LLM微调不太实用
我从2023年到现在进行了几次实验,最新的是使用Gemma 4。在所有这些之后,我得出了一个许多人也达成的结论:微调LLM以注入知识通常不值得努力。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
自从ChatGPT之后第一波较小的开源模型出现以来——像BLOOM、Flan,甚至GPT-2这样的模型——我一直在进行一个长期的探索,即在自定义数据集上微调它们。
最初的目标是知识摄取:在特定领域教授较小模型领域特定知识,使其能够充当虚拟助手。
我从2023年到现在进行了几次实验,最新的是使用Gemma 4。
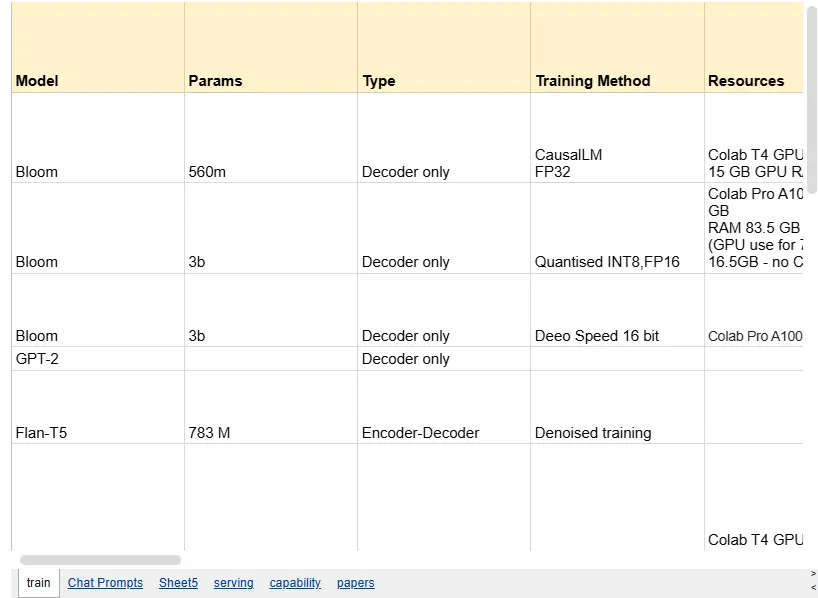
在所有这些之后,我得出了一个许多人也达成的结论:
微调LLM以注入知识通常不值得努力。
这可能听起来很刺耳,特别是因为微调是一个如此吸引人的想法。但在实践中,对于大多数个人和小团队来说,它通常会变成大量的工作,回报却很有限。
1、为什么人们被微调吸引
有一些很好的原因使得微调感觉有吸引力。
1.1 它看起来像RAG的替代方案
如果你有大量内部文档,而你的RAG管道没有产生好的答案,很自然地会想:
为什么不完全跳过检索,直接将知识训练到模型中呢?
这听起来很合理。如果检索无法提取正确的片段,也许直接在源材料上微调模型会让它"更深入地了解"内容。
1.2 现代库使其看起来简单
使用Hugging Face生态系统——Transformers、Trainer、DataLoader、TRL的SFTTrainer、PEFT等——微调看起来很简单。
例如:
#colab https://colab.research.google.com/drive/1IE-2fGPUiYYKNenOMzWBnq2GIV1HrIam?usp=sharing#scrollTo=2d6QgbMrG4yD
from transformers import TextDataset,DataCollatorForLanguageModeling
from transformers import AutoTokenizer
def load_dataset(path,tokenizer):
dataset = TextDataset(
tokenizer=tokenizer,
file_path=path,
block_size=125)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=False,
)
return dataset,data_collator
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
train_dataset,data_collator = load_dataset(train_path,tokenizer)
training_args = TrainingArguments(
output_dir="./bloom-560-small3-v2", #The output directory
overwrite_output_dir=True, #overwrite the content of the output directory
num_train_epochs=500, # number of training epochs
per_device_train_batch_size=8, # batch size for training
per_device_eval_batch_size=4, # batch size for evaluation
eval_steps = 400, # Number of update steps between two evaluations.
save_steps=1000, # after # steps model is saved
warmup_steps=500,# number of warmup steps for learning rate scheduler
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
#eval_dataset=test_dataset,
)1.3 LoRA 和 QLoRA 降低了硬件门槛(GPU)
LoRA 和 QLoRA 等参数高效的微调方法使得使用一到两块 GPU 而非大型多 GPU 集群来训练模型成为可能。这是一个巨大的优势;您无需花费巨资即可进行实验。
示例:Gemma 4 E2B(约 23 亿个活跃参数)
对于 Gemma 4 E2B 的 23 亿个训练参数核心,在 BF16 混合精度下进行粗略的完整微调预算约为:
Weights (BF16): 2.3B × 2 bytes ≈ 4.6 GB
Gradients (BF16): ≈ 4.6 GB
AdamW Optimizer State (FP32): 2.3B × 8 bytes ≈ 18.4 GB
Total Base Memory: ~27.6 GB (before activation's)对于像 24 GB RTX 3090/4090 这样的中端 GPU(在 RunPod 中每小时 50 美分),这在技术上仍然超出了标准完整微调的预算范围。对于标准的全参数运行,您仍然需要一块 A100(40GB/80GB)(每小时费用为 x 美元)或一套多 GPU 配置。
但对于 LoRa 模型,情况则完全不同。如果您使用 r=32(排名解释见下文)作为目标投影,可训练参数将降至约 2200 万至 2500 万(约占 23 亿个有效参数的 1%)。
内存需求:优化器状态和梯度现在仅应用于这 1% 的参数,这意味着它们占用的空间可以忽略不计(低于 500 MB)。
硬件兼容性:该模型在 24 GB 的 3090 显卡上运行非常流畅,并且为长上下文激活或更大的批大小留出了充足的空间。
1.4 优化的 CUDA 内核使其更具吸引力
高度优化的内核和训练堆栈(例如 Unsloth 和类似的 CUDA 级优化)可以降低内存使用量并进一步加快训练速度。
据官方宣称,Gemma 4 E2B 最低只需 8GB 显存即可流畅运行。
这些都是很好的理由,现在让我们来看看它的缺点。
2、现实情况
2.1 它并不能解决 RAG 的问题
人们常常转向微调,是因为 RAG 的效果不佳。但 RAG 的根本问题不在于存储,而在于检索和组合,或者说是数据的质量。相关信息通常分散在多个数据块中。如果检索过程中遗漏了某些部分,答案就会受到影响。
微调并不能自动解决这个问题。
微调过程中究竟发生了什么?
情况 1:在原始文本上训练
如果您直接使用下一个标记预测在文档上进行训练:
- 使用 LoRA,您更新的参数不到 1%
- 模型无法有效地吸收大量新知识
如果您进行完全微调(假设您有足够的 GPU 来运行完整的训练),
- 您的数据集通常太小
- 模型过拟合
- 您面临着灾难性遗忘的风险
结果?一个充其量只能鹦鹉学舌般地复述数据的模型,无法提供任何解释
情况 2:指令调优
指令调优(QA 风格的数据)效果更好。但现在你需要:
- 一个强大的 LLM 来生成 QA 对
- 一个用于维护和更新它们的管道
即便如此,如果一个查询需要结合数据集多个部分的知识,模型仍然可能难以胜任。
因为其底层仍然是:下一个词元预测——而非真正的推理。你的模型并没有真正理解数据。
在我使用小型数据集进行的实验中,指令调优取得了最佳结果——Colab 链接
2.2 现代库仍然存在抽象泄漏(有时)
没错,工具已经改进,库也大多能按预期工作。但在实践中,让模型训练正常运行仍然并非易事。你经常会遇到兼容性问题。
- CUDA 版本/PyTorch/Transformers 兼容性
- 分词器问题
- bitsandbytes 的怪癖
- 模型特有的 bug,甚至是库本身的 bug
在尝试微调一个相对较新的模型时,这种情况尤为突出。
即使设置完成后,由于您自身的操作失误或使用了不合适的超参数,您仍然会遇到以下问题:
- 学习率不稳定
- 填充/掩码错误
- 批处理问题
- 由于使用了错误的填充标记或错误的聊天和指令训练模板而导致的损失计算错误
即使是简单的训练也需要付出大量努力才能正确完成。
2.3 LoRA:出色——但存在固有的局限性
LoRA(低秩自适应,LoRA:大型语言模型的低秩自适应)是一项重大突破。
它通过学习低秩更新而非修改完整的权重矩阵来实现高效的微调。
工作原理
LoRA 不使用完整的矩阵(例如,1000×1000 = 100 万个参数),而是使用以下方式近似更新:
- 1000 × r
- r × 1000
如果 r 很小 → 参数量大幅减少。这就是为什么 LoRA 可以在单个 GPU 上运行的原因。 (如果 r 为 1,则参数数量为 2000,通常 r = 16 或 32)
缺点是参数数量较少,网络无法学习太多模式。优点是模型中已有的知识不会被完全覆盖或过度拟合(灾难性遗忘)。
2.4 真正的瓶颈:数据
这是第二大难题。拥有大量文本数据是不够的。
要有效地进行微调,您需要:
- 高质量的指令数据
- 结构化的问答对
- 覆盖所有边界情况
- 持续更新
构建这些需要:
- 强大的基础模型
- 流水线
- 验证系统
这最终会成为一个完整的数据工程问题。
3、结束语
微调绝对值得一试——就学习而言。
它能教会你:
- 模型内部机制
- 优化权衡
- 内存限制
- 数据质量的重要性
- 训练动态
但对于真实系统中的知识吸收,尤其是在数据不断演变的情况下:微调通常不是合适的工具。它无法解决 RAG 的核心问题,反而会引入新的复杂性。它很脆弱,难以正确实现。而且,对于 PEFT 方法而言,其效率限制了其学习能力。RAG 和类似技术则要简单得多。
原文链接: Fine Tuning an LLM is Educational But not Very Useful Still for Knowledge Ingestion
汇智网翻译整理,转载请标明出处
