我用GPT蒸馏Llama 3.2-3B
为了节约token成本,我将蒸馏一个紧凑的 Llama 3.2–3B 模型,使其能够模仿大预言模型(GPT)的对话能力。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
大语言模型(LLM)已经可以在任何场合、任何设备上使用。
但拥有数千亿参数的 LLM 对于低延迟应用来说过于昂贵,而普通的小型模型(SLM)在准确性和一致性方面往往表现不佳。
为了解决这个挑战,我将微调一个紧凑的 Llama 3.2–3B 模型,使其能够模仿更大 LLM 的对话能力。
这需要一个三阶段的流程——SFT、RKD 和 DPO——有效地将独特的个性嵌入到模型更小的权重中。
1、我们要构建什么
我们将构建一个数字分身,模拟我们在回答问题时的个性。
下图展示了系统架构:
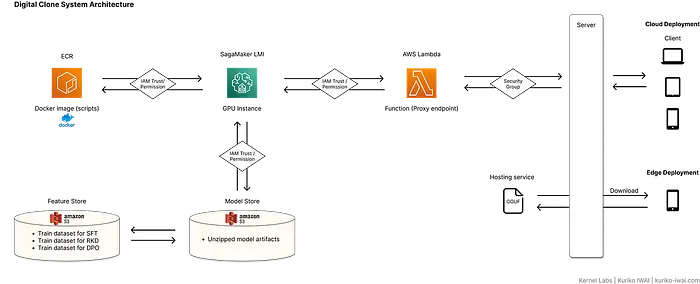
微调后的模型通过 AWS LMI 部署,配合 Lambda 函数 作为下游服务的安全代理,或者作为 GGUF 文件 分发到智能手机等边缘设备。
2、架构:混合云端-边缘部署
我将采用跨云端和边缘环境的混合部署策略。
该方法分为两个阶段:
- 云端部署: 通过简单的 API 实现跨设备(Web、移动端、平板)的快速角色测试。
- 边缘部署: 定位为高级功能,允许用户下载模型进行离线交互,实现 100% 数据隐私。
使用 Llama 3.2–3B 模型在计算能力和紧凑体积之间达到了最佳平衡。
3、云端和边缘部署策略
下表比较了云端和边缘部署的策略:
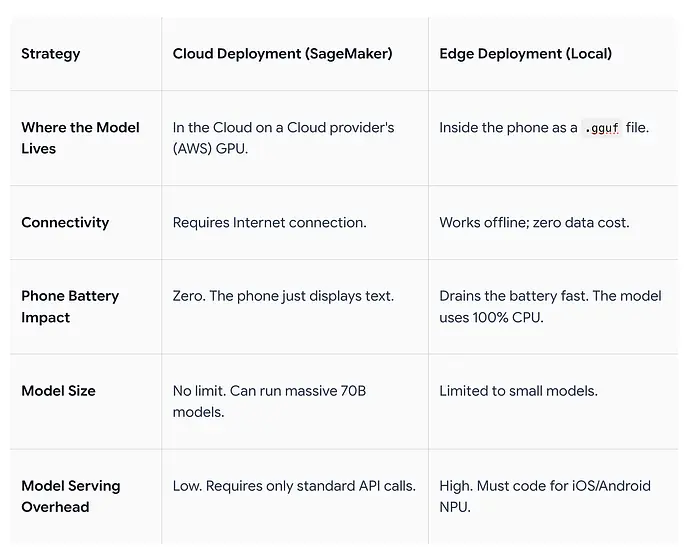
云端部署 可以托管大型模型而不受硬件限制,但需要稳定的互联网连接。
边缘部署 不需要互联网连接;然而,模型必须大幅压缩以适应智能手机的内存限制,实时推理可能导致快速耗电。
4、模型量化
在 SageMaker 的 T4 或 A10G 等 GPU 上,3B 模型非常小,量化模型反而会适得其反。
保持 BF16 格式可以确保模型保留在 DPO 期间学到的所有细微差别,无需任何压缩。
如果模型超过 8B 参数,vLLM 与 AWQ(4 位)或 FP8(8 位浮点)等格式兼容性良好,这些格式旨在让 GPU 张量核心比 GGUF 格式更快地执行计算。
5、多步模型调优流程
训练序列遵循 "学习、模仿、对齐" 流程:
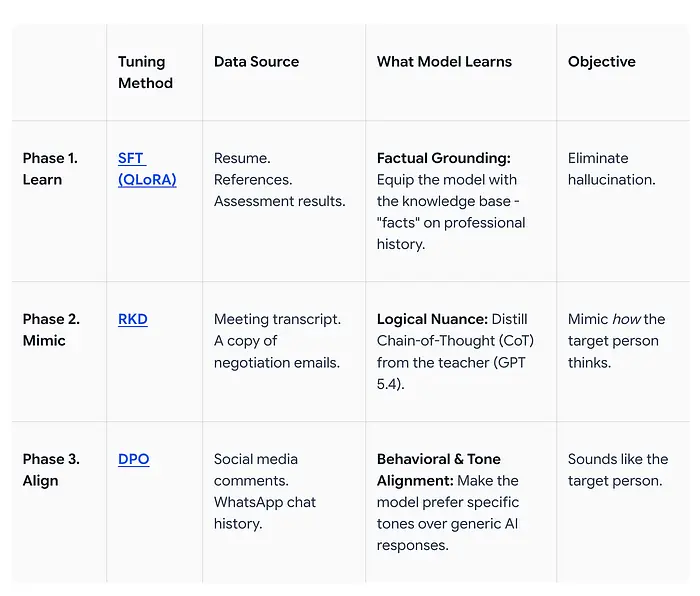
数据源可以是任何能够满足每个阶段模型学习目标的内容。
例如,在阶段 1 中,可以使用 MBTI 结果作为职业性格的真实依据。
无论哪种情况,在调优模型之前,请确保屏蔽敏感信息。
阶段 1. 学习:SFT 和 QLoRA 实现事实基础
第一阶段是将我的职业背景转化为模型,使其掌握事实真相。
在从简历和 LinkedIn 帖子等参考文档创建至少 100 个问答对后,我将训练数据集格式化为遵循 Llama 模型系列的聊天模板:
[
{
"instruction": "QUESTION_1",
"context": "CONTEXT OF THE ANSWER_1. RELATED_PROJECT ETC",
"response": "ANSWER_1"
},
...
]
然后,我将使用 trl 库的 SFTTrainer 实例执行 QLoRA(量化低秩适应):
from trl.trainer.sft_trainer import SFTTrainer
from transformers import TrainingArguments
# instantiate sft trainer
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset['train'], # HuggingFace's Dataset
processing_class=tokenizer,
peft_config=peft_config,
formatting_func=formatting_func,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
...
),
)
# train
trainer.train()
训练后的模型和分词器可以通过以下方式访问:
trained_model = trainer.model
tokenizer = trainer.processing_class
开发者笔记:合成 SFT — RKD 的另一种形式
与其手动编写问答对,不如让 LLM 从简历等参考文档中生成问答对。这是响应知识蒸馏的另一种形式,将 LLM 用作教师模型。
阶段 2. 模仿:响应知识蒸馏(RKD)实现逻辑细微差别
接下来,我将使用 GPT 作为教师模型执行响应知识蒸馏(RKD)。
这个过程将我回答背后的逻辑蒸馏到学生模型(3B 模型)中,使学生模型能够掌握回答背后的推理和语言细微差别。
首先,我将提示教师模型生成训练数据集:
阅读参考资料,生成 100 个遵循思维链(CoT)结构的示例,例如: 指令:与参考资料相关的任务或问题。 思考:根据给定的参考资料,写出我采取的内部逻辑步骤(例如,'首先,我会检查 API 日志看看 token 是否过期…')。 回答:根据给定的参考资料写出我选择的最终答案。
训练数据集将如下所示:
[
{
"instruction": "GENERAL_QUESTION_1",
"thought": "COT_1",
"response": "RESPONSE_1"
},
...
]
开发者笔记:
保持所有元素在 150 个 token 以内,因为小模型在训练示例简洁精炼时表现更好、幻觉更少,而不是冗长啰嗦。
然后,与上一阶段类似,我将使用 SFTTrainer 实例训练 3B 模型:
from trl.trainer.sft_trainer import SFTTrainer
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset['train'],
processing_class=tokenizer,
peft_config=peft_config,
formatting_func=_formatting_func,
args=training_args,
)
trainer.train()
阶段 3. 对齐:DPO 实现行为和语气对齐
最后阶段是执行 DPO,将模型与对话的语气和风格对齐。
DPO 需要带有已选答案和拒绝答案的提示:
[
{
"prompt": "QUESTION_1",
"chosen": "ANSWER_1 (aligns with tone and style)",
"rejected": "REJECTED_ANSWER_1 (sounds like AI)"
},
...
]
在生成至少 100 条训练数据后,我将使用 trl 库的 DPOTrainer 实例执行 DPO:
from unsloth import PatchDPOTrainer
from trl.trainer.dpo_trainer import DPOTrainer
# apply the patch
PatchDPOTrainer()
# initialize the trainer
dpo_trainer = DPOTrainer(
model=model,
ref_model=None,
args=training_args,
train_dataset=train_dataset['train'],
processing_class=tokenizer
)
# train
dpo_trainer.train()
6、保存调优后的模型产物
最后,我将保存模型产物:
# for cloud deployment (bf16)
model.save_pretrained_merged(
<OUTPUT_DIR>,
tokenizer,
save_method="merged_16bit", # keep the model in 16 bits
)
# for edge deployment (save the artifacts in a gguf file)
model.save_pretrained_gguf(
<OUTPUT_DIR>,
tokenizer,
quantization_method="q4_k_s", # llama.cpp quantization to compress the file
)
7、部署
最后,模型被部署到云端和边缘设备上。
这里,我将演示使用表 2.1 中描述的企业级方案进行云端部署;在 SageMaker LMI 上部署调优后的模型,使用其内置的 vLLM 引擎。
在设置专用的 IAM 角色和信任策略后,我将在 SageMaker 上创建模型:
aws sagemaker create-model \
--model-name "$MODEL_NAME" \
--execution-role-arn "$ROLE_ARN" \
--primary-container "{
"Image": "$IMAGE_URI", # sagemaker's built-in vllm container uri
"Environment": {
"HF_MODEL_ID": "$S3_PATH", \
"OPTION_TRUST_REMOTE_CODE": "true", \
"OPTION_ROLLING_BATCH": "vllm", \
"OPTION_TASK": "text-generation", \
"OPTION_DTYPE": "fp16", \
"OPTION_MAX_MODEL_LEN": "512" \
}
}"
当脚本调用 aws sagemaker create-model 时,它将必要的配置传递给 GPU 实例。当实例启动时,它会:
- 从
IMAGE_URI拉取内置容器镜像。 - 检查
Environment变量并将其应用为serving.properties参数:
option.rolling_batch=vllm表示使用内置的 vLLM 引擎。S3_PATH作为HF_MODEL_ID表示使用存储在S3_PATH中的远程模型(调优后的),而不是原始的 HF 模型(如unsloth/Llama-3.2-3B)。
初始化内置的 vLLM 引擎并在 SageMaker 上部署调优后的模型作为新模型。
开发者笔记:SageMaker 标准容器 vs LMI 容器标准 SageMaker 容器(Hugging Face、PyTorch 等)需要将模型产物打包为 tarball,即 model.tar.gz 文件,这会触发解压延迟:接收请求。→ 实例启动。→ 下载 tar。→ 将 tar 解压到默认目录:/opt/ml/model/。→ 加载权重。→ 执行推理。相反,SageMaker LMI 容器不需要 tarball;它可以直接从 HF_MODEL_ID 变量中的 S3 前缀拉取原始权重,实现更好的推理延迟:接收请求。→ 实例启动。→ 从 S3 流式传输权重。→ 加载权重。→ 执行推理。
创建模型后,我将配置专用端点:
# create an endpoint config
aws sagemaker create-endpoint-config \
--endpoint-config-name "$CONFIG_NAME" \
--production-variants "[{
\"VariantName\": \"variant-1\",
\"ModelName\": \"$MODEL_NAME\",
\"InstanceType\": \"ml.g4dn.xlarge\",
\"InitialInstanceCount\": 1
}]"
# create a dedicated endpoint and attach the config
aws sagemaker create-endpoint \
--endpoint-name "$ENDPOINT_NAME" \
--endpoint-config-name "$CONFIG_NAME"
8、为什么选择 vLLM?
PagedAttention 和 LLM 流式传输。
vLLM 原生内置在 SageMaker 异步推理和 LMI 中,因此我不需要显式加载独立的 vLLM 包。
即使是 3B 这样的微小模型,使用 vLLM 也是出于三个具体原因的战略选择:
- 大规模并发: 所有用户无延迟。
- 成本: 榨取更多显存。
- 人类感受: 文字逐词出现。
8.1 大规模并发
标准推理引擎(HuggingFace)的延迟随用户增加而线性增长。当用户 A 问了一个长问题时,用户 B 必须等模型完成用户 A 整个 回复后才能开始处理。
vLLM 使用连续批处理,系统在还在处理用户 A 的段落一半时就开始为用户 B 生成回复。当应用有多人同时与分身对话时,vLLM 确保没有人感到延迟。大规模并发下的延迟几乎保持平稳。
8.2 成本
vLLM 可以在廉价硬件上榨取更多性能,因为其 PagedAttention 动态管理 KV 缓存,在长对话中没有 OOM 风险。
8.3 人类感受
vLLM 原生支持高速流式传输,兼容 OpenAI API 格式,这对分身应用至关重要,因为文字逐词出现对于营造生命感至关重要。
原文链接: How I Used SFT, Distillation, and Preference Tuning to Create a High-Performance SLM
汇智网翻译整理,转载请标明出处
