AI经济学:倒置的价值链
理解AI超级周期的经济学。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
Yann LeCun最近说了一些让我印象深刻的话。在与Dario Amodei就AI是否会消除一半白领工作进行公开争论的过程中,LeCun用一句简单的指令切入了核心:"不要听CEO的。他们有既得利益去夸大他们销售产品的能力。"他的建议是?听听经济学家的。AI对劳动力、对市场、对整个行业结构的影响——"是一个经济学问题,而不是技术问题。"
不要听CEO的。他们有既得利益去夸大他们销售产品的能力。 — Yann LeCun
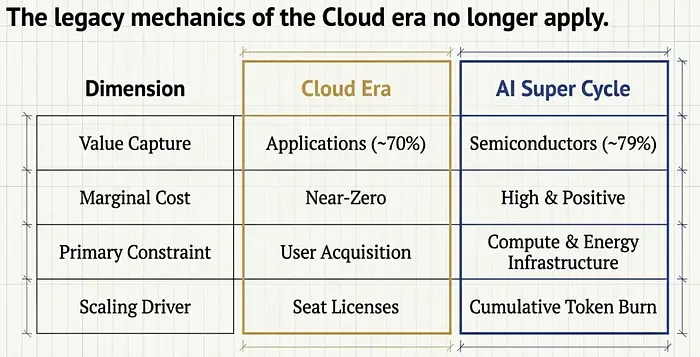
我认为他比他自己预期的还要正确。大多数人用来理解AI的视角是技术性的——基准测试、模型能力、推理突破。但如果你真正想了解钱流向哪里、谁赢了、谁被挤压了,以及为什么这个周期感觉与之前的一切都如此不同,你需要经济学。具体来说,你需要审视AI价值链的结构——这是自PC、互联网和移动时代以来最大的价值链,拥有自己独特的经济学,打破了从云时代继承下来的大多数心智模型。
Altimeter Capital的合伙人、在斯坦福教授MS&E 435课程的Apoorv Agrawal,自2024年以来一直在追踪Gen AI价值链。他的核心观察简单而令人不安:AI经济是我们所见过的每一个平台周期的倒置版本。资金流向技术栈的底部,而不是顶部。这种倒置的原因——他称之为tokenomics问题——很好地解释了为什么这个周期在结构上与云计算、移动或互联网不同。
1、倒置三角形
想想云计算经济学是如何成熟的。硬件在底部,基础设施在中间,应用在顶部。随着时间推移,价值向上迁移。到2010年代末,应用公司捕获了云计算栈中约70%的总毛利。半导体公司捕获了约6%。应用是高估值倍数所在的地方,因为那是你离终端用户最近的地方,也是边际成本接近零的地方。
AI翻转了这一点。
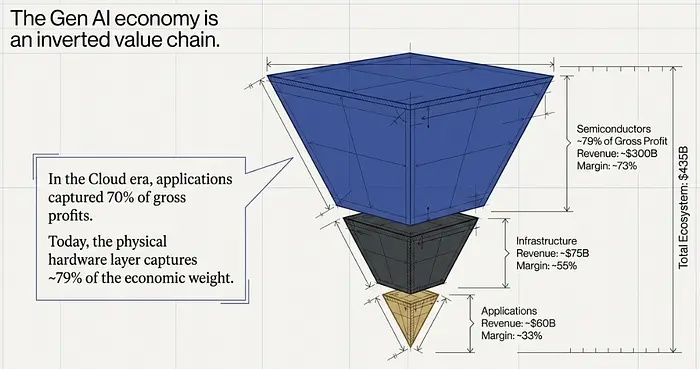
整个Gen AI生态系统现在的年收入约为4,350亿美元——比2024年初增长了5倍。但分布方式严重失衡,如果用云计算的规范来衡量,看起来会显得很不正常。
半导体捕获约3,000亿美元。基础设施占约750亿美元。应用——OpenAI、Anthropic和每个聊天机器人产品所在的层级——获得约600亿美元。半导体捕获了生态系统中约79%的总毛利。
利润率更加直白地说明了问题。NVIDIA的数据中心业务毛利率约为73%。基础设施层约为55%。应用公司平均约为33%。每一美元的AI应用收入的经济权重约为芯片美元的一半。芯片公司将这一利润率优势再投资于下一代硬件,从而保持了差距。
在云计算中,应用捕获了70%的毛利,半导体捕获了6%。在AI中,半导体捕获了79%,应用可能只有10%。技术栈几乎完全倒置了。
为什么?一个词的回答是tokenomics。
2、为什么Tokenomics改变了一切
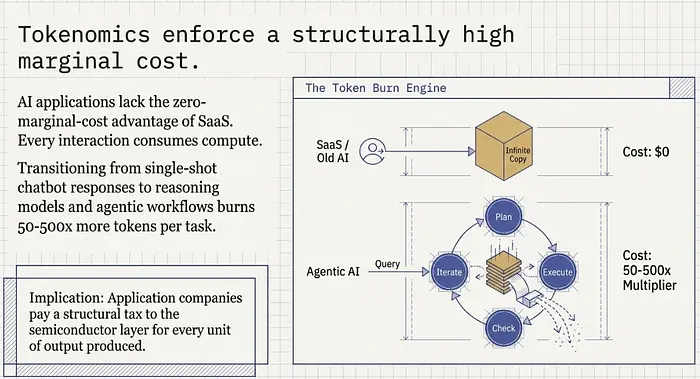
在传统的SaaS中,服务一个新用户的边际成本接近零。你构建一次软件,托管在共享基础设施上,每个额外的席位几乎都是纯利润。这就是为什么云应用公司能运行70-80%的毛利率并证明其数倍收入估值是合理的。经济学奖励靠近用户的一方。
AI不是这样运作的。与AI模型的每一次交互都消耗算力——它生成token,而token不是免费的。每个新用户、每个新查询、每个新智能体会话都在燃烧GPU周期。服务下一个用户的边际成本是正的且显著的,特别是当我们从一次性聊天机器人响应转向推理模型和智能体工作流时。
在AI中,服务下一个用户的边际成本是正的且显著的
这种转变的规模值得深思。推理模型——在回答之前逐步思考问题的那种——每个任务消耗的token可能比2023年简单的单次响应多出数量级。一个计划、执行、检查和迭代的智能体工作流可能消耗单个提示的50-500倍的token。 推理需求曲线正在变陡,而不是变平。
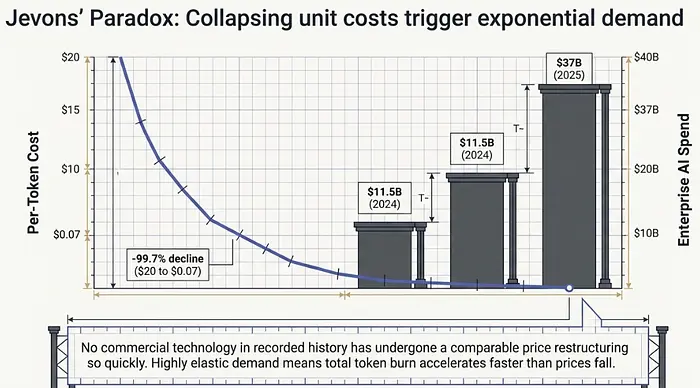
这里有一个悖论正在企业AI预算中上演:根据斯坦福AI指数,2023年到2025年间,每token成本下降了约280倍——从每百万token 20美元降至约0.07美元(GPT-3.5等效性能)。这是不到三年内99.7%的成本下降。有记录的历史上没有任何商业技术在如此压缩的时间窗口内经历过 comparable 的价格重组。
然而,企业AI支出在一年内翻了三倍,从2024年的115亿美元增至2025年的370亿美元。
当价格大幅下降且需求高度弹性时,总支出会上升,即使单位成本崩溃。经济学家称之为杰文斯悖论——它发生在煤炭、电力和带宽上,现在正在计算token上发生。
分析单位已经从每次查询的成本转移到累计月度token消耗,这些数字已经足以引起警惕,以至于FinOps基金会在其2026年报告中将AI确定为增长最快的企业支出类别。
这就是为什么应用层运行33%的毛利率而半导体层运行73%。不是因为应用公司管理不善。而是因为他们的COGS——生成使其产品工作的token的成本——在结构上高于任何SaaS公司处理过的。他们为每一单位产出向半导体层付费,而这些付款直接流向NVIDIA的利润表。
3、电动机问题
所以AI技术栈是倒置的,tokenomics解释了原因。但还有第二个令人不安的模式值得单独理解:AI投资与可衡量的生产力增长之间的差距。
Robert Solow在1987年观察到"你到处都能看到计算机时代,但在生产力统计中看不到"。全球AI投资现在每年超过5,000亿美元。OpenAI的估值在一年内从1,570亿美元增长到5,000亿美元。然而,经合组织国家的全要素生产力增长仍然顽固地停滞不前。
这里标准的史实类比是电动机。当电动机在1880年代首次出现时,工厂主做了一件完全理性但完全错误的事情:他们用电动发动机替换了蒸汽机,但没有改变工厂布局。工厂仍然是围绕中央动力源设计的,通过传动轴和架空皮带分配机械力。电动机只是放在了蒸汽机曾经的位置上。
生产力增益微乎其微。花了将近40年——直到1920年代——新一代管理者才意识到电力的真正优势是分布式动力。你可以在每个工位放一个小型电机。你可以围绕工作流程而不是动力源的位置重新设计整个工厂。只有那时生产力才开始起飞。
早期与电力相关的生产力增益微乎其微。花了将近40年——直到1920年代——新一代管理者才意识到电力的真正优势是分布式动力
Paul David在他1990年的论文《电动机与计算机》中记录了这一滞后。他的论点是,通用技术——电力、计算,以及现在的AI——需要组织、管理和业务流程的互补创新,其生产力潜力才能实现。仅靠技术是不够的。你必须重新布线工厂。
我们现在正处于AI的电动机阶段。
大多数公司正在做相当于更换蒸汽机的事情:他们将AI附加到现有工作流上,而没有重新思考工作流本身。一个客户支持团队添加了聊天机器人,但保持了相同的工单路由逻辑。一个软件团队使用Copilot,但保持了相同的冲刺结构和代码审查流程。一个法律部门使用AI进行文档审查,但保持了相同的律师配置模型。
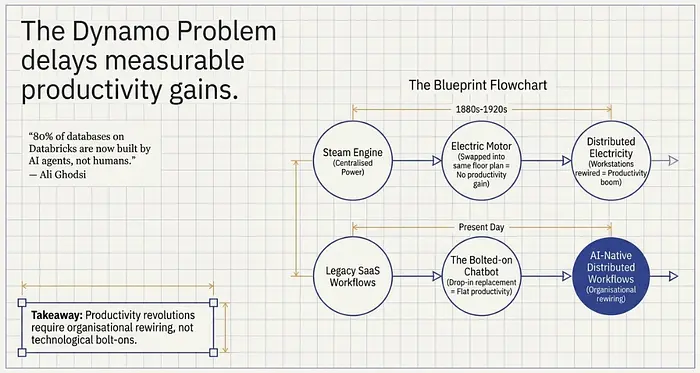
Databricks的CEO Ali Ghodsi一直在提出类似的观点。仅在他的平台上,现在有80%的数据库是由AI智能体而非人类构建的——但这并不是均匀分布的。企业采用受到他所描述的40年积累的数据架构混乱的制约:来自不同供应商的软件、跨系统隔离的数据、使甚至简单的集成都变得困难的安全顾虑。
直到公司将目前困在员工头脑中的上下文——机构知识、隐性工作流、不成文规则——放入模型中,AI仍然只是一个花哨的工具,而不是生产力杠杆。
AI带来的生产力革命将会到来。但它将来自重新布线工厂,而不是将更智能的引擎固定到现有的布局上。 而这种重新布线是组织性的,不是技术性的。它很难、很慢,不会出现在季度收益中——这正是为什么生产力统计数据仍然停滞不前,即使AI投资在爆发式增长。
4、职业阶梯正在断裂
有一个领域AI的影响已经在数据中清晰显现,而它不是大多数人预期首先看到的地方。
斯坦福数字经济实验室的Erik Brynjolfsson、Bharat Chandar和Ruyu Chen利用覆盖数百万美国工人的ADP工资数据,发表了首批关于AI就业影响的大规模实证研究之一。他们的发现:自生成式AI广泛采用以来,在AI暴露度最高的职业中,22-25岁的早期职业工作者经历了16%的相对就业下降,即使在控制了公司层面的冲击之后也是如此。软件开发人员和客户服务代理——典型的入门级知识工作角色——看到了最陡峭的下降。
这种模式是具体且具有揭示性的。不是AI在广泛地摧毁工作岗位。同一高暴露领域的年长工作者(30岁以上)在同一时期看到了6-12%的就业增长。低暴露领域的工人,如家庭健康助手,看到了相反的模式——对年轻工人的需求稳定。
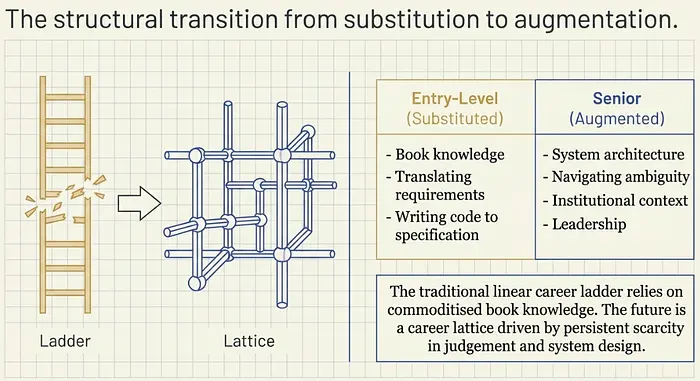
冲击集中在AI可以替代书本知识和实施技能的入门级角色上,而这些技能曾经定义了初级员工的价值。
初级软件开发人员的主要贡献是根据规范编写代码——将需求转化为实现。这正是AI编码工具擅长的事情。相比之下,高级开发人员的价值来自系统架构决策、理解机构上下文、驾驭模糊性和指导——这些是AI处理得不好的事情。 初级开发人员的梯子被踢走了,但高级开发人员的栖身之地仍然完好无损。
Chandar将年轻工作者描述为"煤矿中的金丝雀"——更广泛重组的早期信号。研究区分了自动化和增强:负面的就业影响集中在AI替代任务的领域,而不是增强任务的领域。
主要以增强型AI应用为主的职业没有出现类似的入门级招聘下降。
这种区别对于你如何思考职业策略很重要。传统的职业阶梯假设了可预测的晋升路径。Chandar提议用"职业网格"来替代它,AI赋能的学习使跨职业的横向移动变得更快、更实际。
价值从你所知道的(越来越商品化)转移到你如何运用判断力、说服力和领导力(持续稀缺)。
5、铁锹仍然在赢
所有这些对理解超级周期之所以重要,是因为经济学和人类影响通过相同的结构性原因连接在一起:计算很昂贵,计算是约束条件,谁控制了受约束的资源,谁就捕获了剩余价值。
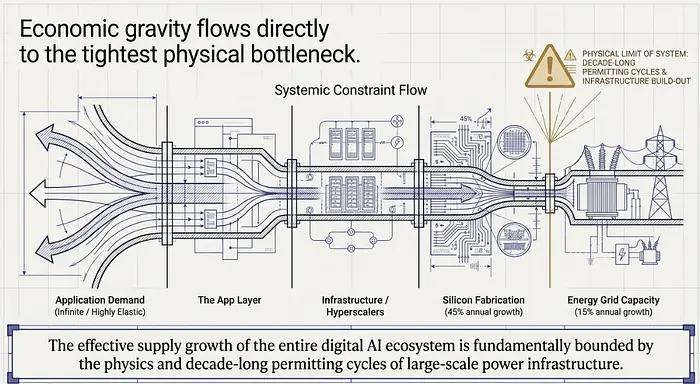
NVIDIA的数据中心业务在2025年底的一个季度就达到了620亿美元,年化约2,500亿美元。当AI计算需求以估计每年310%的速度增长,而芯片供应以约45%的速度增长时,约束是显而易见的。NVIDIA不仅从擅长制造芯片中受益——它从成为瓶颈中受益。以目前的规模,仅NVIDIA一家在过去两年增加的增量收入大约是整个应用层总和的三倍。
前五大超大规模企业——微软、谷歌、亚马逊、Meta、Oracle——2025年在资本支出上花费了约4,430亿美元,预计2026年将超过6,000亿美元,其中约75%用于AI基础设施。这些数字是前所未有的。资金流向计算,因为计算是约束整个系统的东西。
但在计算之下还有一层约束着它的东西:能源。这是瓶颈分析变得真正有趣的地方。
AI计算栈有多个依赖项,每个都以不同的速度增长。芯片生产以每年约45%的速度增长。内存带宽约28%。网络互连约35%。但AI数据中心的能源容量以每年约15%的速度增长,而计算需求以310%的速度增长。整个系统的有效供应增长受限于其最慢的组件。
但AI数据中心的能源容量以每年约15%的速度增长,而计算需求以310%的速度增长。整个系统的有效供应增长受限于其最慢的组件。
现在,那就是能源。这不是资本可以在短时间内轻松解决的问题——许可、电网互联排队,以及大规模电力基础设施的基本物理学都在十年时间尺度上运作。这就是为什么核电站重启的对话和小型模块化反应堆的部署已经成为严肃的基础设施策略,而不仅仅是绿色公关。
这就是为什么黄仁勋说能源是他唯一担心的约束——因为与芯片供应或封装能力不同,你不能通过预承诺来获得额外的50吉瓦电网电力。
投资含义:追踪瓶颈,因为那是剩余价值汇集的地方。三年来一直是芯片。现在部分是能源。随着芯片供应的扩展,约束将会迁移——到内存带宽、到网络、到任何成为新的最慢环节的东西。无论约束集中在哪里,经济学就跟随到哪里。
到目前为止,三种模式。
倒置三角形是结构性的,不是偶然的——tokenomics使应用利润率保持低位,半导体利润率保持高位,这种情况直到推理成本下降到足以使应用COGS可以忽略不计时才会解决,尽管成本下降了99.7%,但由于需求增长速度快于成本下降速度,这还没有发生。
生产力影响是真实的但滞后的——就像电动机一样,就像计算机一样——在大多数公司中,捕获它所需的组织重新布线几乎还没有开始。
劳动力市场影响已经可衡量,但比标题所暗示的要窄,集中在AI可自动化任务中的入门级角色上,而高级工作者和以增强为主的领域的工人正在经历就业增长。
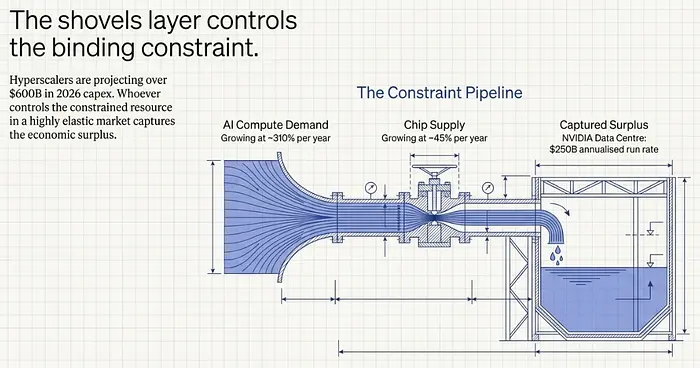
这三种模式都指向同一个方向:铁锹生意仍然是这个周期中最好的生意。
6、一个假设:我们如何知道三角形已经翻转?
如果每个先前的平台周期最终都将价值向上移动,那么问题是AI何时跟随。不是作为带有日期的预测——那些通常是错误的——而是作为带有可观察标记的假设。我们实际上需要看到什么才能得出AI超级周期已经从基础设施建设成熟为应用驱动型经济的结论?
云计算的先例是最接近的类比。
AWS于2004年推出。软件层直到2010-2012年才真正接管。在大约15年的时间里,技术栈从硬件主导转向软件主导。以AI利润份额迁移的当前速度——基础设施和应用每两年各增长约4个百分点——达到类似云计算的利润分配将需要十多年。云计算的转变花了15年。AI可能更快,但"更快"可能意味着7-10年,而不是2-3年。
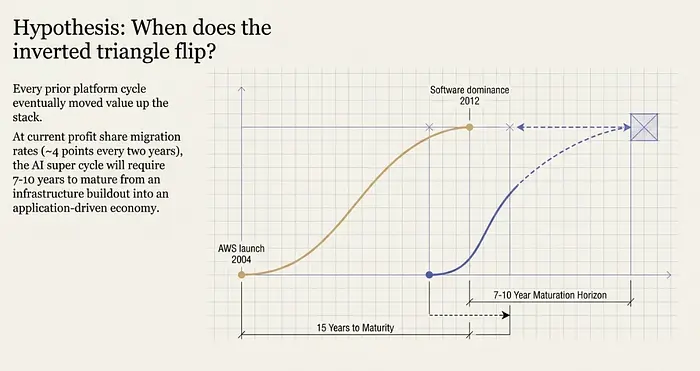
以下是我会关注的标记——不是作为确定性,而是作为倒置开始解决的信号。
推理成本通缩超过需求弹性。 目前,每token成本下降280倍导致总支出增长3倍。当成本通缩远远超过需求增长,使应用毛利率开始向50%以上扩张时——这是传统软件业务运作的水平——三角形开始翻转。我们还没有接近这个点。但成本下降的轨迹是非凡的,在某个点杰文斯悖论会饱和——需求弹性有天花板,成本通缩没有。
定制硅片碎片化NVIDIA的利润率。 谷歌的TPU项目是最成熟的替代方案,据报道已经迫使NVIDIA做出了一些价格让步。亚马逊已经部署了140万颗Trainium2芯片;其定制芯片业务的ARR已超过100亿美元。微软的Maia 200现在为一些ChatGPT工作负载提供动力。如果其中两三个项目在真正的训练规模上取得成功——而不仅仅是推理——半导体层利润率将压缩,利润将向上重新分配。这可以在NVIDIA的毛利率趋势中按季度观察。注意持续压缩到70%以下。
在支付意愿巨大的行业中应用层的崛起。 医疗保健占美国GDP的17%。教育是另一个巨大的市场。如果AI能够大规模交付有意义的个性化医疗诊断或辅导,应用收入机会将使当前的聊天机器人生态系统相形见绌。下一个万亿美元的AI公司可能根本不会看起来像聊天机器人。它们看起来会像是碰巧运行在AI基础设施上的医疗保健和教育平台。这里的信号是应用层收入开始比其运行的基础设施增长更快——这在绝对金额上还没有发生。
电动机重新布线达到临界质量。 这是直接衡量最困难但可以说最重要的一项。当公司开始报告来自AI的真正生产力增益时——不是"我们添加了一个聊天机器人"而是"我们围绕AI原生工作流重组了运营和人员编制"——那就是工厂地面真正围绕分布式动力重新设计的时候,而不仅仅是更换引擎。Ali Ghodsi观察到Databricks上80%的新数据库是由AI智能体而非人类构建的,这可能是一个早期信号。但我们需要看到这种模式在各行业中传播,而不仅仅是在数据基础设施层内。
推理在计算组合中占主导地位。 目前,GPU使用大约60%用于训练,40%用于推理。随着自主智能体开始持续工作——24/7监控、计划、执行任务,而不是响应单次提示——推理需求将以训练不会的方式复合增长。当推理超过总计算使用的70-80%时,经济学在结构上转向应用层,因为推理收入比训练收入更接近终端用户。这可以在超大规模企业的披露和NVIDIA自己的细分报告中直接观察到。
这些标记都还没有被触发。有些可能几年内都不会被触发。但它们共同形成了一个可检验的假设:AI超级周期成熟——以及三角形翻转——当组织重新布线赶上技术能力时,当token成本下降到足以给应用公司真正的利润率时,以及当约束资源从硬件供应转向更接近人类采用速度的东西时。

这个周期的长期赢家可能仍然是应用公司——就像云计算周期的长期赢家是SaaS业务,而不是AWS。最重要的构建者将是那些想清楚如何重新布线工厂的人,而不是那些将聊天机器人固定到现有布局上的人。
那种重新布线——组织性的,而非技术性的——是实际生产力增益隐藏的地方。这也是这个周期中最艰难、最有价值的工作仍有待完成的地方。
原文链接: The Inverted Stack
汇智网翻译整理,转载请标明出处
