本地AI机器配置方案
让我告诉你一件事:本地AI不再是奢侈品,而是生存策略。 读完这篇文章,你就会确切知道该组装什么样的机器,而不会超出预算或让你抓狂。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
听着,我理解。在2024年,每个人都像抢购即将绝版的商品一样购买云端API token。"哦,直接调用API就行!"他们说。"太方便了!"他们说。好吧,如果你在2026年还在按token付费,恭喜你——你可能为不拥有自己的AI技术栈的特权多付了钱。
让我告诉你一件事:本地AI不再是奢侈品,而是生存策略。 读完这篇文章,你就会确切知道该组装什么样的机器,而不会超出预算(或让你抓狂)。
1、为什么选择本地AI?
1.1 在谈论token之前...先谈谈隐私
这里有一个没人问够的问题:你真的愿意把你的密码和信用卡交给某个第三方API吗?
想想看。每次你通过云端调用LLM时,你都在信任:
- 你的数据会交给陌生人(AI公司)
- 你的提示可能会被保存为"机密"
- 你的代理记忆存储在你无法控制的服务器上
关键点来了:你自己的代理记忆才是关键。 当你运行本地AI时,你的代理会随时间构建上下文——它记得你关心什么、之前问过什么、什么对你重要。使用云端API时,那段历史通常分散在不同的服务中,除非你明确告诉它们记住事情。
使用本地AI:
- 你的记忆只属于你自己(不是租来的)
- 不需要每个月"重置"代理的上下文
- 敏感数据不会泄露,因为...它根本没有泄露到任何地方!它就在那里,在你的机器里
现在来谈谈实际成本。因为是的,隐私重要——但钱也重要。
2024-25年没人告诉你的是:按token定价是个陷阱。 而且从那以后情况变得更糟了。
问题不仅在于模型说更多话了(确实如此——现代代理喜欢长篇大论),更在于你需要分别为输入和输出token付费。 这意味着:
- 你的提示需要花钱
- AI生成的每个字需要花更多钱* 现代代理越来越消耗token,比2024年多消耗30-50%的token(更大的上下文窗口、更长的推理链、更深层的记忆检索)
所以当一个代理说"我认为..."然后花三段话解释为什么时...你在为所有这些付费。而且不是一次——每次调用API都要付费。
没人谈论的隐性成本:
- 输入token膨胀: 你的代理学会了使用更长的提示和更深的上下文窗口——这意味着更多token、更多钱。突然间你每月8美元的API账单变成25美元,因为模型需要多1万个上下文token。
- 延迟敏感性: 云端延迟约50毫秒;本地可以在你需要的时候做到<10毫秒
- 隐私问题: "哦,这是机密的"——但你现在把敏感数据存储在本地,不再每次都发送到云端
- 速率限制惊喜: 当你的API调用队列在周五下午2点开始堆积时
这里发生了变化: 在2026年之前,开源模型仍然很弱——它们能处理基本任务但在复杂推理上挣扎。你需要云端API来处理任何严肃的任务。
2026年之后?完全是另一回事了。 开源模型现在好多了,真正可以用于日常工作。"免费"本地模型和付费云端API之间的差距已经显著缩小,使得盈亏平衡点比任何人预期的都低得多。
如果你每月处理超过500万个token,数学计算就已经倾向于拥有自己的技术栈了——但关键来了:使用2026年新一代模型,即使是轻度用户也发现本地AI具有竞争力,因为...让我展示一下现在真正好用的东西。
1.2 新的竞争者
Qwen3.5-27B——通用型强者(2026年2月发布)
这不仅仅是渐进式更新——而是代际飞跃。以下是Qwen3.5特别之处:
- 原生多模态能力: 文本和视觉处理在早期训练中就在同一潜空间中发生,实现了改进的空间推理能力
- 处理大型工作负载的能力比前代(Qwen2.5)强8倍
- 云部署成本降低60%——本地运行时意味着大幅节省
- 可扩展矢量图形生成: 可以直接从文本描述创建SVG(开源模型首创!)
- 视觉代理能力: 不只是"看到"图像——还能对图像采取行动
为什么你关心: 如果你在构建需要同时处理文本和图像的本地AI,而不希望花费太多,Qwen3.5现在是GPT-4.1的有力竞争者。而且在70B参数(或更小变体)下,它可以在消费级GPU上舒适地运行。
Qwen3-Coder-Next——编程专家
这对开发者和工程师特别有趣。原因如下:
- 80B参数模型,推理时仅激活3B: 这意味着你获得了巨型模型的智能,却拥有小模型的速度
- 在编程基准测试中的性能可与Claude Sonnet 4.5媲美——但可以在本地运行,不需要128GB显存
- 本地部署可行,显存<60GB: 第一个"可用的"适合消费级硬件的编程模型
- 擅长长期推理、复杂工具使用和错误恢复: 它不只是写代码——它构建系统
为什么你关心: 如果你是开发者,寻找本地AI编程助手,这是第一次开源模型能真正在编程任务上与付费云端API竞争。而且因为它推理时只激活3B参数,它快到在你编程时感觉"实时"。
底线: 这些不只是渐进式改进。Qwen3.5和Qwen3-Coder-Next代表了本地AI能力的根本性转变。2026年之前,你需要云端API来做严肃的工作。现在呢?只有当你的GPU显存不够用时才需要它们。
2、NVIDIA GPU选项
2.1 RTX 5090——新王者,但代价是什么?(而且越来越贵)
实际价格(2026年3月):
- 亚马逊: ~$4,232
- 新蛋: ~$3,620–$4,000
- 发布时MSRP: $1,999(现在几乎找不到)
- 显存: 32GB GDDR7
现实是:RTX 5090在2025年底以合理的$1,999发布。但由于内存短缺和AI需求,你现在要付近两倍的价格。 在亚马逊上,价格徘徊在$4,232左右,而新蛋上如果运气好,有些价格接近$3,620。
这是在2025年底发布时让所有人都说"哇"的显卡。对于AI工作负载,它比RTX 4090快60-80%,并且可以轻松处理70B以上的模型。32GB显存意味着你在处理大型上下文窗口时不会遇到瓶颈。
谁应该购买: 如果你认真对待本地AI,预算不紧张,或者想要未来2-3年的前瞻性,那么就是你。如果你能负担得起$2,600,并且预计每天运行重型模型,这就是你的显卡。
缺点: 它功耗575W,所以你的电费账单会在大约六个月内...表示感谢。
2.2 RTX Pro 6000(Blackwell)——企业级巨兽
实际价格(2026年3月):
- 新蛋: ~$8,400–$12,000
- 亚马逊: ~$9,500–$11,000
- 发布时MSRP: $7,999(Blackwell工作站版)
- 显存: 96GB GDDR7 ECC
这是NVIDIA最新的企业级GPU——基于Blackwell架构(比Ada更新)。RTX Pro 6000不只是另一张显卡;它是GPU形式的桌面超级计算机。 凭借惊人的96GB显存,这个东西可以处理:
- 巨型上下文窗口而不会费力(100万+token是可行的)
- 在本地微调AI模型* 同时运行多个大型模型
为什么你关心: 如果RTX 5090的32GB感觉不够用,并且你愿意花$8,400–$12,000买个安心,这张显卡就是在说"我不再在显存上妥协"。如果你在构建专用AI工作站,容量比原始推理速度更重要,它就特别有价值。
2.3 RTX 4090——性价比之王(但越来越贵!)
实际价格(2026年3月):
- 亚马逊新品: ~$2,755
- 新蛋新品: ~$2,100–$3,765
- eBay二手: ~$2,200
- 发布时MSRP: $1,599(现在几乎绝迹)
现实是:RTX 4090在2022年底以合理的$1,599发布。但现在呢?你在亚马逊上要付接近 $2,755——比MSRP多了 $1,156。
好消息:二手卡在eBay上~$2,200仍然是不错的价格。如果你能找到$2,300以下的维护良好的4090,它仍然是本地AI工作负载中性能和成本之间的最佳平衡点。
显存: 24GB GDDR6X
没人愿意承认的事实:4090能很好地处理95%的用例。 对于本地LLM推理,它仍然非常快,可以舒适地运行大多数70B模型。在~$2,200–$2,800新品或$2,300以下二手的价格下,它仍然是性能和成本之间的最佳平衡点——如果你愿意支付溢价的话。
谁应该购买: 想要强大AI性能但不想花太多钱的人。如果你在构建专用AI机器,想要平衡价格和未来性能,这仍然是2026年最值得考虑的选择。
2.4 RTX 3090——预算传奇(是的,仍然!)
实际街价(2026年3月):
- 亚马逊新品: ~$1,488
- 亚马逊/新蛋二手: ~$650–$950
- eBay二手: ~$630–$800
- 显存: 24GB GDDR6X
如果你认为买二手3090是"小气",我要挑战这个观点。这张显卡在2026年仍然是本地AI的性价比之王。 你以不到一半的价格获得与4090相同的24GB显存。是的,它更慢(原始token/秒大约落后15-20%),但当你节省$1,000以上时,没人在乎。
谁应该购买: 注重预算的装机者、第二代本地AI用户,或者任何说"我只需要显存"而不想超支的人。它特别受多GPU装机者的欢迎,你可以用两张3090的价格买到一张5090的性能。
没人愿意承认的现实:RTX 3090在token生成速度上仍然比新的M5 Max快。 让我告诉你为什么。

为什么RTX 3090仍然是预算装机者的首选:
1. 内存带宽优势: RTX 3090的936 GB/s带宽碾压M4 Max(546 GB/s)和M5 Max(614 GB/s)。对于LLM推理,内存带宽就是王道——它直接决定了你能多快生成token。
2. 性价比: 以~$700–$850二手的价格:
- RTX 3090: ~0.9 tok/$(每美元token数)
- M4 Max(二手): ~0.6 tok/$
- M5 Max(新品): ~0.4 tok/$
3. "足够好"的阈值: 对于交互式聊天,你需要大约10+ token/秒才能感觉响应迅速。RTX 3090提供该阈值的8-12倍,而成本不到二手M4 Max的一半。
如果你在构建第一台本地AI机器,不想在GPU上花超过$1,000,RTX 3090仍然无可匹敌。 是的,Apple Silicon有更好的效率(更低的功耗)——但如果原始token生成速度比省电更重要,NVIDIA在这个价位上轻松胜出。
关键点:你可以花~$750买一张二手RTX 3090,获得比M4 Max更快的推理速度,而M4 Max新品要$1,800–$2,200。这不只是价值——简直是捡到宝了。
2.5 NVIDIA DGX Spark——桌面超级计算机(为想要简单的人)
价格: ~$4,699(2026年3月,从发布时的$3,999上涨) | 内存: 128GB统一内存
DGX Spark是NVIDIA对"我不想要完整PC组装"的回答。它是一款一体化桌面AI超级计算机,具有:
- GB10超级芯片(Grace Blackwell架构)
- 128GB统一LPDDR5x内存,CPU和GPU共享
- 包含4TB NVMe存储
- 1 petaFLOP稀疏FP4性能
它本质上是预装、即插即用的AI工作站。没有线材管理噩梦,没有奇怪的驱动问题(基于ARM),开机即用。
谁应该购买: 想要简单而非定制化的人、需要统一内存架构的数据科学家,或者不想组装传统PC但仍想要强大本地AI性能的人。以$4,699的价格,你在为便利性支付溢价——如果你觉得自己的时间比每月$500更值钱,这完全可以接受。
3、Apple Silicon("我想要低功耗+强大性能"级别)
3.1 M5 Max——新热点(刚刚发布!)
发布日期: 2026年3月 | 价: ~$3,600(14英寸)到$6,100+(16英寸,高配版)
Apple刚刚发布了M5 Max,引起了不小的轰动。拥有18核CPU(6个性能核心+12个能效核心)、32核GPU和高达128GB统一内存,这对本地AI工作负载来说是认真的。
为什么你可能想要它:
- 无与伦比的能效(MacBook Pro M5 Max功耗约90W,而RTX 5090功耗575W)
- 统一内存架构意味着模型可以使用所有这些RAM而不会遇到瓶颈
- 静音运行——你的笔记本电脑不会听起来像火箭发射
权衡: 你在为效率付费,而不是原始吞吐量。如果你需要极快的token生成速度,NVIDIA在纯速度上仍然胜出。但如果你想要低功耗且不介意稍慢的推理,M5 Max就是答案。
3.2 M1 Max——预算传奇(在2026年仍然有价值!)
价格: ~$800–$2,000二手 | 内存: 高达64GB统一内存
这里有一些可能让你惊讶的事情:M1 Max在2026年仍然值得购买。 是的,真的。发布四年后,人们仍然疯狂购买这些设备,因为它们提供了令人难以置信的性价比。
为什么它适合预算装机:
- 你获得高达64GB统一内存(对大多数本地AI工作负载来说足够了)
- 以~$800二手的价格,你以折扣价获得高端芯片
- 仍然能流畅运行LLM,具有不错的token吞吐量(在较大模型上约50-70 token/秒)
谁应该购买: 预算紧张但仍然想要Apple的效率和统一内存架构的人。如果你不需要最新的芯片,但想要可靠的本地AI性能而不会破产,这是你的选择。
如果你决定购买M1 Max版本,我认为16英寸、64GB RAM、32核GPU是最佳选择。
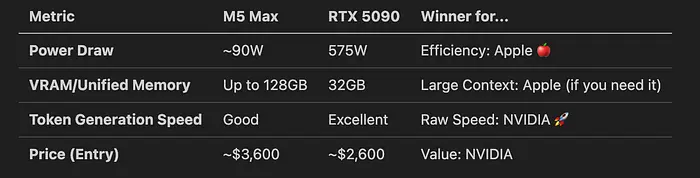
Apple与NVIDIA快速对比(2026年3月):
4、其他选项(因为生活不是非黑即白)
由于我对其他选项不太熟悉,这部分我先保留。
...
5、二手零件策略("我懂得省钱"的方法)
5.1 3090金矿
正如我之前提到的,RTX 3090在2026年仍然是本地AI的性价比之王。以~$600–$850二手的价格,你获得:
- 与RTX 4090相同的24GB显存
- 运行70B量化模型的可靠性能
- 成熟的生态系统和广泛的支持
- 你可以在一台机器中使用4张RTX 3090
专业提示: 在eBay上寻找来自信誉良好卖家、挖矿时间少于100小时的显卡。避免那些在游戏设备中重度使用的显卡,除非它们便宜得多。
5.2 M1 Max的最佳点
如果你选择Apple路线,二手M1 Max MacBook Pro或Mac Studio在~$800–$1,800(取决于配置)的价格下仍然是令人难以置信的价值。你获得高达64GB统一内存,而不用支付M5的溢价。
5.3 多GPU装机(为有雄心的人)
如果你想要强大的性能而不破产:
两张二手RTX 3090(总共~$1,400–$1,700)在某些工作负载上可以胜过单张RTX 5090
你本质上获得了更多的显存空间和并行推理能力
6、最终建议(TL;DR版本)
预算装机(~$800–$1,800):
- GPU: 二手RTX 3090或二手M1 Max Mac Studio/Macbook Pro(64GB RAM)* 最适合: 第一次尝试本地AI的用户、爱好者、注重预算的专业人士
中端装机(~$1,800–$2,500):
- GPU: 新RTX 4090或新AMD 7900 XTX + CPU升级
- 最适合: 想要性能但不想超支的认真用户
高端装机(~$3,600+):
- GPU: RTX 5090或M5 Max(如果你重视效率)
- 最适合: 高级用户、每天运行重型模型的专业人士、追求未来性能的爱好者
简约装机(~$4,700):
- 一体化: NVIDIA DGX Spark
- 最适合: 想要即插即用而不组装PC的人
7、底线
在2026年,本地AI比以往任何时候都更容易获得。无论你是购买二手RTX 3090来装预算机,还是挥霍购买M5 Max MacBook Pro,拥有自己的AI基础设施从来没有比现在更好的时机。
关键问题不是"我应该选择本地吗?"——而是"我能负担什么而不会在六个月后后悔?"
所以选择你的道路:
- 如果你想要原始速度和成熟的工具,选择NVIDIA
- 如果你重视效率和简单性,选择Apple
- 如果你懂得省钱(你应该如此),选择二手市场
记住:没人在乎你有什么GPU,直到他们看到在周五下午3点你的云端API突然被限速时,你的本地AI响应有多快。😄
原文链接: Why and How to Build your own Local AI Machine in 2026
汇智网翻译整理,转载请标明出处
