Mamba 解密
注意力并非你所需要的一切。事实证明,有时候你需要一条蛇。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
2017年,Google 的一个研究团队发布了一篇题为"Attention Is All You Need"的论文,引入了 Transformer 架构。它改变了深度学习领域的一切。在接下来的七年里,这篇论文的标题(以及 Transformer 架构本身)被视为"福音"。
然后一条蛇出现了。
2026年3月,一个名为 Mamba-3 的新模型在 Apache 2.0 许可下发布。它将 Transformer(最常用的模型)之前的语言建模基线提高了近4%,并且在处理超长文本序列时表现优于 Transformer(快达7倍)。Mamba 论文被 ICLR 2026(世界上最具竞争力的机器学习会议之一)接收。
而且几乎没有人震惊。
没有"Transformer 杀手"的头条。没有引发推特论战。深度学习社区没有存在危机。如果说有什么的话,这种缺乏反应可能恰恰是这个故事中最能说明问题的部分。它表明 Mamba 不仅取代了 Transformer,而且已经进入了真正重要的系统。
最新的 NVIDIA Nemotron-H 模型呢?92%的注意力层已被移除并替换为 Mamba 块。IBM 的 Granite 4.0 是混合 Mamba/Transformer 架构。微软的 Phi-4-mini-flash 基于 SambaY 设计,将 Mamba 与滑动窗口注意力混合。最后,Mistral 的 Codestral Mamba 是完全基于 SSM 的架构,专为编码设计(即完全没有注意力)。
这不是炒作。这是已发布的代码。
让我们来拆解这个东西。
1、房间里的大象有 O(n²) 条腿
以下是 AI 领域每个人都知道但没人愿意谈论的 Transformer 脏秘密:注意力非常昂贵。极其昂贵。二次方级别的昂贵。
当 Transformer 分析给定序列时,对于序列中的每个 token,它需要与该序列中的每个其他 token 进行比较。这被称为"自注意力",定义注意力机制的形式化方式如下:
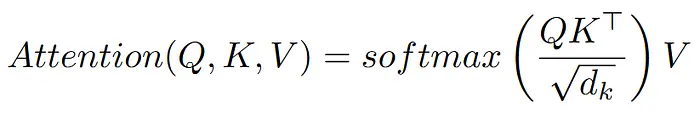
其中 Q、K 和 V 是从输入派生的查询、键和值矩阵,dₖ 是键的维度。对于序列中的 n 个 token,QKᵀ 乘积将产生一个维度为 n × n 的注意力矩阵。这意味着每个 token 能够与每个其他 token 通信。结果是所需的时间和内存为 O(n²)。
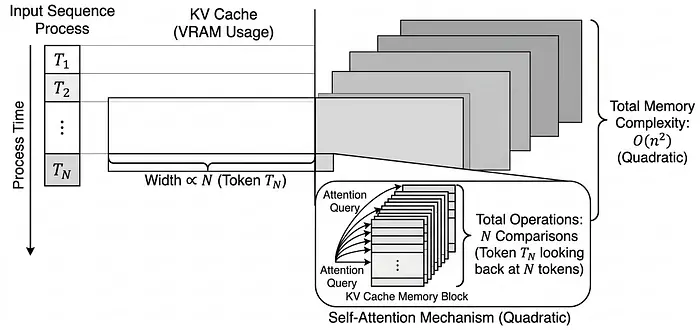
如果你有4,096个 token 作为输入;大约需要进行1,670万次比较,听起来可行,对吧?那么现在考虑当你有10万个 token 时;将有100亿次比较,如果你有100万个 token,别费心计算了;你的 GPU 在你到达解决方案之前就已经离场了。
回到2017年,这不是问题,因为上下文窗口非常小。没有多少人要求他们的模型处理完整的代码库或300页长的法律合同,而且与训练成本相比,推理成本微不足道。
但2026年是另一回事。
AI 智能体——Claude Code、Codex、OpenClaw——正在生成长达数小时的长运行 token 流。强化学习管道需要大量的推演序列和数据。基因组学研究人员希望在包含数十万个碱基的全长序列上进行训练和测试。另一方面,视频模型也希望在完整长度的电影(而不仅仅是30秒)上进行训练。
Transformer 的二次注意力,曾经是一个美妙的创新,已经成为 AI 行业云账单上最昂贵的一行。
这引出了一个自然的问题:如果能够在线性时间内完成同样的任务,会发生什么?
蛇登场了。
2、状态空间模型,就像你在咖啡馆聊天一样解释
Mamba 属于一个叫做状态空间模型(SSM)的家族。这些模型有趣的地方在于它们不是自然语言处理(NLP)社区的发明——它们源自控制理论领域,这是工程师用来建模物理系统随时间行为的数学领域。例如恒温器如何工作、自动驾驶仪如何保持飞机直线飞行、以及火箭如何穿越太空到达目的地。
SSM 背后的基本概念非常简单。假设你正在尝试阅读一本非常长的小说——例如《战争与和平》。你可以使用两种方法之一来为你读过的每一章写读书报告。
- Transformer 方式:在为任何新章节写读书报告之前,你必须回去阅读书中之前的每一章。所以当你到达第800页时,你已经把之前的每一章都读了多遍。但是要注意,你在第101-200页之间花的时间比之前更多!
- SSM 方式:在阅读时,你形成一个关于到目前为止书中发生了什么的持续性心理记录(一个"压缩状态"),在你阅读每一页新内容时不断更新。你不会因为任何原因回到原文。你的总结只包括文本中的要点,所有填充内容在你继续阅读时消失在背景中。这样,你将更容易阅读,且不会增加你的记忆负担。
这就是根本区别。Transformer 维护它所见一切的完整记录(KV 缓存),并为每个新 token 查询所有内容。SSM 维护一个固定大小的隐藏状态并增量更新它。
3、心理总结背后的数学
SSM 的连续时间形式由两个方程定义:
状态方程("心理总结"如何更新):
h′(t) = A · h(t) + B · x(t)
输出方程(总结如何产生响应):
y(t) = C · h(t) + D · x(t)
其中:
x(t) ∈ ℝ是时间 t 的输入信号h(t) ∈ ℝᴺ是隐藏状态("心理总结"),具有 N 个状态维度y(t) ∈ ℝ是输出A ∈ ℝᴺˣᴺ是状态转移矩阵("我要忘记什么?"旋钮)B ∈ ℝᴺˣ¹是输入投影矩阵("我要记住什么?"旋钮)C ∈ ℝ¹ˣᴺ将隐藏状态映射到输出D ∈ ℝ是直接馈通(通常省略)
但是等等,文本是离散的,不是连续的。你一次读一个 token,不是平滑信号。所以我们需要对这个系统进行离散化。使用步长 Δ,零阶保持(ZOH)离散化得到:
Ā = exp(ΔA)B̄ = (ΔA)⁻¹(exp(ΔA) − I) · ΔB
这将连续系统转化为我们实际可以计算的递推:
hₜ = Āₜ · hₜ₋₁ + B̄ₜ · xₜyₜ = Cₜ · hₜ
这是每个 SSM 的心跳。在每个时间步,隐藏状态 hₜ 通过(a)通过 Ā 衰减旧状态和(b)通过 B̄ 整合新输入来更新。然后输出 yₜ 通过 C 读出。
成本是多少?对于 n 个 token 的序列为 O(n)。线性的。不是二次的。而且状态 hₜ 无论序列多长都保持相同大小——意味着推理时内存恒定,没有不断增长的 KV 缓存。
听起来完美,对吧?别急。
4、原始 SSM 的问题:把每个词当作同等重要
在早期 SSM 中(具体来说,被称为 S4 的模型),存在一个严重的问题使其无法使用:在学习之后,矩阵(A、B 和 C)对于每个 token 都是恒定的。它们总是以相同的方式变换。token 之间没有区别,上下文方面没有差异。
考虑会议中的以下例子:"所以,嗯,基本上我想说的是我们的收入数字实际上非常好。"就像一个基本 SSM 会把"嗯"、"基本上"、"你知道"和"像"的权重视为与"收入非常好"相同,它没有办法确定要注意什么——即把注意力集中在重要的事情上而忽略不太重要的事情。
这正是注意力真正发光的地方。Transformer 非常擅长说"我不想注意'嗯'"和"我想关注'收入'"。这就是注意力如此有效的原因:注意力模块能够选择性地确定有效沟通所需的相关上下文。
而正是 Mamba 被设计来弥合的这一差距。
5、Mamba 的大创意:如果我们让蛇变得挑剔呢?
原始的 Mamba 论文于2023年12月发布,由 Albert Gu(卡内基梅隆大学)和 Tri Dao(普林斯顿大学)撰写。核心洞察简洁而优雅:
让 SSM 参数依赖于输入。
Mamba 不使用固定的 A、B 和 C 矩阵,而是使它们成为当前 token xₜ 的函数。具体来说,选择机制参数化了:
Bₜ = LinearB(xₜ)Cₜ = LinearC(xₜ)Δₜ = softplus(LinearΔ(xₜ))
步长 Δₜ 特别巧妙。它控制当前输入有多少被整合到状态中。大的 Δₜ 意味着"注意这个 token",而小的 Δₜ 意味着"基本忽略它"。离散化参数然后变为:
Āₜ = exp(Δₜ · A)B̄ₜ = (Δₜ · A)⁻¹(exp(Δₜ · A) − I) · Δₜ · Bₜ
递推变得依赖于输入:
hₜ = Āₜ · hₜ₋₁ + B̄ₜ · xₜyₜ = Cₜ · hₜ
你会看到现在每个变量都带有一个 t;这些变量随着每个时间步的进展而变化,取决于在该时间步正在查看的内容。每个 token 动态修改被记住的 token 数量、被遗忘的现有状态数量以及该 token 对产生输出的影响强度。
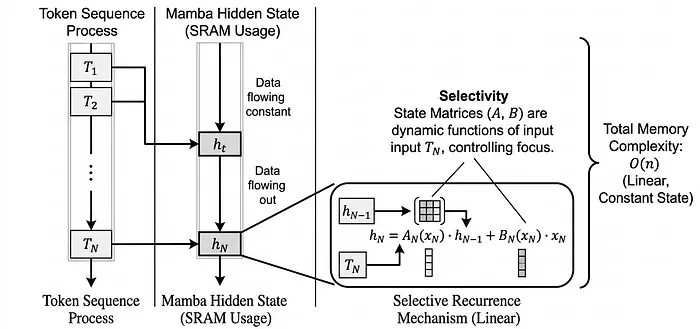
作者们将此称为"选择性 SSM"或 S6(S4 模型 + 选择机制 + 扫描计算)。关于他们的架构,作者们将其命名为"MAMBA",因为多个 S 产生了蛇一般的"嘶嘶"声。
这两种技术的激动人心之处在于,它们在推理内容方面具有相同的基本功能。它们都允许模型根据输入的实际内容来确定什么重要;然而,一个通过使用注意力方法 O(n²) 将所有 token 与所有其他 token 进行比较来实现这一点,而 Mamba 通过利用压缩状态并动态更新它 O(n) 来实现这一点。
简单来说,你必须把注意力看作是一个群聊。群聊中的每个人都在与群聊中的其他人交谈。同样,Mamba 可以被认为是一个非常出色的执行助理。助理阅读并记住所有重要的电子邮件消息,并可以为您提供所有通信的简明摘要。同样质量的信息。一小部分的精力。
但还有一项工程魔法使这在实践中可行。使参数依赖于输入后,你阻止了使用卷积来高效训练旧 SSM 模型。当卷积核每次更新时都发生变化时,不可能预计算一个大的全局卷积核。Mamba 通过硬件感知的并行扫描算法解决了这个问题,这本质上是一个自定义 CUDA 核,将选择性扫描计算与 GPU SRAM 融合——其目标是尽可能少地从 GPU 上最慢、最高带宽的内存(即 HBM)中读取。这是系统级思维,类似于 FlashAttention 在基于 Transformer 的架构中的成功实现。
结果如何?结果令人瞩目。一个28亿参数的 Mamba 模型在语言基准上匹配了两倍大小的 Transformer,同时提供了5倍的推理吞吐量。
蛇有了牙齿。
6、演进:Mamba-1、Mamba-2 和 Mamba-3 时刻
就像任何好的续集一样,Mamba 的每个版本都修复了前一个版本的问题。
6.1 Mamba-1(2023年12月)——"嘿,这真的管用"
Mamba-1 展示了 SSM 可以在语言处理、音频处理和基因组学方面与 Transformer 竞争的概念验证。Mamba-1 的亮点是创新的选择性扫描。虽然选择性扫描创新旨在改善推理性能,但 Mamba-1 的训练能力还有很大的成长空间。
6.2 Mamba-2(2024年5月)——"让我们让训练更快"
这就是这个项目的理论精华发挥到极致的地方!在开发 Mamba-2 的过程中,Gu 和 Dao 发现 SSM 和注意力之间的关系在数学上有惊人的深度。当在选择 SSM 层的架构中使用正确类型的约束时:
Y = M · (X ⊙ Bᵀ) · C
其中 M 是由标量转移 aₜ 的累积乘积定义的掩码矩阵:
Mᵢⱼ = aⱼ₊₁ · aⱼ₊₂ · … · aᵢ (如果 i ≥ j),否则为 0
有趣的是,这两种形式的因果掩码注意力在概念上非常相似。作者展示了他们称之为结构化状态空间对偶(SSD)的 SSM 结构在数学上等同于线性注意力的一种结构化形式。
这一发现的好处远不止学术好奇心,因为它通过重新组织计算以使用矩阵乘法(matmul)——这是当前高性能 GPU 最擅长的计算风格——使处理速度比以前的模型快了约2-8倍。
获得更快处理的代价是 Mamba-2 将其状态转移简化为标量 aₜ ∈ ℝ,这导致训练相对更快,但如前所述,牺牲了一部分表达能力。其他研究人员后来表明,将特征值限制为实数和非负值可能在某些状态跟踪任务上导致性能下降。
6.3 Mamba-3(2026年3月)——"推理为王"
一个 AI 项目能否成功取决于它在推理方面的表现,而非训练。
Mamba-2 的最大因素是你的机器在训练方面有多高效。而 Mamba-3,让 AI 成功的最大因素将是 AI 从训练中推断数据的效率。随着智能体跟踪多个工作流步骤并产生数千行代码,Mamba-3 的决定似乎是正确的。
三个重要改进:
1. 更具表现力的递推(指数-梯形离散化)。
Mamba-1 和 Mamba-2 使用"指数-欧拉"离散化,本质上是前向欧拉步与矩阵指数的结合。Mamba-3 引入了指数-梯形变体:
hₜ = Āₜ · hₜ₋₁ + ½(B̄ₜ · xₜ + Āₜ · B̄ₜ₋₁ · xₜ₋₁)
使用梯形法则对当前和先前值的输入进行平均,更丰富地定义了模型的动态,从模糊的心理表示升级为高清画面。重要的是,这种递推的类卷积效应使 Mamba-3 能够消除 Mamba-1 和 Mamba-2 在到达 SSM 之前所需的短因果卷积层。
2. 复值状态跟踪。
此前,Mamba 的转移仅由实数非负值组成(aₜ ∈ ℝ≥₀),这限制了它们在跟踪时间状态序列时表示值特征(即减少/外部化相位或振荡运动)的能力。
Mamba-3 在其转移规则中重新引入了复值状态:
aₜ = rₜ · eⁱᶿₜ ∈ ℂ, 其中 rₜ ∈ (0,1), θₜ ∈ [−π, π]
状态空间中随时间的旋转是通过将幅度乘以复指数的 eiθ 来实现的。这可以通过用 RoPE(旋转位置编码)编码来表示复指数来实现;从而利用了成熟的实现,而不是专门开发新的 CUDA 核。
3. MIMO(多输入,多输出)。
以前的 Mamba 版本使用 SISO(单输入,单输出)结构,其中每个 D 特征维度都有自己的 SSM,输入或输出之间没有交互——想象一次只读一个字符的书。
Mamba-3 的 MIMO 变体扩展了 B 和 C 矩阵以实现跨特征交互:
Bₜ ∈ ℝᴺˣᴾ, Cₜ ∈ ℝᴾˣᴺ
其中 P > 1 允许状态更新在多个输入/输出通道之间混合信息。这在不减慢解码速度的情况下提高了准确性,因为控制推理速度的状态大小 N 保持不变。
成绩单:在15亿参数下,Mamba-3 相比其最接近的竞争对手(Gated DeltaNet)平均下游准确率提高了1.8个百分点。它在状态大小减半的情况下达到了 Mamba-2 级别的困惑度。团队还开源了所有核心。
7、剧情反转:未来不是对抗
大多数文章会在这里宣布赢家。Mamba 好,Transformer 坏。或者反过来。
现实比这有趣得多。
整个 AI 行业正在收敛到混合架构——同时使用 SSM 和注意力层的模型——因为每种机制在对方不擅长的方面都非常出色。
SSM 的困难所在: 假设你读了一份10万字的合同,第247页有一个标题为"赔偿"的段落,你正试图找到该赔偿的文本。一个纯粹的 SSM,以其压缩状态 hₜ ∈ ℝᴺ,可能已经让那个细节消散了。它完美地捕捉了合同的要点,但具体条款呢?没了。但是,如果你使用全注意力(在合同整个语料库的每个 token 之间进行 O(n²) 比较),你将能够准确识别段落所在的位置。
注意力的困难所在: 现在想象你正在实时阅读那份合同,一页一页地读好几个小时。Transformer 的 KV 缓存线性增长:n 个 token 需要 O(n · dₖ) 内存。随着 token 数量增加,速度下降,最终会在 GPU 上耗尽内存。而 SSM 状态无论处理1,000个还是1,000,000个 token 都保持 O(N)。
混合答案一旦你看到就几乎很明显了:让 SSM 层处理长范围序列处理和高效生成的繁重工作。在需要精确手术的地方——检索、精确回忆、特定查找——撒上几个注意力层。
这已经在生产中发生:
- NVIDIA Nemotron-H 使用92% Mamba 层,8% 注意力。在同等准确率下比 Meta 的 LLaMA-3.1 快3倍。
- AI21 Jamba 每7个 Mamba 层使用1个注意力层,外加系统中的混合专家。
- IBM 的 Granite 4.0 使用混合 Mamba-Transformer 架构用于企业,大规模降低了服务成本。
- 微软的 Phi-4-mini-flash 使用 SambaY 架构——Mamba + 滑动窗口注意力 + 门控记忆单元。
Mamba-3 团队自己说得清楚:混合模型将主导生产。
注意力并非你所需要的一切。但它也不是什么都不是。
8、好吧,但这对我意味着什么?
无论你是开发者、研究人员,还是只是想了解 AI 发展方向的人,以下是实际的要点。
你的推理支出应该很快会减少。 混合模型架构使流行的长上下文类 AI 有了经济实惠的解决方案。以前用纯 Transformer 模型在经济上不可行的任务——如多小时的智能体会话、完整代码库分析或长文档推理——将在规模上变得可行。
模型正在自行组合; 不再需要选择混合还是传统架构。Jamba、Bamba、Nemotron-H 和 Granite 4 都可以通过传统开发框架选项获得。你可以通过 Hugging Face 开始实验。
长上下文引用不再是荣誉徽章; 它们变成了品质。基于 SSM 的架构已经在单个消费级 GPU(24GB VRAM)上处理了22万+个 token。限制因素已从"模型能处理什么"转变为"应用实际需要什么"。
关注智能体 AI 领域。 Mamba 的恒定内存推理是持续运行的 AI 智能体的天然适配。基于 Transformer 的智能体随时间累积不断增长的 KV 缓存。基于 Mamba 的智能体呢?第一小时和第一百小时的内存占用相同。这不是一个小细节——它可能是使真正持久的 AI 智能体成为可能的架构特性。
9、还有什么未解决
为什么你不应该卖掉你的 Transformer 股票?
让我们不要假装 Mamba 已经回答了一切。几个重大问题仍然悬而未决。
检索差距是真实的。 目前还没有一个纯 SSM 在所有对抗性检索基准上产生了 Transformer 级别的精确检索——这些基准旨在确定模型在由100万个 token 组成的干草堆中定位埋藏项目的准确度。相反,混合模型由于在其架构中使用了注意力层作为中介,已经在检索中实现了更高的精度,但在基于 SSM 的模型中实现这一点的原生解决方案仍是一个已知的研究问题。
生态系统仍在追赶。 专门为 Transformer 设计的工具——FlashAttention、vLLM 和 TensorRT-LLM——经过多年的优化才达到现在的状态。尽管 SSM 的部署基础设施正在快速成熟(如 Mamba-3 最近发布的开源核心),今天在纯 SSM 准备好商业使用之前仍有相当大的滞后时间。
扩展定律尚未完成。 我们知道 Transformer 可预测地扩展。对于 SSM 和混合模型,这些扩展曲线仍在绘制中。早期迹象令人鼓舞,但我们还没有达到 Transformer 级别的确定性,即如何最优地投入计算。
10、更大的图景:注意力并非你所需要的一切
退远一步看,Mamba 的故事实际上是一个关于成熟的故事。
2017年,深度学习世界发现了"注意力"的用途,并立即开始过度使用它。多年来,我们不断增加"Transformer"神经网络的大小和能力以及我们应用于它们的处理能力,都是为了实现性能改进。
然而,就像在任何其他成熟的创新领域一样,你不能用一种类型的设备建造每一种结构。例如,土木工程师不会只用混凝土建造每种结构,医生不会用手术治疗每个病人,因此也不能说每个人工智能系统都需要"注意力"来进行每次计算。
Mamba 提供的是另一种选择,或者更简单地说——一个与注意力配合使用的互补工具。Mamba 是一种新颖的计算原语,基于控制理论而非自然语言处理——Mamba 被设计为完成注意力做不好的功能(长序列、扩展生成和内存高效使用),同时适当地回到"注意力"来做好它今天擅长的事情——从内存存储中高效检索和处理特定 token。
蛇没有吃掉 Transformer。
它只是教会我们"Attention Is All You Need"一直以来更多的是一个论文标题而非一个普遍真理。
而将定义 AI 下一个时代的模型?它们可能同时有鳞片和注意力头,在同一个身体中协同工作。
注意力并非你所需要的一切。但知道何时需要它何时不需——可能就是一切。
原文链接: Mamba Unboxed: The State Space Model That's Quietly Replacing Attention
汇智网翻译整理,转载请标明出处
