我构建了一个智能AI报告撰写系统
一个多源智能工作流如何从异构企业源中编写结构化报告,包含证据筛选、章节级审查与修正以及依赖感知写作。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
大多数企业报告是从异构源编译而来的,包括音频/视频录音、PDF、电子表格、笔记、图像、扫描文档和专家观察。最困难的部分是在源中找到正确的信息,将其映射到正确的报告章节,遵循组织特定的模板,并保持最终报告的可追溯性。
这在各种报告中都很常见,例如检查报告、审计报告、合规文档、项目状态报告、供应商评估、可持续发展报告、销售提案和会议纪要等。在所有这些情况下,源材料都是碎片化、不均匀且特定于组织的。
编写此类报告的成本是显而易见的。每份报告需要数小时或数天的熟练劳动,这使得报告编写成为AI自动化的一个有吸引力的目标。
我的AI咨询经验表明,在各种应用中对AI辅助报告写作的需求在不断增长。我之前写过关于使用AI进行报告写作的文章:
我构建了一个用于知识提取与报告写作的Claude技能Claude技能 + MCP:从文档和媒体中提取知识,并根据你的模板生成报告
然而,使用AI进行报告写作存在某些挑战。一个挑战是源文档可能具有不均衡的权重。一个两小时的会议录音比一页议程有更多的文本。电子表格数字密集但叙述性内容少。当LLM被要求一次性地从所有内容中编写多章节报告时,章节可能会偏离轨道。它们可能相互重复,偏向于最大的源,或者产生不正确或"幻觉"信息。
编写多章节报告迫使模型同时执行多项操作。它必须分类哪些源材料与哪个章节相关,合并不同权重的文档,遵循模板,并润色文字。当一起执行时,这些操作会放大彼此的错误。
准确的AI辅助报告写作需要一个更结构化的工作流——一个将所有源归一化为通用格式、为每个章节提供其专注的证据、按照给定模板独立编写章节、对照源材料进行审查并执行精确修正、然后组装最终报告的工作流。
在本文中,我开发了一个多源报告写作软件模块,允许用户通过用自然语言定义报告结构来构建其报告写作用例。它通过逐章节的工作流(包含证据筛选、审查、修正、依赖感知写作和可复用配置)从混合输入生成结构化报告。
该工具已作为我们GAIK项目的一个软件模块构建,在该项目中我们为文档密集型工作流构建AI应用和自动化工具(参见项目的GitHub仓库)。多源报告生成器是最新的模块之一。
源代码可在GAIK-toolkit GitHub仓库的此链接获取,附有完整文档。
1、工作流如何运作
管道首先将所有输入文件归一化为通用的Markdown式证据格式。该模块将每种文件类型路由到适当的GAIK组件,例如用于文档的解析器、用于音频/视频的转录器、用于表格文件的电子表格读取器,以及用于图像的基于视觉的解析或提取。
如果提供了样本报告作为样式参考,它会按章节标题分割,这样每个章节的编写者只接收匹配的格式示例。
一旦证据包准备就绪,智能工作流就逐章节编写报告。
下图显示了完整流程,包括源归一化、可选的样本报告处理、逐章节证据筛选、草稿编写、审查、可选的润色、依赖感知执行以及最终报告组装。
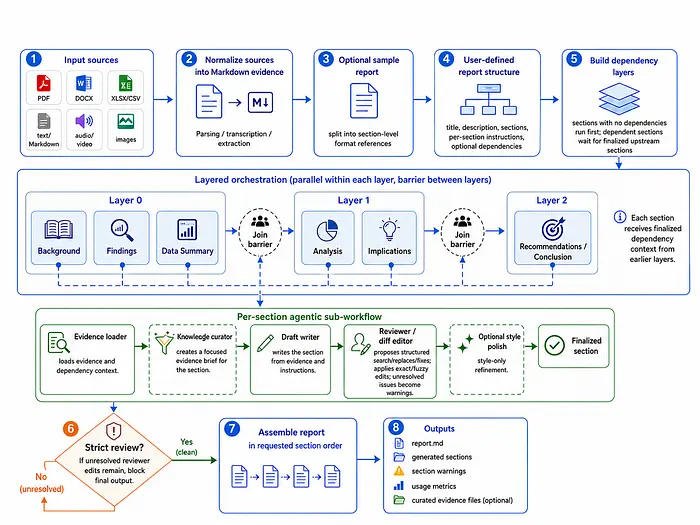
1.1 证据筛选
大型源集引入了信噪比问题。一个项目状态报告可能使用启动会录音、项目演示、KPI电子表格、会议纪要文件夹、需求文档和一组利益相关者邮件中的信息。一个关于"开放风险"的章节可能只需要其中的一小部分,而将完整的信息包送入可能会稀释信号。
在编写每个章节之前,一个筛选步骤会读取完整的归一化源集,并仅提取与该特定章节相关的内容,以生成一个聚焦的简报。编写者和审查者随后基于该简报而非整个源包进行工作。筛选后的简报被保存,因此人工审查者可以精确审计每个章节是基于什么编写的。
筛选每个章节需要额外一次LLM调用,但它持续改善基础性并使得输出更可追溯。没有它,狭窄主题的章节可能会偏向于包中最突出的源,而非实际与该章节相关的内容。
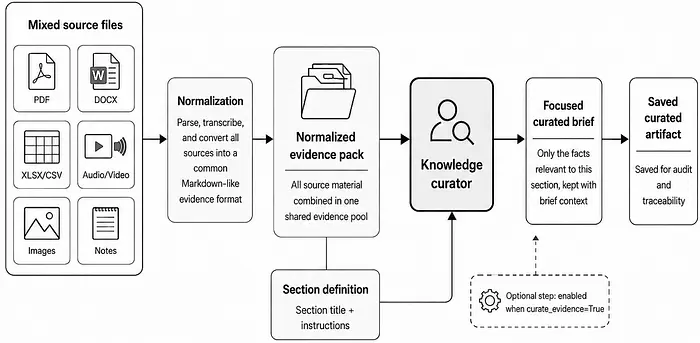
1.2 构建依赖层级
许多真实报告具有自然的层次结构。事实性章节,如背景、发现和数据摘要,可以独立于原始源编写。综合性章节,如分析、建议和执行摘要,应建立在事实性章节已确立的内容之上,而非从头推导。
用户可以通过定义某个特定章节依赖哪些其他章节来声明依赖关系。编排器读取这些声明并使用拓扑排序将所有章节分组到有序层级中。没有依赖关系的章节形成第0层。依赖于第0层输出的章节形成第1层,依此类推。依赖图在任何LLM调用开始之前被验证。
在各层之间,工作流强制执行一个连接屏障,其中一个层级中的所有章节必须完全定稿(经过筛选、草稿、审查和润色)后,下一层才能开始。一旦屏障清除,下一层中的每个章节都会收到其声明的依赖项的定稿内容以及其自身的筛选简报。
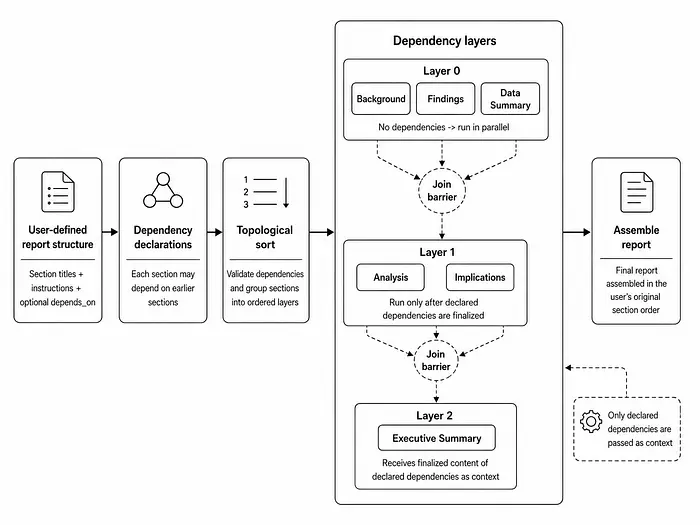
1.3 逐章节智能子工作流
在每个层级内,所有章节并行运行。每个章节独立经历相同的子工作流。
一个知识筛选器为该章节创建一个聚焦的证据简报。然后,草稿编写者根据该简报和(用户给定的)章节指令编写章节。
审查者接收编写者使用的相同证据。它对照提供的证据检查每一项主张,验证章节指令是否被完全覆盖,并且当存在匹配的样本章节时,强制执行其格式和样式。然后它提出有针对性的搜索/替换修正,并使用精确和模糊匹配在本地应用它们。
审查者不会重写章节,而只修补特定的错误。在一定次数的重试后仍无法匹配的任何修正都会被记录为警告。
一个可选的样式润色步骤在不引入新事实的情况下优化语言和流畅度。
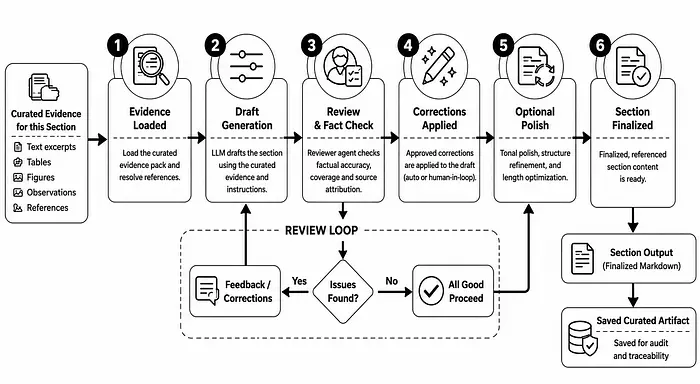
以下是分层执行在终端中的样子:
Phase 1/2 - writing 5 section(s) in parallel: Emissions and Energy Use, Sustainability Initiatives, Material Risks, Data Gaps, Future Targets
[Emissions and Energy Use] evidence loaded -> curation
[Emissions and Energy Use] curated evidence -> drafting
[Emissions and Energy Use] draft written (340 words) -> reviewer
[Emissions and Energy Use] reviewer: 2 correction(s) proposed, 2 applied
[Emissions and Energy Use] done
[Sustainability Initiatives] evidence loaded -> curation
[Sustainability Initiatives] curated evidence -> drafting
...
Phase 1/2 complete -> Phase 2
Phase 2/2 - writing 1 section(s) in parallel: Executive Summary
[Executive Summary] context: 5 dependency section(s)
[Executive Summary] evidence loaded -> curation
[Executive Summary] curated evidence -> drafting
[Executive Summary] draft written (160 words) -> reviewer
[Executive Summary] reviewer: 1 correction(s) proposed, 1 applied
[Executive Summary] done
Assembling report in requested order -> report.md
连接屏障在Phase 1/2 complete -> Phase 2处可见。这意味着工作流不会开始执行摘要,直到其配置中声明的所需早期章节已定稿。
智能工作流的编排层构建在LangGraph之上。每个章节成为编译图中的节点,带有使用合并归约器的状态对象,这样并行节点可以将它们的结果写入共享字典而不会发生冲突。
在单个层级中,图形扇出到并行的章节节点。最终组装在图运行之后进行,使用原始用户定义的章节顺序。LangGraph的有状态执行也处理了依赖关系的情况。第0层中的章节作为一个子图运行,它们的定稿内容被合并到共享状态中,第1层的章节在草稿编写之前从该状态读取。
1.4 报告组装与输出
一旦所有层级完成,章节按照用户最初定义的顺序(而非它们执行的顺序)进行组装。在第0层中编写的章节仍然可以出现在最终报告的最后。输出是一个Markdown文件,带可选的Word文档导出。生成的章节、章节警告、筛选后的证据文件和使用指标都会写入输出目录,可供检查。
2、如何使用
我将多源报告编写器打包成一个Python类,作为软件模块驻留在GAIK工具包中。它允许用户通过定义报告结构来构建其报告写作用例,包括报告标题、描述、章节、每个章节的指令、章节依赖(如果有),以及作为样式和格式模板的可选样本报告。
MultiSourceReportGenerator是主类,可以使用用户的API配置实例化一次,并通过run()方法调用。
报告编写器目前使用OpenAI或Azure API。不过,它可以轻松扩展以使用其他提供商/模型。
以下是一个入门示例:
from gaik.software_modules.multi_source_report_generator import MultiSourceReportGenerator
generator = MultiSourceReportGenerator(use_azure=False) # Using OpenAI's API
result = generator.run(
input_paths=[
"materials/",
], # Supported: .pdf, .docx, .mp3, .mp4, .wav, .xlsx, .csv, .png, .jpg, .txt, .md
report_title="Project Assessment",
report_description=(
"Assess the current project state and identify next steps for the client."
),
sections=[
# Section IDs are optional. If not provided, they are auto-generated
# from section titles using lowercase text and underscores.
# Layer 0 - no dependencies, run in parallel from the source evidence
{
"id": "emissions_and_energy_use",
"title": "Emissions and Energy Use",
"instructions": (
"Summarize Scope 1, 2, and 3 emissions figures. Report year-on-year "
"change. Note any gaps or estimates in the source data."
),
},
{
"id": "sustainability_initiatives",
"title": "Sustainability Initiatives",
"instructions": (
"List active initiatives with goal, current status, and any measurable "
"outcome. Use a structured list."
),
},
# ... other Layer 0 sections
# Layer 1 - written only after its declared dependencies are finalized
# Receives the finalized content of those dependency sections as context
{
"title": "Executive Summary",
"instructions": (
"Summarize the key emissions results, highest-impact initiatives, and "
"any material risks or gaps. Base this primarily on the finalized "
"dependency sections."
),
"depends_on": [
"emissions_and_energy_use",
"sustainability_initiatives",
],
},
],
output_dir="output/report",
sample_report_path="sample_report.md",
include_evidence_index=True,
include_source_references=True,
agentic=True,
curate_evidence=True,
polish=True,
strict_review=False,
output_docx=True,
writer_options={
"model": "gpt-5.4",
},
review_options={
"model": "gpt-5.5",
},
)
完整的选项集,包括PDF解析器选择、转录设置、图像处理、语言、输出格式等,请参阅文档。带有样本数据的完整工作示例可在此GitHub链接获取。
用例配置也可以保存到JSON文件,稍后使用save_report_config()和load_report_config()重新加载。因此,一次定义好的报告结构可以在不重新配置的情况下用于新的证据。
当设置了output_dir时,会生成以下文件:
output/
report.md
report.docx # only when output_docx=True (requires Pandoc)
evidence_index.json # index of all normalized sources
usage.json # token usage across all LLM calls
sections/ # individually generated sections
01_emissions_and_energy_use.md
02_sustainability_initiatives.md
...
06_executive_summary.md
evidence/
normalized_sources.md
curated_sections/ # curated evidence for each section
emissions_and_energy_use.md
sustainability_initiatives.md
...
3、观察与最终思考
报告编写器模块还支持一个更简单的单调用工作流(agentic=False),即在一次LLM调用中编写整个报告。它更快、更便宜;但适用于短报告、较小的证据集或可接受偶尔偏离的早期草稿。
智能工作流每份报告的成本更高,因为每个章节都会产生自己的筛选、草稿和审查调用。但是,它将错误限制在单个章节内,允许并行执行,并产生更可追溯的输出。对于面向客户或高风险的报告,智能工作流更可取。
工作流的审查部分扮演着重要角色。提出有针对性的修正而非重写整个章节的方法很有用。重写章节的审查者会丢失编写者建立的所有基础。只提出精确修正的审查者是可以验证的。
证据筛选增加了成本(每个章节额外一次调用),并且可以禁用(curate_evidence=False),但对于源数量较多的报告,它会显著改变质量特性。筛选还通过保存筛选简报使输出可审计。
依赖排序对于建立在其他部分之上的报告章节很有用。直接从原始源独立编写此类章节可能不如在其他章节已编写之后再编写准确。
报告编写器模块通过保存归一化证据、筛选简报、证据索引、章节文件、警告和使用数据来改善可追溯性。然而,内联源引用是文件名级别的引用,而非页面级别或句子级别的出处。因此,完整的审计级出处尚未实现。
一个悬而未决的问题是评估。人类专家可以审查和验证生成的报告。但纯粹的人工审查无法在多次运行或不同配置间提供一致的信号。 我们目前正在研究一个客观质量标准,可以将报告结构、内容顺序、事实准确性和所需信息的完整性结合为一个或多个量化指标。这种度量将使得比较工作流配置、调整筛选和审查设置以及系统性地捕捉回归成为可能。
原文链接: I Built an Agentic AI Report Writer That Reviews and Corrects Its Own Sections
汇智网翻译整理,转载请标明出处
