如何用AI检测AI生成的文本?
使用Wikipedia社区策划的AI生成内容特征,用Python构建AI文本检测器

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
自2022年11月ChatGPT推出以来,AI生成的内容持续涌入互联网。这正成为一个日益严重的问题,例如在教育领域,当学生提交AI生成的作业时。
这对Medium来说也是一个问题,因为其AI内容政策禁止付费墙文章中使用AI生成的写作[1]。
Medium是用于人类讲故事的,而非AI生成的写作。
同样,Wikipedia也在打击质量低劣的AI生成内容[2]。
LLM生成的文本通常违反Wikipedia的几项核心内容政策。因此,使用LLM生成或改写文章内容是被禁止的,除了对来自其他语言Wikipedia资料的基本复制编辑和翻译[…]
"WikiProject AI Cleanup"产生了一个社区编写的、最新的建议页面,列出了许多AI生成写作的特征,例如破折号的过度使用。
基于这个列表,我们将创建一个小应用程序,使用大语言模型(LLM)作为评判者来评估给定文本是否可能由AI生成或人类撰写。
1、AI文本检测的工作原理
检测文本是由人类还是AI撰写的并不容易。一个著名的例子包括AI检测软件将1776年的《独立宣言》标记为AI生成的概率高达98.51%[3]。
LLM在演进,所以写作风格随着每个新LLM版本的发布而变化。此外,人们可以通过使用特定的提示来避免某些明显的特征,或者通过改写句子来迷惑检测模型来避免AI写作检测。
1.1 AI文本检测系统的4种主要类型
检测AI生成的文本仍然是一个活跃的研究领域。如下图所示,检测方法可以分为四类。
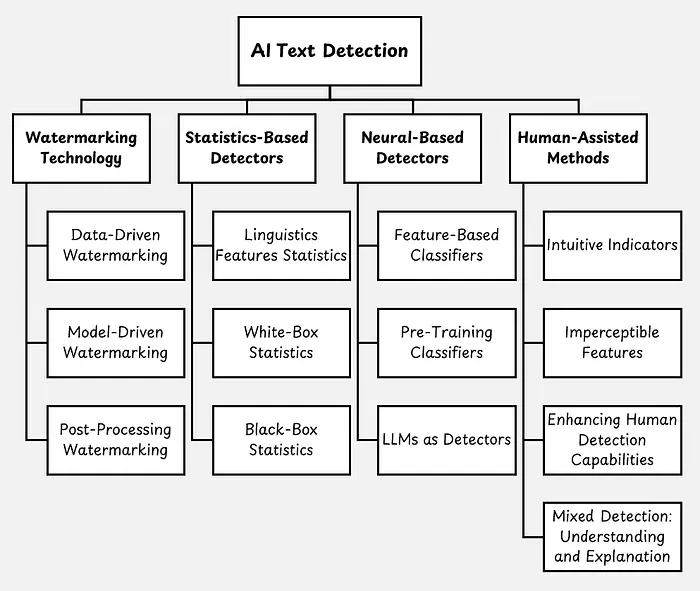
- 水印技术:LLM提供商在生成的文本中嵌入不可见的数字水印。例如,Google在其生成的图片、音频文件、文本和视频中嵌入SynthID水印。这些水印可用于检测AI生成的内容。
- 基于统计的检测器:这些检测器分析不同的文本特征来检测AI生成文本中的统计模式。如果某个特征超过特定阈值,就被视为AI生成文本的证据。例如,我们可以使用LLM的logits(概率)来计算给定文本的似然度。
- 基于神经网络的检测器:人类和AI生成的文本被用作训练数据来训练分类模型。
- 人工辅助方法:人类的直觉、先验知识和分析技能被用来识别AI生成文本中典型的不一致或错误。
1.2 困惑度和突发性:AI检测器使用的流行信号
除了研究之外,许多AI检测工具专注于基于统计的检测,包括困惑度和突发性[5]。
困惑度是一种白盒统计量,使用LLM来衡量下一个词的概率。例如,给定文本"I would love a bowl of ___,"AI最可能预测的词是"soup"。
然而,人类作家可能会写更不可预测的内容,比如"I would love a bowl of the soup you made for my birthday last year." AI生成的文本往往困惑度较低,而人类生成的文本困惑度较高。
突发性衡量句子长度和结构的变化。AI生成的文本突发性较低,通常意味着中等句子长度和一致的结构。人类生成的文本则有更多变化。
现在,让我们看看两个目前可用的在线工具是如何工作的。
ZeroGPT如何标记AI编写的文本
ZeroGPT主要是一个"基于统计的检测器"。它分析给定文本的语言学和统计信号。这些信号包括token模式、突发性、熵和在混合数据集上训练的集成分类器特征。输出是一个整体分数和看起来像AI生成的突出段落[6]。
GPTZero如何检测AI生成的写作
GPTZero是使用最广泛的AI检测模型之一。最新版本属于"基于神经网络的检测器"类别。它使用一个深度学习AI模型,在各种流行LLM的人类编写文本数据和AI生成文本上进行训练。该模型对每个句子进行分类,并提供其由AI、人类或两者生成的概率[7, 8]。
2、Wikipedia的AI写作特征
AI生成内容已经成为最大的在线百科全书Wikipedia的一个问题。"WikiProject AI Cleanup"创建了一个建议页面,包含指示AI生成文本的特征列表[9]。
这个列表对于信息性写作(如Wikipedia文章)最有用,但也适用于Medium和其他地方的博客文章。它包含与文本内容、风格、格式等相关的特征,例如ChatGPT曾经痴迷的破折号(—)的过度使用。
当然,这些特征只是观察,不是文本由AI撰写的确定性证据。然而,多个特征的积累提供了强有力的证据。
我们将使用这个特征列表来创建一个应用程序,使用LLM作为评判者,根据每个特征/类别对给定文本进行评分。输出将是文本由AI生成的概率。这个AI文本检测模型属于"人工辅助方法"。它使用人类知识创建AI特征列表。
基本思想是使用1到5的量表独立评估每个类别,然后使用分数集合得出最终结论。
这个列表最大的优点是它是社区驱动的,并且不断更新。不需要训练一个会随着每个新LLM版本而过时的AI模型。相反,我们可以使用这个可适应的列表作为提示模板。
3、使用LLM-as-a-Judge构建AI文本检测器
我们将使用Google的Gemini LLM在Python中自动评估文本的AI写作特征。
首先,我们需要安装必要的Python包。
pip install google-genai==1.73.1 dotenv pyyaml
使用Wikipedia文章作为蓝图,我们可以将选定的内容复制到categories.yaml文件中。对于每个特征,我们定义一个name、一个description和一个examples列表。
生成的文件看起来像这样:
categories:
- name: overuse_of_em_dashes
description: >
While human editors and writers often use em dashes (—), LLM output
uses them more often than nonprofessional human-written text of the same
genre, and uses them in places where humans are more likely to use commas,
parentheses, colons, or (misused) hyphens (-) and en dashes (–). LLMs
especially tend to use em dashes in a formulaic, pat way, often mimicking
"punched up" sales-like writing by over-emphasizing clauses or
parallelisms.
examples:
- You're right about one thing — we do seem to have different
interpretations of what policy-based discussion entails.
这只是一个摘录。对于这个项目,我使用了以下类别:
- 对重要性、遗产和更广泛趋势的不当强调:AI写作经常夸大主题的重要性。例如,它可能使用"关键时刻"或"重大转变"等短语。
- 肤浅的分析:AI倾向于插入肤浅的分析,通常在句子末尾添加现在分词("-ing")短语。
- 宣传和广告式语言:LLM难以保持中立的语气。
- "AI词汇"的高密度: delve, pivotal, key, …
- 负面平行结构:不仅仅是X,而且是Y。
- 三法则:"形容词、形容词、形容词"或"短语、短语和短语。"
- 标题大小写:AI倾向于将章节标题中所有主要单词大写。
- 破折号的过度使用:著名的——
- 表情符号作为格式:🚨 AI喜欢表情符号,特别是在标题或列表中。🚨
使用yaml.safe_load(),我们可以从YAML文件中将内容作为Python字典导入:
import yaml
with open("categories.yaml") as f:
data = yaml.safe_load(f)
CATEGORIES = data["categories"]
接下来,定义我们的LLM。我使用Google的Gemini 3.1 Flash Lite Preview模型。以下代码假设你在同一文件夹中有一个.env文件包含你的API密钥。你可以在Google AI Studio中为开发目的创建一个免费的API密钥。
import os
from dotenv import load_dotenv
load_dotenv()
assert os.getenv("GOOGLE_API_KEY"), "GOOGLE_API_KEY not found in environment"
使用Google的genai库,我们可以使用我们选择的Pydantic模型进行结构化的LLM调用。
from typing import Type, TypeVar
from google import genai
from google.genai import types
from pydantic import BaseModel
client = genai.Client()
T = TypeVar("T", bound=BaseModel)
def call_llm(prompt: str, response_model: Type[T]) -> T:
"""Make a structured LLM call conforming to the provided Pydantic model"""
config = types.GenerateContentConfig(
temperature=0.0,
thinking_config=types.ThinkingConfig(thinking_level="minimal"),
response_mime_type="application/json",
response_json_schema=response_model.model_json_schema(),
)
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents=prompt,
config=config,
)
text = response.text
try:
return response_model.model_validate_json(text)
except Exception as e:
raise ValueError(f"Invalid structured output:\n{text}") from e
我们将使用三个Pydantic类。首先,一个用于每个类别/特征的CategoryScore类,包含1到5的分数和一个推理字符串,为LLM提供额外的思考token并提供评分理由。
from pydantic import Field
class CategoryScore(BaseModel):
reasoning: str
score: int = Field(
...,
ge=1,
le=5,
description="Score from 1 to 5, where 1 means 'not present at all' and 5 means 'very strongly present'",
)
class AllCategoryResults(BaseModel):
results: dict[str, CategoryScore]
class Verdict(BaseModel):
reasoning: str
ai_probability: int = Field(
...,
ge=0,
le=100,
description="Estimated probability that the text was written by AI, from 0 to 100",
)
AllCategoryResults类以结构化的方式聚合每个类别的分数。这将用作生成最终判定的输入。Verdict类是LLM的输出,提供文本是AI生成的0到100之间的概率。
score_category()函数从YAML文件中读取单个类别,并指示LLM如何评估提供的文本。目标是独立地对每个类别进行评分。
def score_category(category: dict, text: str) -> CategoryScore:
examples_str = "\n".join(category["examples"])
prompt = f"""
You are an expert linguistic evaluator. Your task is to assess whether the given text exhibits a specific writing pattern.
You must be precise, consistent, and conservative in your judgments. Do not overgeneralize or infer intent beyond the text.
## EVALUATION CATEGORY:
Name: {category["name"]}
Definition:
{category["description"]}
Examples (for calibration only, do NOT copy wording or assume exact matches are required):
{examples_str}
## SCORING GUIDELINES
Score from 1 to 5 based on how strongly the pattern is present:
1 = Not present at all
2 = Possibly present (weak or ambiguous signal)
3 = Moderately present (clear instance, but limited or isolated)
4 = Strongly present (multiple clear instances or a dominant pattern)
5 = Very strongly present (pervasive, defining characteristic of the text)
Important:
- Base your score ONLY on observable text features.
- Do NOT rely on assumptions about the author or intent.
- Do NOT penalize or reward general writing quality.
- The pattern must match the definition, not just vaguely resemble it.
## OUTPUT FORMAT:
Return JSON with:
- reasoning: brief explanation of your decision
- score: 1-5
## INPUT TEXT:
{text}
""".strip()
return call_llm(prompt, CategoryScore)
final_verdict()函数使用所有类别的聚合分数来生成最终判定。我还添加了一个关于字数的简短提示,因为太短的文本不可靠,所以需要更强的证据。
def final_verdict(categories: AllCategoryResults, word_count: int) -> Verdict:
prompt = f"""
You are an impartial judge. Your task is to estimate the probability that a text was written by an AI system.
You MUST base your decision strictly on the provided category scores and reasoning.
## INPUT CATEGORY SCORES:
Each category includes:
- a score from 1 (not present at all) to 5 (very strongly present)
- reasoning describing the evidence
{categories.model_dump_json(indent=2)}
## OUTPUT PROBABILITY GUIDELINES
Use these rough anchors for calibration:
- 0-20: little to no evidence of AI patterns
- 21-40: weak or sparse signals
- 41-60: mixed or moderate evidence
- 61-80: strong evidence across multiple categories
- 81-100: overwhelming and consistent AI-like patterns
When in doubt, favor the human-written hypothesis: unless the evidence is both strong and consistent, keep the probability close to 50 rather than assigning a high AI likelihood.
## LENGTH ADJUSTMENT RULES
Text length: {word_count} words
- <50 words: low reliability -> reduce confidence
- >=200 words: higher reliability -> increase confidence
## OUTPUT FORMAT:
Return JSON with:
- reasoning: brief explanation of your decision
- ai_probability: estimated probability from 0 to 100
""".strip()
print(prompt)
return call_llm(prompt, Verdict)
analyze_text()函数运行整个流程。它返回一个包含每个类别和最终判定的字典。
import json
input_text = "Insert input text here"
result = analyze_text(input_text)
print(json.dumps(result, indent=2))
4、使用Streamlit构建UI
如截图所示,我创建了一个带有Streamlit UI的小应用,其中有一个文本区域可以粘贴文本。后端调用analyze_text(text),结果字典用于向用户显示AI概率和推理。
更多详情请查看GitHub。
5、结果:测试AI检测器
让我们用几个输入文本示例来测试应用。
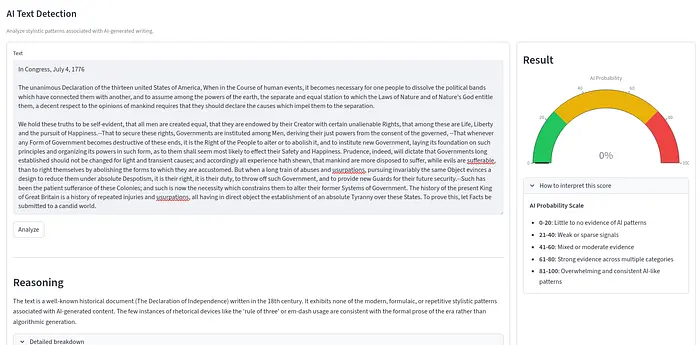
测试1:独立宣言(0% AI)
首先,我测试了独立宣言,看看历史文档是否会被误判为AI。如下所示,文本的AI概率为0%。
然而,推理显示LLM识别出文本是独立宣言,这似乎严重影响了判断。但也许这是件好事。毕竟,LLM评判者足够智能,能够推理出历史文档应该被不同地评估。
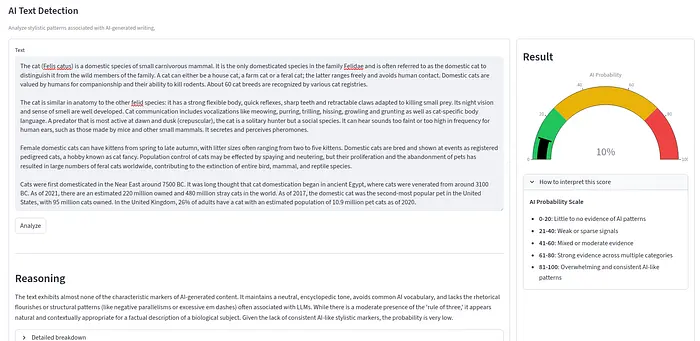
测试2:ChatGPT之前的维基百科文章(0% AI)
以下文本来自2022年1月2日的维基百科文章"Cat",比ChatGPT首次向公众发布早了几个月。因此,我假设这段文本完全由人类撰写。
测试3:100% AI生成的博客文章
我使用以下提示生成了100% AI编写的文本:
写一篇关于智能体AI的简短(300字)博客文章。
使用相同的提示,我用ChatGPT 5.3、Gemini 3和Qwen3.6-Plus生成了三个不同的AI编写文本。
所有三段文本都被判定为75%的AI概率。例如,以下是Qwen生成的文本:
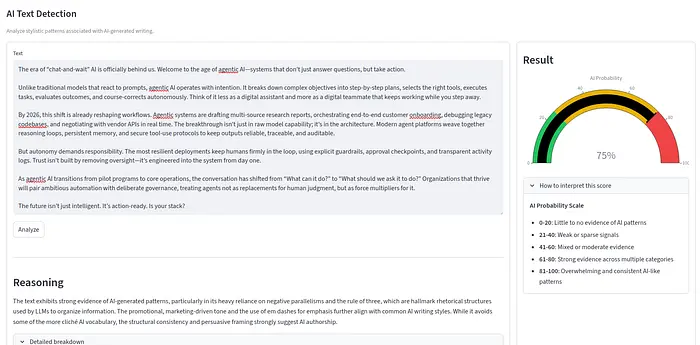
6、AI检测器对比
我测试了GPTZero、ZeroGPT和QuillBot的AI文本检测模型,将我们的应用基于Wikipedia的AI写作特征进行了比较。
结果如下表所示。每个单元格显示给定文本由AI生成的概率。绿色单元格表示正确的检测,红色单元格表示不正确的检测。
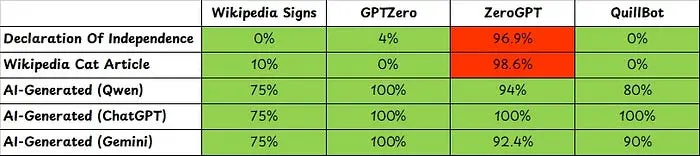
总体而言,我们的应用表现相当不错。GPTZero和QuillBot的概率更接近真实情况。特别是GPTZero在这个小实验中非常准确。
另一方面,ZeroGPT将所有内容标记为几乎100%的AI生成。这是危险的,因为这些误报可能被用来做出错误的指控。
7、结束语
在这个项目中,我们实现了LLM-as-a-judge概念,使用Wikipedia社区生成的AI生成写作特征列表自动评估文本。
我在两段人类编写的文本和三段AI生成的文本上测试了这个概念,取得了相当好的结果。
当然,还有一些可以改进的地方。首先,我没有实现Wikipedia列表中的所有规则。例如,"粗体的过度使用"是一个强指标,但在将简单文本复制粘贴到文本字段时不起作用。
也许还有其他优秀的AI指标列表,不专门针对Wikipedia文章。其他类别可以轻松添加到YAML配置文件中。例如在Medium上,我认为AI生成的封面图片和信息图是AI使用的强指标。
不幸的是,Wikipedia的AI特征列表可以通过提示LLM避免所有这些特征来被利用。这就是为什么仅依赖该列表不足以检测熟练的AI使用的原因。
检测AI写作的一个很好的解决方案是结合研究总结中AI文本检测工作原理的多个类别。Wikipedia列表是一种人工辅助方法。一个有价值的改进将是添加基于统计的方法。例如,可以评估困惑度和突发性作为额外的信号,使整体管道更加健壮和准确。
原文链接:How to Detect AI-Generated Text Using Signs of AI Writing
汇智网翻译整理,转载请标明出处
