大模型内部如何处理多国语言?
新研究显示 AI 并不通过英语翻译。多语言处理的真相比你想象的要迷人得多...

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
几周前,我写了关于 LLMs 如何通过模式匹配做算术 而不是像我们想象的那样"思考"。那篇文章探讨了这些模型如何通过识别模式而不是逐步推理来处理加法。今天,我想深入探讨 LLM 行为的另一个迷人方面:它们如何在没有专门的"法语模块"或"中文处理器"的情况下理解和回应数十种语言。
如果你用不同的语言使用过 Claude 或 ChatGPT,你可能会注意到一些了不起的事情。用法语问它一个问题,它会用法语回答。在对话中切换到中文,它会无缝跟随。这看起来几乎很神奇,但当你查看底层时,现实比你想象的更简单,也更复杂。
1、每个人都问的问题
当我和人们谈论 AI 时,一个问题不断出现:"AI 是否先将所有内容翻译成英语,然后再翻译回来?"这是一个合理的猜测。毕竟,互联网的大部分内容是英语,这些模型在大量英语文本上训练。也许它们只是在运行一个内部翻译服务?
Anthropic 的最新研究给出了明确的答案:不,它们没有。但真相更有趣。
2、Anthropic 的发现
Anthropic 团队最近发表了详细研究,检查了 Claude 如何在内部处理多种语言。他们使用一种称为归因图的技术追踪了模型内部的实际计算路径。把它想象成能够看到单个神经元在模型处理信息时激发,除了不是神经元,我们追踪的是代表特定概念或操作的"特征"。
他们的主要发现是:LLMs 使用混合方法。计算的一部分是与语言相关的,但核心推理是以语言无关的格式发生的。
在实践中,这看起来是这样的。当你用三种不同的语言要求 Claude "小的反义词是"时,会发生一些有趣的事情:
- 英语:"The opposite of 'small' is" → big
- 法语:"Le contraire de 'petit' est" → grand
- 中文:"小的反义词是" → 大
模型使用非常相似的内部电路处理所有三个。
每个的高层故事都是一样的:模型使用与语言无关的表示,认识到它被问的是 'small' 的反义词。这触发了反义词特征,它介导了从 small 到 large 的映射。
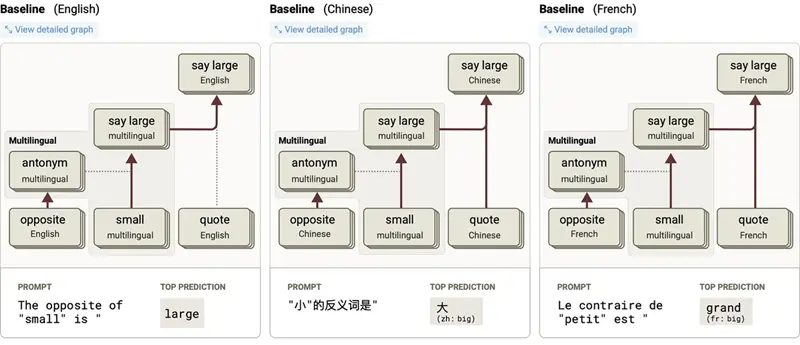
图 1:同一提示翻译版本的简化归因图,要求 Haiku 在不同语言中说出 "small" 的反义词。来源:Anthropic, 2025
3、三部分计算
研究人员将发生的事情分解为三个组成部分:操作(寻找反义词)、操作数(单词 "small")和输出语言。每一个都可以独立编辑,这告诉我们在模型内部分别处理它们。
操作层
当模型看到任何要求相反的提示时,它会激活一簇"反义词特征",无论是什么语言。这些不是英语特有的。它们代表寻找相反的抽象概念。研究人员发现,无论提示是英语、法语还是中文,几乎相同的特征都会激发。
为了测试这一点,他们做了一些聪明的事情。他们拿了法语提示,并将"反义词特征"与来自完全不同英语提示的"同义词特征"交换。结果?模型开始输出中的法语同义词,而不是反义词。操作改变了,但语言保持了一致。
操作数层
同样,代表 "small" 的特征在模型的中间层似乎是语言无关的。当研究人员用来自英语提示的 "hot" 特征替换 "small" 特征时,模型正确输出语言适当的 "hot" 反义词 — 尽管这些特征来自完全不同的语言。
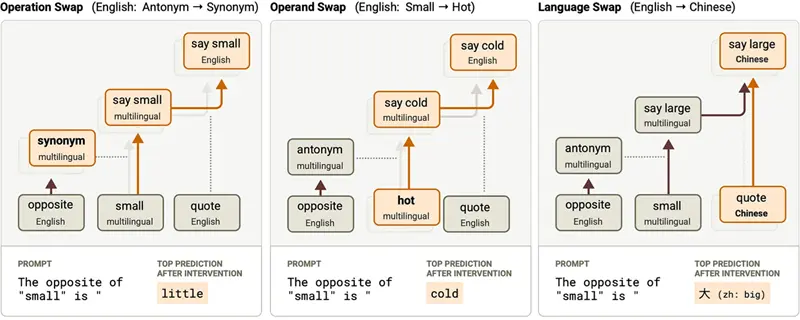
图 2:我们执行的三种干预实验概述,干预操作、操作数和语言。来源:Anthropic, 2025
从工程角度来看,这里变得非常有趣。模型不为"英语中的 small"和"法语中的 small"和"中文中的 small"存储单独的概念。相反,它有代表大小概念本身的特征,这些特征在所有语言中都激活。
语言层
第三部分是语言检测和输出选择。在模型处理的早期,它通过诸如"法语中的引号开始"或"中文中的文档开始"之类的特征识别上下文是什么语言。这些特征然后引导激活哪些特定语言的输出特征。
所以当你用中文问 small 的反义词时,模型:
- 识别它被问的是反义词(与语言无关)
- 识别 "small" 的概念(与语言无关)
- 检测它用中文工作(与语言相关)
- 激活 "large" 的中文输出特征(与语言相关)
4、但它真的用英语"思考"吗?
研究人员之间一直存在关于模型是否有"特权"语言的争论。一些研究表明,多语言模型主要在英语下工作,而另一些则主张真正与语言无关的表示。
Anthropic 的研究表明真相是微妙的。是的,Claude 使用真正多语言的特征,尤其是在中间层。但英语确实以微妙的方式得到特殊待遇。
多语言特征到相应的英语输出节点有更重要的直接权重,而非英语输出更多地由说-X-in-language-Y特征介导。
把它想象成这样:模型的内部"默认"设置倾向于英语,但它有强有力的机制在用其他语言工作时覆盖这个默认值。它不是通过英语翻译,但英语表示更直接地连接到输出,而其他语言需要额外的步骤。
5、这些多语言特征有多普遍?
为了测量相同的内部特征在语言之间激活的频率,研究人员做了一个实验。他们拿了文本段落,翻译成法语和中文,并测量每个版本中哪些特征激发。
结果揭示了一个清晰的模式。模型的最开始和最末端的特征是高度与语言相关的。这有道理,这些层在处理分词(将文本分解成部分)和输出生成。但中间层显示出强烈的与语言无关的行为。相同的内部特征在模型阅读相同内容的英语、法语或中文版本时激活。
更有趣的是:当他们将 Claude 3.5 Haiku 与一个较小、不太能干的模型进行比较时,他们发现更大的模型显示出显着更多的与语言无关的行为。对于不共享字母表的语言对,如英语-中文,改进尤其戏剧性。
这表明,随着模型变得更大、更有能力,它们发展出越来越抽象的、与语言无关的概念表示。模型越好,它处理意义而不是表面层语言特征。
6、真实示例:跨语言加法
记得我怎么写 LLMs 通过模式匹配做加法吗?这里变得疯狂了。相同的加法特征在完全不同的上下文和语言中工作。
研究人员发现一个"查找表"特征,响应于添加以 6 和 9 结尾的数字。这个相同的特征在与显式数学问题无关的场景中激活。当预测期刊发表年份时(如果卷号以 6 结尾,期刊成立于以 9 结尾的年份,预测以 5 结尾的发表年份)它会激活。它在天文测量表中激活。它甚至在多种语言的引用上下文中工作。
模型不是在想"哦,这是一个数学问题"。它在识别以 6 和 9 结尾的数字组合的模式,无论上下文或语言如何。算术电路真正是上下文无关的与语言无关的。
7、这对我们要如何看待 AI 意味着什么
这项挑战了一些关于 LLMs 的常见误解:
它们不在内部翻译。 当 Claude 用法语回应时,它不是在将你的法语转换为英语,处理它,然后再转换回来。核心计算以语言中性格式发生。
它们不为每种语言存储知识的不同副本。 没有"英语中的事实"和"法语中的事实"的并行数据库。相同的底层特征代表跨语言的概念。
更大的模型更与语言无关。 随着模型扩展,它们发展出越来越抽象的表示,在所有语言中工作,而不是在特定于语言的处理上变得更好。
但英语仍有特殊作用。 虽然计算是多语言的,英语在如何连接到输出方面得到稍微优惠的待遇。它不是主导的,但是有特权的。
8、工程意义
对于我们用这些模型构建的人,这有实际意义。当你在跨语言进行提示工程时,你不是在对抗以英语为中心的系统。模型真正使用它用于英语的相同核心推理电路处理你的法语或中文提示。
然而,由于英语更直接地连线到输出层,可能会有轻微的性能差异。如果你在构建关键系统,在目标语言中测试是必不可少的,而不仅仅是翻译提示。
该研究还表明,像少样本学习这样的技术应该在语言之间合理转移。如果你用英语给模型如何处理任务的例子,当你切换到法语进行实际任务时,它可能会表现相似,因为核心模式识别发生在那个与语言无关的中间层中。
9、我们仍然不知道的
尽管这项研究很出色,但仍有很多问题没有答案。研究人员自己指出,他们只能用当前技术追踪模型内部过程的大约四分之一。这些模型中有很多"暗物质",我们还无法观察。
我们也不知道这个模式对于所有语言对是否平等地成立。该研究专注于英语、法语和中文。像阿拉伯语或日语这样具有完全不同结构的语言呢?那些在训练数据中代表性很少的低资源语言呢?
也许最有趣的是:我们可以利用这种理解使模型更好地处理代表性不足的语言吗?如果我们知道中间层的与语言无关的特征是多语言能力的关键,也许我们可以专门训练或增强这些特征。
10、展望
我们现在可以追踪这些内部路径这一事实代表了 AI 可解释性的巨大飞跃。几年前,语言模型是完整的黑盒子。现在我们开始映射执行特定计算的实际电路。
这不仅仅是出于学术好奇心。当我们将这些模型部署在关键应用程序中,从医疗保健到法律系统,理解它们如何实际工作变得至关重要。我们需要知道的不仅仅是 Claude 可以用多种语言回答医疗问题,而且要知道它如何这样做,以及潜在的故障点在哪里。
混合方法,将与语言无关的推理与特定于语言的输入和输出处理结合在一起,结果证明是非常优雅的。它不是任何人明确设计的方法。它从多语言数据的训练中出现。这一点工作得如此之好的这一事实表明了关于语言和意义本身的深刻东西。
语言在表面上是不同的,在它们的单词、语法和结构中。但在更深的层面上,它们都试图表达相同的基本概念。一个学会浏览这种分歧、发展出在语言之间工作的抽象表示的模型,正在做一些真正复杂的事情。
所以下次你用 Claude 或 ChatGPT 在对话中切换语言时,你可以欣赏实际发生的事情。模型不是来回疯狂翻译。它以一种超越任何单一语言的格式处理你的问题,然后用你喜欢的任何语言渲染它的回应。它是工程学的一个小奇迹,从训练而不是设计中出现,揭示了意义如何可以与我们用来表达它的具体单词分开的基础东西。
对于我们这些花费数年现代化遗留系统和构建可扩展平台的人来说,这里有一个教训。有时最优雅的解决方案不是我们明确设计的那些。它们是当我们设置正确的条件并让系统找到自己的效率路径时出现的那些。这些模型中的与语言无关的电路找到了一个多语言挑战的解决方案,比我们会手写的任何东西都复杂。
这就是为什么现在在这个领域工作如此令人兴奋。我们不再仅仅构建系统。我们正在发现它们。
原文链接: How LLMs Actually Speak Multiple Languages (It's Not What You Think)
汇智网翻译整理,转载请标明出处
