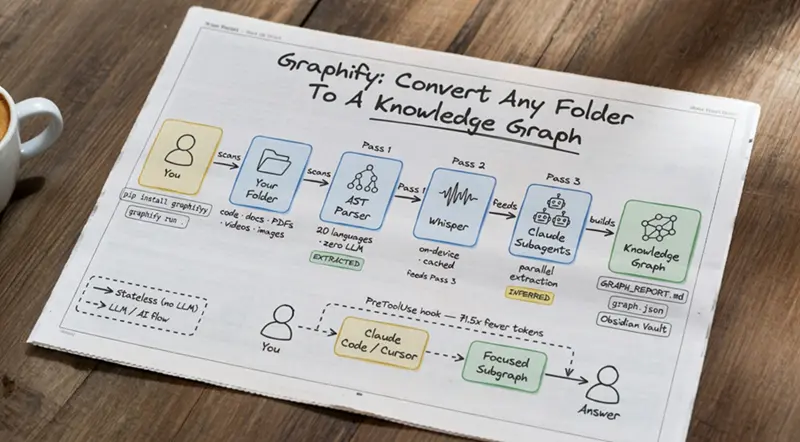
Graphify:文件夹->知识图谱
Graphify不是将原始文件喂给你的AI助手,而是从你的代码、文档、论文、图像和视频中构建一个持久的、可查询的知识图谱。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
每个在大型代码库上使用LLM的开发者最终都会遇到同样的困境:上下文窗口是有限的,但代码库不是。标准方法——将原始文件转储到提示中并希望最好的结果——在token上线性扩展,在实际理解上亚线性扩展。
Andrej Karpathy最近描述了他的个人知识工作流程:将论文、截图和推文转储到一个原始文件夹中,然后使用LLM将所有内容编译成wiki,并使用Obsidian进行导航。
他以一个挑战结束了他的描述:"我认为这里有一个令人难以置信的新产品的空间,而不是一堆hacky的脚本集合。"
Graphify就是那个产品。它对上下文采取了根本不同的方法。不是将原始文件喂给你的AI助手,而是从你的代码、文档、论文、图像和视频中构建一个持久的、可查询的知识图谱。然后它向你的AI助手提供压缩的子图。
这里是一个关于Graphify如何在幕后工作的逐步指南,以及你如何使用它将token使用量减少多达71.5倍。
1、安装并指向一个文件夹
开始使用Graphify不需要任何配置。它不是向量数据库的包装器,也不需要你设置复杂的嵌入管道。
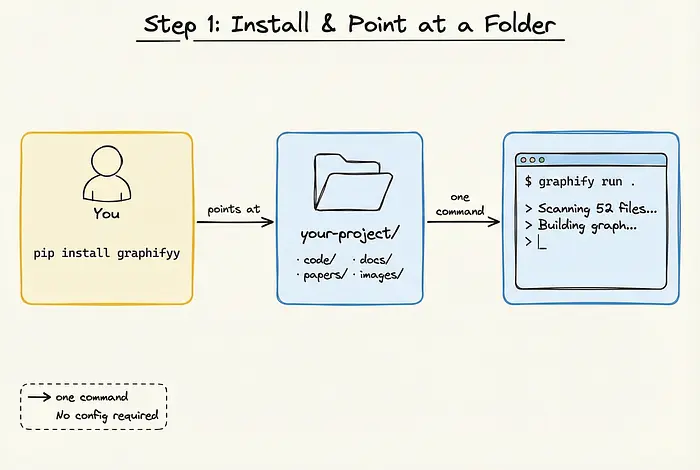
你只需要通过pip安装包(pip install graphifyy)并在项目目录中运行单个命令(graphify run .)。Graphify立即开始扫描你的文件——无论是代码、PDF、图像还是视频——并开始构建图谱。
2、第1遍:确定性AST解析
Graphify管道的第1遍完全是确定性的,在本地机器上运行。在这个阶段,没有任何代码被发送到任何LLM API。
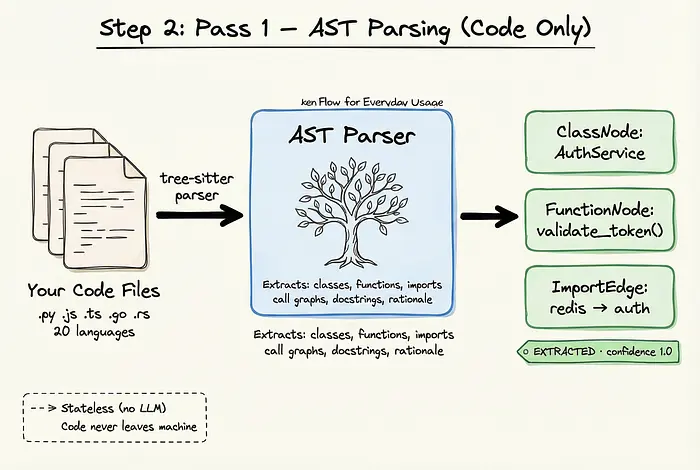
Graphify使用tree-sitter解析20种不同语言的代码。它提取类、函数、导入、调用图、文档字符串和原理注释。因为这种提取是确定性的,所以在这遍中创建的每条边都被标记为EXTRACTED的来源标签和1.0的置信度分数。你总是知道这些关系是你代码库的事实表示。
3、第2遍:本地转录
如果你的文件夹包含音频或视频文件(如录制的讲座或会议MP4),Graphify在第2遍本地处理它们。
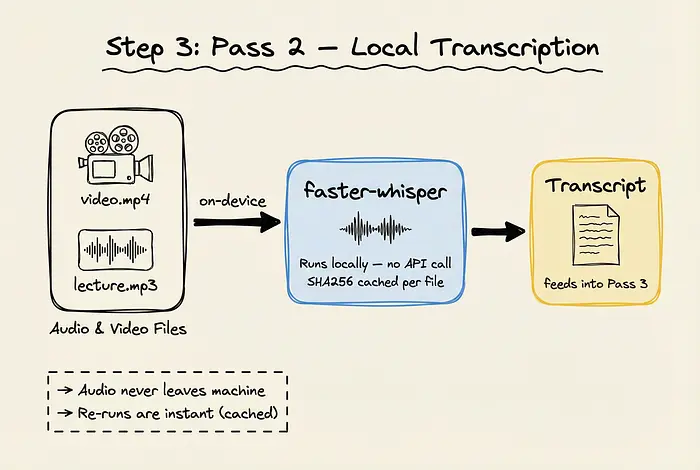
使用faster-whisper,Graphify直接在设备上转录这些媒体文件。音频永远不会离开你的机器。此外,转录本被SHA256缓存,这意味着如果你再次运行Graphify,转录步骤是即时的,除非媒体文件发生了变化。然后这些转录本被送入最终的提取遍。
4、第3遍:并行LLM提取
对于非结构化语义内容——如文档、PDF、图像和第2遍中生成的转录本——确定性解析是不可能的。这就是Graphify利用LLM的地方。
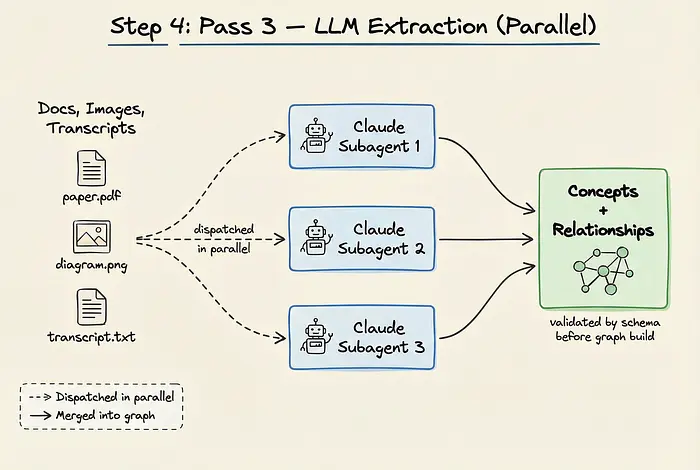
Graphify将这些文件分派给并行运行的Claude子智能体。每个子智能体读取内容并提取概念、关系和设计原理。这些子智能体的输出在合并到主图谱之前,会被严格验证是否符合模式。因为这些关系是由AI推断的,所以它们被标记为INFERRED的来源标签以及置信度分数。
5、知识图谱输出
一旦三遍完成,Graphify输出一个结构化的、持久的知识图谱。
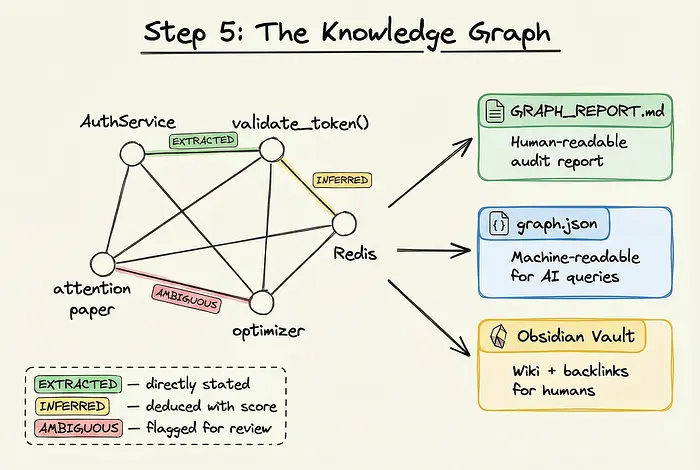
输出有三种形式:
- GRAPH_REPORT.md:一个人类可读的审计报告,总结了图谱并突出显示任何需要人工审查的AMBIGUOUS边。
- graph.json:一个为AI助手查询设计的机器可读文件。
- Obsidian Vault:一个可立即使用的wiki,带有反向链接,允许你像Karpathy的工作流程一样,以可视化和文本方式导航图谱。
图谱中的每条边都带有其来源标签(EXTRACTED、INFERRED或AMBIGUOUS),确保认识论诚实。你总是知道系统发现了什么,与猜测了什么。
6、查询图谱
当你将Graphify与你的AI编码助手(如Claude Code、Cursor或Codex)集成时,它的真正威力才得以实现。
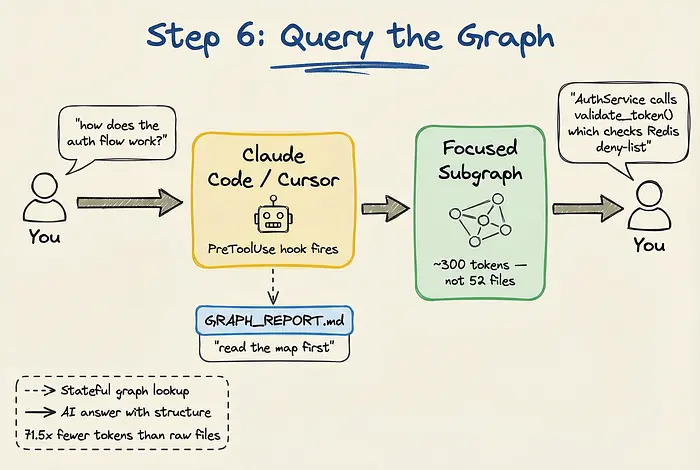
Graphify带有一个PreToolUse钩子。当你问助手"认证流程如何工作?"这样的问题时,钩子在助手开始在原始文件中grep之前触发。助手首先读取图谱映射,识别相关节点,并检索一个聚焦的子图。
不是将52个文件转储到上下文窗口中,助手接收一个高度相关的子图,可能只有300个token。这种结构化上下文允许AI在大幅减少token使用的同时提供准确的答案。
7、结束语
当你把它们放在一起时,Graphify代表了AI助手消费信息的根本转变。
论点是简单的:结构化的、压缩的、带来源标签的知识图谱是比原始文件更好的输入表示。通过将确定性提取与概率推断分离,并通过拓扑而非嵌入进行聚类,Graphify确保项目内的结构关系被保留并可查询。
图谱就是上下文窗口。其他一切只是搜索。
下一代开发者工具将不是关于向模型提供更多上下文——而是关于提供更好的上下文。分离已知与推断、压缩结构而非原始文本的工具,将定义严肃团队如何大规模使用AI。
今天就试试吧,在任何项目文件夹中运行pip install graphifyy && graphify run .。从一个你已经很熟悉的代码库开始——它产生的图谱会让你惊喜。
原文链接: How to Use Graphify: Turn Any Folder Into a Knowledge Graph
汇智网翻译整理,转载请标明出处
