模型实验室正在走向编排层
三家前沿实验室在十二个月内转向了运行时。以下是什么在消亡,什么在兴起。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
周三,在一家法国银行。你的 agent 原型在正常路径上运行良好。然后有人问,如果在凌晨两点进行一个 22 步的 KYC 审查时,第三次工具调用中途失败了会怎样。
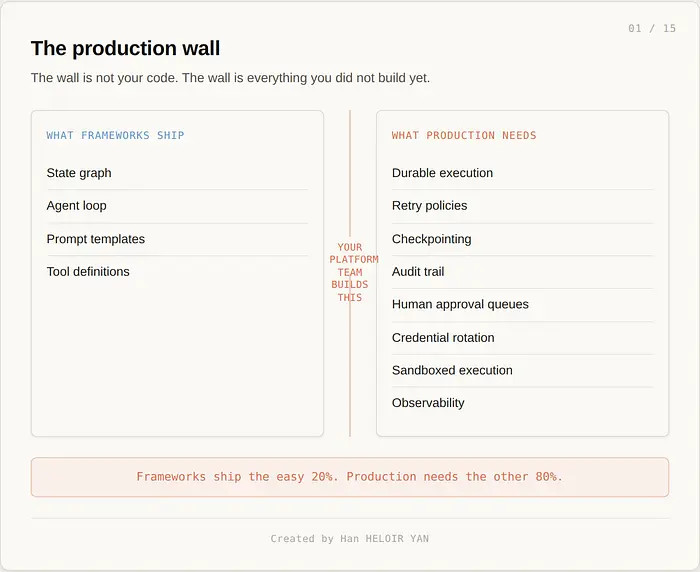
你去查看你的 LangGraph 代码。你看到一个 Python 状态机。你没有看到重试机制。你没有看到检查点。你没有看到人工审批队列。你看到的是一堵墙。
你花了一周时间在 Temporal 上做原型。持久执行、确定性重放、精确一次语义。它运行正常。你觉得自己很聪明。然后你想起 Temporal 不会在工作流内部运行你的 LLM 调用,因为它们是非确定性的。你需要构建一个封装层。一个沙箱。一个可观测性栈。凭证轮换。在 agent 上线之前需要两个月的平台工程工作。
当你在规划平台工作时,Mistral 发布了 Workflows。Anthropic 发布了 Managed Agents。OpenAI 扩展了 Agents SDK,加入了 Agent Builder 和 ChatKit。他们每一家都构建了 Temporal 形状的部分,加上沙箱,加上可观测性,加上凭证管理,并通过一个小型 API 界面交给你。你不需要一个平台团队。你需要你的模型供应商成为一个平台。
三家前沿实验室,在大约相同的十二个月窗口内,发布了功能上相同的产品。这不是巧合,也不是一个功能。这是模型实验室停止成为模型实验室的时刻。
如果你在生产环境构建 agent,这至少消除了你正在评估的三个供应商类别。如果你在起草平台架构,你关于持久执行的部分刚刚变短了。如果你在分配资本,编排层刚刚获得了三个已经拥有模型层的新巨头。
1、Mistral 在 4 月 28 日实际上发布了什么
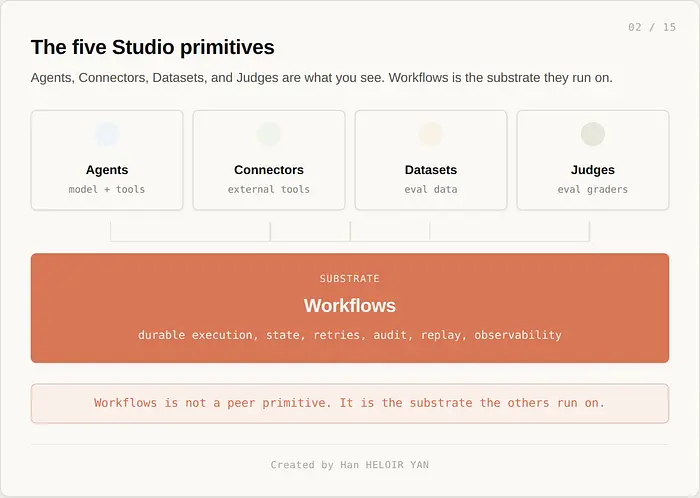
Workflows 不是一个 agent 功能。它是 Studio 中其他一切的运营骨干。
4 月 28 日发布的大部分报道都忽略了这一点。Workflows 与 Studio 的其他四个原语一起发布:Agents、Connectors、Datasets 和 Judges。其他四个是你看到的东西。Workflows 是当某些东西在大规模运行中出现问题时将它们联系在一起的东西。
具体来说,Workflows 是作为托管产品的持久编排。你声明式地定义一个工作流,平台处理状态、重试、重放、可观测性、人工审批和精确一次语义。Mistral 通过 Studio API 和 Vibe CLI 暴露它。在底层,它运行在 Temporal 上。我们将在下一节讨论为什么。
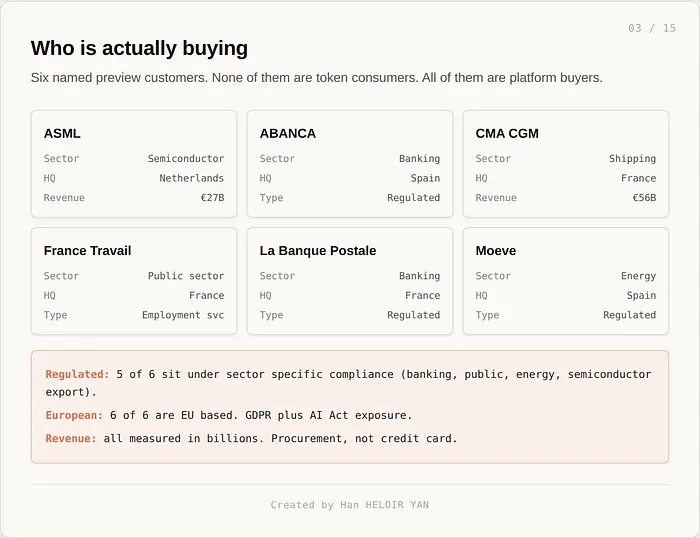
Mistral 报告说系统在预览发布时已经每天执行数百万个工作流。请将这个数字视为自报告的。可验证的是客户名单:ASML、ABANCA、CMA CGM、France Travail、La Banque Postale、Moeve。这些不是按 token 付费的 API 消费者。这些是横跨半导体、银行、航运、公共就业服务和能源的数十亿欧元企业。他们购买的是平台承诺,而不是积分。
架构很重要。Workflows 运行在混合模型上:控制面在 Mistral 的云中,数据面在客户的 VPC 内部。你的提示词、工具调用和中间状态永远不会离开你的环境。编排器负责协调,但它看不到有效载荷。
这是在 GDPR、欧盟 AI 法案以及受监管的欧洲企业现在写入其 AI 采购的主权要求下唯一可行的架构。目前没有美国前沿实验室提供这种架构。这就是 Mistral 用来进入那些本会默认选择 OpenAI 或 Anthropic 的账户的楔子。
2、Temporal 赌注
OpenAI 从头构建了他们的编排器。Anthropic 从头构建了他们自己的。Mistral 做了一个更有趣的赌注。
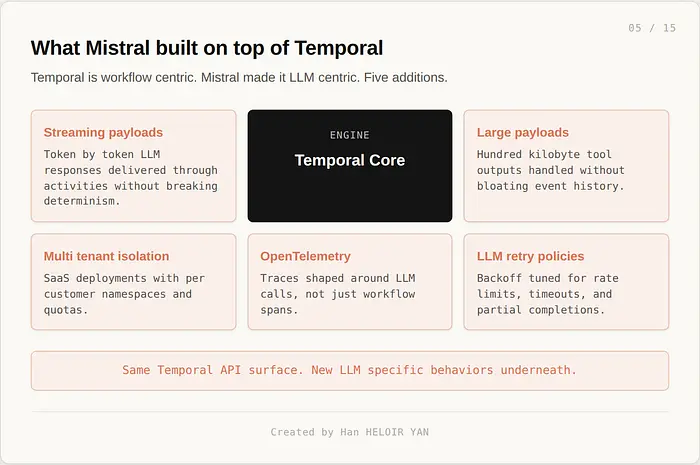
Mistral 没有构建 Workflows。Mistral 在 Temporal 之上构建了一个 LLM 特定的层——Temporal 是运行 Netflix、Stripe、Salesforce 以及大约一半金融系统后台的持久执行引擎。这个选择并不偷懒。它是三个实验室中最有主见的赌注。
Temporal 的核心原语是代码即工作流。你编写看起来像普通 Python 或 Go 的代码,引擎保证每个步骤要么完成、要么重试、要么从最后一个已知良好状态重放。在工作器执行中途崩溃它,当一个新工作器上线时工作流会从中断的地方继续。这就是持久执行,是每个受监管企业都需要而几乎没有任何 LangGraph 部署拥有的特性。

这个权衡是真实的。Temporal 在工作流定义内强制确定性。副作用(网络调用、LLM 调用,任何非确定性的东西)必须被包装在活动中,引擎会将这些活动记录到事件历史中。你不能直接在工作流中调用 LLM。你将调用定义为一个活动,活动记录其结果,在重放时工作流读取记录的结果而不是再次调用 LLM。这意味着你的代码看起来比在 LangGraph 中稍微奇怪一些。这也意味着当工作器在运行中途死亡时,你的 agent 不会向你重复收费。
Mistral 在此之上添加的内容才是真正的工作所在。Temporal 原生不处理流式 LLM 有效载荷(逐 token 的响应)。它不太擅长处理大型有效载荷大小(十万字节级别的工具输出)。它默认没有多租户隔离,其可观测性是以工作流为中心的,而不是以 LLM 为中心的。Mistral 将这些中的每一个构建为 Workflows 特定的扩展,为已经了解 Temporal API 的工程师保留了 Temporal API 界面,并将结果作为托管服务发布。
这是长期资产还是长期约束,取决于五年后你称之为 agent 的东西是否仍然看起来像一个工作流。如果是,Mistral 就有了领先优势。如果不是,从头构建的实验室可以更快地转向。
3、Workflows 程序的形态
尽管有关于持久执行的所有架构争论,你编写的代码看起来几乎很无聊。这就是重点。
开篇提到的 KYC 银行不是假设的。Workflows 发布的正是你会编写的程序形态——如果你坐下来将一个受监管的多步骤 agent 任务表达为代码的话。大约五十行:
from mistralai.workflows import workflow, activity, Workflow
from mistralai import Mistral
@activity
async def extract_identity(documents: list[bytes]) -> dict:
client = Mistral()
response = await client.agents.complete(
agent_id="kyc-extractor",
inputs={"documents": documents},
)
return response.parsed
@activity(retry_policy={"max_attempts": 5, "backoff": "exponential"})
async def check_sanctions(name: str, dob: str) -> dict:
return await sanctions_api.lookup(name=name, dob=dob)
@activity
async def score_risk(profile: dict) -> float:
client = Mistral()
response = await client.agents.complete(
agent_id="risk-scorer",
inputs=profile,
)
return response.parsed["risk_score"]
@activity
async def create_account(customer_id: str, profile: dict) -> str:
return await core_banking.create(customer_id, profile)
@workflow
class KYCReview(Workflow):
async def run(self, customer_id: str, documents: list[bytes]):
identity = await self.execute(extract_identity, documents)
sanctions = await self.execute(
check_sanctions, identity["name"], identity["dob"]
)
if sanctions["match"]:
return {"status": "rejected", "reason": "sanctions_match"}
risk_score = await self.execute(
score_risk, {"identity": identity, "sanctions": sanctions}
)
if risk_score > 0.7:
decision = await self.wait_for_signal(
"compliance_review", timeout="7d"
)
if decision["outcome"] != "approved":
return {"status": "rejected", "reason": decision["notes"]}
account_id = await self.execute(
create_account, customer_id, identity
)
return {"status": "approved", "account_id": account_id}
让我们看看每行代码下面发生了什么。

持久性。 运行这个程序的工作器在 extract_identity 和 check_sanctions 之间死亡。一个新工作器启动,读取事件历史,看到 extract_identity 已经返回了结果,跳过它,接下来运行 check_sanctions。你不会为 LLM 调用付两次费。你没有编写恢复逻辑。Workflows 帮你做了。
重试。 制裁 API 不稳定。check_sanctions 携带一个重试策略:五次尝试,指数退避。工作流代码中没有 try except。没有你维护的重试队列。平台读取策略并应用它。
人在回路中。 当风险分数超过 0.7 时,工作流调用 wait_for_signal("compliance_review", timeout="7d") 并暂停。它不占用工作器。除了磁盘上序列化的状态之外,它不消耗内存。合规官在 Studio(或你在此基础上构建的自定义 UI)中审查案件,点击批准或拒绝,平台发送信号,工作流恢复。中位等待时间可能是三小时,p99 可能是三天。代码不在乎。
审计。 每个活动结果都带有时间戳记录。当监管机构询问 3 月 14 日客户 84319 发生了什么时,从事件历史中获得确定性答案,而不是从日志抓取中猜测。
重放。 score_risk 中的一个 bug 在六个月后暴露。你修复它,针对原始事件历史重放工作流,修正后的代码产生正确结果而无需重新运行任何 LLM 调用。这是框架不提供的取证调试。
在 LangGraph 中,这些特性中的每一个都需要八周的平台工作。重试你自己写。事件历史你自己构建(用什么数据库,什么保留策略,什么 schema)。人工信号你通过队列接入。审计你后加上去。重放你根本得不到,因为 LangGraph 状态不是日志式的。在 Workflows 中,同样的 agent 大约五十行代码,周二就能上线。
这就是未来十年每个受监管 agent 工作负载在生产环境中的形态。框架发布工作流类。实验室发布其他一切。
4、钳形攻势
Agent 框架不是因为不好而消亡。它们消亡是因为它们出售的抽象现在已经无处不在。
LangGraph、CrewAI、AutoGen、Pydantic AI 等等发布了 agent 运行时问题中简单的 20%。定义状态图。定义 agent 人设。定义交接。定义工具 schema。开发者体验很好,从原型到运行的时间以小时计,开源许可证是宽松的。
困难的 80% 是 demo 之后的一切。在工作器崩溃后仍然存活的持久执行。满足监管机构的审计跟踪。在有人点击之前阻止工作流的人工审批队列。不需要重新部署 agent 的凭证轮换。SaaS 部署中客户之间的多租户隔离。让你能问这个 agent 上周二为用户 X 做了什么的可观测性。框架不提供这些中的任何一个。它们期望你自己加上。
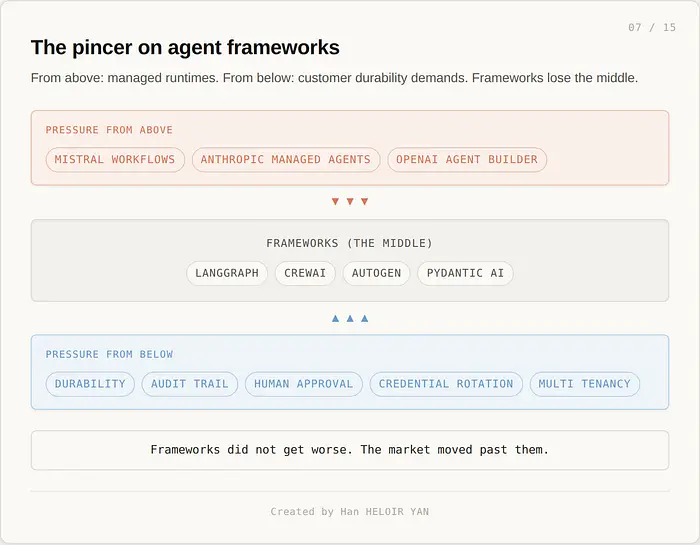
两年来,"自己加上"是一个可行的答案,因为没有人在卖这个。今天,三家前沿实验室在卖。Workflows、Managed Agents 和 Agent Builder 将困难的 80% 作为托管服务发布。不是作为一个功能。作为运营基底。框架现在位于基底之上,而不是旁边。
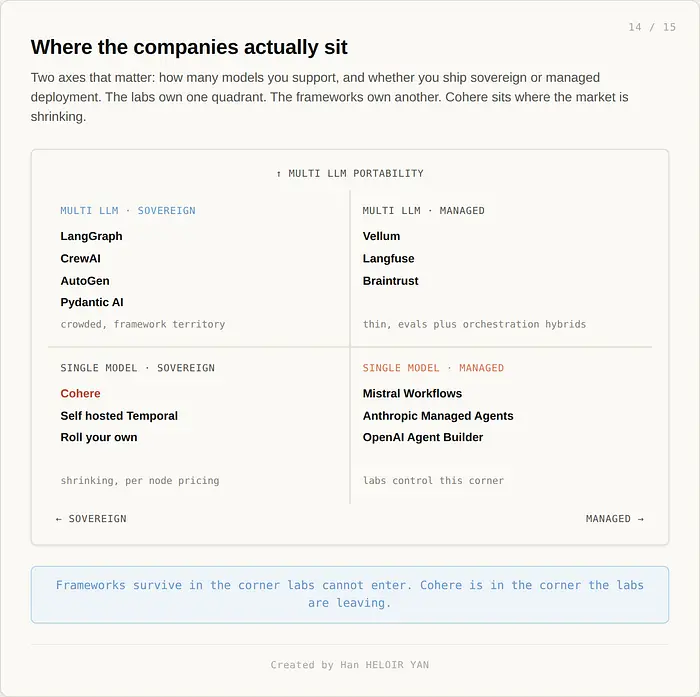
诚实的反驳:框架仍然赢得三样东西。多 LLM 可移植性(Workflows 不运行 Claude,Managed Agents 不运行 Mistral)。法规完全禁止托管服务的自托管部署。以及绿地项目的原型速度,在向任何供应商的运行时承诺之前你想比较三种架构。这些都不小。它们为框架定义了一个真正的长期生态位。只是不再是框架被推销的那个生态位。
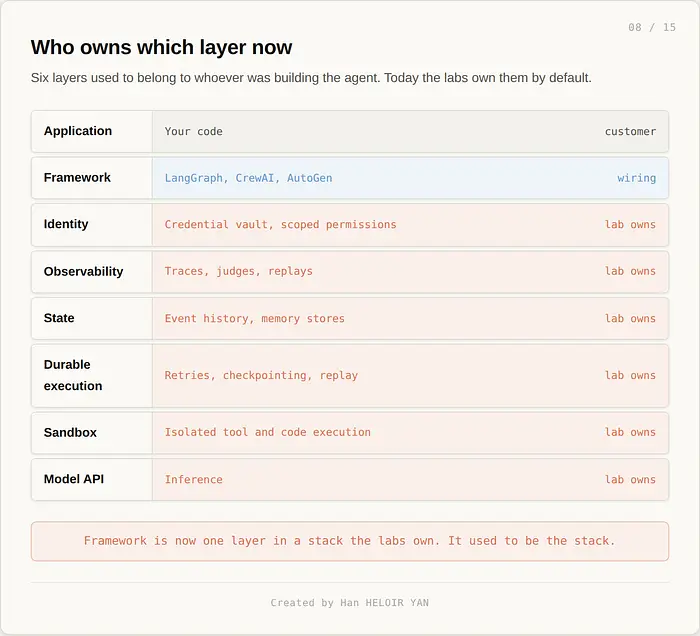
新的平衡看起来像这样。框架作为 IDE 位于实验室运行时之上,就像 React 位于浏览器 API 之上。框架是你编写 agent 的地方。运行时是 agent 存活的地方。混淆这两层的公司将把预算输给同时购买两者的公司。
5、这是一个品类动作,不是 Mistral 的动作
如果你只读了一个公告,这看起来像是 Mistral 的发布。读了三个,你在看一个品类形成。读了四个,你看到谁被落下了。
2026 年 4 月 9 日。Anthropic 在 Claude 平台上发布了 Managed Agents 公开测试版。公告文案明确称其为针对生产基础设施调优的 agent harness。沙箱化代码执行。检查点。凭证库。限定权限。端到端追踪。内存存储。会话 API。除了特定的持久性后端之外,与 Workflows 是完全相同的产品。
在 2025 年整个期间,OpenAI 分块推出了相同的栈。Responses API 取代了 Chat Completions 和 Assistants。Agents SDK 以开源方式发布了带交接、护栏和追踪的托管编排。Agent Builder 作为托管可视化编辑器发布。ChatKit 作为部署面发布。Sandbox Agents 作为隔离执行环境发布。到 SDK 达到第一个稳定版本时,OpenAI 正在运营与 Mistral 现在在 Studio 中发布的相同的五个原语栈:agent 循环、持久执行、沙箱、可观测性、身份。
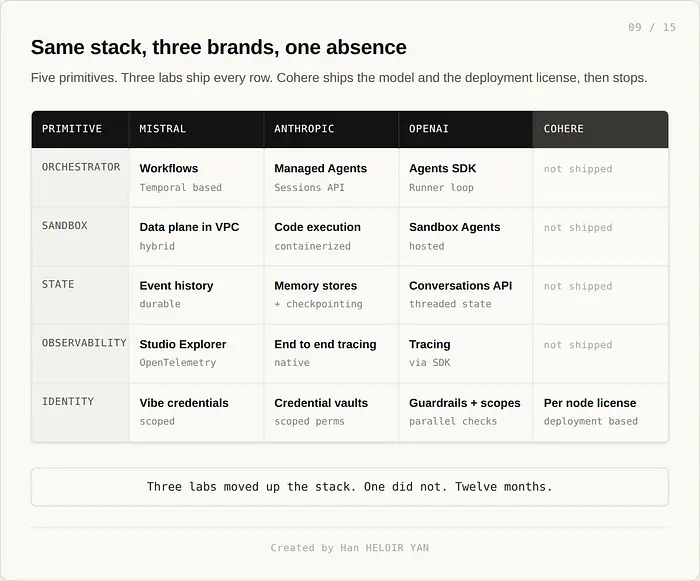
词汇告诉你一切。Anthropic 称之为 harness。Mistral 称之为 Workflow。OpenAI 称循环为 Runner,称单元为 Agent。同一个原语用三个不同的词。当三个竞争实验室在相同的十二个月内收敛到同一个原语时,你看到的不是三个产品决策。你看到的是一个品类在形成。
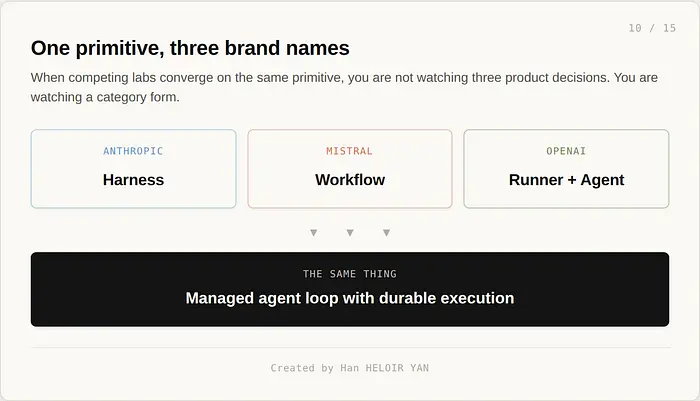
两种压力迫使了这种情况。技术压力:任何试图将 agent 投入生产的人都发现,agent 不完全是模型行为,它是运行时行为。模型可能只贡献了 agent 在生产中工作的 20%。另外 80% 是状态管理、沙箱化、重试、审计、凭证、可观测性和编排。出售没有那个运行时的模型就像出售没有汽车的方向盘。
商业压力:token 利润率在压缩。Mistral Small 4 的价格比同类专有模型低 5 到 7 倍。GPT 系列定价在过去十八个月中大幅下降。Anthropic 的每 token 毛利润也在竞争压力下收紧。如果你是一个前沿实验室,而你的 token 正在商品化,你有两个选择。向上进入运行时栈,或者看着你的利润率归零。三个实验室选择了相同的选项。
一家前沿实验室留在了旧模式中。 Cohere 仍然出售部署节点,仍然按 GPU 而不是按工作流运行定价,仍然定位为模型和授权而不是运行时。那里的赌注是本地主权 AI 是一个足够可防御的市场,不需要向上进入栈。接下来的两年将检验这个赌注。如果托管运行时继续赢得 Cohere 本会服务的欧洲主权账户(Workflows 正在做的事),按节点定价将成为化石。
6、为什么是现在(经济学)
Token 收入看起来像 AI 业务。它是 AI 业务的亏本引流品。
前沿模型定价在过去十八个月中大幅下降。Mistral Small 4 的价格在 2024 年初是不可预测的。GPT 模型定价在整个系列中都压缩了。Anthropic 的每 token 毛利润在竞争压力下收紧。轨迹很清晰:token 趋向于商品基础设施,就像之前的带宽和存储一样。出售商品基础设施最终是一个 10% 毛利率的业务。
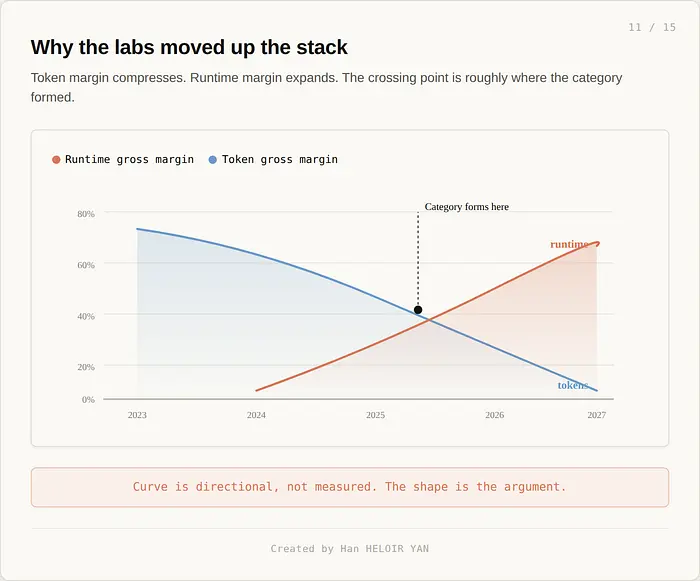
运行时是完全不同的业务。在受监管银行的 Workflows 合同是多年期的、六位数年度经常性收入,切换成本以月计的平台工程衡量。在 Stripe 或 Ramp 的 Managed Agents 部署是相同的形态。Token 在一小时内就可以切换。运行时合同持续三到五年,并在账户内增长,因为客户发布的每个新 agent 都运行在同一个基底上。
这种不对称是残酷的。一个 token 客户可能通过 API 产生几百到也许一万美元的年收入。一个在托管运行时合同上的受监管企业从相同的工作负载中产生数十万到个位数百万美元的收入,毛利润更高,持续时间更长,边际获取成本更低——因为现有的 token 关系正是产生这笔交易的源头。如果你是一个前沿实验室的 CFO,你不需要算两次。你向上进入栈。
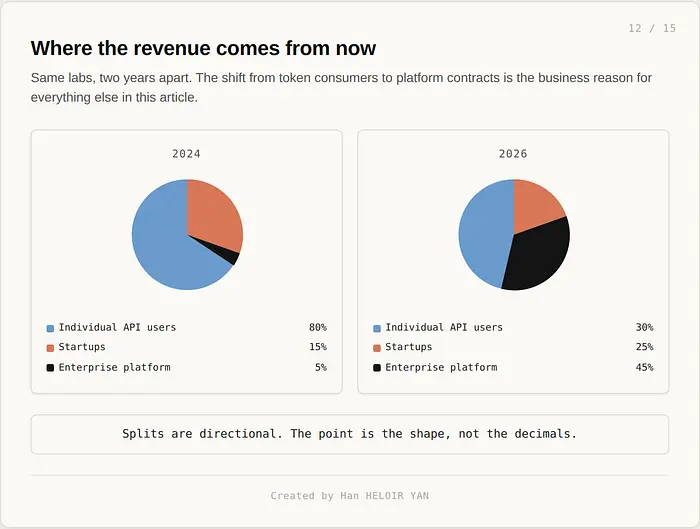
这就是客户名单告诉你的。ASML 和 La Banque Postale 不买 token。他们买平台。Stripe 将 1,370 名工程师投入 Claude Code 不是一个 API 合同。这是一个平台部署,涉及内部集成、安全审查和在 CIO 层面协商的账单条款。模型获得新闻稿。运行时获得采购签字。
7、对构建者、架构师和资本配置者的变化
三个受众,三个具体转变。它们都不是下个季度的问题。
如果你在生产环境中构建 agent,每个新项目的第一个问题发生了变化。过去是"我用哪个框架"。现在是"我锚定哪个实验室"。框架是你编写 agent 的方式。实验室的运行时是 agent 存活的地方。先选实验室,再选框架。具体信号:如果你的平台团队估计需要超过三周的工程工作来发布重试、审计和人工审批,你正在重新发明一个已经存在的托管服务。购买它。用那个团队做差异化工作。
如果你设计平台,框架选择不再是一个生产力问题。它是一个主权问题。Workflows 运行 Mistral。Managed Agents 运行 Claude。Agent Builder 运行 OpenAI。选择一个意味着将你的持久执行层承诺给一个模型家族,持续合同期。混合模式成为标准:主要模型家族使用托管运行时,长尾的回退和专用模型使用框架抽象。两者都规划。推荐单一运行时的文档在十八个月内看起来会很幼稚。
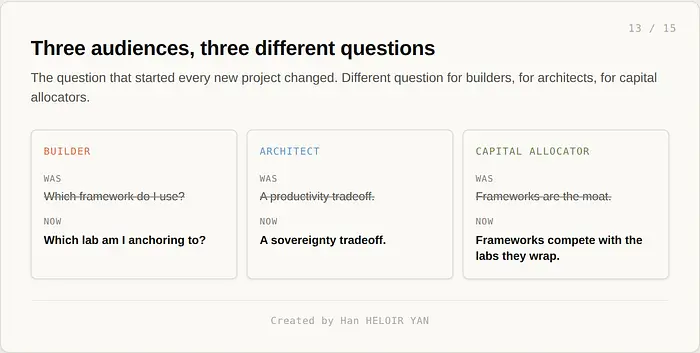
如果你分配资本,编排层刚刚获得了三个已经拥有模型层的新巨头。LangChain 将编排作为护城河。Temporal 将持久执行作为护城河。两者都以数亿美元估值融资。两者现在都在与它们所包装模型的公司竞争。可移植的公司将赢得实验室无法发布的层:主权和本地部署、多 LLM 可移植性,以及目前没有托管运行时能匹配的框架人体工程学。在相同轴上与托管运行时正面竞争的公司(大规模持久执行、可观测性、审计)将被价格挤出。
8、更深的转向
下次有人问你哪个模型实验室在赢,你的答案是错的。模型不是决定谁赢的层。
贯穿 2024 年和 2025 年的大部分时间,这个问题是合理的。不同实验室确实有不同的模型能力,基准测试差距映射到业务结果。那个窗口已经关闭。前沿模型性能在 2025 年中期在顶级实验室之间趋同,剩余的差距不足以驱动企业级采购决策。
替代它的是运行时。带 Workflows 的 Mistral。带 Managed Agents 的 Anthropic。带 Responses、Agents SDK 和 Agent Builder 的 OpenAI。每个实验室现在正在用三个不同的品牌名称销售相同的产品:一个托管基底,承载你的 agent、你的状态、你的沙箱、你的审计和你的凭证,模型包含在内。模型是市场看到的。基底是被计费的。
这就是从模型实验室到运行时公司的转向,而且它不是局部的。Mistral 的客户名单是平台合同。Anthropic 明确将 Managed Agents 称为生产基础设施。OpenAI 正在为企业部署配置人员,而不是消费者规模。新闻稿仍然谈论基准测试,因为基准测试是新闻稿的写作方式。合同不再以基准测试为条件。
三个地理区域,相同的赌注,一个没有动的实验室。美国实验室将在生态系统深度和与现有美国企业软件栈的集成上竞争。Mistral 将在主权、AI 法案合规性和不会为一等工作负载购买美国托管服务的欧洲采购上限上竞争。中国实验室将在防火墙内竞争。Cohere 将按节点部署经济学竞争,直到那个市场缩小。模型层将继续商品化。运行时层不会。
未来十年的正确问题不是哪个模型实验室在赢。而是谁的运行时现在是你公司的基底,以及到时候迁移出去需要多长时间。
对大多数企业来说,第二部分的答案是永远。这就是运行时公司出售的东西。这就是为什么实验室正在成为运行时公司。这就是为什么 4 月 28 日的 Workflows 不是一个功能发布。
它是一个宣言。
原文链接:Mistral shipped Workflows and the real story is that model labs are no longer model labs
汇智网翻译整理,转载请标明出处
