如何设计生产就绪的 AI API
设计在规模化下保持可靠、处理幻觉并能在真实生产环境中生存的AI API。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
现在进入软件行业感觉有点像试图在流沙上建造砖房。我们被交付了巨大的、概率性的语言模型,并被要求将它们集成到确定性的软件系统中。业界沉迷于模型本身——参数、基准测试、上下文窗口。
但模型只是一个组件。你在其周围构建的API才是你真正的系统。
一个在你的本地机器上完美运行的脚本会在生产环境中突然崩溃。它会在流量激增时崩溃。它会在用户输入稍微异常的内容时崩溃。它会在模型悄悄决定输出字符串而不是JSON对象时崩溃。扩展AI应用需要我们对后端架构的思考方式进行巨大转变。
1、为什么AI API以不同的方式失效
传统API合约很简单。你提供特定的输入,然后获得高度可预测的输出。这种关系是确定性的。
集成LLM引入了一个根本问题:你正在将输入导入一个返回可能输出分布的系统。你不再是在设计简单的端点。你是在尝试工程化受控的不确定性。
这些API的失效模式与标准Web服务器完全不同。标准服务器抛出500错误或超时。AI API可能返回一个格式完美的200 OK响应,但包含危险地幻觉产生的事实,或者可能需要八秒才能响应,锁住你整个客户端应用。它可能随时间微妙地降低质量而不触发任何系统警报。
2、隐藏的复杂性层
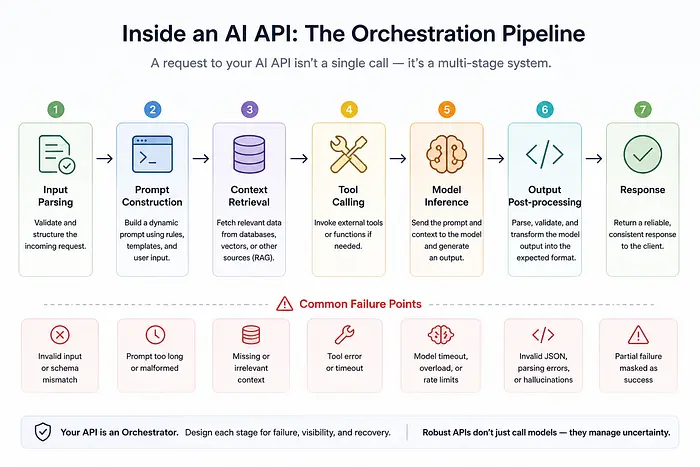
当客户端向你的"AI端点"发出请求时,他们通常假设只是在和一个围绕OpenAI或Anthropic的包装器对话。但生产级AI API实际上是一个深层多阶段管道的顶端。
单个请求通常会触发输入解析、动态提示构建、多次用于上下文检索的数据库调用、内部工具调用、实际的模型推理和严格的输出验证阶段。如果这个链条中的任何一个环节失败,API调用就会失败。你的API是一个编排器。
2.1 设计原则 #1:强输入合约
你不能信任用户输入,当然也不能信任模型能优雅地处理垃圾输入。如果你构建一个API,简单地直接将原始用户字符串传入提示,你就是在自找系统故障。
遏制工程从边界开始。你需要在其到达编排层之前验证请求的结构。
使用严格的schema来精确定义API期望什么。对用户输入强制执行最大token限制。如果你的系统不需要,拒绝包含不允许的格式或可执行代码的请求。一个错误的输入应该立即返回400 Bad Request,而不是浪费15秒的计算时间后才在生成步骤失败。
2.2 设计原则 #2:幂等性和重试安全
AI推理调用很昂贵。与标准数据库查询相比,它们也极其缓慢,这使得它们非常容易受到网络超时和客户端重试的影响。
如果客户端发送处理大文档的请求,在十秒后超时,然后重试请求,你的后端可能会意外地运行两次那个繁重的提取过程。你将为token付费两次。
像对待金融交易一样对待AI操作。每个请求必须包含一个幂等键。后端应该对照缓存检查这个键。如果操作已经在进行中,API应该将客户端附加到现有进程而不是启动新进程。
// Disclaimer: Simplified version of a production idempotency wrapper for Next.js/Node
import { Redis } from '@upstash/redis';
import { generateText } from 'ai'; // Vercel AI SDK or similar
import { z } from 'zod';
const redis = new Redis({ url: process.env.REDIS_URL, token: process.env.REDIS_TOKEN });
const RequestSchema = z.object({
idempotencyKey: z.string().uuid(),
documentText: z.string().max(10000),
});
export async function processDocument(req: Request) {
const body = await req.json();
const parsed = RequestSchema.safeParse(body);
if (!parsed.success) {
return new Response(JSON.stringify({ error: "Invalid input" }), { status: 400 });
}
const { idempotencyKey, documentText } = parsed.data;
// Check if we already processed or are processing this key
const cachedResult = await redis.get(`idemp:${idempotencyKey}`);
if (cachedResult) {
return new Response(JSON.stringify(cachedResult), { status: 200 });
}
// Set a lock so concurrent retries don't trigger duplicate work
await redis.set(`idemp:${idempotencyKey}`, { status: "processing" }, { ex: 60 });
try {
const { text } = await generateText({
model: 'your-preferred-model',
prompt: `Extract key entities from: ${documentText}`,
});
const finalResult = { status: "complete", data: text };
// Store final result
await redis.set(`idemp:${idempotencyKey}`, finalResult, { ex: 86400 }); // 24hr cache
return new Response(JSON.stringify(finalResult), { status: 200 });
} catch (error) {
// Clear lock on failure so the user can actually retry
await redis.del(`idemp:${idempotencyKey}`);
return new Response(JSON.stringify({ error: "Inference failed" }), { status: 502 });
}
}
2.3 设计原则 #3:延迟是一等约束
快速API阻塞50毫秒。AI API可能阻塞5秒。如果你按传统延迟预期设计系统架构,你的产品将完全停滞。
你必须同时管理用户期望和系统线程。如果任务很小,使用流式传输立即将数据块发送回客户端。这改善了感知性能。
如果任务很大,不要保持HTTP连接开放。将端点转换为异步作业系统。客户端提交负载并接收一个作业ID。然后客户端轮询单独的端点或通过WebSocket监听完成。此外,如果你处理的是局部的、简单的智能任务,将请求路由到小型本地语言模型或边缘WebGPU节点可以完全绕过网络延迟。将重型云模型留给重型推理。
2.4 设计原则 #4:使输出机器可读
开发者犯的最大错误是将AI模型的输出视为最终用户界面。
如果你的系统无法解析输出,你的系统就无法信任它。你必须强制执行结构化输出。几乎所有主要提供商现在都支持严格的schema解码。你定义一个JSON schema,模型在数学上被强制输出匹配该schema的数据。
这就是遏制的本质。模型不再编写自由格式的段落。它填充一个数据对象。然后你编写标准的确定性代码在前端渲染该对象。
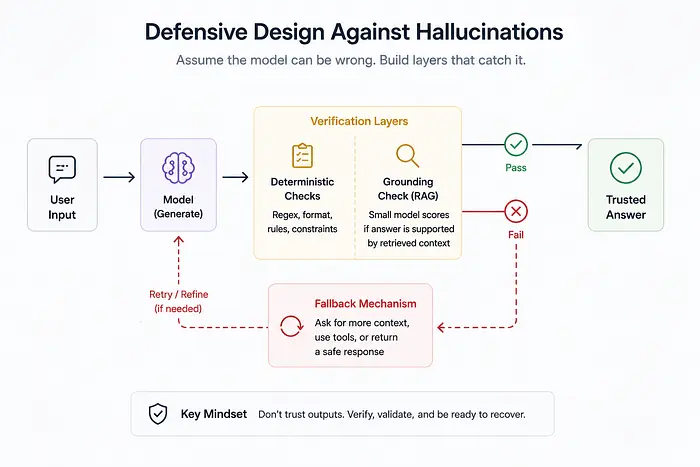
2.5 设计原则 #5:针对幻觉的防御性设计
你不能仅通过提示消除幻觉。你必须假设模型偶尔会说谎。在AI中错误不是异常;它们是默认行为,你必须主动抑制。
向你的管道添加验证层。如果模型应该从文档中提取特定的识别号码,编写一个确定性正则表达式检查以确保输出实际匹配该ID的格式。
如果你的系统依赖检索增强生成,实现一个后检查,让一个更小、更快的模型阅读最终答案和检索到的文档,并严格评分答案是否真正基于所提供的文本。如果检查失败,触发回退机制。
2.6 可观测性:缺失的那块
传统服务器日志不足以应对AI系统。知道端点返回了200状态码并不能告诉你响应的质量。
你需要跟踪token使用量以防止成本爆炸。你需要记录提示变体以查看小变化如何影响输出。最重要的是,你需要分解管道中每个阶段的延迟。请求花了六秒是因为向量搜索慢,还是因为模型难以生成最终的token?如果你无法细粒度地检查系统,你就无法扩展它。
3、真实失败案例:数据提取
考虑一个旨在自动化用户验证数据提取的真实集成工作流。目标是读取扫描文档并输出标准数据点。
如果系统依赖基本提示和标准API端点,它可能达到90%的成功率。这听起来令人印象深刻,直到你扩展到数千用户。10%的失败率创建了巨大的瓶颈。模型可能因为文档模糊而未能正确提取邮政编码,或者可能因为误解水印而给用户分配"HOLD"状态。
修复方法很少是更好的提示。修复方法是重新设计API。你在模型看到数据之前添加OCR预处理。你对输出强制执行严格的JSON schema。你编写一个确定性回退脚本,标记任何不恰好是六位数字的提取的邮政编码。你将失败的提取路由到人工审核队列而不是中断主用户流程。API架构解决了模型的局限性。
4、心智模型的转变
我们需要停止将API集成视为用户和模型之间的简单管道。构建可靠的应用需要在不可预测的智能引擎周围包裹严格的、确定性的护栏。
在未来几年中成功的组织不一定能获得更好的基础模型。它们只是围绕模型构建了最可靠、容错的系统。
模型会免费变得更好。可靠性不会。这才是真正工程开始的地方。
原文链接: How To Design AI APIs That Don't Break At Scale
汇智网翻译整理,转载请标明出处
