DiffusionGemma 图解
DiffusionGemma让我特别兴奋,因为它采用了一种不同的文本生成方式,同时利用了我们现有"常规"大语言模型的许多优秀特性。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
继 Gemma 4 12B 发布之后,我又可以向大家介绍另一个创新模型了,那就是 DiffusionGemma!
这个模型让我特别兴奋,因为它采用了一种不同的文本生成方式,同时利用了我们现有"常规"大语言模型的许多优秀特性。我们将探讨旧方法、新方法,以及它们如何并存。
在这篇指南中,我将涉及很多内容,因为 DiffusionGemma 有太多特别之处!你将了解更多关于扩散的一般知识、它在离散文本中的工作方式、DiffusionGemma 的架构以及所有有趣的技术细节。
准备好,这将是一个有趣的探索 ;)
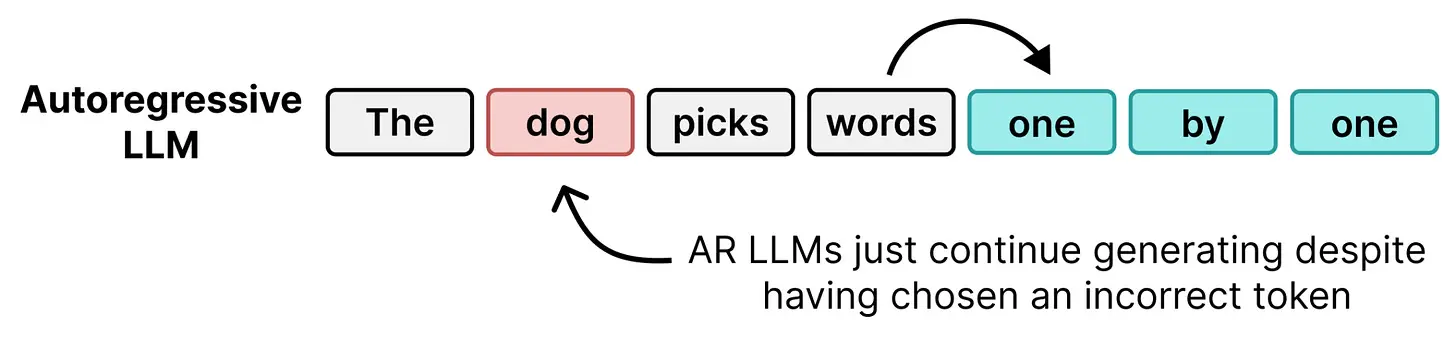
1、自回归模型的问题
自回归大语言模型一次生成一个 token,非常适合同时为多个用户服务。为什么?因为为单个用户生成单个 token 的计算成本出奇地低。在每个步骤中,生成 token 所需时间的很大一部分用于从内存中加载权重,而不是实际的计算。
在解码过程中,这些常规 Transformer 模型是内存受限的,而非计算受限的。这意味着,例如,为一个用户生成一个 token 的时间与为 256 个用户生成的时间是相同的。
原因是权重每步只需从内存加载一次,无论正在服务多少用户。这意味着无论我们将这些权重与 1 个用户的向量相乘,还是与 256 个用户的向量相乘,将权重移入内存的成本保持不变。通过将所有用户批处理在一起,我们几乎以相同的成本获得了相同数量的工作。
不过这不是免费的午餐,超过某个点(取决于芯片本身),LLM 可能服务太多用户而缺乏计算能力。你可以用屋顶线图(roofline plot)来可视化这种权衡。它显示了增加芯片性能(生成一个 token 需要多长时间)与芯片内存(从内存加载数据的速度)之间的影响。
当只服务一个用户(batch size 为 1)时,LLM 是内存受限的,加载了大量权重而没有做太多计算。随着我们增加 batch size(相同的内存负载但更多计算),你会接近一个"骑行点",硬件被充分利用。
因此,虽然批处理非常适合同时服务多个用户,但对单个用户来说没有任何好处!它仍然以相同的速度接收 token。延迟没有区别。
DiffusionGemma 颠覆了这个剧本。
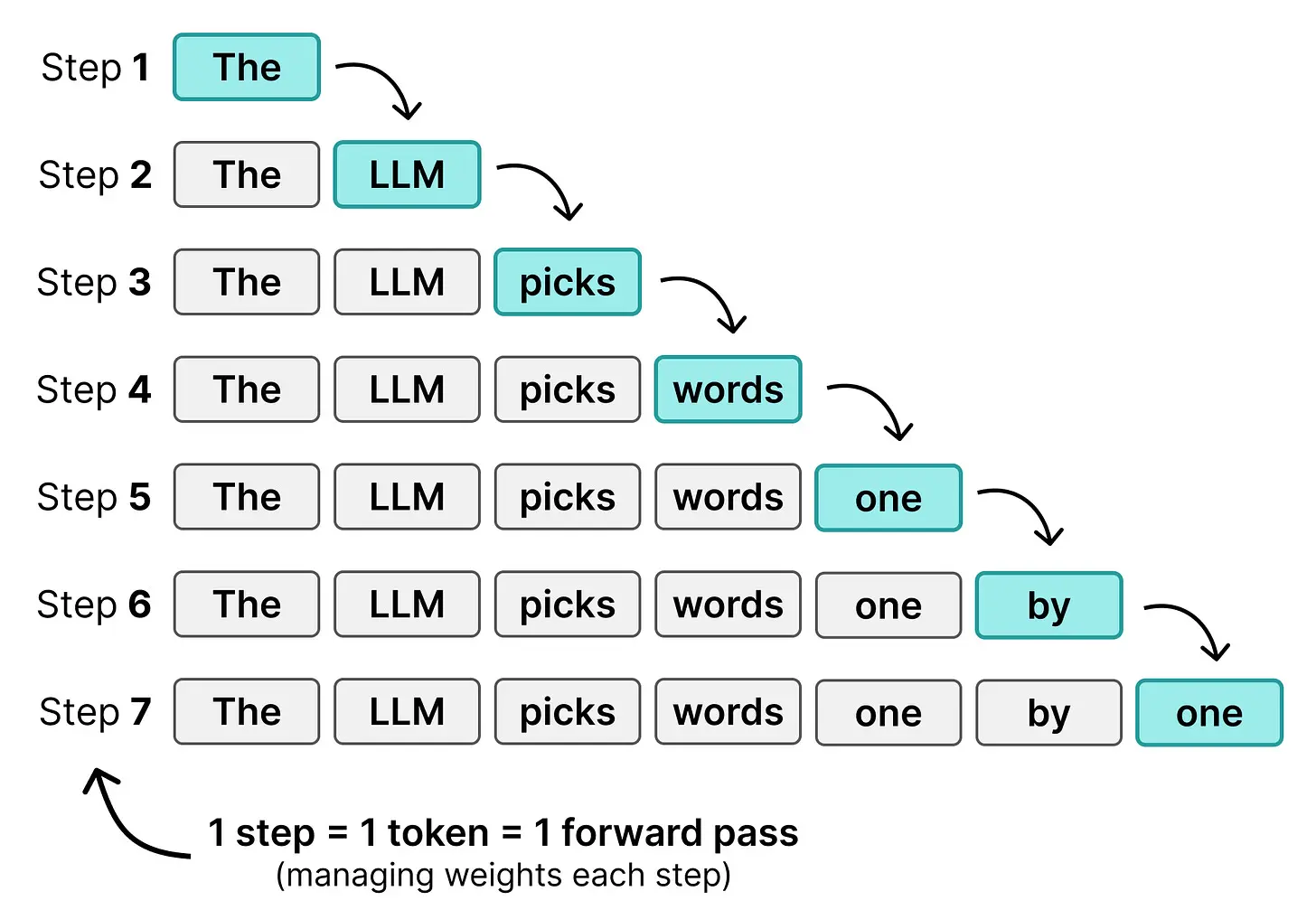
如果我们把计算的空闲时间用于单个用户呢?与其为 256 个用户各生成 1 个 token,不如为 1 个用户一次生成 256 个 token?
这就是 DiffusionGemma 的核心思想!模型从 256 个随机初始化的 token 序列(称为画布)开始,尝试同时为整个画布选择更好的 token。通过同时预测 256 个 token,256 个 token 的计算预算现在集中在一个用户上,而不是分散在多个用户上。
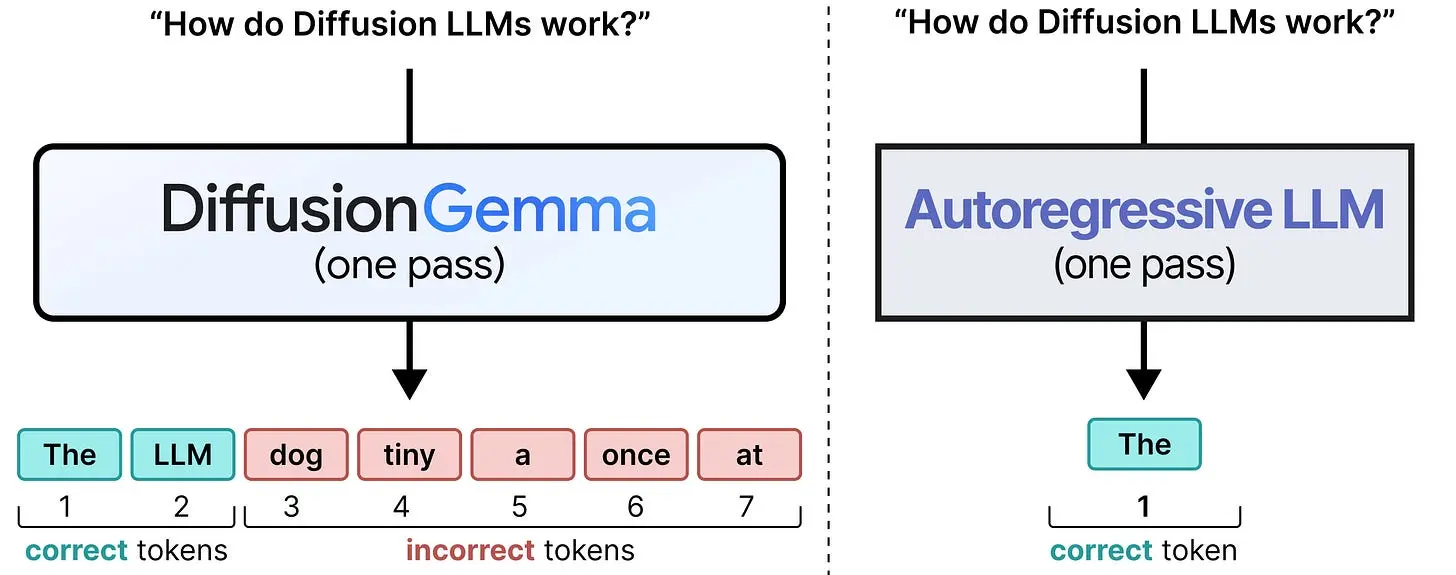
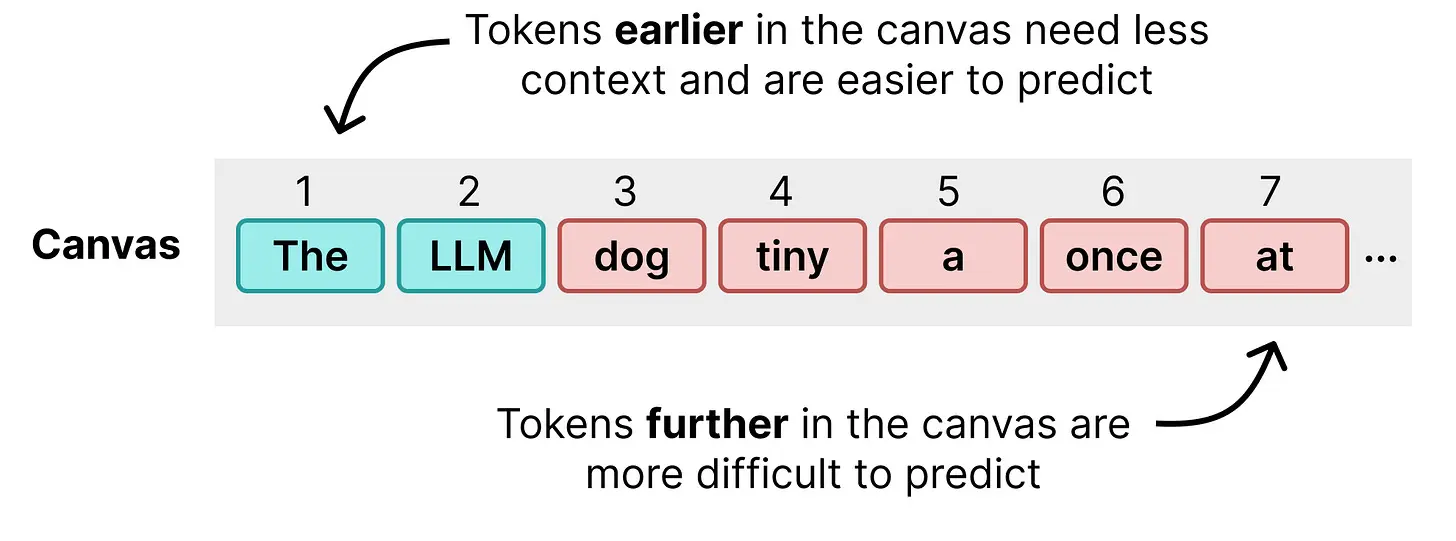
当然,一次预测这么多 token 是非常困难的,模型很难在不知道前面 token 是什么的情况下预测 token 254。注意前两个 token 很好,但慢慢开始输出无意义的内容。DiffusionGemma 对画布的第一次处理倾向于在画布开头生成相当准确的 token,但在末尾生成较差的 token。
那么与其只做一次处理,如果我们简单地执行多次处理会怎样?
这就是迭代优化(iterative refinement)的用武之地。模型使用其之前的预测对画布进行又一次处理。正确的 token(那些仍然具有高概率的)帮助模型对画布更远的位置做出更好的猜测。每次处理,模型都会改进之前概率较低或被不准确 token 包围的 token。经过多次迭代后,画布收敛到与常规 Transformer 模型相似质量的文本,但对单个用户来说快得多。主要原因在于模型的前向传播次数远少于它生成的 token 数。

看,我们刚刚从常规 Transformer 模型的逐 token 预测变成了同时处理 256 个 token!
虽然两者都使用多个步骤来生成输出,但常规 Transformer 每个 token 使用一个步骤,而 DiffusionGemma 每个步骤都用来改进画布。使这成为可能的是一种叫做扩散(diffusion)的技术,该技术在图像生成领域变得流行。它与迭代优化的概念密切相关。
与模型是内存受限的(如自回归 LLM)不同,扩散 LLM 是计算受限的,当你添加更多计算时,它的扩展速度更快。
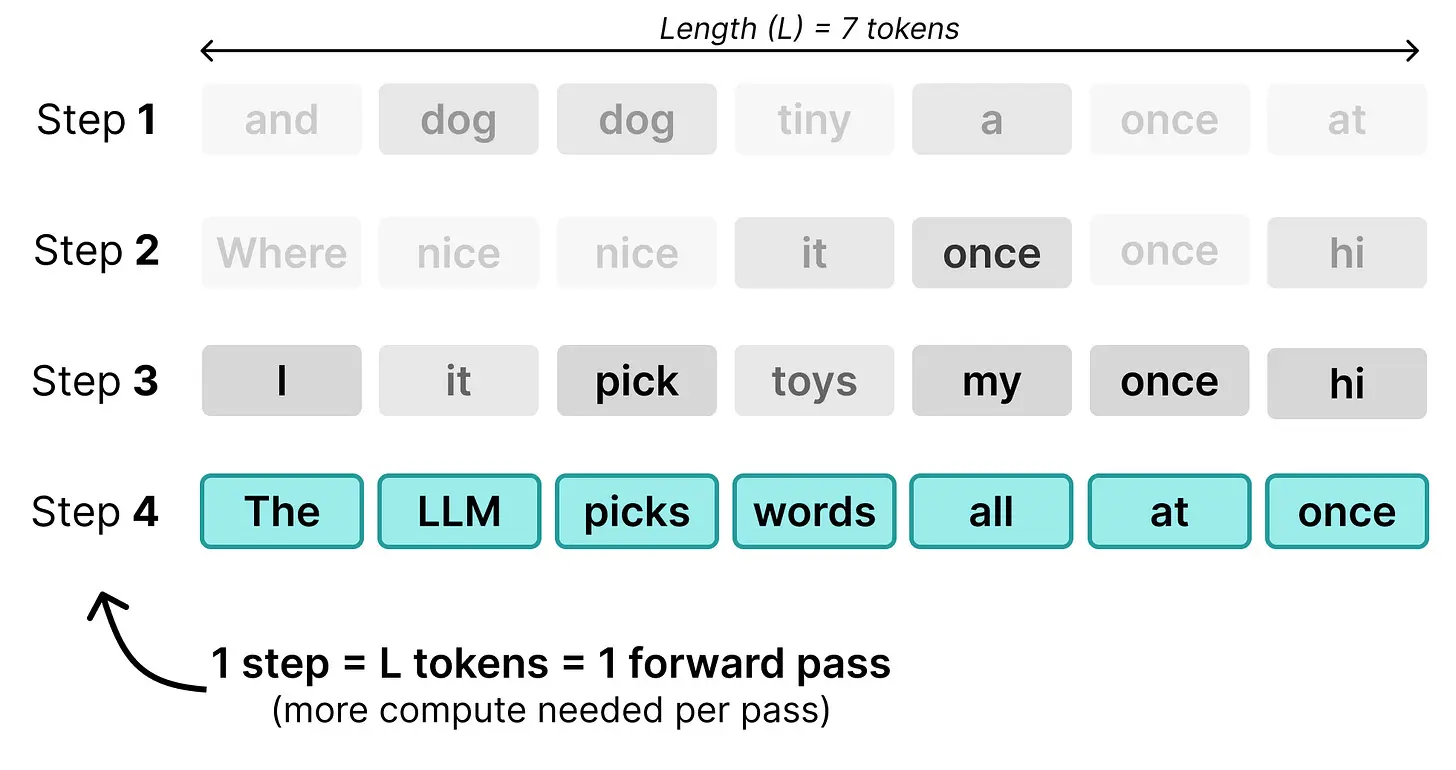
你得到的是自回归 LLM 和扩散 LLM 之间的主要区别,即它们处理相同 token 的方式不同。自回归 LLM 在每次前向传播中生成一个 token,在服务单个用户时是内存受限的,而扩散 LLM 在每次前向传播中生成一个 token 序列,是计算受限的。
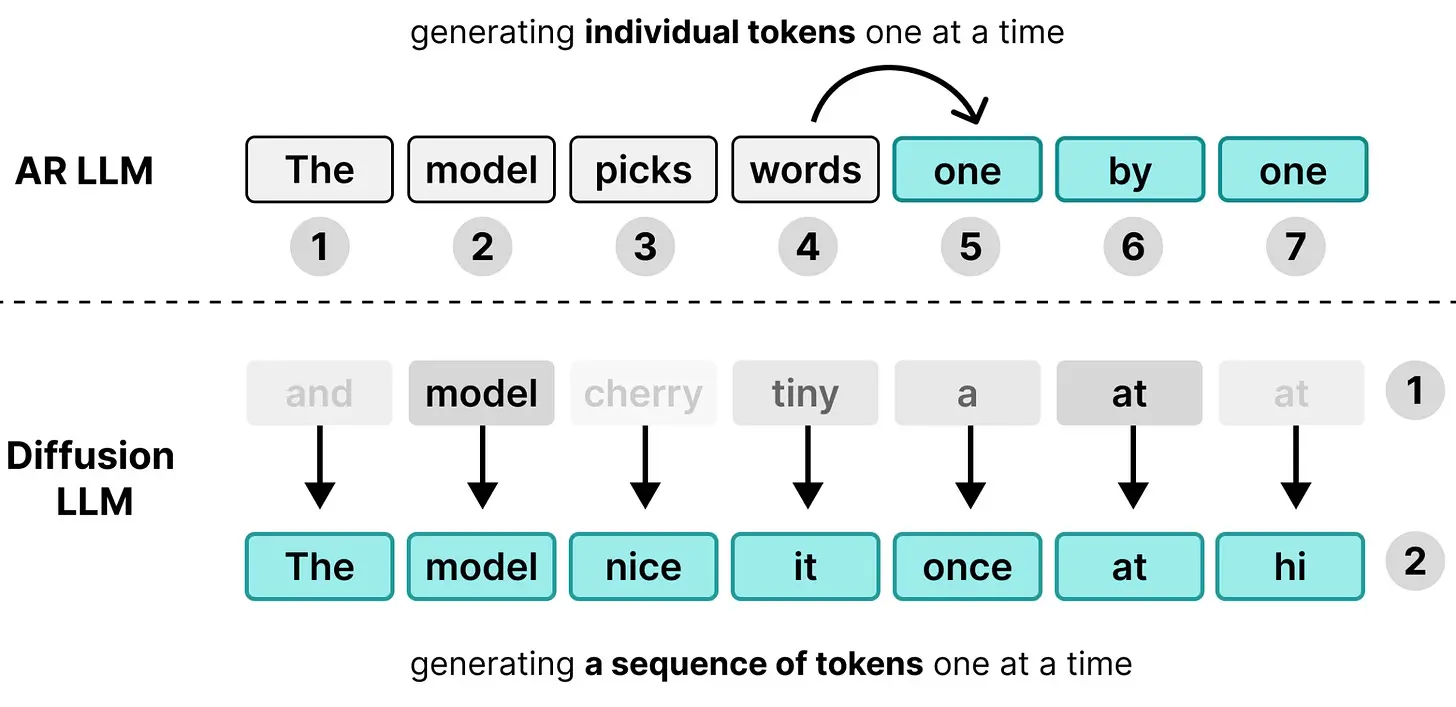
那么让我们更详细地探索扩散,以及 DiffusionGemma 如何将图像生成的原理应用到文本生成中。
什么是扩散?
扩散是图像生成中以"噪声"为中心的过程。
2、图像扩散
扩散是图像生成中以从图像中去除"噪声"为中心的过程。从一个随机初始化的图像(100%"噪声")开始,扩散尝试在每个后续步骤中减少噪声量。在图像生成中,这个过程由提示词引导。经过足够的步骤后,它最终会生成或"揭示"一张图像。
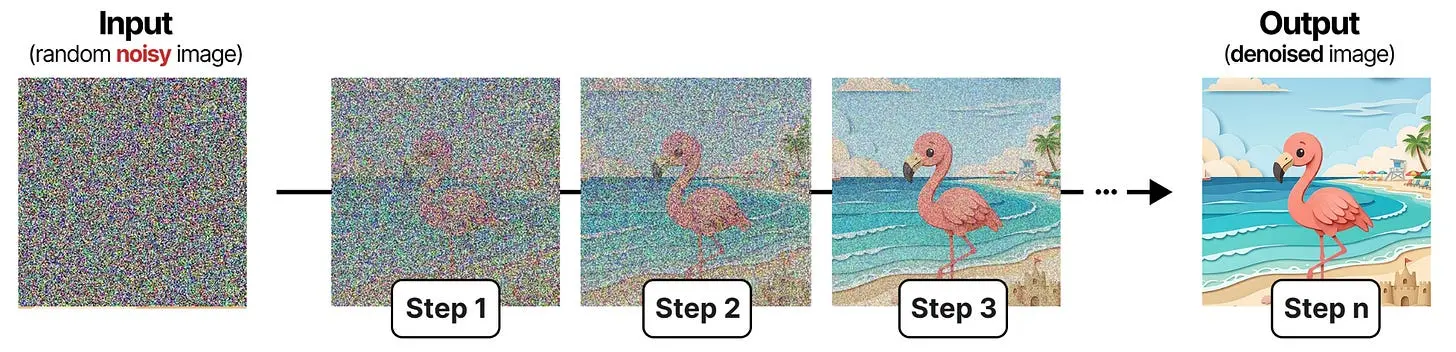
减少图像中噪声量的过程叫做去噪(denoising)。正如你从图中看到的那样,这是一个迭代和顺序的过程。每一步,你都能更清楚地看到图像,到最后,完整的图像就显示出来了。这个原理不仅是图像扩散的核心,你将看到,也是 DiffusionGemma 的核心。
这个去噪过程由两个主要原则引导:前向扩散(forward diffusion)和反向扩散(reverse diffusion)。
2.1 前向扩散
要让模型学习如何对图像进行去噪,你需要从一些训练数据开始。这些数据包含图像/文本对。对于每一对,你向图像添加一定量的随机(高斯)噪声。

这个过程叫做前向扩散。它从现有数据创建新数据,并为训练过程添加信号。
2.2 反向扩散
反向扩散则尝试训练模型来预测我们添加到初始数据中的噪声。这样训练数据就有了一个清晰的预测信号:噪声。你基本上是在告诉模型,这里是一张有噪声的图像,我只想让你从中预测噪声。
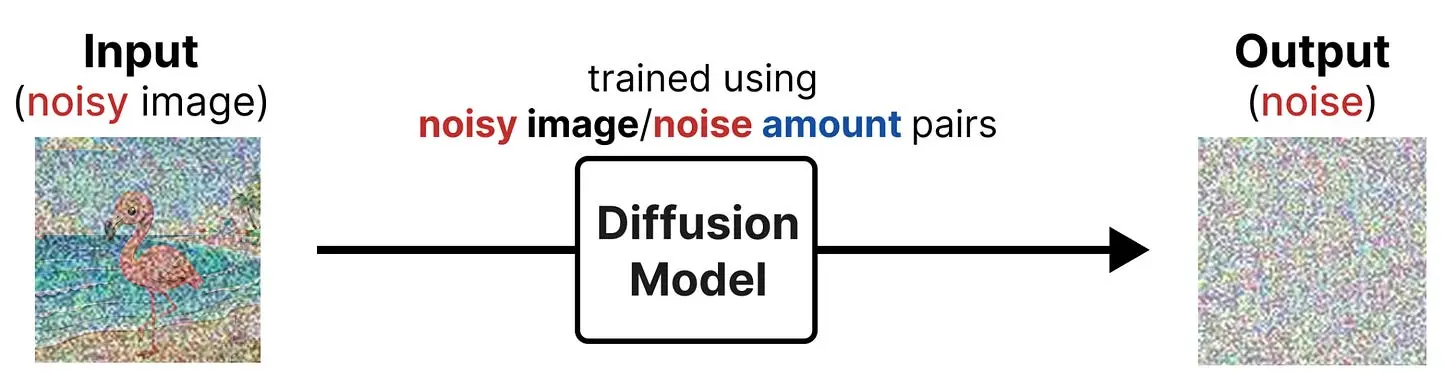
那么我们为什么要向图像中引入噪声然后尝试预测它呢?
因为我们可以从有噪声的图像中减去预测到的噪声,使其更接近模型训练时使用的图像。通过迭代地执行此操作,你可以从纯噪声开始,慢慢去噪,直到图像中没有噪声为止。
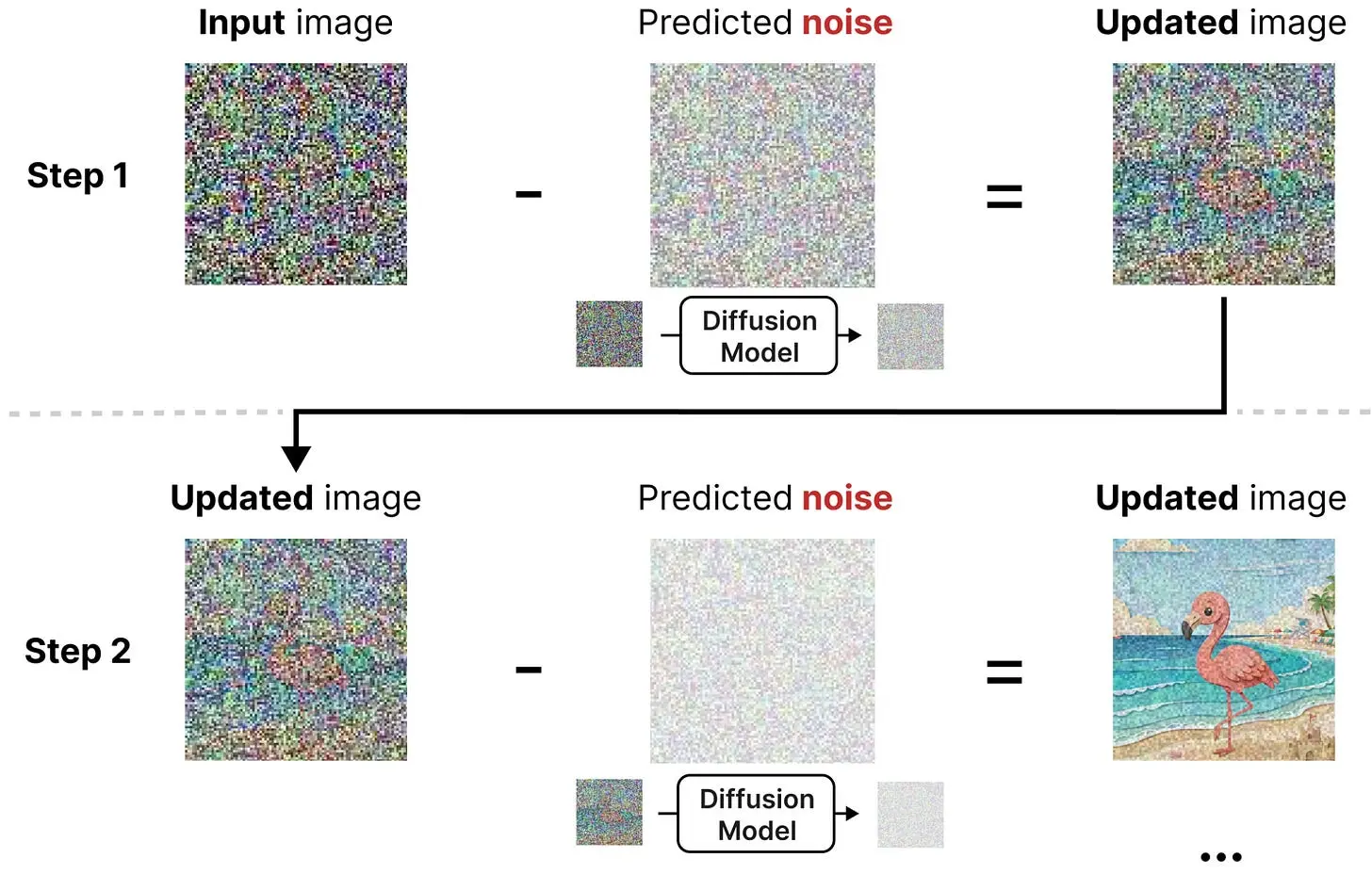
前向扩散(生成噪声训练数据)和反向扩散(对噪声输入数据进行去噪)共同创建了这个打破和修复图像的过程。

请注意,在图像扩散中,这个过程由提示词引导,它作为额外的信号来决定什么是什么不是噪声。没有引导它的东西,模型根本不知道它首先应该创建什么。
引导这个过程的东西叫做编码器,用于处理输入查询并理解其背后的语义含义。编码器的输出然后传递给扩散模型,使其被引导创建你查询中的图像。没有编码器,扩散模型将不知道从第一步接收到的 100% 噪声中创建什么。
它们共同创建了完整的流程,由两个主要架构组成:
- 去噪器 – 用于迭代地从噪声输入中去除噪声的模型(例如,扩散模型)。
- 编码器 – 用于处理输入查询的模型(例如,编码器语言模型)。
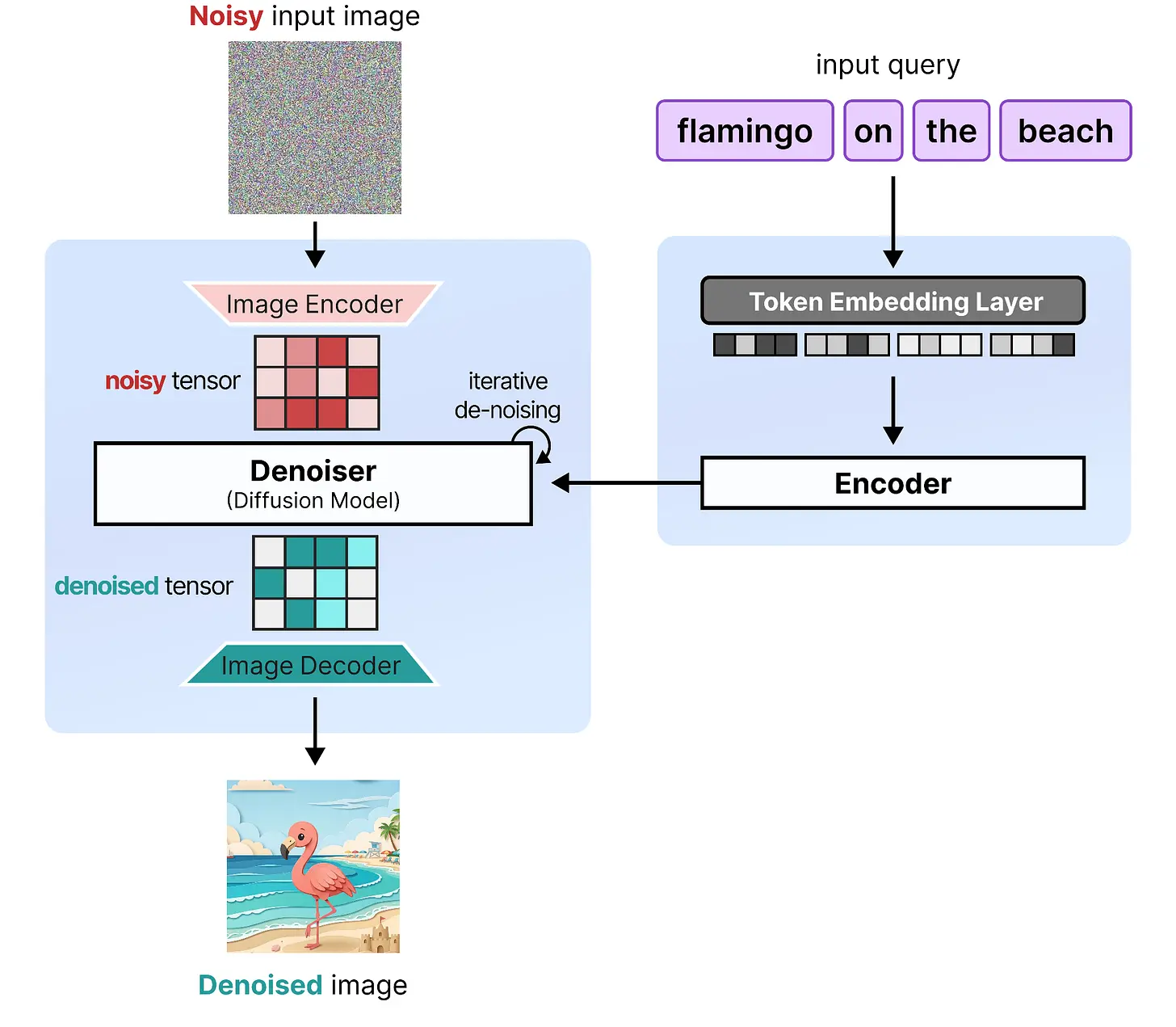
如前所示,扩散模型也被称为去噪器,因为它主要关注从噪声输入中去除噪声。我们将在全文中使用这个术语来展示模型的目的。
3、文本扩散
既然我们已经看到了图像的扩散,那如何将其转化为文本呢?对像素添加单独的噪声比较容易,因为它们是连续值。你可以让红色像素少一点红,多一点蓝。但是,你怎么让 token "The" 少一点 "The" 呢?什么构成单个 token 的"噪声"?
3.1 掩码扩散
与其将它们看作单个 token,不如考虑整体。在掩码语言建模中,就像训练 BERT 等编码器模型时做的那样,输入中的随机 token 被替换为 ** $\square$** token。我们可以将这个 $\square$ token 视为"噪声"(也称为损坏的 token)。
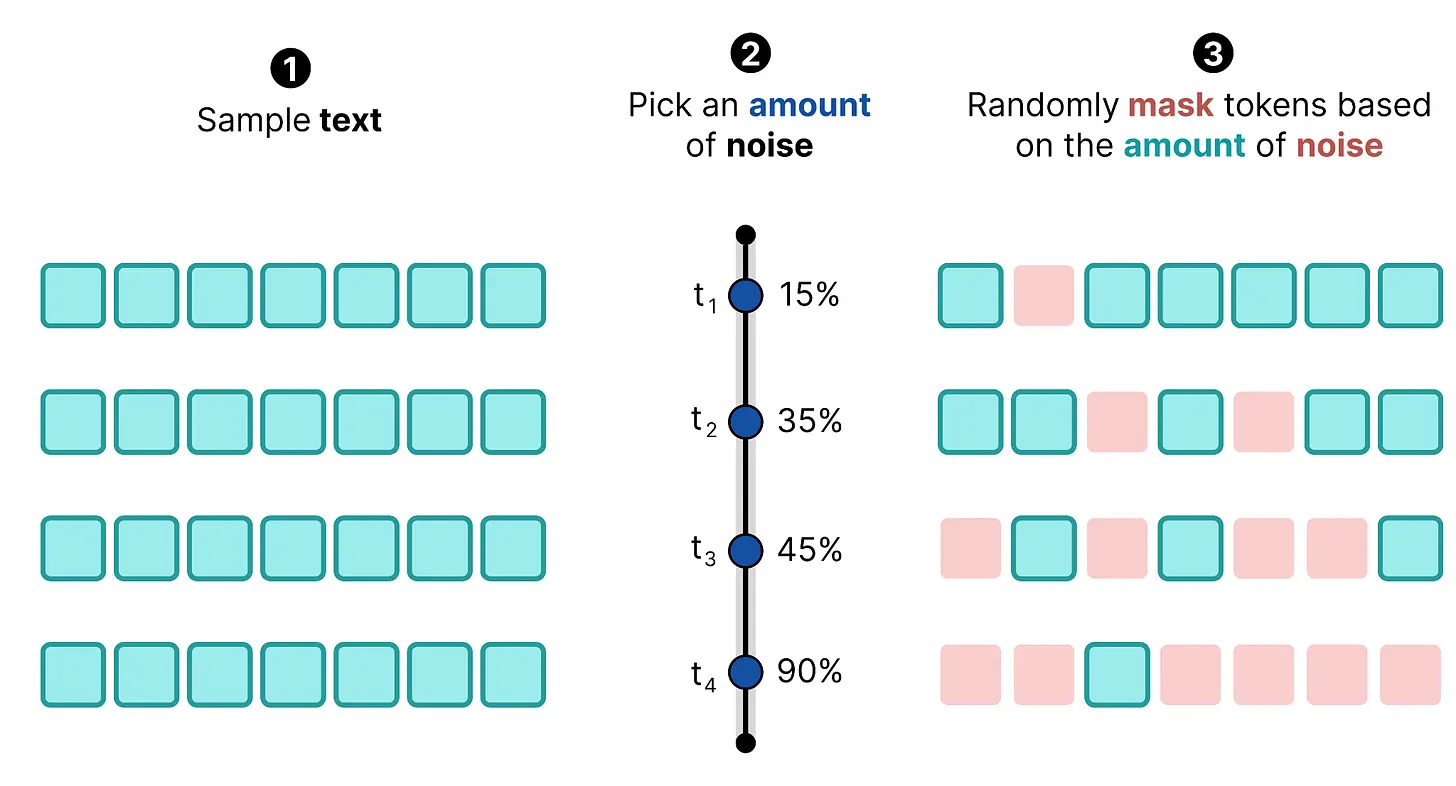
那么这个过程就类似于我们在图像扩散中看到的:你采样一段文本,选择一定量的噪声,并根据噪声量随机掩码 token。
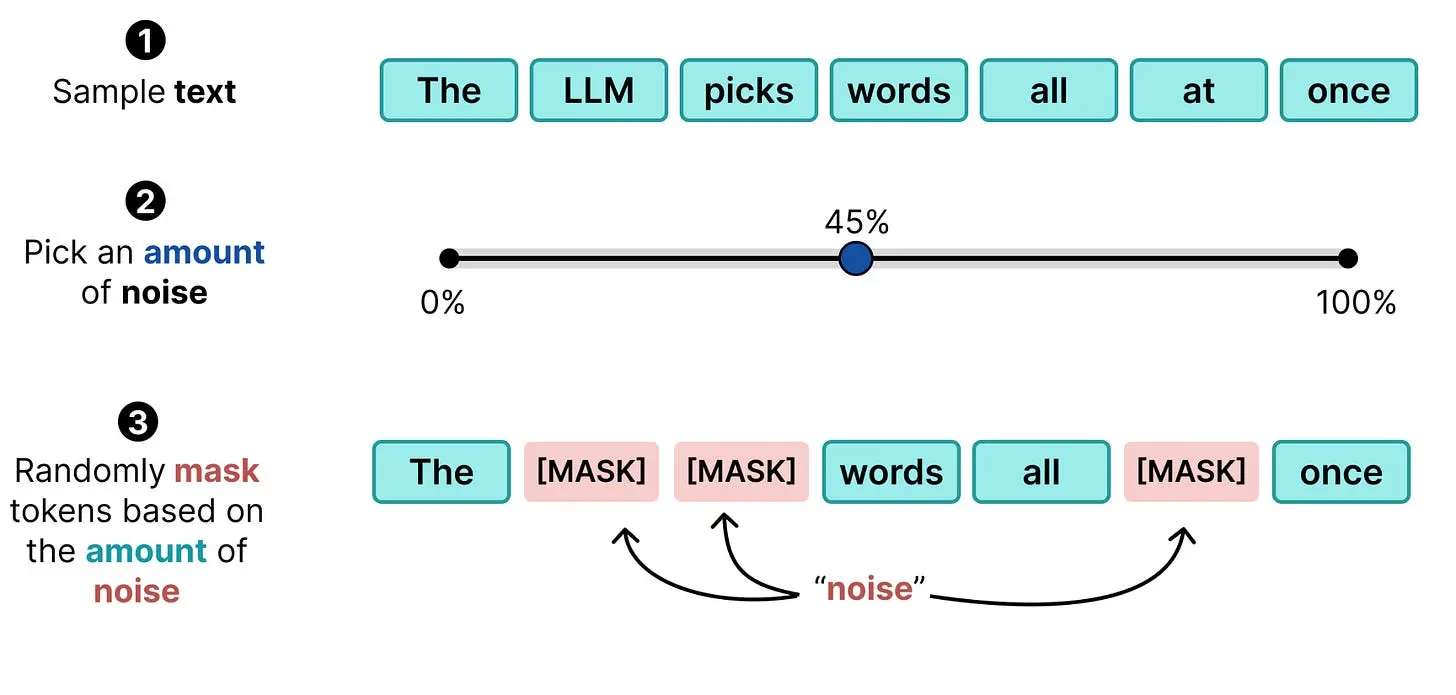
当我们多次执行此操作时,可以创建一个训练数据集。你采样相同的文本(或不同的文本)并添加不同量的噪声。这使模型能够学习如何对不同量的噪声进行去噪,就像图像扩散一样。
这个前向扩散过程之后是反向扩散,模型将预测 $\square$ 位置上正确的 token 应该是什么。在每个步骤中,模型只对它确信有良好替换的 token 进行去噪。
在单次去噪步骤中,模型预测画布中每个位置最可能的 token。然后,只有超过一定阈值的 token 才会被选中。未达到阈值的 token 将保持为掩码 token。
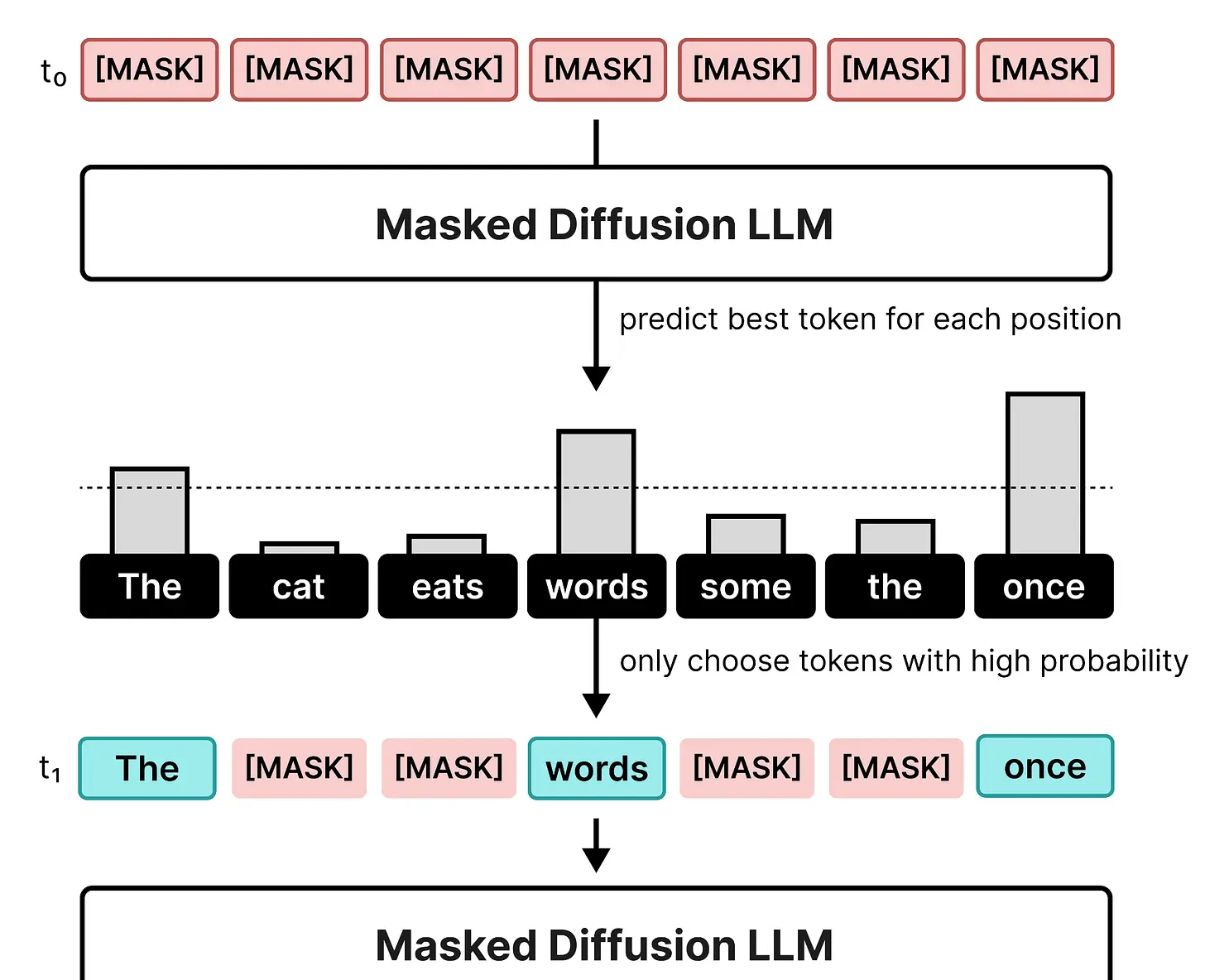
这个过程持续进行,直到所有掩码 token 被替换或达到一定数量的步骤。通常,使用的步骤越多,生成的序列越准确。它不一次性确定所有 token,而是使用多个步骤来决定哪些 token 应该放在哪里。
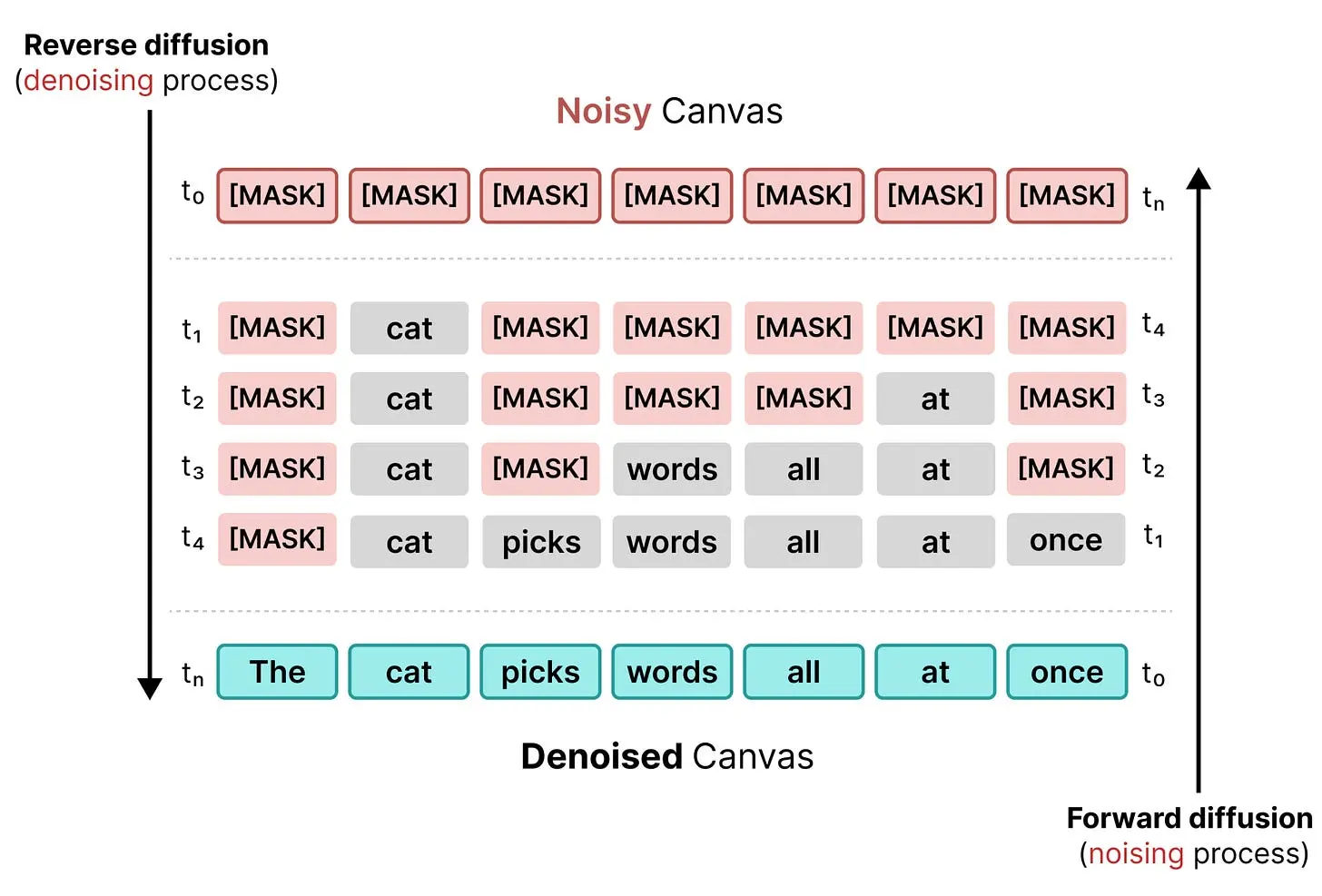
就像图像扩散一样,我们可以用一个图来可视化前向和反向掩码扩散过程:
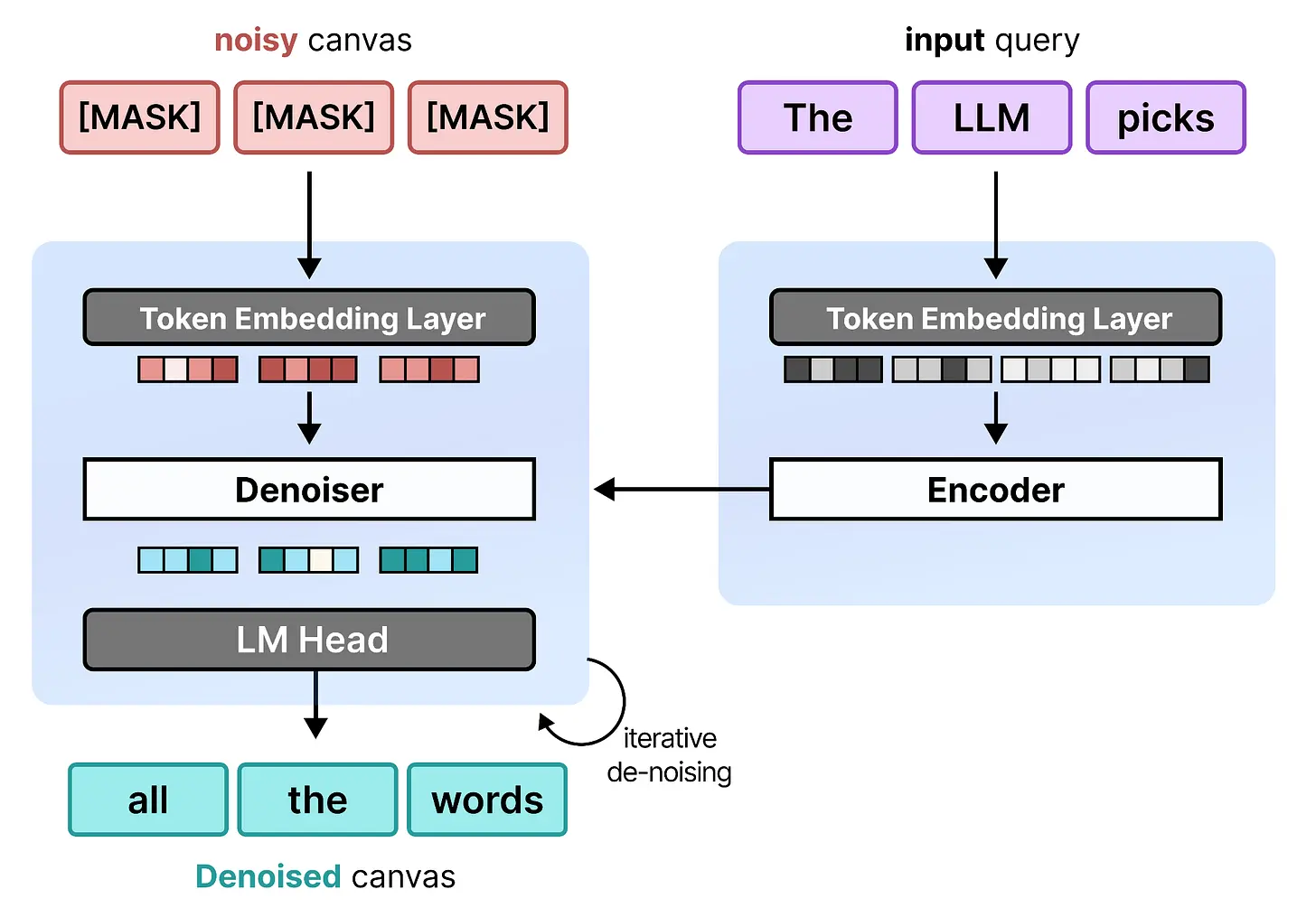
与图像扩散非常相似,文本扩散通常由两个模型(或两种技术)协同使用:
- 去噪器 – 用于迭代地从噪声输入中去除噪声的模型(更多内容在"DiffusionGemma 的架构"部分)
- 编码器 – 用于处理输入查询的模型(例如,编码器语言模型)。
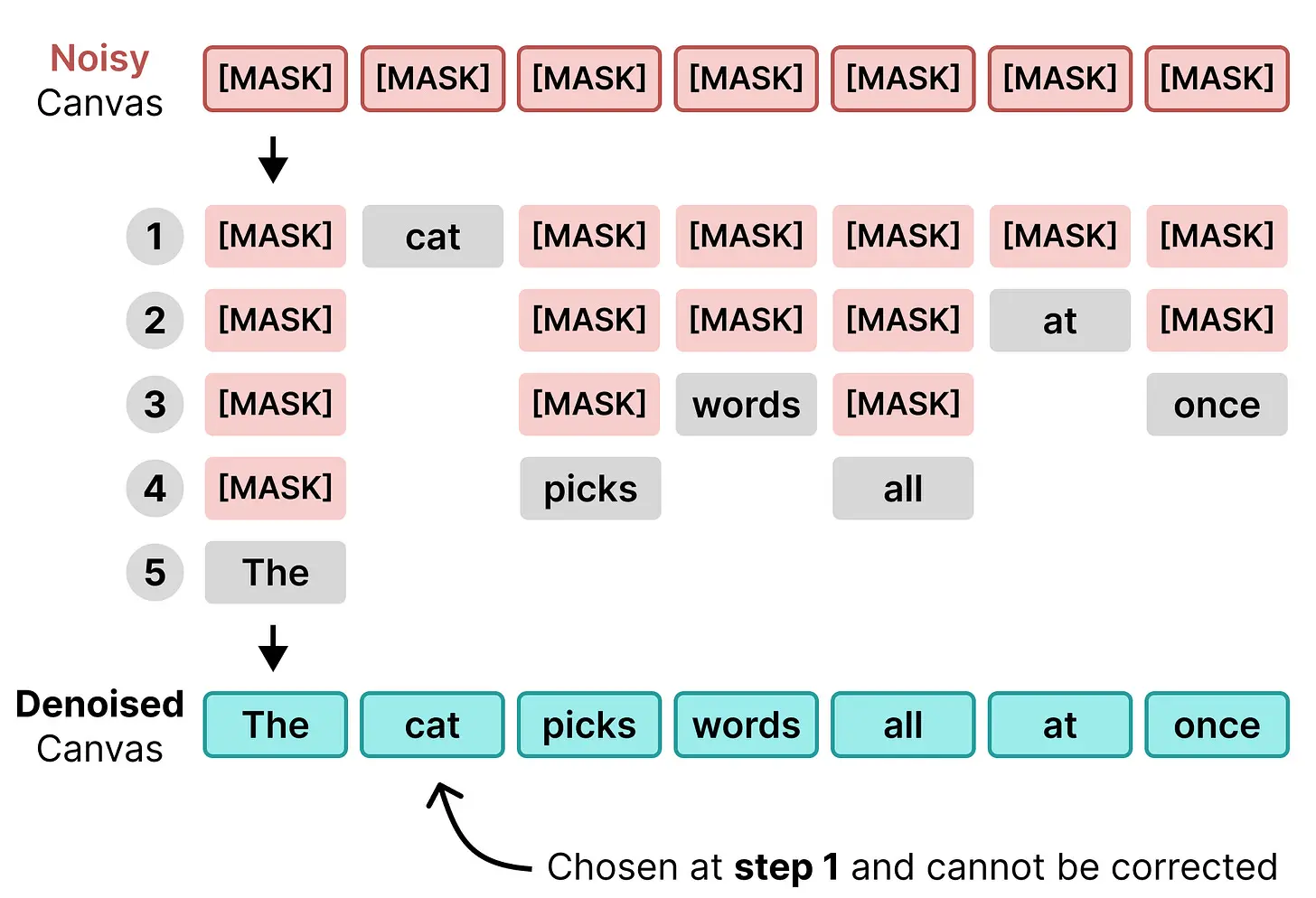
不过掩码扩散有一个问题,那就是自我纠正!每当模型决定替换一个 $\square$ token 时,它就被固定了。一旦被选中就不能再被替换。这阻碍了它纠正可能过早选择的某些 token 的能力。这实际上类似于自回归模型也选择一个 token 然后被"困在"选定的 token 上的行为。
那么,如果我们探索一种不同类型的"噪声"呢?
3.2 均匀状态扩散
使用 |MASK| token 是一种相当"严格"的噪声定义方式。它要么在那里,要么不在,没有中间状态。与图像扩散相比,这是一种相当"布尔式"的看待文本的方式。此外,当一个 token 被选中替换某个|MASK| token 后,它不能再被替换。
与其用相同的东西(一个 |MASK| token)替换 token 序列来损坏它,我们可以用不同的东西(一个随机 token)替换每个 token。在前向扩散过程中,随机 token 被用作噪声来创建数据集,就像掩码扩散一样。
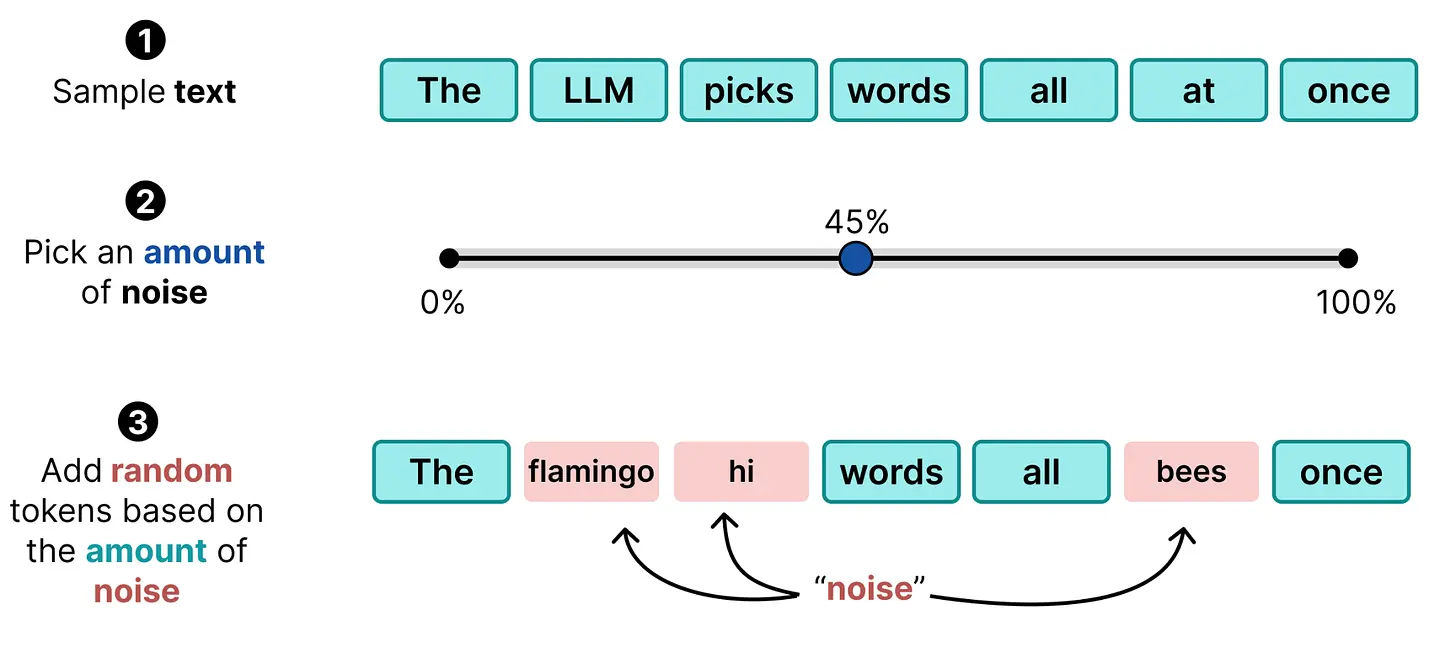
这个过程创建了一个带有噪声的数据集,但没有明确指出噪声在哪里(除了有真实标签外)。使这与掩码如此不同的是,模型必须自己弄清楚噪声来自哪里并相应调整。无论替换的词是 10% 还是 90%,都需要对输入有深入的理解。
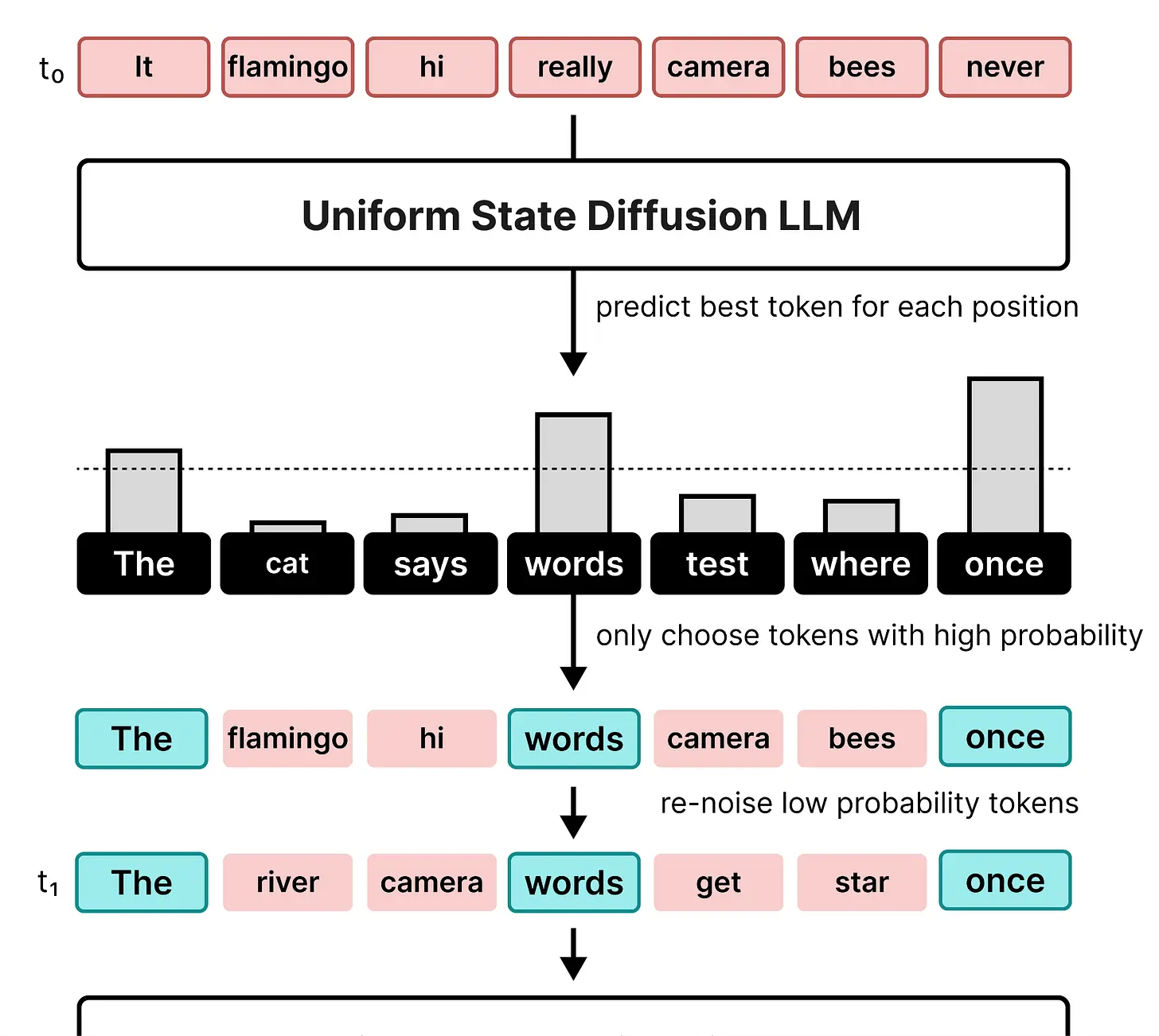
在去噪过程(反向扩散)中,模型必须检测哪些 token 是噪声,哪些应该被更新。在每个去噪步骤中,模型为画布中的每个位置预测一个 token。如果一个 token 不应该改变,它将保持高概率。然而,如果它决定替换该 token,则会生成另一个具有高概率的 token。因此,模型继续为每个位置预测最佳 token。这也意味着在前 10 步中可能获得高概率的 token 可能在第 11 步突然获得低概率,因为画布被更新了。
因此,在画布中的每个位置,模型以一定概率建议一个 token。如果达到某个阈值,它将被放在该位置。然而,如果未达到阈值,之前存在的 token 将被重新加噪并替换为随机 token。
那么为什么要对低概率 token 重新加噪呢?
如果你保留旧的 token,那它就不是一个均匀随机 token。模型在训练期间学到画布由按照均匀分布绘制的部分加噪 token 组成。保留旧的 token,模型可能在下一步围绕错误的 token 开始规划。为了保持接近训练数据,以及出于实际原因,你需要对低概率 token 重新加噪。
前向扩散(生成噪声文本序列)和反向扩散(对随机 token 进行去噪)共同创建了这个打破和修复 token 序列的过程。
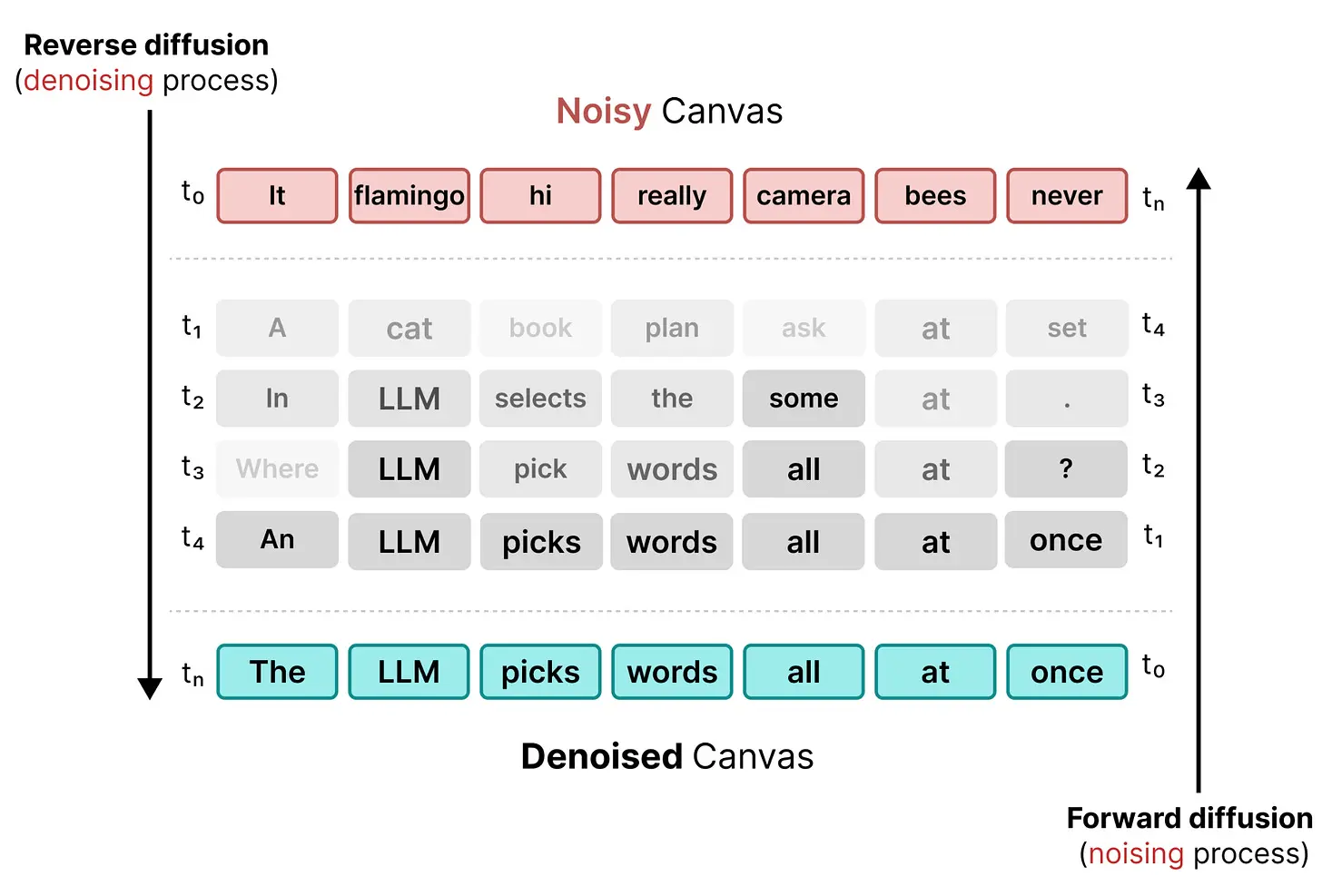
因此,模型在用一个 token 替换随机 token 后不会停止。它仍然可以改变画布中的任何 token。与掩码扩散相比,这允许模型在处理过程中持续更新和改变画布。

均匀状态扩散,以及基于文本的扩散,与自回归模型有很大不同。自回归是按顺序一次预测一个 token,而扩散则迭代地更新画布。自回归和扩散之间的差异在将它们并排放置时尤为明显。

这些差异很重要,因为它们帮助你理解什么时候选择文本扩散模型而不是自回归模型,反之亦然。虽然文本扩散模型在为单个用户生成许多 token 方面表现出色,但它们的多用户吞吐量低于自回归模型。因此,文本扩散也不是免费的午餐。以下是它们之间一些基本差异的概述:
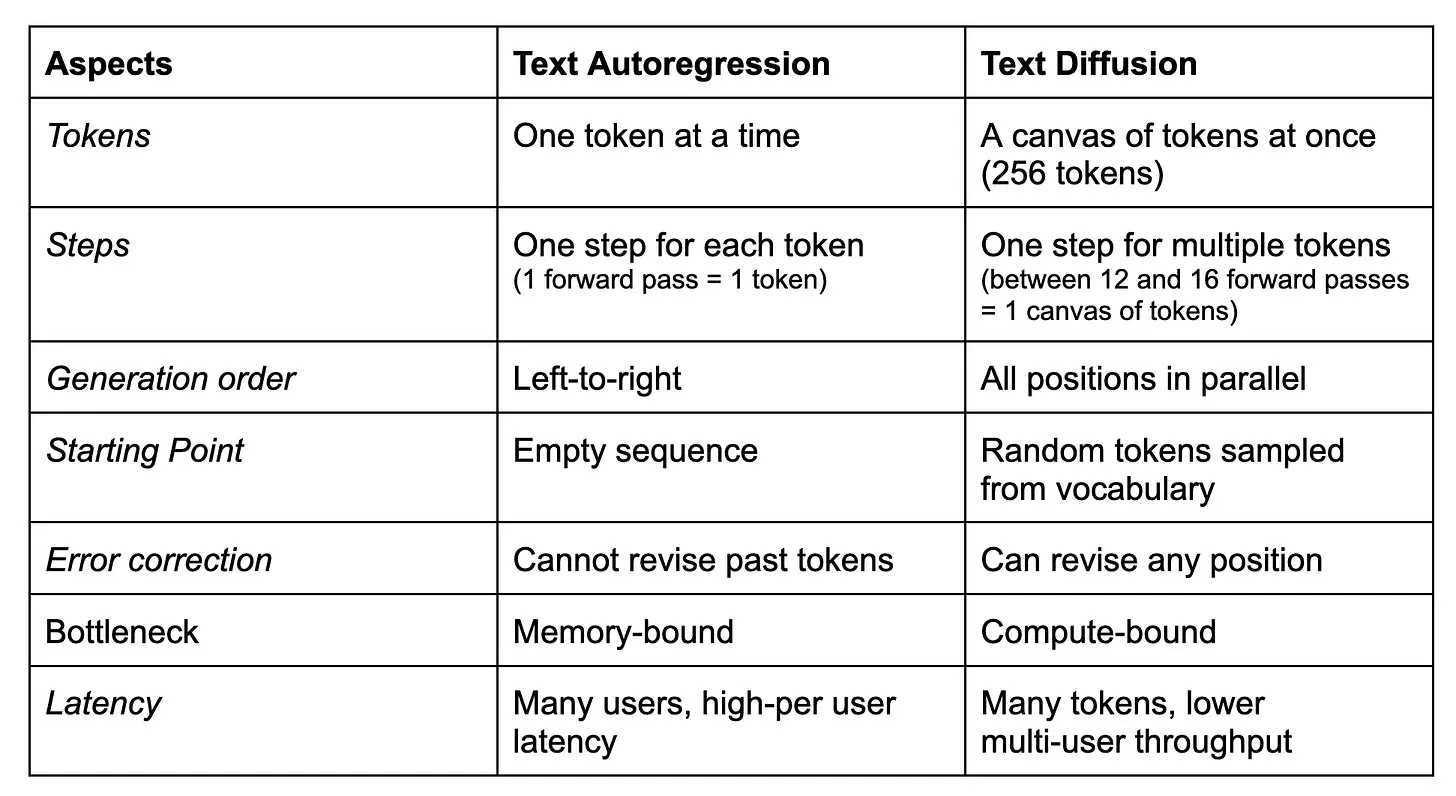
需要注意的是文本扩散的一个缺点,特别是均匀状态扩散,是它们很难训练。原因是训练目标不仅需要对各种噪声级别的画布进行去噪,还需要首先识别哪些 token 实际上是噪声。否则,它只会将画布中的所有 token 都视为噪声,这并不理想。
那么如何获得均匀状态扩散的好处而不受训练的缺点呢?让我们探索 DiffusionGemma 的编码器-解码器补丁中的解决方案!
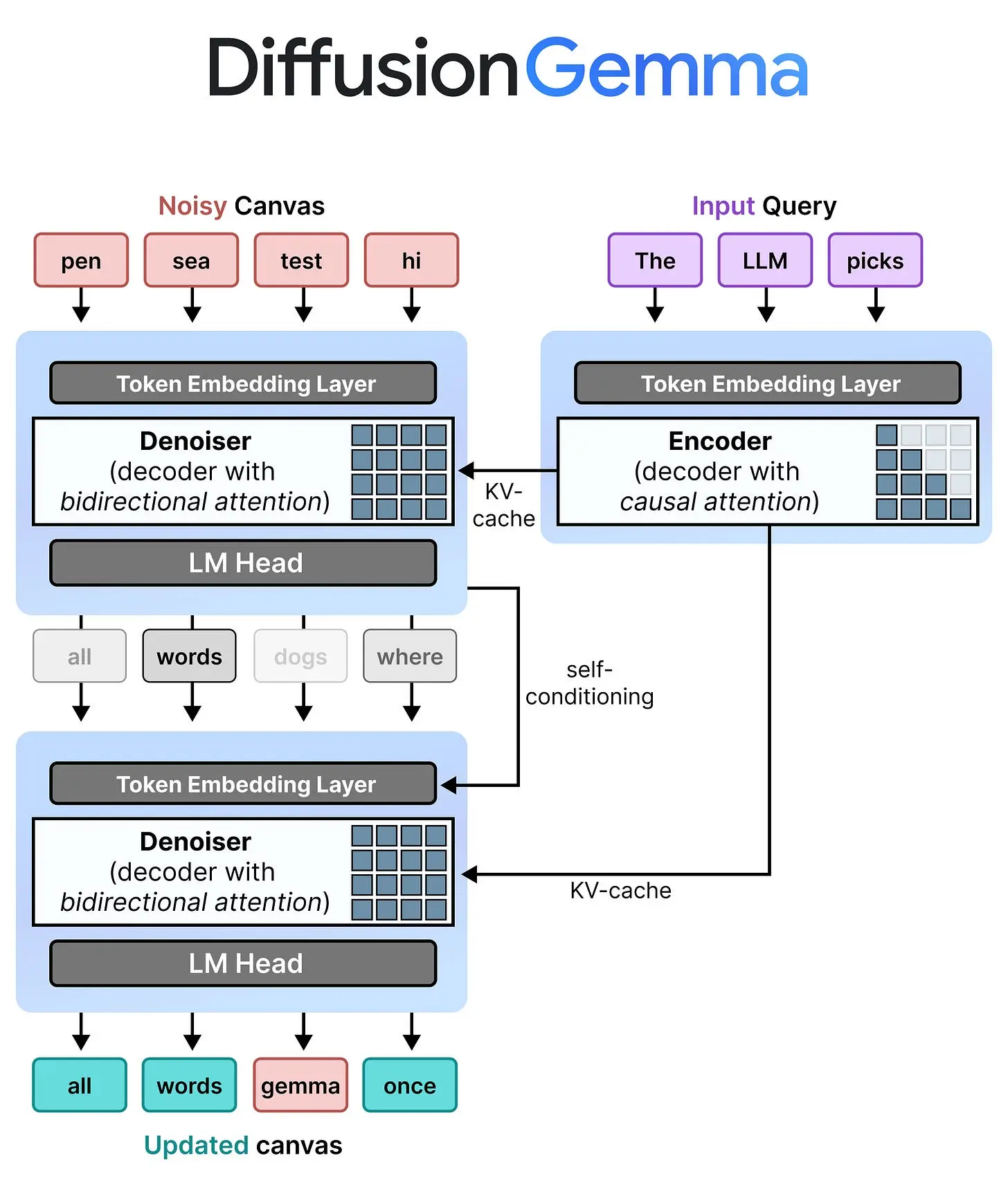
4、DiffusionGemma 的架构
DiffusionGemma 应用了我们迄今为止探讨的均匀状态扩散。然而,完全从头开始训练的缺点仍然存在。解决方案很简单:不从零开始训练,而是使用现有的检查点作为起点,即 Gemma 4 26B A4B 模型。
Gemma 4 26B A4B,如 Gemma 4 可视化指南 中所述,是一个混合专家(MoE)模型,已经经过了大量训练并具有出色的性能。但有一个问题…
Gemma 4 26B A4B 是一个仅解码器模型,用于逐个生成文本,而扩散通常需要一个编码器和一个去噪器。这就是一个优雅的解决方案出现的地方:编码器-去噪器补丁!
这个补丁是将单个仅解码器模型转换为:
- 编码器 – 用于"理解"查询
- 去噪器 – 用于对画布进行去噪
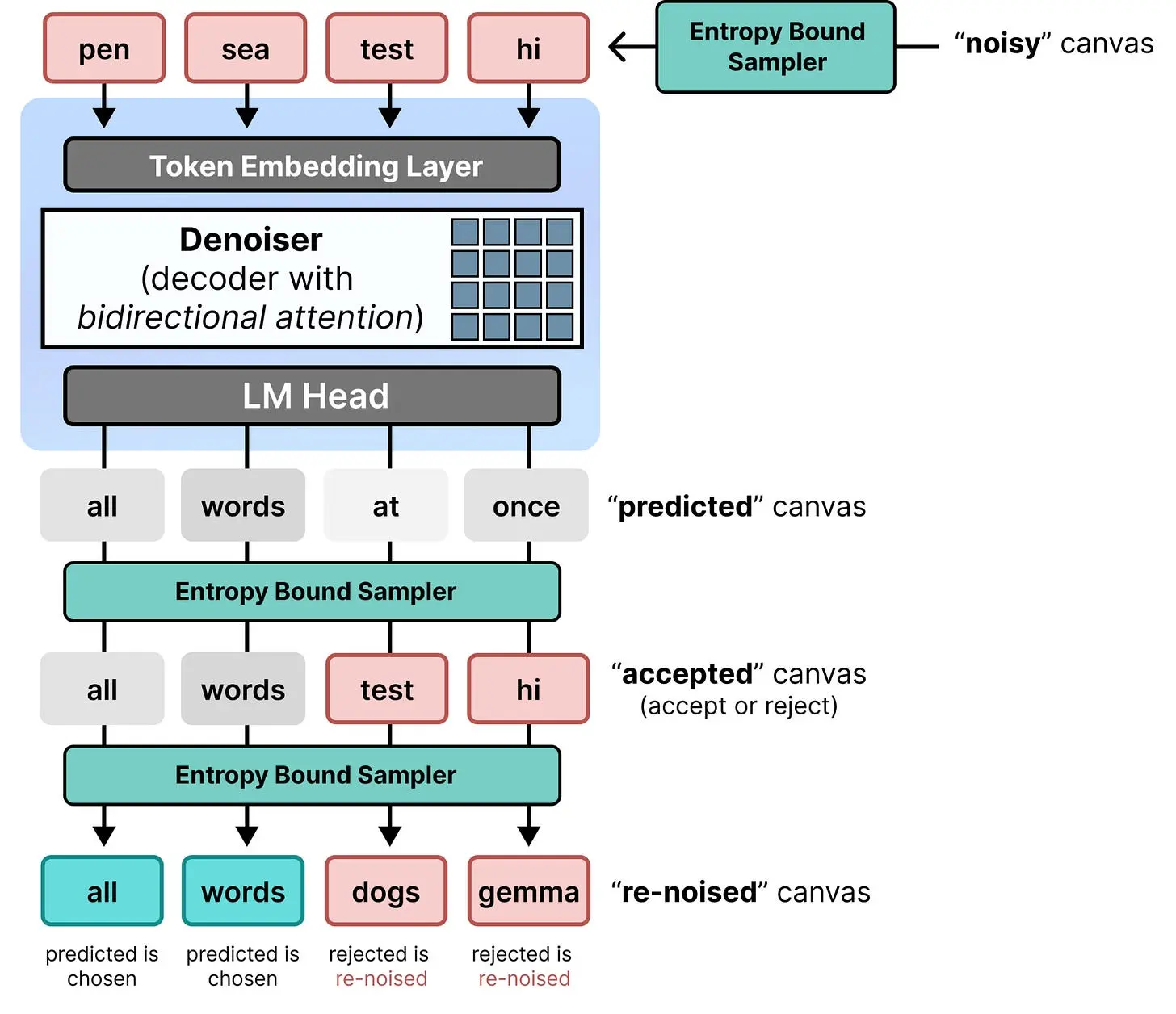
它通过让单个模型(Gemma 4 26B A4B)在去噪器模式和编码器模式之间动态切换来实现这一点。
4.1 去噪器模式 - 表现得像编码器
要将仅解码器模型(Gemma 4 26B A4B)转换为去噪器,我们可以利用它在生成 token 时没有直接使用的东西:所有 token 的 logits!
具体来说,自回归 LLM 首先将文本转换为 token 嵌入(一组一维数值)。当这些 token 嵌入流经 LLM 时,它们被持续处理和更新。这通常被称为模型的隐藏状态。最终的隐藏状态被投影到 logits,表示其词汇表中每个单词的置信度分数。这意味着对于输入中的每个 token,都会生成一组置信度分数。然而,只有最后一个隐藏状态的 logits 被用于选择预测的 token。所有其他 logits 本质上被丢弃了!
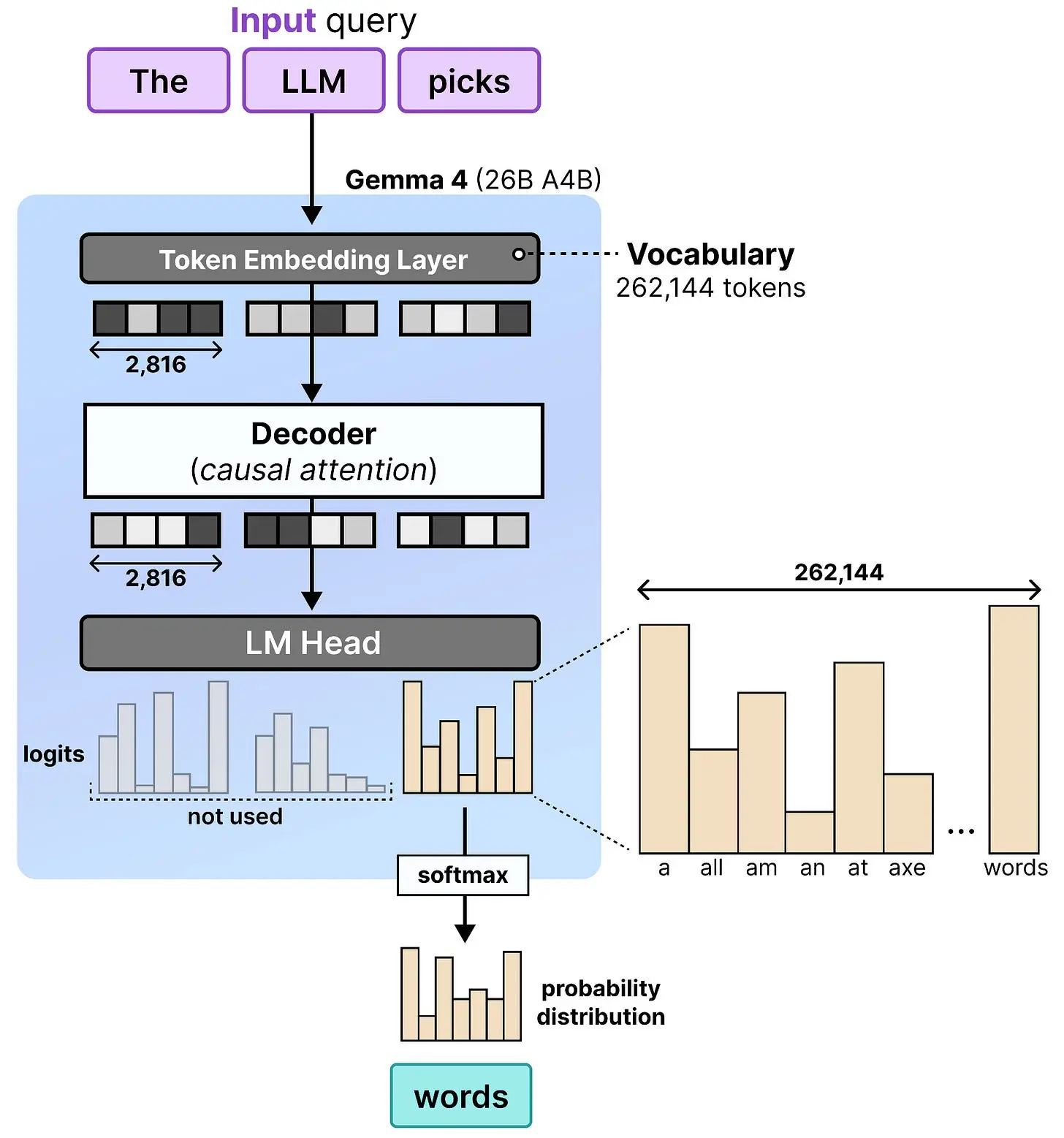
这种"丢弃 logits"的做法不一定是坏事,因为最终 token 的 logits 包含了关于之前所有 token 的信息。我们只使用最终的原因是序列中的每个 token 只能注意到("看到")它之前的 token。因此最终 token 的隐藏状态是整个序列的聚合,你需要它来预测下一个词。
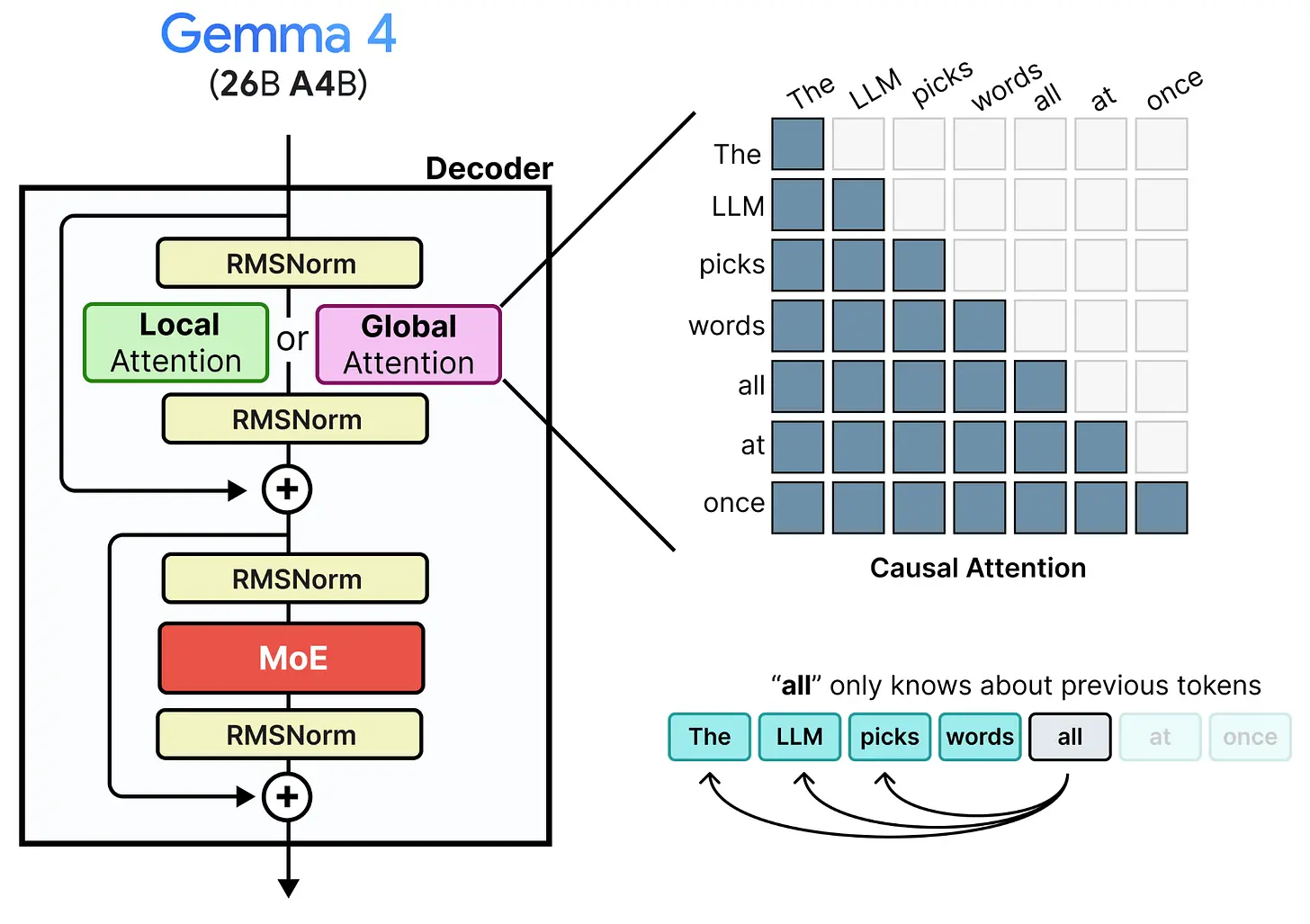
这引出了一个有趣的想法。如果我们替换两个东西会怎样:
- 将输入 token 序列替换为画布
- 将因果注意力替换为双向注意力
既然模型应该作为去噪器工作,我们期望输入 token 是一个噪声画布。然而,使用因果注意力的话,每个位置的 logits 仍然只能注意到它之前的信息。由于我们想同时生成一个 token 序列,我们不希望某个 token 不知道它后面的 token(无论是否有噪声)。我们必须将因果注意力替换为双向注意力。这使得一个 token 可以注意到序列中的所有其他 token,无论它们的相对位置如何。
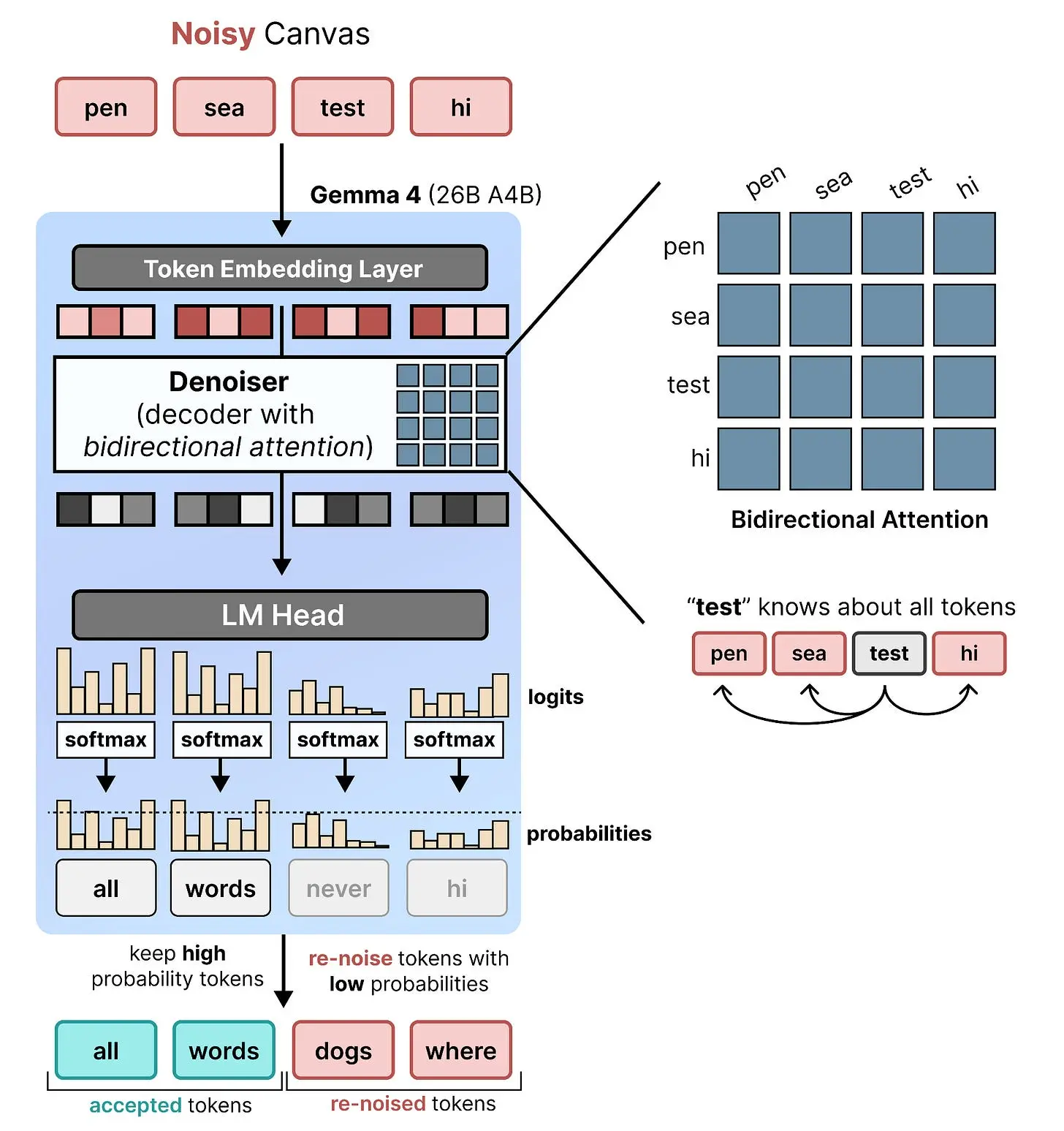
有了双向注意力,我们现在可以使用输入噪声画布中所有 token 的 logits,因为所有 token 都互相注意到。对于噪声画布中的每个位置,选择最佳匹配的 token。如果该 token 具有高概率,它被接受;如果仍然具有低概率,则被重新加噪并替换为不同的随机 token。
替换注意力机制后,它不能直接工作。Gemma 4 26B A4B 是用因果注意力训练的,所以如果它突然可以使用双向注意力会感到困惑。这需要训练,更多内容后面再说。
有了噪声画布作为输入和双向注意力,我们可以使用 Gemma 4 26B A4B 作为去噪器来迭代地更新画布。然而,没有输入查询,模型无法知道如何填充画布。这就是编码器的用武之地。
4.2 编码器模式 - 表现得像解码器
Gemma 4 26B A4B 的编码器模式,就像图像扩散中的编码器一样,用于处理输入查询并为去噪器提供上下文和引导。通常,你会使用编码器(具有双向注意力的 LLM)来处理输入。然而,Gemma 4 26B A4B 是用因果注意力训练的,如果我们再次替换它会相当昂贵。相反,我们可以直接使用 Gemma 4 26B A4B 来执行查询处理。这个 Gemma 4 26B A4B 模型不是原生使用的,而是经过微调以支持去噪和编码的不同任务。
在这个过程中,我们不使用 LM 头,因为我们不是在生成 token,而是生成 token 表示。这些表示通常以两种方式出现:隐藏状态或 KV 缓存。
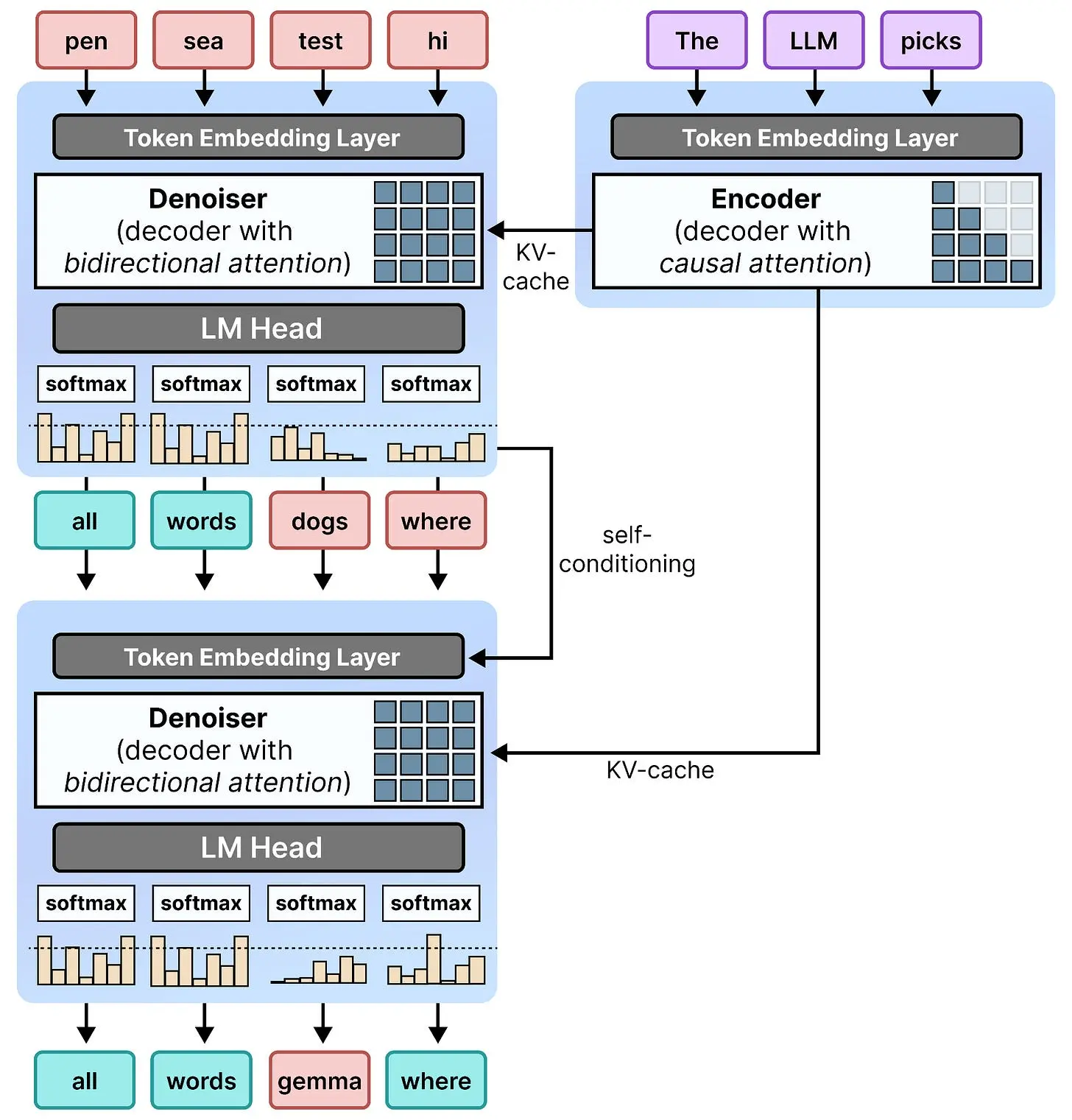
然而,使用隐藏状态需要额外的交叉注意力,这是又一个补丁。由于编码器模式和解码器模式共享完全相同的模型,只是注意力机制不同,DiffusionGemma 在编码器模式和解码器模式之间共享 KV 缓存。
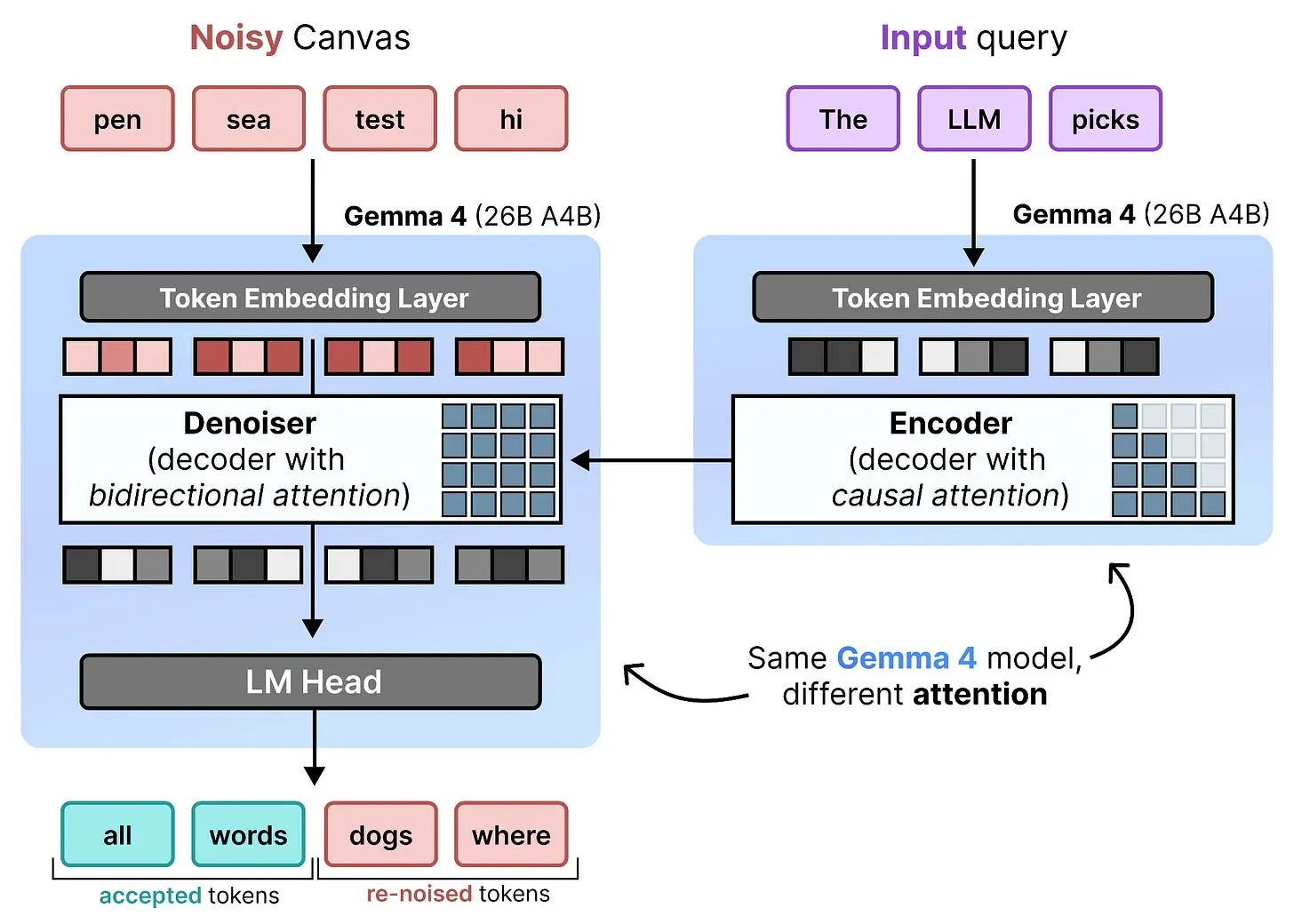
另一个原因是,即使编码器是一个具有因果注意力的解码器模型,它仍然可以生成输入查询的出色表示。因此,这些 KV 缓存表示与去噪器(具有双向注意力的 Gemma 4 26B A4B)共享,使其理解用户实际想要生成什么。KV 缓存在去噪器的去噪步骤中不会被更新。
5、DiffusionGemma 的推理
扩散模型的一个重要部分是如何处理推理。具体来说,画布不是在单个步骤中生成的,而是迭代更新的。这带来了几个我们尚未回答的问题:
- 模型如何知道它在上一步中做出的预测?
- 如何生成比画布更大的序列?
- 去噪器使用多少去噪步骤?
5.1 自条件化
我们回答的第一个问题是"模型如何知道它在上一步中做出的预测?"。
幸运的是,答案相当简单。去噪器运行一个步骤后,可以使用它生成的概率并将其传递给第二个步骤。这给模型提供了关于它上一步打算做什么以及从哪里来的信息。
在实践中,它通过将 softmax 后的概率与所有 token 的嵌入相乘来实现,这也称为嵌入矩阵或嵌入表。这个乘法的结果是画布中每个位置的一个嵌入,表示这个概率分布。因此,它对更可能的 token 的嵌入给予更多权重。然后它们被传递给一个小型前馈神经网络(FFNN),并添加到下一步的 token 嵌入中。
这本质上给了它关于上一步尝试做什么以及在某些位置预测时有多自信的记忆。
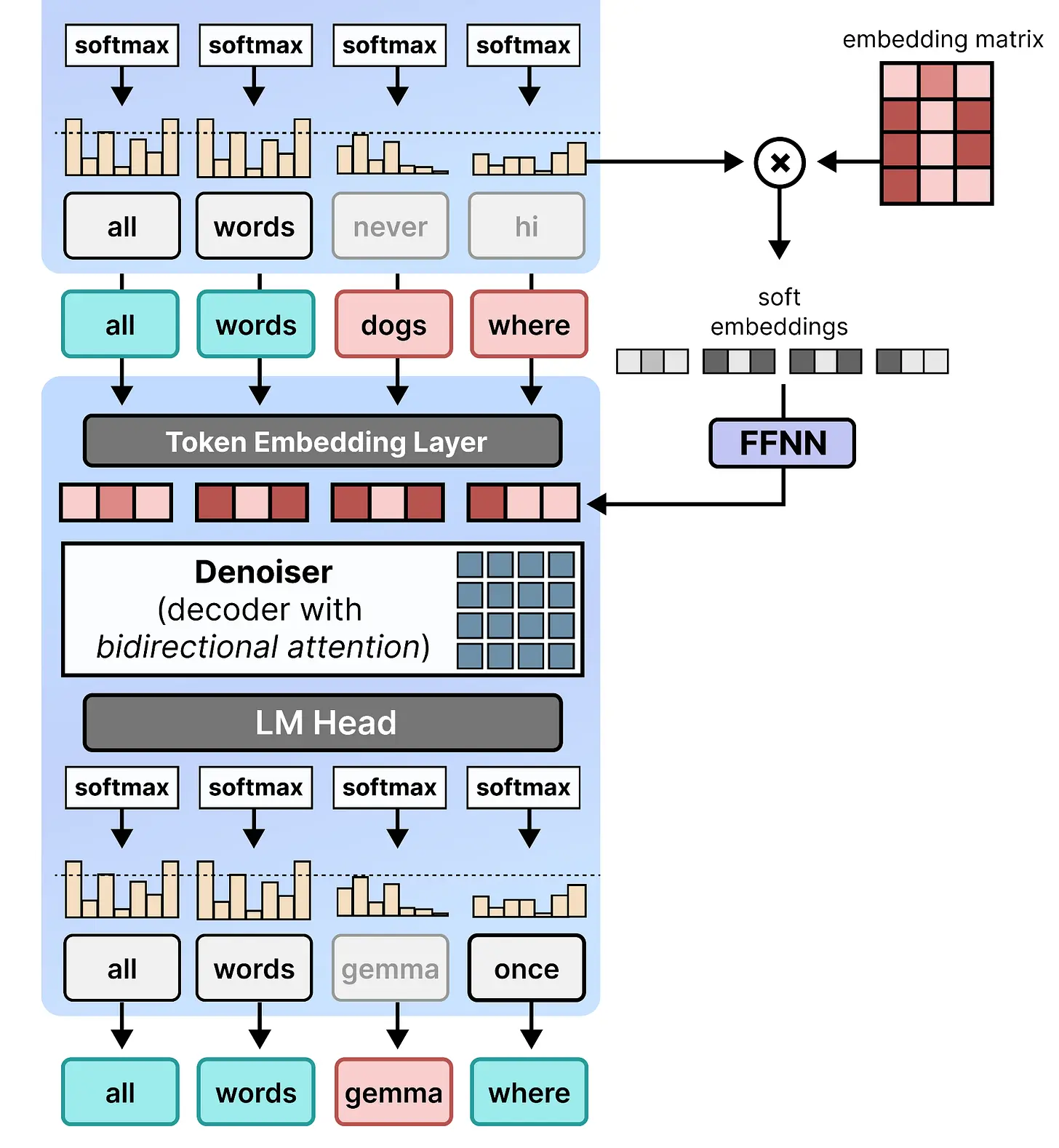
当你把一切放在一起时,第二步与第一步完全相同,并重用编码器的 KV 缓存。这种对上一步的自条件化可以看作是一个跳跃步骤,其中信息被传播到下一步,以便它可以继续处理并拥有更多上下文。
现在我们有了 DiffusionGemma 的完整架构概览:
5.2 多画布采样(块扩散)
我们需要回答的第二个问题是"如何生成比画布更大的序列?"。
DiffusionGemma 中的画布大小为 256 个 token,这并不算太大!幸运的是,我们可以将扩散与自回归混合搭配来扩展生成的 token 数量。
具体来说,我们首先使用 DiffusionGemma 生成 256 个 token,如我们迄今为止探索的那样。这 256 个 token 只需要通过编码器一次以生成 KV 缓存,之后去噪器需要多个步骤来填充这个画布。当它完成后,提示词用新的 256 个 token 更新,并添加到编码器的输入序列中以扩展 KV 缓存。去噪器然后继续创建另一个 256 的序列。这个过程持续进行,直到去噪器生成停止 token。
因此,画布是使用扩散生成的,但按顺序拼接在一起。这意味着我们在扩散和自回归之间交替!
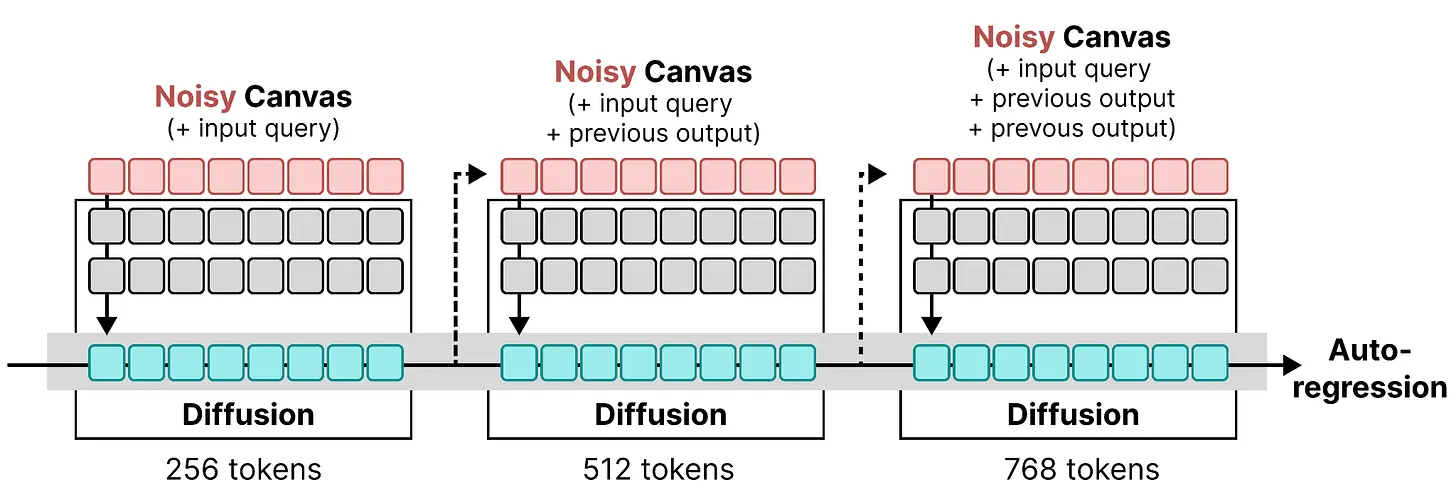
回顾我们用来比较扩散和自回归的图表,它们现在被组合成一个过程,其中每个扩散输出以自回归方式附加在一起:
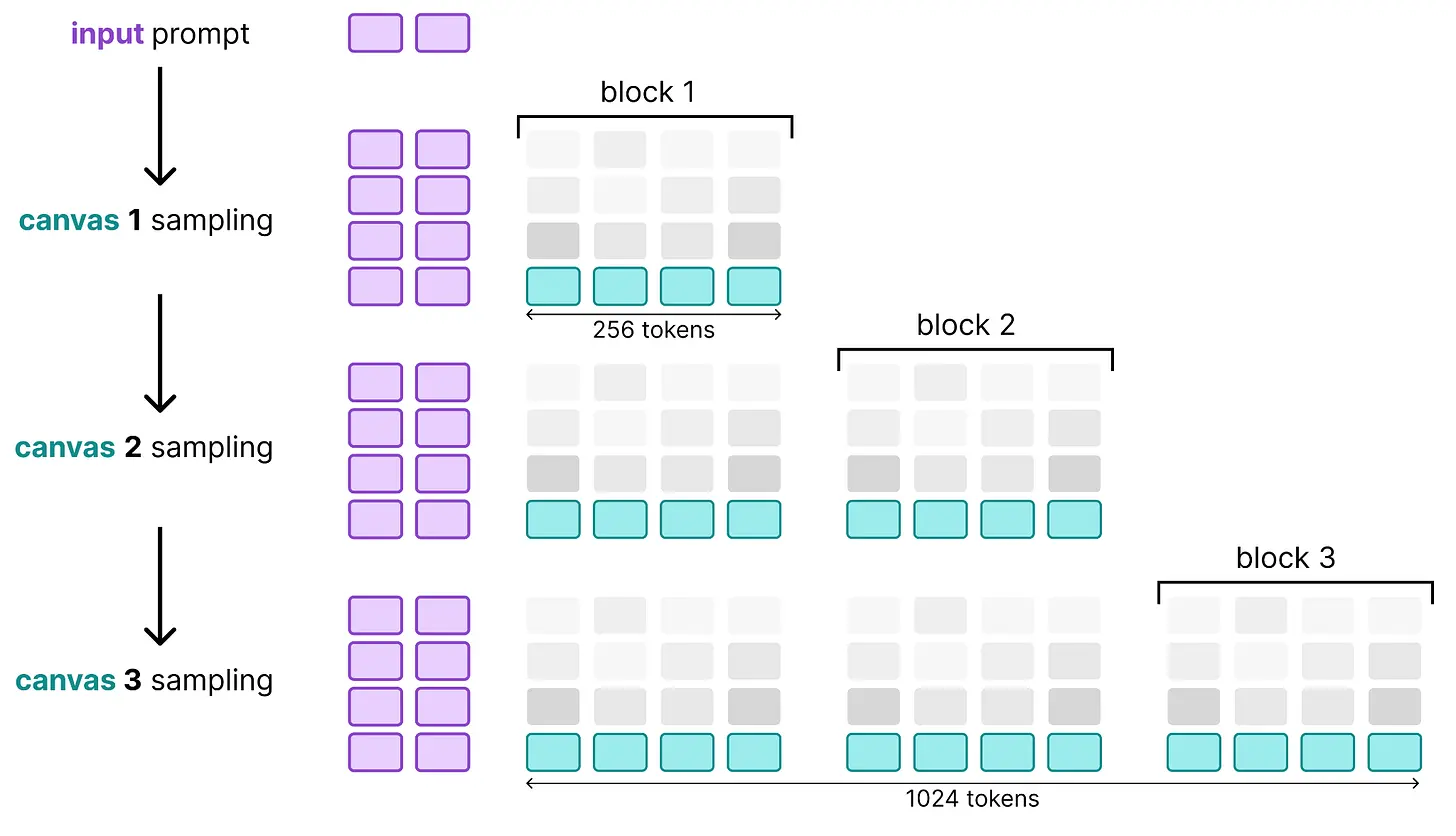
使这成为可能的一个重要原因是编码器的 KV 缓存是使用因果注意力计算的。由于每个 token 只注意到它之前的内容,只需要为每个"自回归步骤"中添加的画布计算 KV 缓存。结果是一个相对便宜的操作,因为我们可以持续更新 KV 缓存,而不是重新计算它。
使这成为可能的另一个重要原因是编码器的 KV 缓存只需要在每个"自回归步骤"开始时计算。在"扩散步骤"期间,KV 缓存被重用,不需要重新计算,因为在扩散结束之前不会添加新的 token。
5.3 调度器
图像扩散中的调度器控制在每个去噪步骤中去除了多少噪声以及需要多少步骤。在 DiffusionGemma 中,它是一组技术的集合,共同决定基于步骤的去噪过程如何工作。它"调度"去噪过程,但不直接决定接受或拒绝哪些 token。与图像扩散不同,DiffusionGemma 中的调度器由三个独立的组件协同工作。
首先是步骤数。它决定了最大去噪步骤数。更多步骤通常意味着更高质量的输出但更慢的生成。
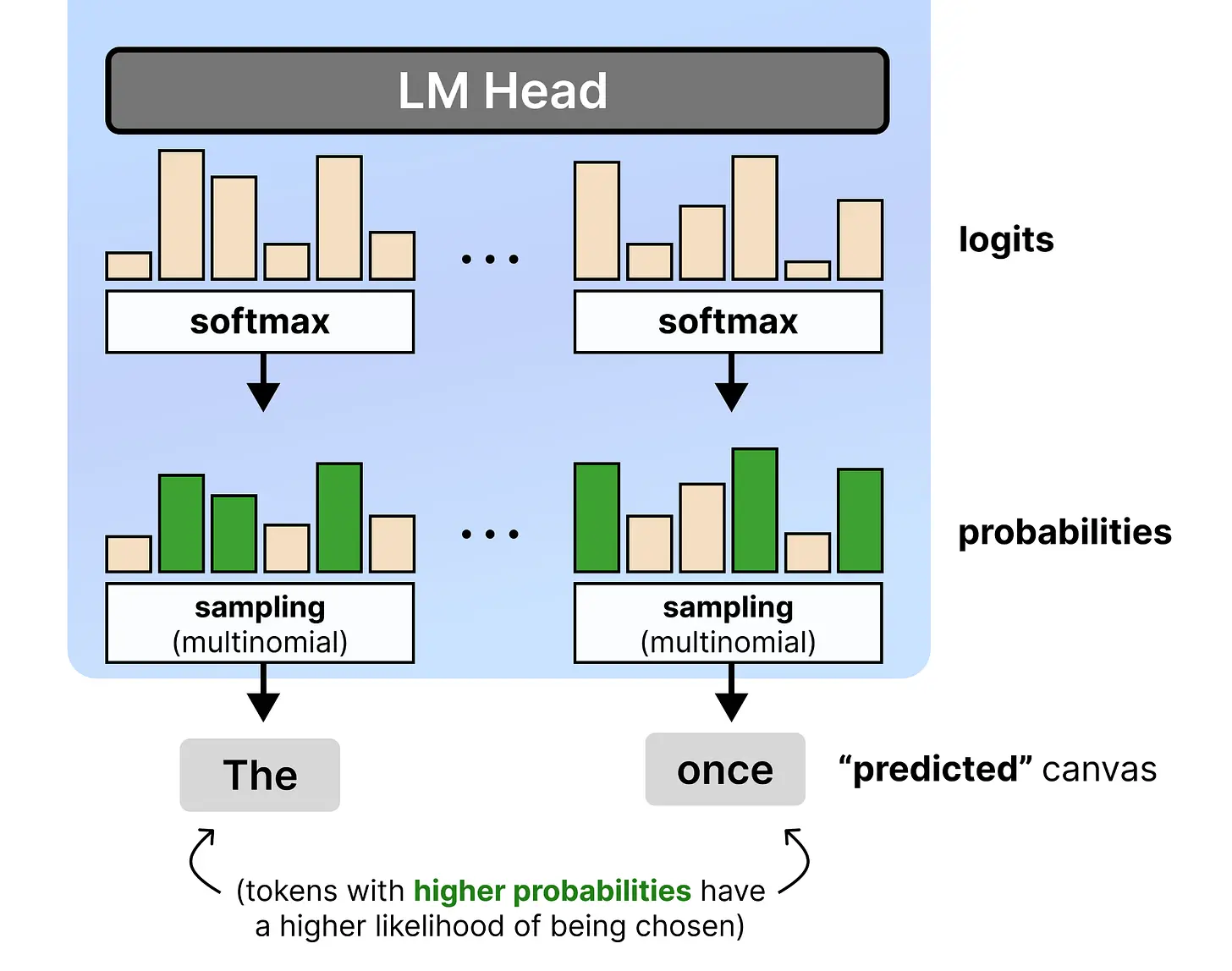
其次是 logits 调度器。模型生成原始 logits 后,通过 softmax 转换为概率。从这些概率中,并不总是选择最可能的 token。它基于多项式分布选择 token。这意味着高概率的 token 被选中的几率更高,反之亦然。
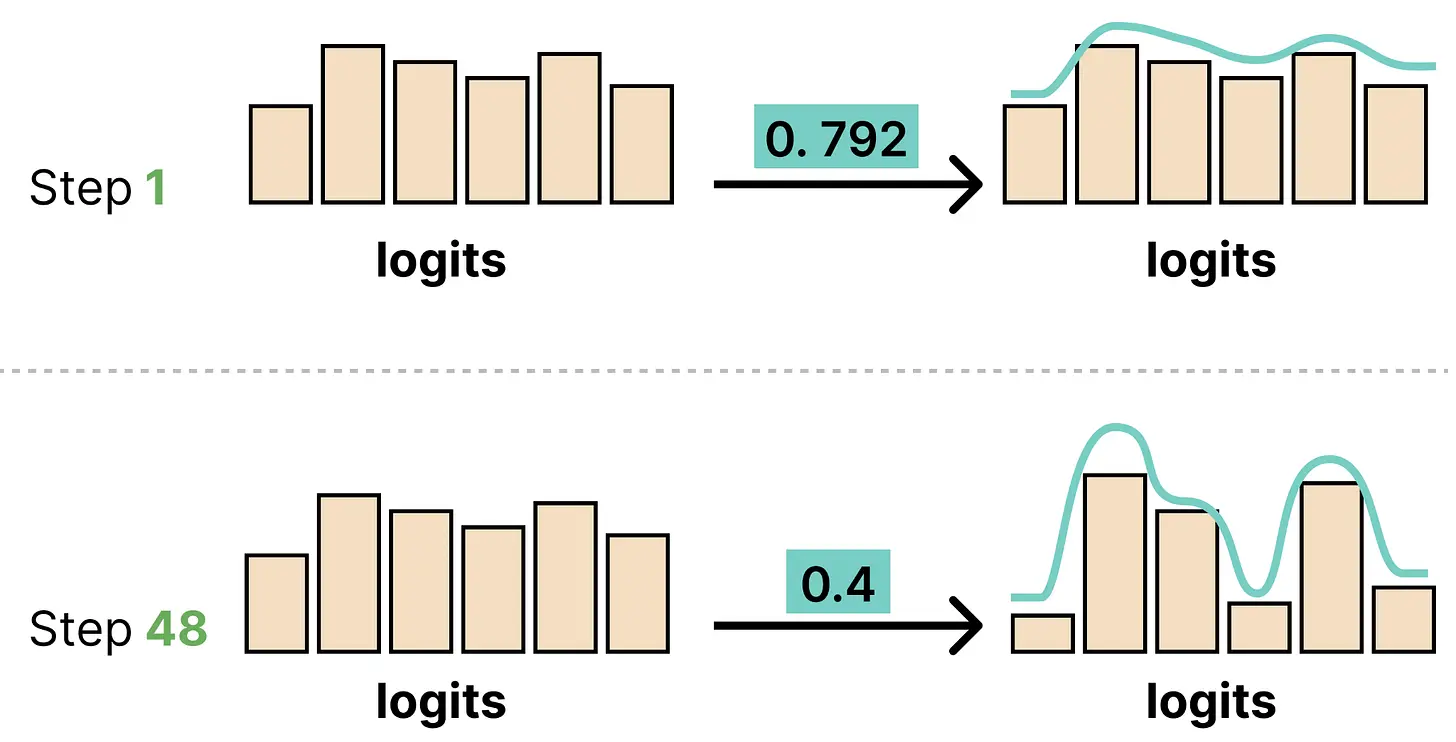
然而生成的 logits 有一个问题,即它们往往更不确定。原因是在去噪过程的每个步骤中,画布中有噪声的 token,这可能影响每个位置的可预测性(因此影响 logits)。
Logits 调度器确保模型的预测(logits)更加果断。它通过将 logits 除以温度值来实现。这个值与你在自回归 LLM 中看到的相同。

请注意步骤是倒计数的,以确保每个去噪步骤有更低的温度:

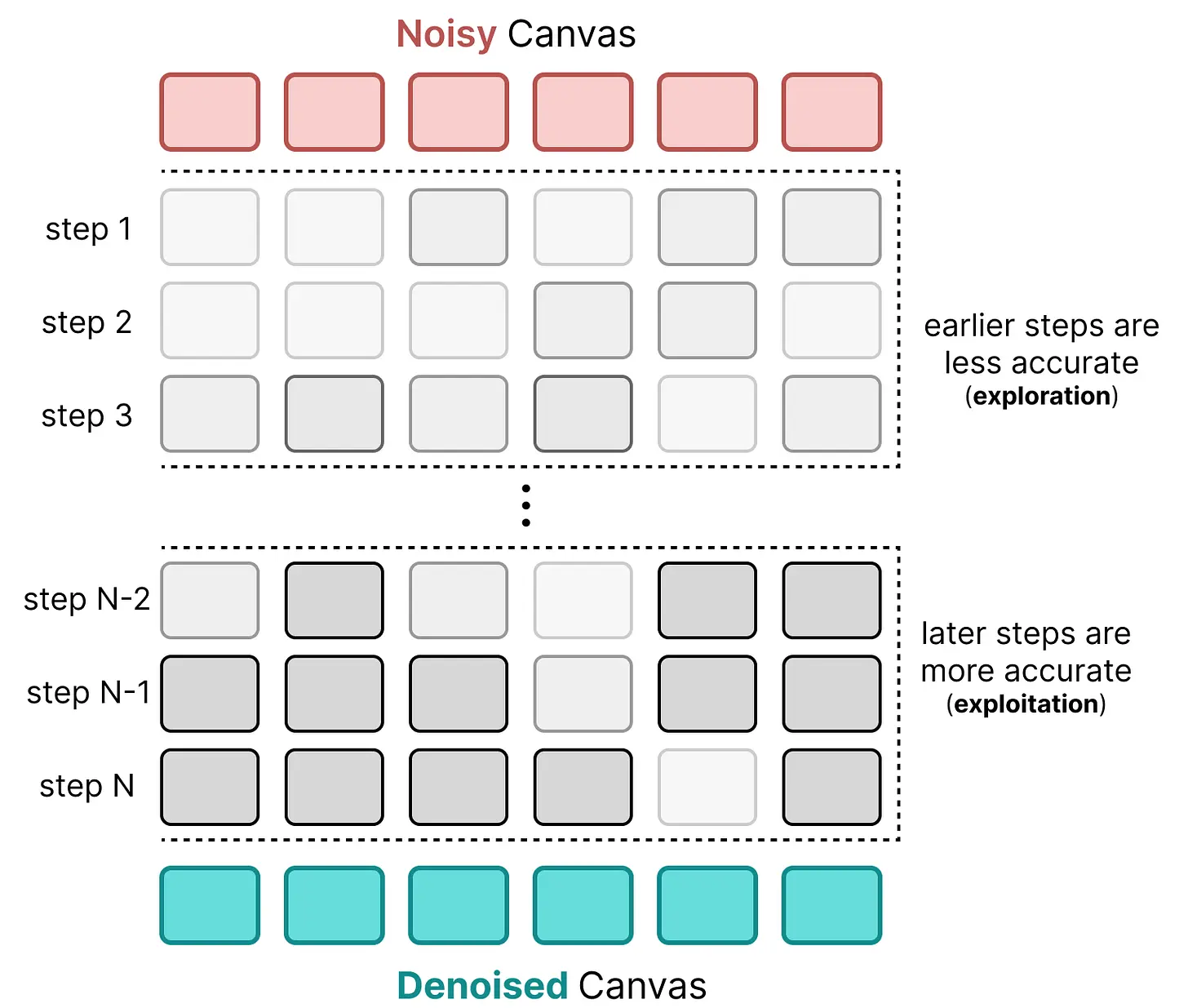
在每个步骤将 logits 除以温度有助于使 logits 分布更加明显或"尖锐"。由于早期画布大部分是噪声,使预测更尖锐几乎没有意义。只有在后面的步骤中,模型才拥有更清晰的画布,我们才能使预测更尖锐。
这意味着在早期步骤中,模型会更多地探索,而不仅仅关注最可能的 token。而在后面的步骤中,模型会更少地探索,更多地关注最可能的 token。它在探索(早期步骤)和利用(后期步骤)之间强制一种平衡。
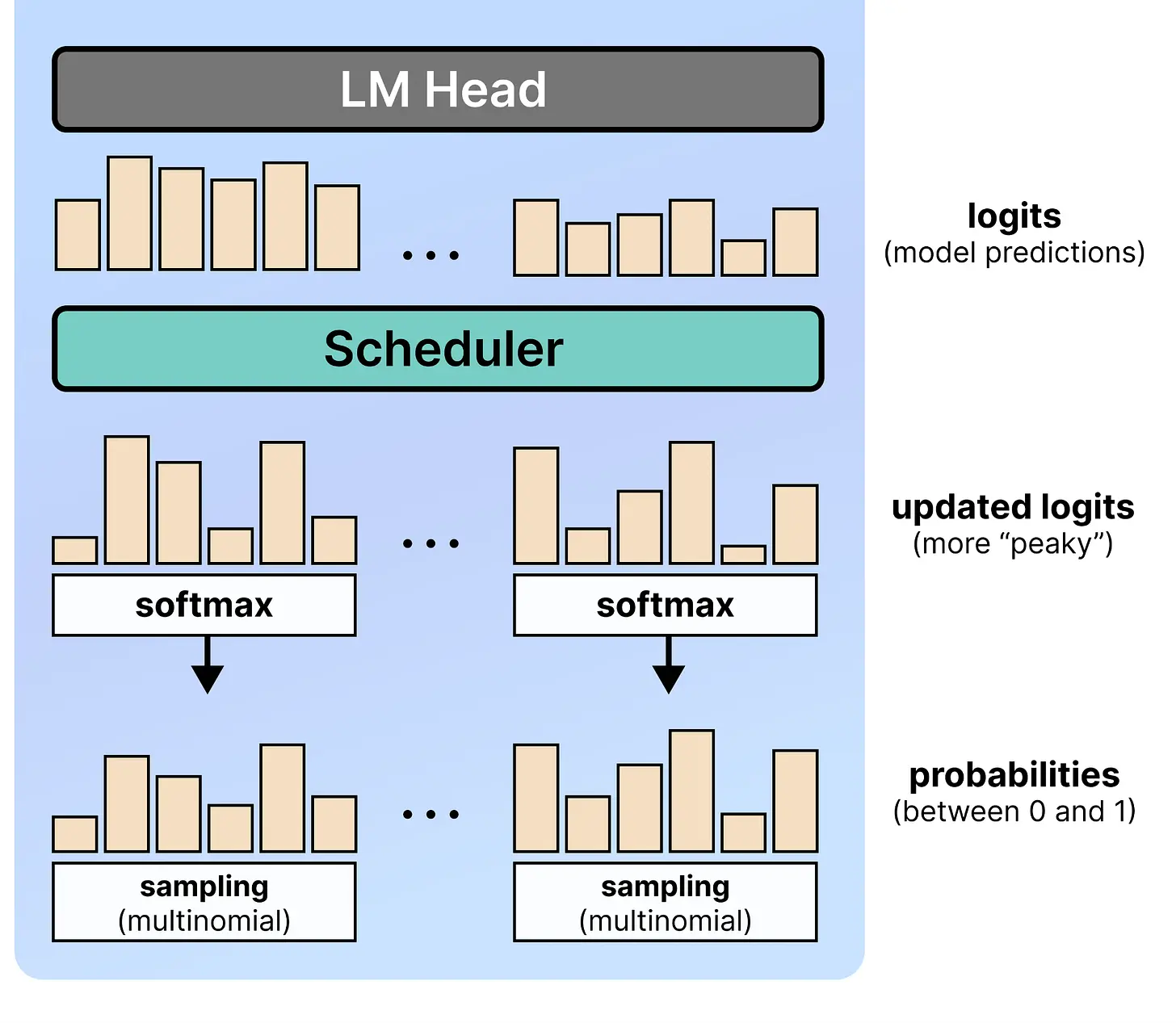
因此,我们可以看到早期步骤相对于后期步骤在 token 分布方面更加"嘈杂"。
第三是自适应停止。虽然步骤数已经定义了去噪过程可以采取的最大步骤数,但模型可能会提前收敛。为此,有自适应停止机制。在每一步,它检查:
- 稳定性 – 最高概率的 token 预测在最后 N 步中是否相同?
- 置信度 – 模型在画布中所有 token 上的置信度如何?
在 DiffusionGemma 的配置中,置信度阈值为 0.005,稳定性阈值为 1。置信度通过模型预测的分散程度来衡量,称为熵。在给定的画布位置,如果一个 token 的概率相当高(例如,95% 为"LLM"),则它是自信的,熵很低。这意味着如果模型在大多数 token 位置上都很自信,并且预测的 token 与上一步相同,那么模型将停止生成,无论它还剩多少步骤。
5.4 熵有界采样器
在图像扩散中,采样器控制如何将模型的预测与当前噪声图像结合起来以生成下一个稍不嘈杂的图像。在 DiffusionGemma 中,它控制去噪过程中的噪声量。每个采样器由三个组件组成:
- 画布初始化 – 如何创建噪声画布。
- Token 接受 – 保留和拒绝哪些预测的 token
- Token 重新加噪 – 如何对被拒绝的 token 重新加噪
默认情况下,使用的是熵有界采样器。
画布初始化
画布使用随机 token(均匀绘制)创建,这本质上与图像扩散中从纯噪声开始相同。
Token 接受
熵有界采样器根据模型对每个 token 的置信度来决定保留哪些 token。为了衡量该置信度,它使用熵来定义概率分布的分散程度。请记住,画布中的每个位置,模型都会创建一个概率分布。如果该分布严重偏向单个 token,那么它相当自信,熵会很低。然而,如果分布是均匀的(它不知道选择哪个 token),熵会很高。
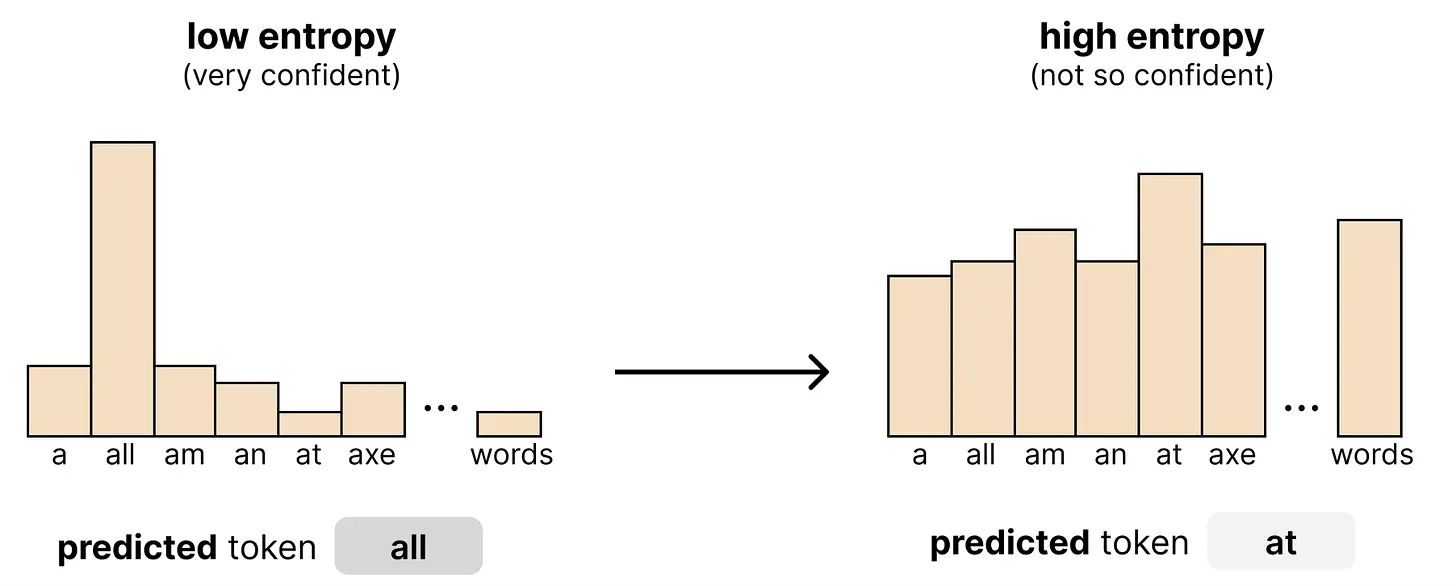
采样器计算画布中每个位置的熵值。然后,从最低熵(最自信)到最高熵(最不自信)排序。因此,这个 token 列表从模型最自信的预测开始,采样器将逐一检查是否可以接受。
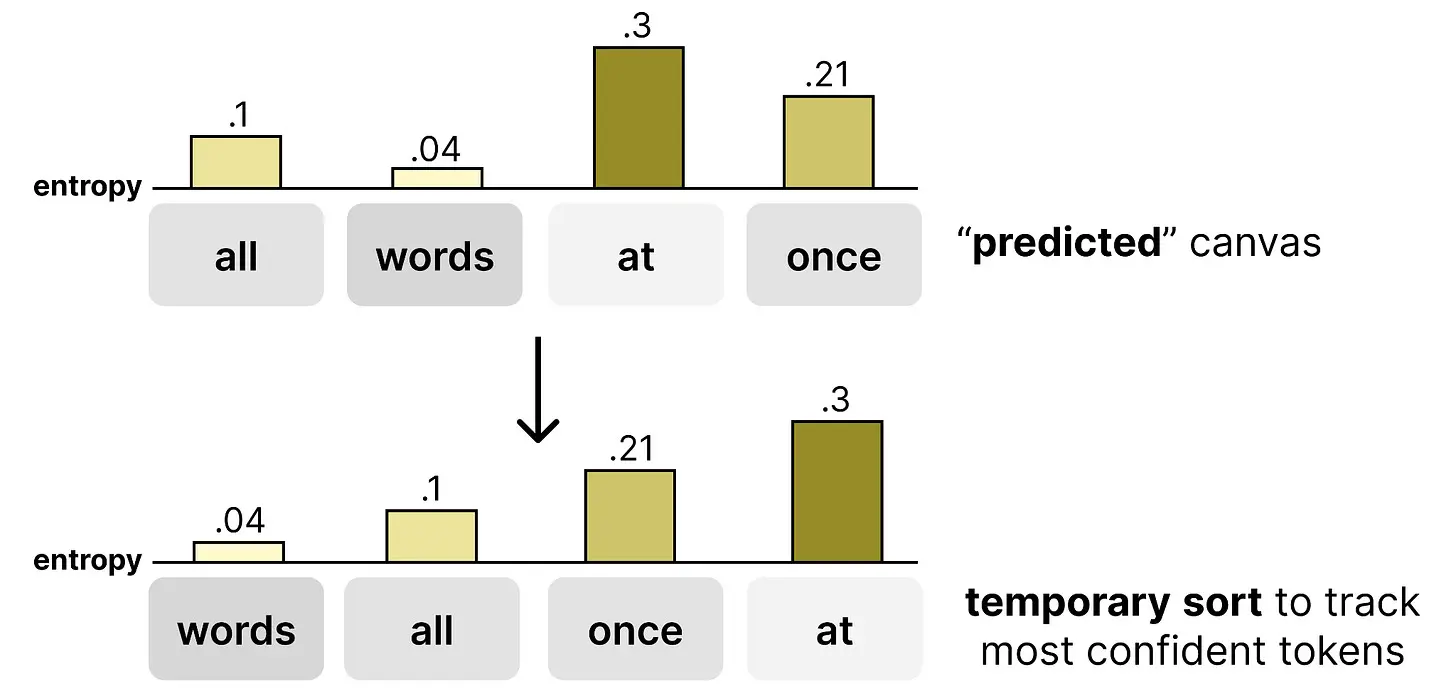
接受标准基于以下公式:
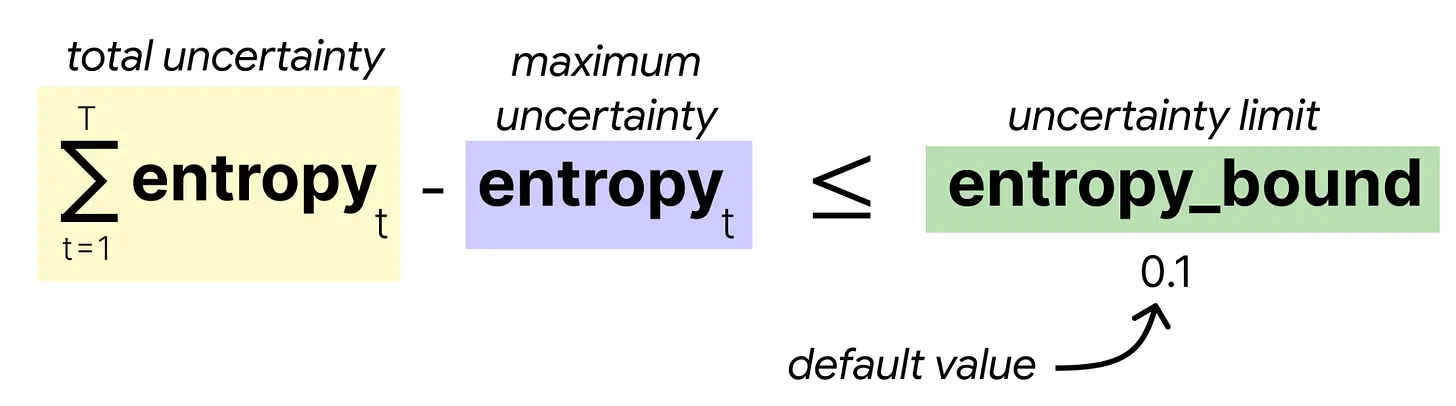
从模型最自信的画布位置开始,采样器检查到目前为止看到的熵之和(减去最大熵)是否超过你预设的极限。如果是,则模型不够自信,将被拒绝。如果未超过极限,则模型足够自信,我们继续下一个最自信的画布位置。
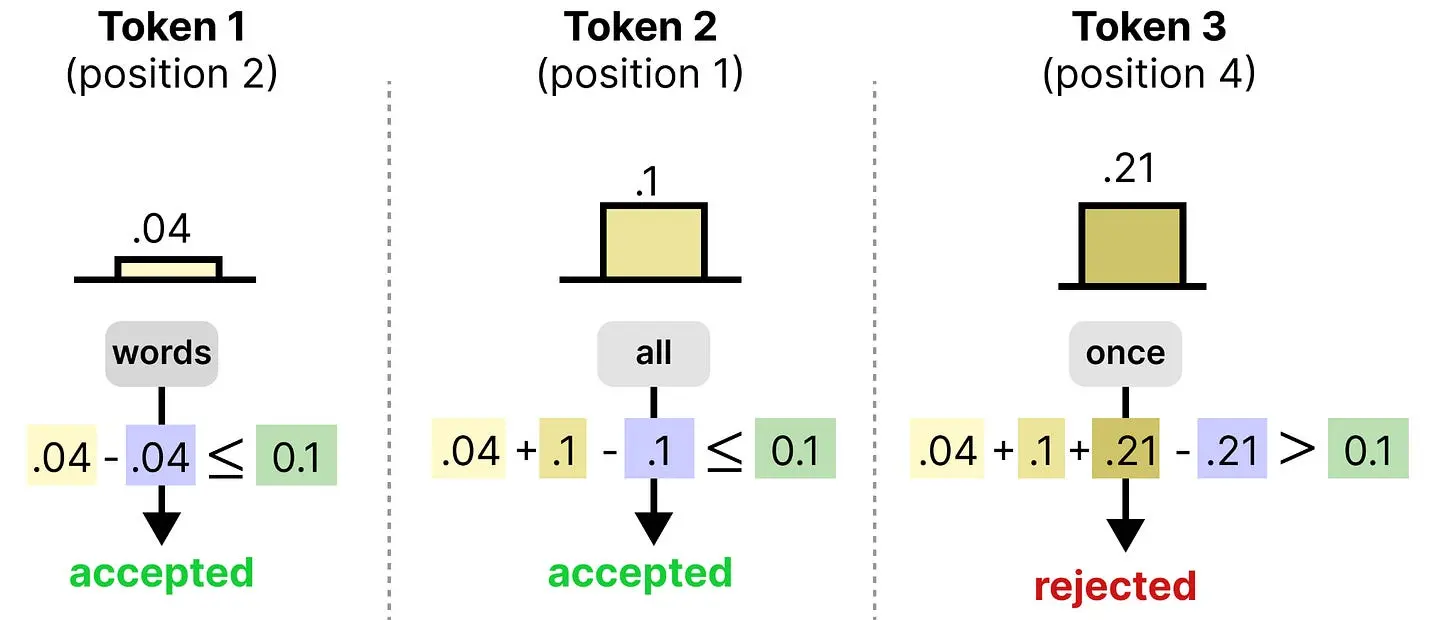
因此,采样器只在一组 token 各自都足够自信且整体不超限的情况下才接受它们。这允许模型更多地关注接受它相当确定正确的 token,而不管其他 token 位置如何。
Token 重新加噪
在熵有界采样器中对画布重新加噪非常简单,所有被拒绝的 token 都被重新加噪!但这并不意味着被接受的 token 总是会保持在原位。在下一个去噪步骤中,模型可能会在生成更新后的上下文后给它一个更低的概率。
6、结束语
真是一段旅程……文本中的扩散!
在这里你可能看不出来,但我实际上忍住了没有再创建 40 张额外的图片和深入的内容。 希望你喜欢这篇深入的解析,它在思考这个模型时给你一种直觉。关于这个模型以及 DiffusionGemma 中扩散如何工作,还有很多需要发现。与文本生成相比,你可以尝试的新东西,比如构建自己的采样器!
原文链接: A Visual Guide to DiffusionGemma
汇智网翻译整理,转载请标明出处
