我用PageIndex替换了向量库
如果你已经构建RAG系统有一段时间了,你知道这种沮丧。你花几个小时设置嵌入、调整块大小、选择正确的向量数据库,然后你的系统仍然返回错误的答案。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
如果你已经构建RAG系统有一段时间了,你知道这种沮丧。你花几个小时设置嵌入、调整块大小、选择正确的向量数据库,然后你的系统仍然返回错误的答案。不是因为它找不到相似的东西。而是因为「相似」和「相关」根本不是一回事。
我在处理财务报告时遇到了这个问题。一份120页的10-K文件。我的向量RAG系统不断从执行摘要中提取片段,而实际答案却埋在第87页的脚注中。两个部分都有相似的关键词、相似的语义,但只有一个有我需要的具体数字。
那就是我找到PageIndex的时候。
1、PageIndex到底是什么?
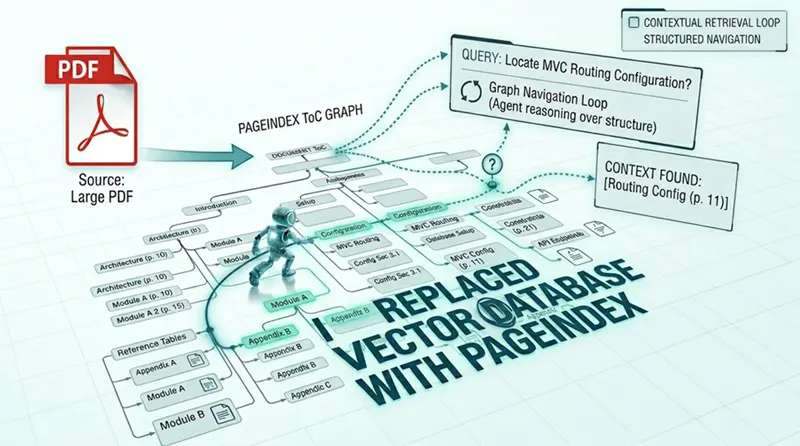
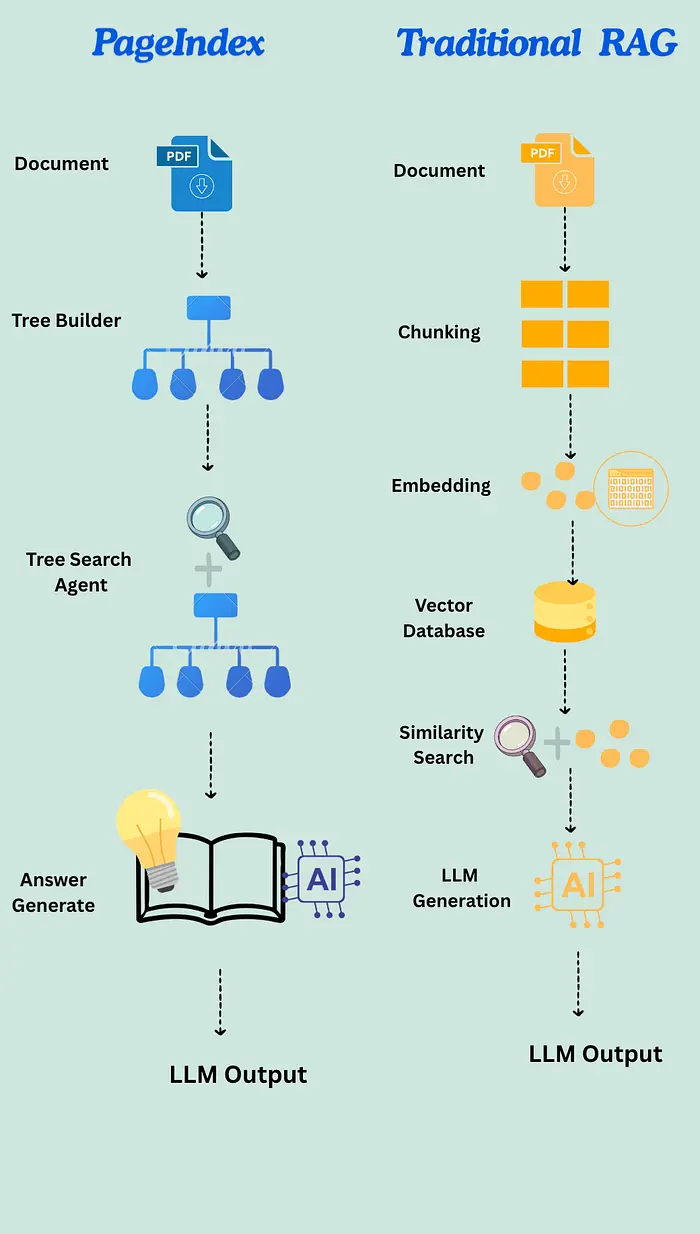
PageIndex 是一个由VectifyAI团队构建的开源RAG框架。核心概念简单但与其他的完全不同。PageIndex不是将你的文档转换为向量并做最近邻搜索,而是从你的文档构建一个分层树结构,然后使用LLM推理出正确的答案。
没有嵌入。没有向量数据库。没有分块。
他们称之为「无向量RAG」,老实说这个名字非常准确。
该项目于2025年9月推出,很快获得了很多关注。主要是因为一个基准数据:在FinanceBench上达到98.7%的准确率。作为参考,传统的向量RAG系统在相同基准上的分数约为50%。这不是一个小改进。这是一个完全不同的性能类别。
2、向量RAG的问题(没有人足够诚实地谈论)
在我们了解PageIndex如何工作之前,让我们诚实地对待向量RAG为什么会挣扎。
向量RAG的基本假设是:与你的查询语义最相似的文本也是最相关的。这个假设在现实世界中不断被打破。
想想它。如果你问「2023年公司的总债务是多少?」返回的高余弦相似度的片段可能包括:
- CEO提及债务管理策略的信
- 讨论债务契约的风险部分
- 长期债务的词汇表定义
这三者在语义上都接近你的查询。都不 是实际答案,实际答案在第64页资产负债表上的具体数字。
还有其他几个问题。
- 分块破坏上下文。 当你将100页文档分成500-token的块时,你正在丢弃文档的自然结构。一个说「如表3.2所述」的部分一旦你将它们分开分块,就与表3.2完全断开连接。文档有逻辑和流程。分块忽略了所有这些。
- 交叉引用对向量不可见。 文档经常说「见附录G」或「参考第4节中上一年的数字」。向量相似性无法遵循这些引用。它只是将它们视为与其指向的地方没有联系的文本片段。
- 查询表达意图,而不是内容。 当用户提问时,他们表达的是他们想知道什么,而不是答案的样子。答案可能使用与问题完全不同的词汇。向量检索在这里很挣扎,因为它将问题文本与答案文本进行匹配。
3、进入PageIndex:推理检索
这是使PageIndex与众不同的思维转变。
PageIndex不是问「哪些块看起来与这个查询相似?」,而是问「如果我是一个人类专家,我会在文档的哪里找到这个问题的答案?」
这是一个完全不同的检索策略。而且对结构化、复杂的文档效果更好。
4、它实际上是如何工作的
PageIndex分两个主要阶段工作。
阶段1:构建索引(目录树)
PageIndex不是将文档分块成500token的片段,而是提取文档的固有结构:
- 标题和副标题
- 表格和图表
- 页码
- 章节编号
它从这些元素构建一个树结构。这保留了文档的逻辑组织——章节、节、小节、表格、数字。
在这个树结构中,每个节点代表一个逻辑部分。每个节点包含:
- 部分标题
- 起始页
- 结束页
- 该部分的原始文本
- 任何子部分
然后,阶段2:检索(通过推理)
当查询进来时,PageIndex不是做向量相似性搜索。它使用一个LLM来推理:
「如果我是一个专业会计师审计这份文件,
找出第64页资产负债表中2023年总债务,
我首先会看哪里?我会跳过哪些部分?」
LLM实际上是在模拟人类专家会采取的思考过程。它遍历文档结构,遵循逻辑流程,并在正确的位置找到答案。
这与关键词搜索或向量相似性完全不同。这是一个推理问题。
5、内部一瞥
让我展示实现的核心部分。
步骤1:加载文档
from pageindex import load_document
doc = load_document("10k_filing.pdf")
# 构建目录树
toc_tree = doc.build_toc_tree()
步骤2:查询驱动的导航
def retrieve(query: str, toc_tree) -> str:
# LLM决定看哪里
nav_prompt = f"""You are a financial expert analyzing this 10-K filing.
Given the question: {query}
Which sections would you check? Return the section IDs.
QUESTION: {query}
SECTIONS:"""
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=nav_prompt,
)
# 解析选定的section IDs
section_ids = parse_section_ids(response.text)
# 提取这些section的文本
context = fetch_sections(section_ids, toc_tree)
return context
步骤3:Context Retrieval
这不仅仅是返回原始文本。PageIndex将整个section拉入context——不仅仅是匹配的块,而是整个相关部分。这保留了flow和逻辑连接。
def fetch_sections(selected_ids, section_map):
context_parts = []
for sid in selected_ids:
if sid in section_map:
sec = section_map[sid]
context_parts.append(
f"--- Pages {sec['start_page']}-{sec['end_page']} ---\n"
+ sec["text"][:3000]
)
return "\n\n".join(context_parts)
步骤4:答案生成
检索的文本与原始问题一起发送给Gemini。该模型综合一个精确的答案,并带有页面级的引用。
def generate_answer(query: str, context: str) -> str:
prompt = f"""Answer the question using only the provided context.
Be specific. Include exact numbers, technical terms, and cite page numbers.
CONTEXT:
{context}
QUESTION: {query}
ANSWER:"""
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=prompt,
config=types.GenerateContentConfig(temperature=0.1),
)
return response.text.strip()
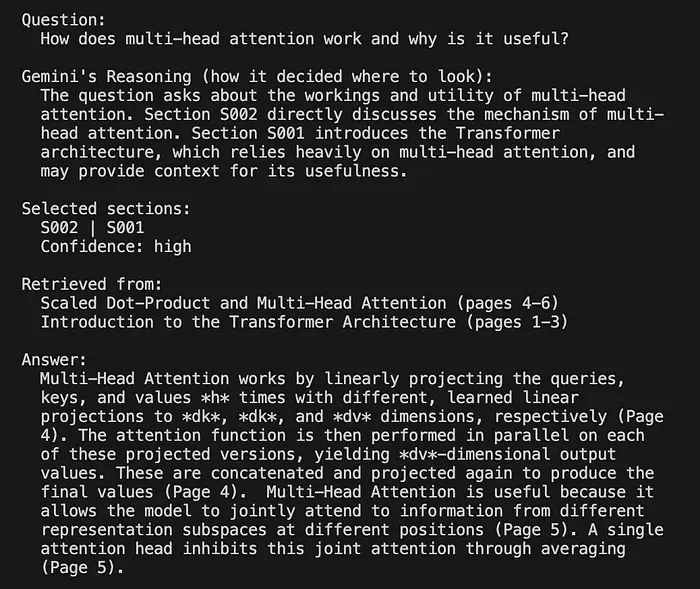
一些生成的答案😃:


6、PageIndex vs传统向量RAG
7、什么时候应该使用PageIndex?
这是最重要的问题。PageIndex不是每种情况下都替换向量RAG。它是针对不同工作的不同工具。
在以下情况下使用PageIndex:
你正在处理单一的长结构化文档,其中准确率比速度更重要。财务文件、法律合同、监管文件、技术手册、学术论文。任何文档有有意义的层次结构,以及「差不多」不够的地方。
你需要可解释性。你的用户或利益相关者需要知道答案来自哪里。PageIndex为你提供完整的推理trace,包含section引用和页码。
你在为受监管的行业构建。金融、法律、医疗保健。这些领域错误的答案会产生真实的后果。98.7%的准确率数字在这里很重要。
坚持使用向量RAG当:
你在搜索大量文档集合,需要找出哪些是相关的。向量RAG非常适合这个。PageIndex设计用于深入一个文档,而不是从一千个文档中找到正确的文档。
你需要高吞吐量和低延迟。PageIndex每个查询进行多个顺序LLM调用。这在规模上累积成本和时间。
你的文档很短、非结构化或对话式的。PageIndex的优势是导航文档层次结构。如果没有层次结构可以导航,你就失去了优势。
两全其美: 使用向量搜索从你的集合中找到正确的文档,然后使用PageIndex从该文档中提取精确答案。像这样的混合方法给你两个系统最好的。
8、最终想法
PageIndex真正做的是将检索视为一个推理问题而不是相似性问题。
而且这个转变超越了文档检索。这个想法也出现在其他地方。例如,Claude Code据报道已经放弃了基于向量的代码检索,转而支持推理驱动的方法。模式变得更清晰:当任务需要理解结构和遵循逻辑时,推理胜过相似性。
向量数据库不会消失。它们快速、可扩展,非常适合大量集合的语义搜索。但对于困难的问题「在这份复杂文档中找到我确切想要的信息」,推理优先的方法正在获胜。
PageIndex现在是这个想法最好的实现之一。它是开源的,有一个干净的API,基准测试结果不言自明。
如果你正在构建涉及密集专业文档的任何东西,我强烈建议尝试它。向你询问200页报告中精确问题的用户会感谢你。
原文链接: I Stopped Using Vector Databases for RAG : PageIndex Vectorless RAG
汇智网翻译整理,转载请标明出处
