LCM:无损上下文管理
LLM 受限于它们能够记住的 token 数量,那么接下来是什么?

AI编程/Vibe Coding 遇到问题需要帮助的,联系微信 ezpoda,免费咨询。
最近,上下文窗口已经成为 AI 领域每个人都在痴迷的新热词。无论是 ChatGPT、Claude 还是 Gemini,大家都在比拼谁能记住最多的 token。但问题是,仅仅因为 LLM(大语言模型)可以在脑海中容纳 100 万个 token,并不意味着它真的能完美地理解或记住所有内容。通常,随着对话变得越来越长,模型开始感到困惑,一个专家们称为上下文腐烂的问题开始出现。
今天,我们将深入探讨无损上下文管理(LCM),这是一种旨在解决上下文腐烂的技术。这是由 Voltropy 团队开发的一种新的 LLM 记忆处理方法,它不仅仅是向模型扔数据,而是通过适当的组织级别来管理数据。
让我们深入了解 LCM 的核心思想,看看为什么它可能是未来 AI 代理的工作方式。
1、什么是无损上下文管理(LCM)
在核心层面,LCM 是 LLM 记忆的确定性架构。简单来说,它是 AI 大脑的智能归档系统。LCM 不是让 AI 猜测它应该从长对话中记住什么,而是使用严格的、引擎管理的过程来确保重要信息永远不会丢失。
名称中的无损部分是一个巨大的承诺。这意味着会话中的每一条消息、工具调用或文件内容都会逐字保存到称为不可变存储的永久记录中。即使对话持续数天并涉及数百万个词,系统也总是可以深入查找并在需要时找到确切的原始数据。
这就像拥有一个个人助理,他不仅为你记录会议摘要,还将原始音频录音完美地编入索引并准备播放。
2、现有方法:为什么常用技巧还不够
在 LCM 之前,我们如何处理长上下文?大多数人使用检索增强生成(RAG)。RAG 就像在你自己的笔记上使用搜索引擎;它非常适合查找特定事实,但经常丢失对话的流程。你得到信息的片段,但丢失了"谁说了什么以及为什么"的部分。
然后出现了递归语言模型(RLM)。这是一个更大胆的方法,AI 被赋予使用脚本和循环来管理自己记忆的权力。虽然这听起来很酷且灵活,但它有点像把戏,因为它是随机的,意味着它是不可预测的。有一天,AI 可能会写出一个很棒的脚本来总结它的笔记,而第二天,它可能会失败或陷入循环,浪费你的时间和金钱。这就是开发人员所称的GOTO 风格的内存管理,它很强大,但容易出现错误和混乱的逻辑。
3、深入探讨:LCM 背后的技术
LCM 为记忆引入了结构化控制流。它将管理记忆的负担从 AI 模型本身转移回系统引擎。以下是 LCM 引擎室的实际工作方式:
双状态记忆架构:LCM 使用两个独立区域。不可变存储是事实的来源,其中所有内容都被永久保存。活动上下文是工作台,这是在给定时间实际发送给 LLM 的小信息窗口。
分层 DAG(有向无环图):而不是扁平的消息列表,LCM 构建树状结构。随着工作台变满,旧消息被压缩成摘要节点。这些摘要不仅仅是文本;它们是指向原始数据的指针。如果模型看到摘要并且需要更多细节,它可以使用名为 lcm_expand 的工具再次查看完整的原始消息。
三级升级协议:AI 的一个大问题是,有时当你要求它总结 100 个单词的段落时,它会给你一个 150 个单词的摘要!这被称为压缩失败。LCM 通过严格的三步过程修复了这个问题:首先,它尝试正常摘要;如果太长,它尝试激进的"项目符号"摘要;如果仍然失败,它使用确定性的"硬切割"来确保上下文窗口永远不会溢出。
操作员级递归(LLM-Map):不是要求 AI 编写for 循环来处理 1,000 个文件(它可能会搞砸),而是给它一个名为 LLM-Map 的确定性工具。模型只是说将此提示应用于所有这些文件,引擎会通过并行处理、适当的错误检查和重试来处理其余部分。这就像给 AI 一个高速装配线,而不是手动锤子。
大文件处理:我们都知道日志文件或数据集有多大。LCM 不会尝试将这些文件塞进上下文窗口。它将它们存储在磁盘上,只给 AI 一个文件 ID 和一个小的探索摘要。这样,AI 知道文件存在以及文件中有什么,而不会因为太多数据而感到"头痛"。
4、Volt vs. Claude
在 Voltropy,研究人员使用 LCM 架构构建了一个名为Volt的编码代理,并与Claude Code进行了测试,Claude Code 目前被认为是市场上最好的工具之一。他们使用了一个名为OOLONG的基准测试,它专门测试 AI 在非常长的上下文上的推理能力。
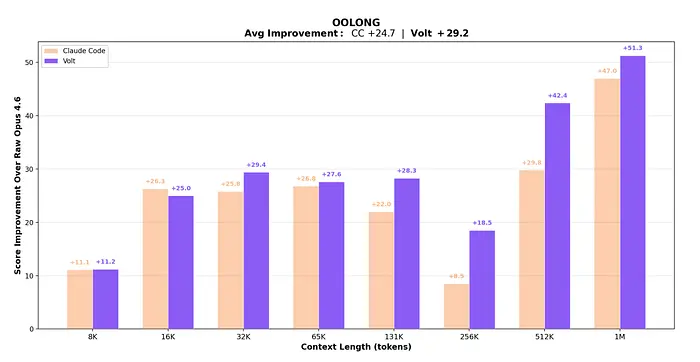
结果非常出色!
• 整体性能:Volt 达到了平均 74.8 分,而 Claude Code 为 70.3 分。
• 长上下文胜利:在较短长度(8K 到 16K token)时,两者几乎相等,因为整个任务可以放入模型的"原生"内存中。但一旦达到32K token 及以上,Volt 开始显著领先。
• 1M Token 测试:在巨大的 100 万 token 时,Volt 比 Claude Code 高出 4.3 分。
• 稳定性:虽然原始模型(没有 LCM)在 65K token 后性能急剧下降,但 Volt 的准确性在更高长度下保持稳定甚至增加。这是因为引擎管理的"装配线"(LLM-Map)即使数据增长也能保持一切井井有条。
5、LCM的优缺点
像生活中的一切一样,LCM 也有其起伏。
优点:
• 确定性可靠性:你不必祈祷 AI 正确管理其记忆;引擎会为你做这件事。
• 无损记忆:无论过了多长时间,你总能找到事实真相的原始数据。
• 零成本连续性:对于小任务,LCM 不会增加任何额外的延迟或成本。只有当对话变得很长时,它才开始其"艰苦工作"(压缩)。
• 效率:它使用并行处理(LLM-Map)来处理巨大的数据集,比模型逐个读取文件快得多。
缺点:
• 灵活性较低:与 RLM 方法不同,AI 无法发明自己的记忆策略;它必须遵循引擎的规则。
• 复杂性:设置数据库(如 PostgreSQL)来处理上下文与仅发送简单的 API 调用相比,增加了一些工程紧张感。
• 工具依赖:模型必须经过训练或提示才能有效地使用特定工具,如 lcm_grep 和 lcm_expand。
6、结束语
最后,无损上下文管理是使 AI 代理能够在长期项目中工作而不会迷失情节的一大步。虽然 RLM 方法希望模型成为一台能够做所有事情的通用计算机,但 LCM 相信为模型提供结构化的高质量工具,以便它可以专注于推理而不是归档。
这就像凌乱的桌子找不到钥匙和高科技数字图书馆之间的区别。随着我们走向更复杂的 AI 系统,这种以架构为中心的方法可能是构建可靠的、生产就绪的代理的最佳方式。所以,下次你的 AI 开始忘记你十分钟前说的话时,记住,它可能只需要一点 LCM!
原文链接: Lossless Context Management — Overcoming Context Rot In LLMs
汇智网翻译整理,转载请标明出处
