Flash 3.1 TTS:用提示控制声音
Gemini 3.1 Flash TTS 携200+音频标签、30种声音预设和让ElevenLabs紧张的控制力重磅登场。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
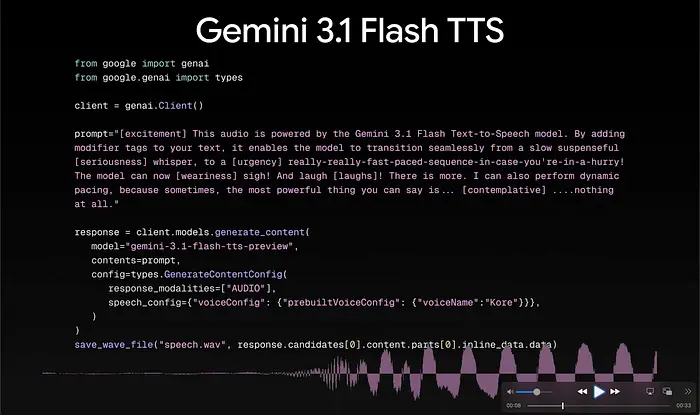
Gemini 3.1 Flash TTS 今天在Google AI Studio、Gemini API和Vertex AI上线。模型ID是gemini-3.1-flash-tts-preview。如果你曾经花时间与TTS API搏斗,试图让声音听起来不那么像一个无聊的GPS导航仪,那么请注意:这可能真的是一个转折点。
1、这个模型到底是什么?
先说架构。Gemini 3.1 Flash TTS基于Gemini 3 Pro构建。文本输入,音频输出。就这么简单。这里没有多模态输入;你给它文本(最多16K token),它返回24kHz单声道PCM音频,base64编码。输出窗口为32K token。
从纸面上看并不革命性。
有趣的部分不是它生成了什么。而是你如何控制它生成什么。Google本质上构建了一个提示驱动的声音导演系统,其粒度在这个价格点上是我们前所未见的。
2、200+音频标签:导演的工具箱
这是真正有意思的地方。Gemini 3.1 Flash TTS支持超过200种内联音频标签,你可以直接嵌入到文本输入中。这些不是后处理效果或2015年的SSML标记。这些是模型原生解释的语义指令。
标签类别大致如下:
- 情感语调:
[excitement]、[frustration]、[admiration]、[contempt]、[nervousness]、[awe]、[sarcasm]、[anger]、[hope]、[curiosity] - 节奏控制:
[slow]、[fast]、[short pause]、[long pause] - 非语言质感:
[laughs]、[whispers]、[sighs]、[crying]、[shouting] - 效价标记:
[positive]、[neutral]、[negative]
它还能更深一层。你可以通过自然语言提示指定声音特征:"提高软腭增加亮度"、"有力的辅音"、"拉长元音以示强调"。你不是在下拉菜单中选择。你是在指导一场表演。
3、但它真的能遵循指令吗?
差不多…几乎总是。Google自己的文档悄悄承认"偶尔会出现声音与提示指令不一致的情况",并建议将提示的语调与所选的说话人配置对齐。翻译一下:如果你选择了一个平静、沉稳的声音预设,然后给所有内容标记[shouting]和[panicked],模型会感到困惑。
还有一个已知的边缘情况,模型会返回文本token而不是音频。很少见,但意味着生产部署需要重试逻辑。这不是GA发布级别的打磨。这是一个预览版,它的表现也像预览版。
4、30种声音,70多种语言,和真正变化的口音
声音预设列表读起来像星表。字面意思。Zephyr、Puck、Charon、Kore、Fenrir、Leda、Orus、Aoede…共30种预设,每种都有独特的音色特征。
但口音系统才是吸引我注意的地方。你可以指定区域方言,精确度令人惊讶:美式山谷口音、美式南方口音、英式RP、Brixton、跨大西洋口音、纽卡斯尔口音、埃克塞特口音。这不是把"英式英语"作为一个单一选项。它是细粒度的。
70多种语言受支持,包括日语、印地语和德语。Google声称在"主要市场"中对风格、口音、节奏和表现力有高级控制。这是通常的企业式含糊说法;意味着200多种标签在英语中效果最好,在其他语言中会逐渐降级。
埃克塞特都作为一个口音选项?那个团队里有人很有主见。
5、多说话人对话:播客利器
这对开发者来说是最有趣的部分。Gemini 3.1 Flash TTS支持原生多说话人对话,每次生成最多两个说话人。你定义命名的说话人,为他们分配独立的声音预设,然后写脚本。
设置如下:Joe使用"Puck [Upbeat]",Jane使用"Kore [Firm]"。模型在每个轮次中保持每个说话人的声音特征,不会混淆。这与notebookLM中的播客功能相同。
6、世界构建上下文
Google列出了格式模板,确切地告诉你他们的目标:播客对话、有声书旁白、语言导师、语音助手、健康指南、新闻广播、客服代理。这不是一个通用TTS贴在聊天模型上。这是一个为特定生产用例设计的产品。
还有,有一个"世界构建上下文"功能,角色可以在多个对话轮次中保持角色特性并自然地互动。设置可以导出为API代码,确保跨项目的一致性。
7、实际场景
假设你正在构建一个语言学习应用。你需要一个导师声音,在讲解部分耐心且鼓励,然后在发音示范时切换到母语者声音。以前,你需要拼接两个单独的TTS调用,手动处理过渡,祈祷两个声音在语调上不会冲突。
现在你定义两个说话人,按片段分配声音预设和情感标签,然后调用一次API。模型处理过渡。如果你在发音示范上叠加[slow]标签,在鼓励片段上叠加[enthusiasm]标签,你会得到听起来...有导演感的东西。不是生成感。
如果你正在构建播客工具、有声书流水线或任何对话式音频产品,这才是最重要的功能。不是Elo分数。
8、Elo分数(好吧,我们来谈谈)
Gemini 3.1 Flash TTS在Artificial Analysis TTS排行榜上得分1,211,综合排名第二。该排行榜通过数千次盲测比较来衡量人类偏好。
在TTS语境中,Elo的工作方式类似国际象棋评级:基于一对一匹配的相对排名。1,211分意味着该模型在与大多数竞争对手的盲测A/B比较中赢得了多数。用人类的话说:当人们不知道哪个模型产生了哪个片段时,他们一致偏好它的输出。
综合排名第二,但事情是这样的:Google正在将其定位在质量与成本比图表的顶端。那个"与成本"的限定词分量很重。ElevenLabs在某些场景下可能在原始表现力上略胜一筹;OpenAI的TTS有其自身优势。但以Google的API定价,这个Elo分数代表了一个完全不同的竞争论点。
重要的不是规模,而是价值主张。
9、SynthID:你听不到的水印
Gemini 3.1 Flash TTS生成的每个音频片段都带有SynthID水印,这是Google的音频水印系统。水印直接编织进音频信号中;人类听不到,但验证工具可以检测到。
这很重要的原因只有一个:随着TTS质量接近与人类无法区分的水平,来源成为监管和信任问题。Google在基础设施层面就将其内置,而不是做成可选项。明智之举。当不可避免的"AI语音欺诈"头条出现时,他们可以指出SynthID作为默认方案。
10、缺少什么(因为总会有"但是")
让我们直接说说差距。
非流式输出。
音频以base64编码的内联数据返回。对于实时应用如语音助手或电话集成,这是一个瓶颈。你在处理完成后得到完整的音频片段,而不是可以立即开始播放的流。
两个说话人限制。
多说话人对话上限为两个声音。如果你正在构建一个有四位主持人的圆桌播客或有完整角色的音频剧,你仍然需要拼接。
预览状态。
这是gemini-3.1-flash-tts-preview。Google保留在GA之前更改行为、弃用功能或调整定价的权利。在预览模型上构建生产基础设施是一个经过计算的风险。
英语优先的现实
70多种语言听起来令人印象深刻。所有70种语言的可控性深度?几乎可以肯定是不均匀的。200多种音频标签、口音选项和导演级提示主要是为英语构建和测试的。
12、谁现在应该关注?
如果你正在构建音频产品,并且一直在按字符向ElevenLabs付费或运行自己的Tortoise/XTTS流水线,这值得认真看看。每美元可控性比率刚刚发生了变化。
如果你是生成播客开场白、有声书样本或教育音频的内容创作者,多说话人加音频标签的组合在这个可及性水平上是真正的新领域。
如果你需要用于语音代理的实时流式TTS?还不是时候。等GA或者看看Gemini 3.1 Flash Live,那是流式的兄弟版本。
13、Google真正的布局
看。Google不只是发布了又一个TTS模型。他们发布了一个碰巧能做TTS的可控性层。200多种音频标签、口音粒度、导演级提示、世界构建持久性;这是一个音频应用的平台布局,不是独立功能。
集成到Google Vids中供Workspace用户使用告诉你上市路径:企业内容创作优先,开发者API其次,消费者产品最终。Google希望每个企业培训视频、每个内部播客、每个产品演示都由Gemini旁白。
这是我的观点。你应该做你觉得舒服的事。但如果我在2026年构建任何与用户对话的东西,我今天就会测试这个。
不是因为它完美。因为"足够的TTS"和"有导演感的声音表演"之间的差距刚刚缩短了大约80%,而Google几乎不为此收费。
原文链接: Google Just Handed You a Voice Director's Chair for Free With Flash 3.1 TTS
汇智网翻译整理,转载请标明出处
