 # log-std(相当宽 -> 信息较弱)
),
roi_rf=tfp.distributions.LogNormal(
loc=0.2,
scale=0.9
),
# 有机媒体使用贡献先验。
# Beta(1, 99) 意味着每个渠道的预期贡献较小,
contribution_om=tfp.distributions.Beta(
concentration1=1.0,
concentration0=99.0
),
contribution_orf=tfp.distributions.Beta(
concentration1=1.0,
concentration0=99.0
),
)
默认值在我们对数据没有任何线索时最灵活,但可以相应地调整它们。模型规范将如下所示:
from meridian.model import spec
model_spec = spec.ModelSpec(
# 付费媒体使用 ROI 先验建模
media_prior_type="roi",
# 有机媒体使用贡献先验建模
organic_media_prior_type="contribution",
# 附加先验配置
prior=prior,
)
5、加载和训练
现在我们可以创建 loader 对象,该对象接受之前为所有付费和有机渠道创建的坐标和映射:
from meridian.data import load
loader = load.DataFrameDataLoader(
df=df,
kpi_type='revenue',
coord_to_columns=coord_to_columns,
media_to_channel=mapping_media ,
media_spend_to_channel=mapping_media_spend
)
data = loader.load()
有了 loader 和 model_spec,我们准备好实例化模型:
from meridian.model import model
mmm = model.Meridian(input_data=data, model_spec=model_spec)
由于 Meridian 基于贝叶斯模型,要训练它,我们需要使用马尔可夫链蒙特卡洛(MCMC)从后验分布中采样。
# 初始化并运行模型
mmm.sample_prior(500)
# 采样后验分布
# 这是"从数据中学习"的步骤
mmm.sample_posterior(
n_chains=4, # 并行采样链的数量(建议 4-7 条)
n_adapt=500, # 调整采样器的自适应步骤
n_burnin=500, # 要丢弃的"预热"样本
n_keep=1000, # 为结果保留的实际样本
seed=101 # 用于可重现性
)
运行上述单元格后(可能需要一些时间),确保将模型保存为 pkl 文件,这样你就不需要再次运行它:
model.save_mmm(mmm, "/content/drive/MyDrive/mmm_model.pkl")
6、从 Meridian 模型获取见解
就是这样,你等待了几分钟,现在是时候看一些结果了!
如果你保存了模型,我们可以做的第一件事是在另一个空笔记本中加载它:
mmm = model.load_mmm("/content/drive/MyDrive/mmm_model.pkl")
让我们看看我们的模型对数据的拟合程度:
from meridian.analysis import visualizer
model_diagnostics = visualizer.ModelDiagnostics(mmm)
model_diagnostics.predictive_accuracy_table()
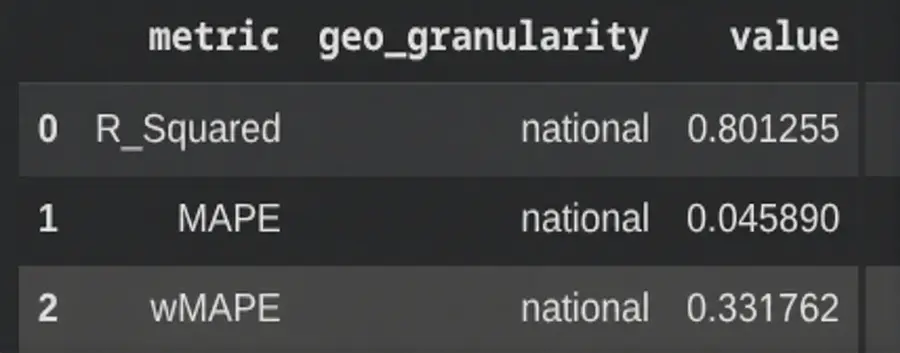
模型指标
在我们的案例中,R-squared 为 0.8。这个值越高,模型拟合越好。但是,过高的值也可能表明过拟合。
在图表方面,有几个选项。我们可以查看的第一个图表是总支出与贡献的对比:
media_summary = visualizer.MediaSummary(mmm)
media_summary.plot_spend_vs_contribution()
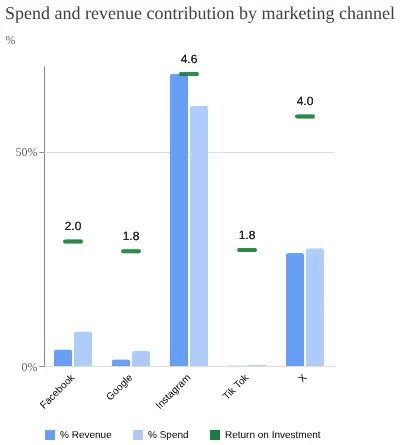
广告支出回报率(ROAS)柱状图
上述图表仅考虑付费营销渠道。其中,Instagram 显示最高的 ROI 或 ROAS,但这也是支出最高的渠道。另一方面,X 不需要投入太多资金就能产生高 ROI。其余渠道显示出相对积极的 ROI,表明有扩大的潜力。
现在,要获取贡献,让我们使用瀑布图。
media_summary.plot_contribution_waterfall_chart()
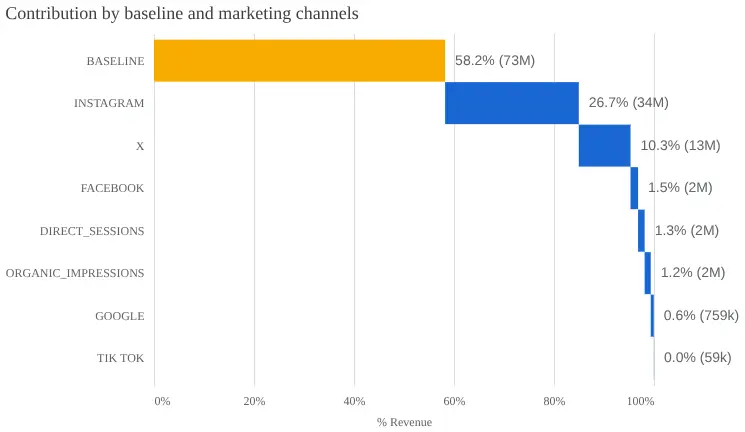
渠道贡献
此图表说明了总收入如何在有机和付费营销渠道之间分配。在此图表中,基线驱动最多,意味着 58.2% 的收入不是由渠道驱动,而是由季节性和其他来源驱动。Instagram 是主导媒体贡献者,占总收入的 26.7%,其次是 X,占 10.3%。有机渠道对该数据样本的影响非常小。
7、结束语
我们可以继续生成其他图表,如广告衰减或收益递减。Meridian 提供多种可视化,但这里的主要目标是演示如何创建和微调模型,同时展示 MMM 可以提供的一些示例。
虽然 Meridian 包括几个内置图表,但你还可以提取驱动这些图表的数据框,并使用它们构建自己的自定义图表和仪表板。
Meridian 是一个非常强大的开源模型,正如你所见,它显著简化了营销组合建模过程,不需要对复杂数学或统计函数有深入的了解。
如果你是想要避免依赖 Cookie 的营销人员或数据科学家,使用 Meridian 或任何其他 MMM 框架是正确的选择。
原文链接: How to Create a Marketing Mix Model with Google's Meridian
汇智网翻译整理,转载请标明出处