MIRAS:语言模型背后的蓝图
Google 的新框架揭示,每一个现代序列模型都在解决同一个四选优化问题

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我们用来让语言模型更好记忆的许多巧妙机制——门控函数、权重衰减、自适应遗忘——原来都是同一个底层原则 retention gate(留存门) 的实例。
Titans 的遗忘机制,例如,可以被重新解读,不是作为一个擦除的门,而是作为一个决定保留多少的留存门。
每一个现代序列模型都管理着记忆。区别在于方式:
- Transformers 维护一个 KV 缓存,(在最佳情况下)随上下文长度线性扩展。
- Mamba 将上下文压缩成固定大小的状态。
- Titans 连接一个神经网络,在推理过程中更新自己的权重。
不同的架构。不同的机制。不同的理念。但最终,它们都在试图解决同一个问题。
每一个有记忆的模型都在学习映射键和值,由一个特定的内部目标引导,受一个控制更新如何发生的正则化器约束,并在先前知识和有价值的新信息之间取得平衡。
四个设计选择。每一个处理序列的深度学习模型都在做这些选择,无论其设计者是否意识到。
这就是 MIRAS 的核心主张,它重写了整个序列建模的格局
MIRAS——在波斯语、阿拉伯语和土耳其语中意为"遗产"——是一个 设计框架,揭示了你听说过的每一个序列架构背后的四个选择。
1、每一个序列模型都在解决同一个问题
如果你看看过去几年定义序列建模的模型——RetNet、Mamba、GLA、DeltaNet、Gated DeltaNet、RWKV-7、DeltaProduct、TTT、Titans。每一个都在定义一个新架构,并声称在解决传统序列建模难题方面具有新颖性。
现在看看每一个实际上优化的是什么。
所有这些模型都使用相同的注意力偏置(ℓ₂ 回归或点积相似度)和相同的留存门(ℓ₂ 正则化)。它们之间的差异是真实但肤浅的:标量与通道级门控、数据依赖与静态参数、向量与矩阵记忆。这些是重要的工程选择。不是根本的架构创新。
整个领域一直在探索一个巨大设计空间的一个角落,而 MIRAS 是整个地图
MIRAS 使当前序列建模中设计空间的狭小变得可见。九年的线性循环神经网络(RNN)研究一直在一个更大建筑的一个房间里徘徊。这个房间很美。但还有更多房间可以参观。
让我们深入这个蓝图
2、每一个序列模型背后的四个设计选择
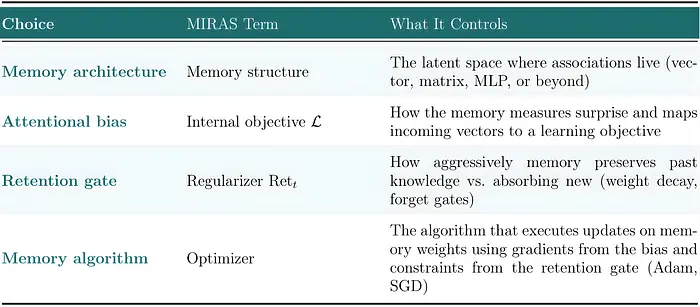
每一个序列模型都由四个设计选择定义。MIRAS 命名它们,形式化它们,并且——第一次——将它们视为可以混合和匹配的独立轴。
第一个是 memory architecture(记忆架构):关联所在的潜在空间。一个向量、一个矩阵和一个 MLP——每一个都定义了存储键值映射的不同容量。
第二个是 attentional bias(注意力偏置):驱动每次更新的内部损失目标,创建学习信号。这就是记忆如何衡量它预测的和实际到达的之间的差距——"惊喜"的定义,塑造每一个学习步骤。
第三个——也是框架的明星——是 retention gate(留存门):控制记忆如何积极地保留过去知识与吸收新信息的正则化器。你遇到的每一个遗忘门都是伪装中的留存门。
第四个是 memory algorithm(记忆算法):使用来自注意力偏置的梯度和来自留存门的约束执行实际权重更新的优化器。SGD、Adam 和 momentum 每一个都产生不同的学习动态。
数学上,框架中的每一个模型在每个 token 上解决相同的优化:

让我们独立地剖析这些旋钮中的每一个。
2.1 记忆架构:知识存在的几何
记忆架构本身就是潜在空间:
- 向量记忆一次存储一个关联——快速且便宜,但有限。
- 矩阵记忆存储整个键值映射,RetNet、Mamba 和 GLA 背后的主力。
- MLP 记忆——Titans 和 TTT 使用的——将关联存储在一个小神经网络的权重中,以更高的更新成本获得非线性容量。
梯子的每一步都用计算换取表达能力。
但容量只是故事的一半。架构还限制了其他三个选择可以做什么:基于 MLP 的记忆需要基于梯度的更新,而基于矩阵的记忆允许更简单的解决方案。这个选择波及整个框架。
进一步推广——到非欧几里得记忆几何,如用于层次结构的超流形或用于方向数据的球面流形——是一个自然的扩展,但主要由 geometric deep learning 文献而不是 MIRAS 本身涵盖。
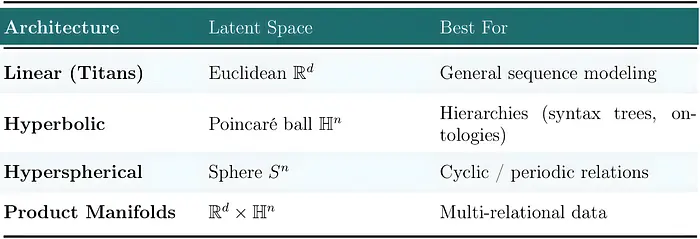
框架在这个轴上的贡献是将记忆架构 命名 为一个独立的设计选择;用更丰富的几何填充那个轴是未来工作,主要是针对不同研究社区的。
2.2 注意力偏置:模型如何定义"惊喜"
注意力偏置是记忆为每个新 token 优化的目标函数,通常由损失函数捕获。它是记忆的 惊喜 定义:它如何衡量它预测的和实际到达的之间的差距。
这个选择对学习动态有直接后果。正如我们在 titans-how-google-taught-ai-to-surprise-forget-and-remember 中看到的,记忆损失函数的梯度是 惊喜信号 ——小损失意味着"我以前见过这个",大损失意味着"这是新的,注意。"
误差的大小决定了记忆更新的积极程度。计算得太积极,一个异常值 token 就会劫持整个记忆状态。计算得太温和,模型就无法区分真正的新奇和噪声。
几乎每个现有模型都使用相同的答案来解决这种张力:ℓ₂ 回归,记忆预测和真实值之间的均方误差。成比例的、平滑的、表现良好的。但它远非唯一的选择——MIRAS 打开了整个损失函数格局。
ℓₚ-norm attentional bias 将 ℓ₂ 推广到任意指数。在 p = 2 时,我们恢复每个现有模型。在 p = 1 时,有趣的事情发生了:记忆只存储误差的 符号,将键映射到 -1 和 +1 的两个极端类别。
作者称之为 valueless associative memory(无值联想记忆),并画了一个与人类应对机制的迷人平行——在极端事件下,大脑存储 发生了某事 而不保留确切的值。

我们可以使用 Huber loss 平滑惊喜信号,它给记忆一个应对异常值的机制,基于阈值 δₜ 产生不同的结果:
- 低于阈值 δₜ,它的行为像 ℓ₂——成比例的、平滑的。
- 高于 δₜ,它切换到 ℓ₁——有上限的梯度,对异常值鲁棒。
模型 动态地 决定每个 token 属于哪个区域。
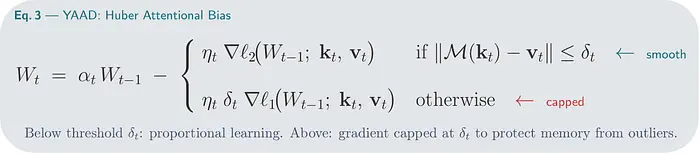
这就是 YAAD 背后的架构,MIRAS 的三个新模型之一
YAAD 使用带有 ℓ₂ 留存的 Huber 注意力偏置——一个平滑吸收常规 token 但对极端惊喜限制其响应的系统。在实验中,YAAD 在长上下文任务上优于纯 ℓ₂ 模型,正是因为它拒绝让异常值 token 劫持记忆。
2.3 留存门:框架的真正明星
留存门是约束记忆在每次更新中漂移多少的正则化器。
每次新 token 到达时,记忆都面临一个根本的张力:吸收新信息还是保留它已经知道的东西。
留存太少,一个令人惊讶的 token 就会覆盖一切——模型变得健忘,追逐它最后看到的东西。
留存太多,模型变得僵化,即使证据确凿也无法适应真正的新模式。
你遇到的每一个"遗忘门"——在 LSTMs、GRUs、Mamba、RetNet 中——都是伪装中的留存门
看起来像是主动决定擦除的,数学上是对记忆被允许偏离其先前状态多远的惩罚。
在 Titans 中,这表现为自适应权重衰减:模型基于来自注意力偏置的惊喜信号动态控制保留多少旧记忆:
- 高惊喜放松留存约束,为新信息腾出空间。
- 低惊喜收紧它,保持记忆稳定。
MIRAS 在整个序列模型分类法中明确了这个映射:

仔细阅读最后一行。Transformer 只是一个具有 无限留存 的联想记忆——它从不更新测试时的权重,所以它从不需要平衡学习与遗忘。这是 MIRAS 内的一个设计选择,不是一个根本不同的范式。
这种重新定义不是表面上的。LSTM 的 sigmoid 遗忘门可以被重新解释为 ℓ₂ 留存正则化器——一个与新记忆状态和先前记忆状态之间平方距离成比例的惩罚。
sigmoid 近似一个近端惩罚。模型不是在擦除——它是 under-retaining(留存不足)。
门控制记忆被允许改变多少,而不是删除什么。 这是对机制的数学观察:真实的大脑确实有主动遗忘过程。但在深度序列模型内,每一个"遗忘门"都计算一个留存惩罚。
数学上总是留存。我们只是称它为遗忘。
一旦你将留存门视为一个独立的轴,你就可以开始转动它。把它想象成惊喜的恒温器。当一个新 token 到达并产生大梯度时,留存门决定记忆响应的积极程度。
每个范数在记忆上产生根本不同的"更新力":
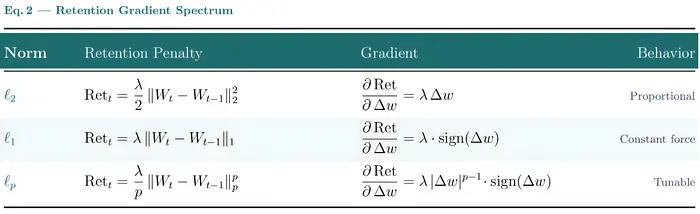
ℓ₂ 是 Goldilocks 区域——平滑的 Hebbian 学习,让令人惊讶的事实更新记忆而不破坏长期知识。ℓ₁ 不关心大小:小变化和大变化受到相同的力,产生稀疏的、积极的更新——二元的"保留或覆盖"决策。MIRAS 实验证实了利害关系。
将留存范数从 ℓ₂ 改变为更高指数的 ℓ-norm(如 Moneta 所做的)直接影响相对于上下文长度的缩放行为。
另一方面,elastic-net 留存(ℓ₁ 和 ℓ₂ 的混合)提供了另一个选择:在稀疏选择(通过软阈值进行硬遗忘)和平滑整合之间的可调拨盘。
# MIRAS retention: your optimizer IS the retention gate
# AdamW weight_decay ≈ L2 retention
optimizer = AdamW(memory_params, weight_decay=lambda_) # λ controls retention strength
# For L_p retention (general case):
bias_loss = F.mse_loss(W @ keys, values) # attentional bias
ret_loss = (lambda_ / 2) * torch.norm(delta_W, p=2) ** 2 # retention
total = bias_loss + ret_loss
2.4 记忆算法:隐藏在明处的优化器
记忆算法是实际计算权重更新的机制。梯度下降是默认的。
但算法的选择是当前文献中探索最少的轴,MIRAS 明确表明优化器是一流的设计选择,而不是实现细节——因为优化器决定了 如何 注意力偏置和留存门交互:
- 单步梯度下降独立处理每个更新:计算梯度,应用留存,继续。
- Momentum 跨 token 累积惊喜,允许记忆在承诺大更新之前建立信念——这正是 Titans 使用的,也是它的惊喜指标从优化步骤自然出现的原因。
- Newton's method 使用二阶信息以闭式解决内部优化。对于二次注意力偏置,这坍缩为值替换——即 delta rule——产生比梯度下降采取的小加法步骤更具表达力的"精确"更新。这就是 DeltaNet 和 Mesa-layer 可以被解读为 MIRAS 的 Newton-step 实例而不是梯度下降实例的原因。
相同的注意力偏置,相同的留存门,不同的优化器——根本不同的记忆行为
3、前向传播正则化不是记忆留存
在 MIRAS 之前,很容易混淆两种完全不同的正则化。LayerNorm、Dropout、RMSNorm——这些稳定 前向传播。它们控制梯度流,防止共适应,并保持激活在健康范围内。它们作用于信号,而不是记忆。
留存门在计算中根本不同的点操作:在优化器步骤内部,在梯度计算之后,当模型决定更新其记忆权重多少时。
Forward Pass: x → [LayerNorm → Dropout → FFN → ...] → loss → gradients
↑ Signal regularization (stability)
Optimizer: gradients → Δw → w_new = w_old + Δw − λ(w_new − w_old)
↑ Memory regularization (retention)
LayerNorm 将 transformers 从梯度灾难中拯救出来。留存门将 AI 从记忆灾难中拯救出来。
这种解耦不仅仅是理论上的优雅。前向传播正则化获得 到记忆的干净梯度。留存门保持 记忆随时间干净。
Transformers 从不需要区分这些,因为它们的权重是静态的——没有测试时更新,没有留存问题。但一旦你允许模型在推理时学习——如 Titans、TTT 和现在的 MIRAS 所做的——这种区分就变得承载负荷。没有留存,记忆容量很快饱和;Hebbian 学习的加法性质导致记忆溢出。
有了适当的留存,模型可以在更长的上下文中管理其固定大小的记忆。
4、Moneta/YAAD/Memora:一个框架的三个模型
命名设计空间的回报是能够搜索它。MIRAS 作者选择三个特定的组合——每一个都为不同的记忆个性设计——并证明它们优于每一个现代基线。
Moneta 使用 ℓₚ 注意力偏置和不同指数的 ℓ-norm 留存门。敏锐、积极的记忆,擅长检索密集型任务。消融发现 p≈3 是注意力偏置的最佳点,放大令人惊讶的 token 同时抑制常规 token;留存指数独立控制相对于上下文长度的缩放行为。
敏锐度:一个为记住令人惊讶的事实而调整的记忆
YAAD 使用带有 ℓ₂ 留存的 Huber 注意力偏置。鲁棒、自适应的记忆,优雅地处理异常值——ℓ₂/ℓ₁ 切换点,通过输入依赖的阈值 δₜ 每个 token 学习,让极端 token 注册而不让它们主导。
平滑度:一个为保持上下文完整而调整的记忆
Memora 使用 ℓ₂ 注意力偏置和 KL-divergence 留存,这从根本上改变了"保持接近先前记忆"的含义。ℓ₂ 留存将旧记忆和新记忆之间的差异测量为单个欧几里得距离——将记忆视为平坦空间中的一个点——而 KL 留存将它们作为 概率分布 进行比较,询问记忆的信念的 形状 移动了多少,而不是它的坐标移动了多远。
分布:一个为权重的含义而调整的记忆,而不仅仅是它们是什么
对于 Memora,结果是记忆的自信部分抵抗变化而不确定的槽位容易适应,更新规则本身变成乘法而不是加法:权重被梯度的指数缩放并通过 softmax 重新归一化到概率单纯形上。
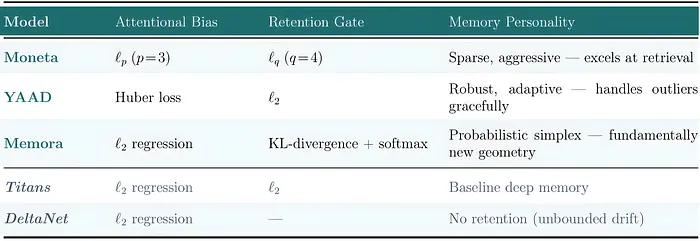
三个都击败了每一个现代线性循环模型,并与包括 softmax 注意力的混合架构相抗衡。在针中寻草基准(RULER)上,Moneta 在从 1K 到 8K 的序列长度上平均达到 93.5,而 Gated DeltaNet 为 75.8,Mamba2 为 52.0。这些不是边际收益。
真正的突破不是 Moneta、YAAD 或 Memora。而是使发明它们变得微不足道的框架。
5、设计空间刚刚爆炸
三个组合。论文留下未触及的数百个合理替代方案。
考虑空间实际是什么样子:多个注意力偏置(ℓ₂、ℓₚ、Huber)× 多个留存门(ℓ₂、ℓₚ 、KL、elastic-net、Bregman divergence)× 多个记忆架构(线性、MLP、双曲、球面、乘积流形)× 多个优化器(GD、momentum、Newton's、隐式方法)。
这个格子的每一个单元都是一个潜在有效的序列模型。在 MIRAS 之前,几乎所有它们都是不可见的。
影响远远超出语言建模:
- 持续学习变得原生。 MIRAS 模型按设计在测试时学习。没有预训练-微调分割。优雅的上下文内遗忘成为一个可调的设计参数,而不是一个突发的失败模式。
- 智能体 AI 获得了一个原则性的记忆基底。 一个在 episode 中更新其记忆的智能体——记住工具输出、纠正失败策略、巩固部分成功——现在有一个框架来选择 如何 该记忆巩固,而不是即兴发挥。
- 多模态流变得自然。 视频帧、DNA 序列、传感器数据——任何可表达为键值对的东西都流经相同的框架。留存范数的选择成为一个模态特定的设计问题。
- 几何序列模型变得可处理。 流形工程方向——用于层次结构的超曲记忆,用于周期信号的球面记忆——等待有人对其进行基准测试。
Titans 已经是一个范式转变。MIRAS 完成了图景。它向我们展示 Titans 是设计空间中的一个点,而不是目的地
过去五年我们称之为"创新"的架构是单一主题的变化。命名主题的框架是让我们最终听到其余音乐的那个。
原文链接: MIRAS: The Blueprint Behind Transformers, Mamba, and Titans
汇智网翻译整理,转载请标明出处
