Minsearch:我的轻量RAG检索库
一个小型进程内 Python 库如何替代了我教学用的 RAG 笔记本中的 Elasticsearch。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
两年前,我正在筹备 LLM Zoomcamp 的首次开课,这是我关于构建 LLM 应用的免费课程。第一期主要聚焦于 RAG。我当时也在就同一主题举办工作坊。
搜索(即检索)是 RAG 中最重要的组成部分之一。我需要一种方式来教授它,但又不想要求参与者安装 Docker 或 Elasticsearch。
于是我构建了 minsearch:一个小型的进程内 Python 搜索库。它最初只是我在笔记本中教授检索所需的最小工具,后来随着课程示例的演进而不断发展。
在本文中,我将分享:
- 为什么 Elasticsearch 在这种场景下过于笨重
- 第一个版本是如何工作的
- 它如何成为一个 PyPI 包
- 为什么我添加了可追加索引和向量搜索
- 我如何利用 Claude 来加速它
- 什么时候 minsearch 是正确的工具

1、为什么 Elasticsearch 过于笨重
在 LLM Zoomcamp 的首次开课中,我需要向参与者展示如何索引一个小型数据集、提交查询并检索相关文档。通常是几千篇文档,有时更少。大多数示例在笔记本中运行,有时在 Google Colab 上,使用 GPU 上的开源 LLM。而在笔记本中工作是我创建 minsearch 作为更复杂搜索引擎轻量级替代方案的主要动机。
对于正常的生产系统,我可能会选择 Elasticsearch。它功能强大,而且我很熟悉。但对于工作坊笔记本来说,它太重了。它需要服务器、Docker、配置以及各种运维细节,而这些都不是课程的重点。
在课程或工作坊的环境中,所有东西都应该在一个笔记本内运行。我寻找过一个可以在与笔记本相同的 Python 进程中进行足够好的词法搜索的小型 Python 库,但没有找到合适的。
当时,我已经从事文本处理和搜索工作很长时间了,所以自己构建一个小型进程内搜索库并不困难。即使在那时——当编码代理还远不如现在强大时——我也可以向聊天助手描述我想要什么,获取代码,然后要求做一些修正。
LLM Zoomcamp 首次开课的检索模块,围绕 minsearch 构建。
2、第一个版本
第一个实现 是一个单独的 Python 文件。
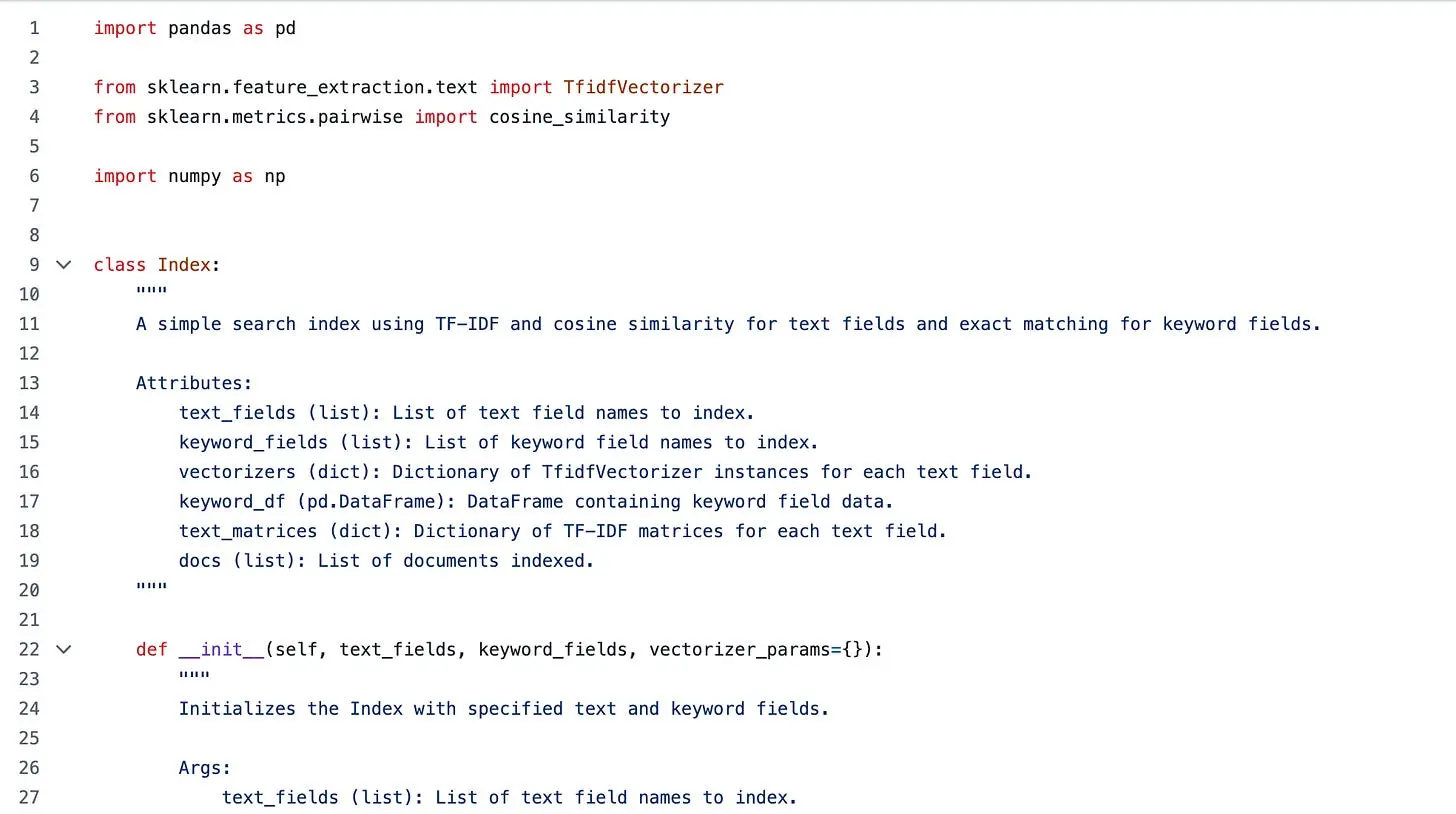
它只有一个类 Index,搜索采用的就是基于 TF-IDF 的词袋模型。
它的工作原理如下:
- 为每个文本字段拟合一个 TF-IDF 向量化器
- 使用相同的向量化器转换查询
- 将矩阵相乘以获得文档分数
- 将所有文本字段的分数相加
- 按分数对文档排序
在教学中,我使用了免费课程 Zoomcamps 的 FAQ 作为示例。一篇典型的文档包含问题、答案、章节、课程名称和一些元数据。
这已经需要比纯文本搜索更多的功能了。问题字段中的匹配应该比答案字段中的匹配权重更高。有时我只想要来自某一门课程的结果。所以第一个版本就有了字段加权(boosting)和关键词过滤功能。
这使得 minsearch 适合教学使用。它的实现足够小,学习者可以理解,但又包含了我真实课程示例所需的全部要素:文本搜索、过滤和加权。
基本用法如下:
from minsearch import Index
index = Index(
text_fields=["question", "answer"],
keyword_fields=["course"]
)
index.fit(docs)
results = index.search("can I join the course?")
我还在名为"构建你自己的搜索引擎"的工作坊中分享了如何构建它。该工作坊的第一个版本大约在两年前推出,最初是 DataTalks.Club 的一个演讲。后来我更新了它以包含更新的库版本,并将其作为 AI Shipping Labs 工作坊库中的结构化教程发布。
如果你想了解 minsearch 内部的工作原理,那个工作坊是最好的参考。
3、从文件到包
起初,人们直接下载那个单独的 Python 文件,这在我需要发布更改之前一直没问题。
每次我修复一些东西或添加功能时,课程参与者都必须重新下载文件。在 LLM Zoomcamp 中,我们通常用 wget 来下载。对于一个笔记本来说还好,但对于一个我不断修改的库来说就不太合适了。
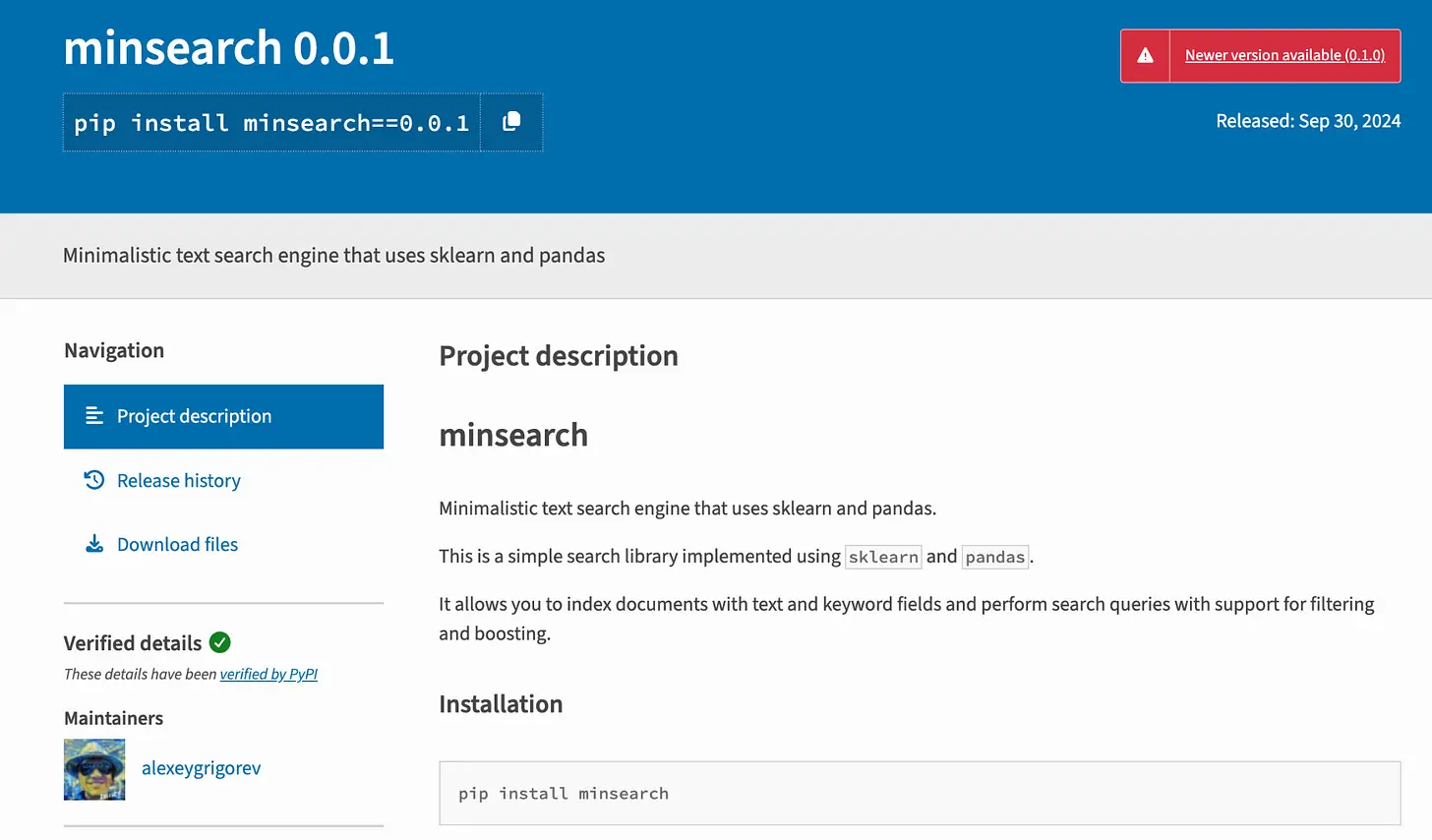
于是我把它正确地打包,发布到 PyPI,现在人们可以用 uv 或 pip 安装它:
uv add minsearch
第一个发布的版本是 0.0.1。截至撰写本文时,当前版本是 0.1.0。
4、我在哪里使用它
我现在在多个课程和工作坊中使用 minsearch:
我在教学之外也使用它,用于个人和 DataTalks.Club 项目。一个例子是 DataTalks.Club FAQ 系统,自动化系统读取 GitHub issues 并创建 FAQ 条目。在添加新问题之前,它会使用 minsearch 检查是否已存在类似问题。
我在 从 Google Docs 到 DataTalks.Club 课程的自动化 FAQ 系统 一文中介绍过它:
自动化系统加载 FAQ,构建索引,搜索它,然后在一个 Python 进程中继续执行。
这仍然是我使用 minsearch 的主要原因,但随着课程示例的变化,这个库也需要不断成长。
5、实现倒排索引和向量搜索
可追加索引是在后来出现的,当时我开始准备 LLM Zoomcamp 的第二轮,并添加了关于 Agent 的模块。
5.1 实现倒排索引
我想展示 Agent 可以做的不只是搜索现有文档,比如将数据添加回索引并修改它。原始索引对这种操作支持得不好。它是为简单场景构建的:创建索引、搜索它,然后在笔记本结束时丢弃。
为了允许 Agent 修改索引,我实现了一种新的索引类型:AppendableIndex。它是一个倒排索引,保留了相同的 fit 和 search 方法,但它还允许你一次追加一篇文档。

5.2 添加向量搜索
向量搜索后来也因为类似的原因被加入。我已经在"构建你自己的搜索引擎"中教授过它,但它最初并不是库的一部分。最终,我也把它加了进来。
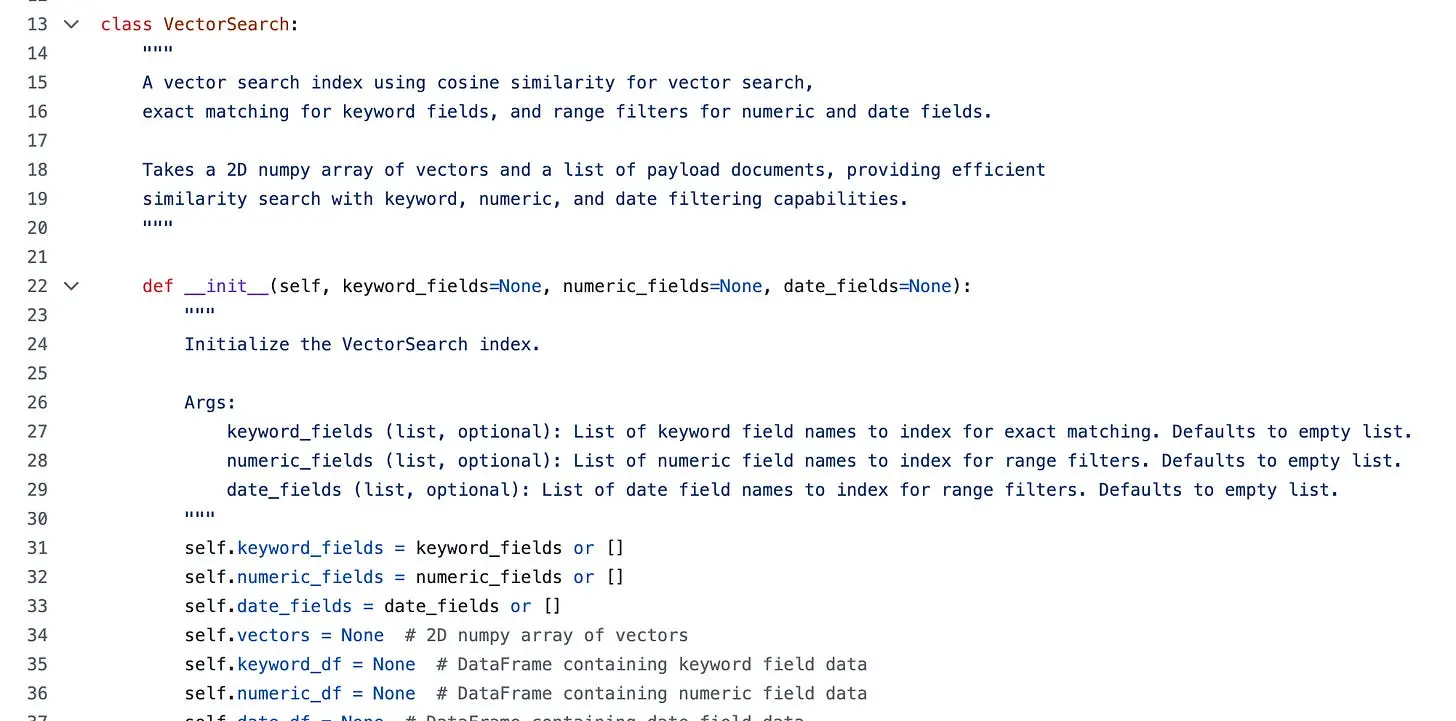
VectorSearch 基于预计算的嵌入工作,并通过余弦相似度对结果排序。它并不是要取代完整的向量数据库。它是一个用于本地示例的简单工具,我的主要用例是在课程和工作坊中解释搜索概念。
5.3 三种索引类型和高亮
如今该库有三种主要的索引类型:
Index:使用 scikit-learn 的基本 TF-IDF 索引AppendableIndex:允许后续添加文档的倒排索引实现VectorSearch:基于预计算向量的余弦相似度搜索
相同的过滤模型适用于所有三种类型。你可以按精确关键词匹配、数值范围和日期范围进行过滤。关键词字段现在是可选的,因为并非每个搜索示例都需要过滤。
现在还有高亮功能。它从搜索结果中提取片段,并标记查询词匹配的位置。动机是我们开始拥有越来越多的 Agent,我意识到对于 Agent 来说,最好模仿人类的查看方式。
人类搜索的方式是查看片段——例如在 Google 搜索中——然后根据我们看到的内容决定是否要查看一篇文章。对于 Agent,我认为如果它们能首先看到高亮的片段,然后基于这些片段决定是否查看整个页面以获取详细信息,效果会更好。
我不把 minsearch 看作一个大型基础设施项目。它之所以成长,是因为示例不断需要更多实用的功能。
6、使用 Claude Code 加速 minsearch
我越来越多地使用可追加索引,最终注意到一个问题:它比简单索引慢得多。
起初我选择了忽略。可追加索引做了更多工作,而且数据集很小。但在某个时刻,它甚至对我来说也太慢了,于是我决定对其进行基准测试。
第一次基准测试显示,可追加索引的索引速度大约慢 14 倍,搜索速度慢 27 倍。
我请 Claude 来看看,它发现了效率低下的原因。可追加索引在每次搜索时都重新计算 token 和分数,而简单索引依赖于 scikit-learn 的优化批量操作。
这是我第一次使用 AI 助手来基准测试和优化类似的东西。
我给了 Claude 一个清晰的循环:
- 对 Simple Wikipedia 进行基准测试并保存基线
- 修改代码
- 检查结果是否仍与基线匹配
- 比较速度
然后我让它运行,大约每小时检查一次,同时我继续准备课程材料。经过几轮后,优化后的可追加索引的搜索速度比基于 scikit-learn 的索引快了 20 到 76 倍。在更大的数据集上,差距更大。
完整的基准测试报告在这里:benchmark/BENCHMARK_WRITEUP.md。
7、什么时候 Minsearch 是正确的工具
Minsearch 适合以下场景:
- 你有小型或中型数据集
- 你需要在笔记本、课程、原型或小型自动化中进行搜索
- 所有东西可以在一个 Python 进程中运行
- 你正在索引最多几千篇文档
最佳适用范围是 10,000 篇文档以内。在这个规模下,索引速度快,搜索便捷,你无需搭建额外的基础设施就能获得一个有用的检索层。
当有足够的纯文本可供搜索时,效果最好。课程 FAQ、工作坊数据集、文档页面和小型内部文档集合都属于这种情况。
超出这个范围,minsearch 就不再是合适的工具了。
如果你有更大的本地数据集但仍想要轻量级方案,请改用 SQLiteSearch。我正是为这种情况构建了它,并在 我如何构建 SQLiteSearch 一文中写了相关介绍。
对于更大的系统,请使用真正的搜索引擎或向量数据库。
原文链接: Minsearch: The Small Search Library Behind My RAG Workshops and Courses
汇智网翻译整理,转载请标明出处
